
一、背景
有一个项目需要使用到爬虫,因此去Google上搜索了一下,发现除了requests,scrapy,多线程,多进程以外,还有一种方法异步爬虫。使用aiohttp+async来进行网站的爬取。
二、使用
通过以下的指令安装
# 通过指令安装aiohttp
pip install aiohttp
我们在使用aiohttp的时候,还需要注意就是需要使用async这种异步编程的方式。同时这个方法需要python3.5以上。主要是使用aiohttp这种异步的方式来进行爬取。
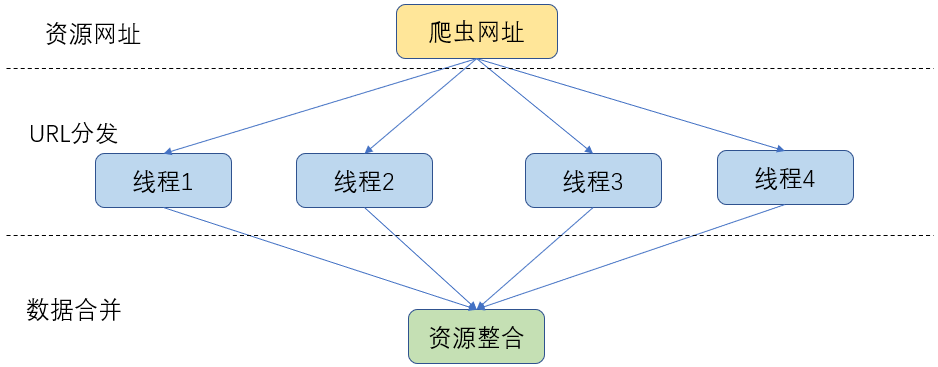
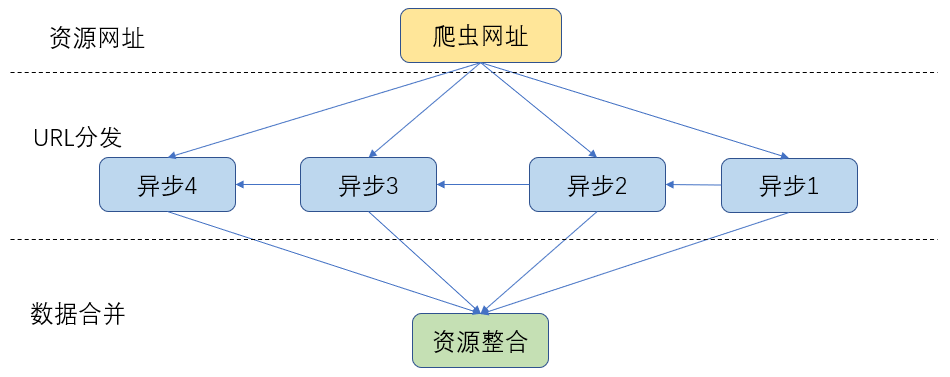
三、模型(不是很准确的结构图)
3.1 多线程爬虫模型
3.2 异步爬虫模型
四、核心代码
其实和一般的request爬虫一样,只是需要注意这里需要使用aiohttp他是异步编程的,因此需要用到async的方法
# 设置爬虫的日志格式 logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s') logger = logging.getLogger(__name__) df = pd.DataFrame(columns=['occupation', 'companyName', 'location', 'salary', 'date', 'education', 'experience', 'companyType', 'companySize', 'type', 'request']) # 异步HTTP请求 async def fetch(sem11, session, url): async with sem11: async with session.get(url, headers=header) as response: return await response.text(errors='ignore') # 处理网页 async def download(sem, url): async with aiohttp.ClientSession() as session: try: html = await fetch(sem, session, url) # 这里添加网页的解析代码 await parser(html) except Exception as err: print(err) if __name__ == '__main__': # 统计该爬虫的消耗时间 print('*' * 50) t_start_web = time.time() loop = asyncio.get_event_loop() sem1 = asyncio.Semaphore(100) # 第一个人 3413 # 第二个人 3413:6826 # 第三个人 6826: tasks = [asyncio.ensure_future(download(sem1, url)) for url in urls[:3413]] tasks = asyncio.gather(*tasks) loop.run_until_complete(tasks) t_end_web = time.time() print('网站爬取总共耗时:%s' % (t_end_web - t_start_web))
五、参考
5.1 详细介绍
http://www.ityouknow.com/python/2019/12/28/python-aiohttp-102.html
https://www.jianshu.com/p/b8010594557f
5.2 性能对比

 浙公网安备 33010602011771号
浙公网安备 33010602011771号