
一、问题
使用selenium自动化测试爬取知乎的时候出现了:错误代码10001:请求异常请升级客户端后重新尝试,这个错误的产生是由于知乎可以检测selenium自动化测试的脚本,因此可以阻止selenium的继续访问。这也算是比较高级的反爬取措施。
二、解决
解决方法,使用自己打开的一个浏览器,再用selenium接管这个浏览器这样就可以完成反爬的处理。
1.建议一个新的映射,以保存原来的chrome不被污染
1)添加环境变量
将chrome.exe放入系统环境变量中,找到驱动位置添加变量,如果没找到,最快的方法就是点击图标右键,点击访问文件地址
chrome.exe位置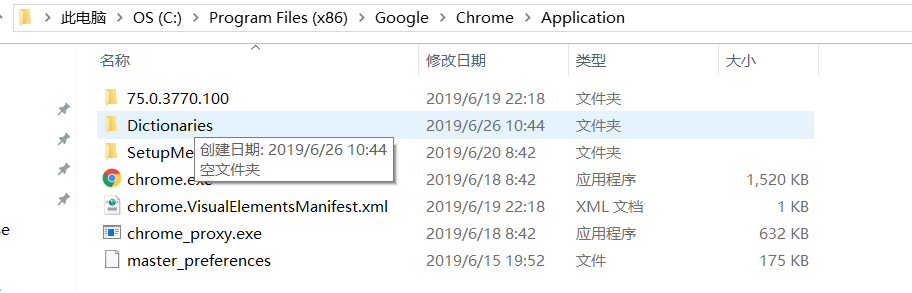
快捷访问方式,在菜单栏同样可以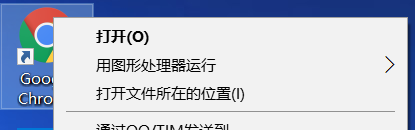
2)新建一个存放新环境的文件夹并映射
使用指令【chrome.exe --remote-debugging-port=9222 --user-data-dir="E:\data_info\selenium_data"】
其中--remote-debugging-port是建立新的移植位置,其中端口后面会使用(自定义), --user-data-dir是数据存储的目录(自定义)
此时会打开一个网页放着就行
2.selenium代码接管
通过下面的代码就可以登录知乎
import time
import json
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
class ZhiHu:
def __init__(self):
self.url = 'https://www.zhihu.com/'
self.chrome_options = Options()
self.chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222") # 前面设置的端口号
self.browser = webdriver.Chrome(executable_path=r'E:\Environment\python_global\Scripts\chromedriver.exe', options=self.chrome_options) # executable执行webdriver驱动的文件
def get_start(self):
self.browser.get(self.url)
# time.sleep(20) # 可以选择手动登录或者是自动化,我这里登录过就直接登陆了
info = self.browser.get_cookies() # 获取cookies
print(info)
with open(r"..\download_txt\info.json", 'w', encoding='utf-8') as f:
f.write(json.dumps(info))
if __name__ == '__main__':
zhihu = ZhiHu()
zhihu.get_start()
三、结果展示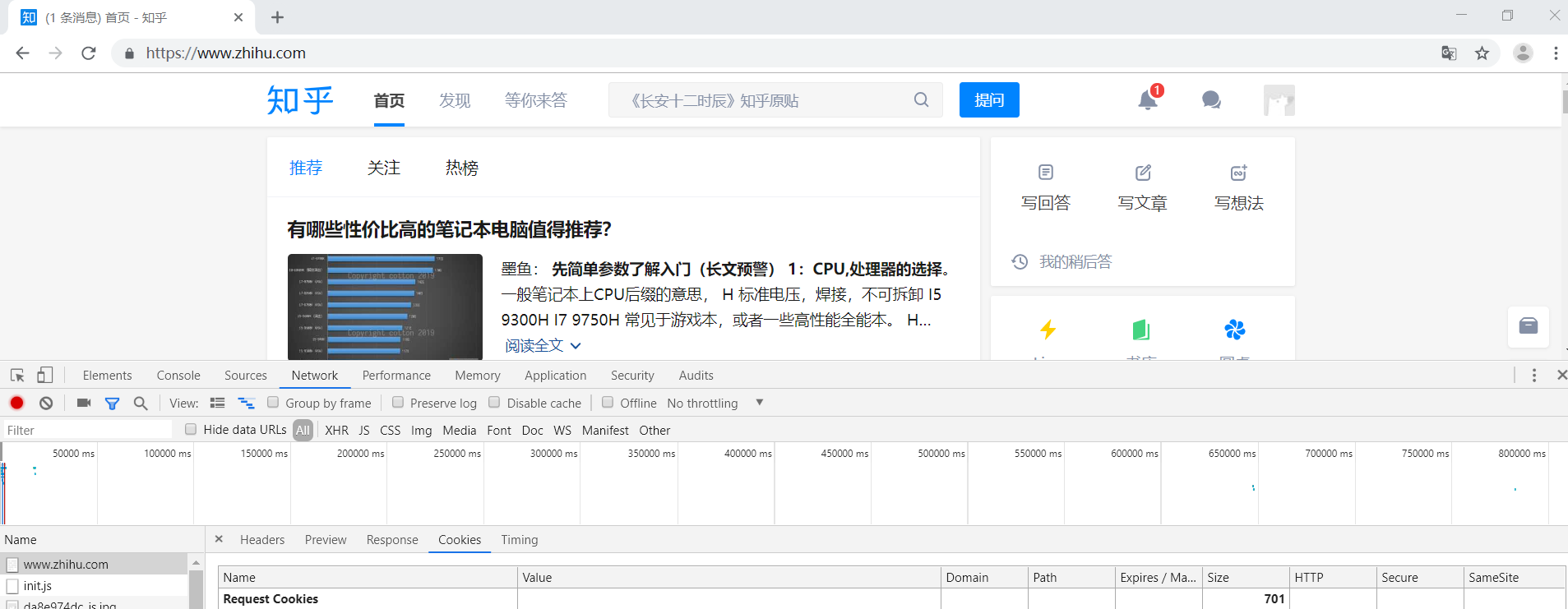
四、总结
利用这个selenium接管正在使用的浏览器就可以绕过知乎的反爬,当然也可以做更多的爬虫,selenium在爬虫的使用中还是有重要的地位,偷懒一点就可以使用这个。这种方法可以获取cookies这样在使用其他的爬虫,就可以使用这个cookies会加快爬取的效率,以及突破不适用浏览器的反爬措施。这引起我们另一个思考,我们直接接管我们正常的chrome好像更加的高效,这个可以以后的学习中尝试一下。
五、参考
附一些参考,方便自己学习,毕竟每次百度起来都很麻烦
https://www.cnblogs.com/HJkoma/p/9936434.html
https://blog.csdn.net/qq_42206477/article/details/86477446

 浙公网安备 33010602011771号
浙公网安备 33010602011771号