
《数据篇》HashMap的get与put原理
简介
参考链接:https://www.cnblogs.com/scxgy/p/15398631.html
HashMap是一个散列表,它存储的内容是键值对(key-value)映射。它是无序的,不会记录插入的顺序。(散列表,英文hash table)
HashMap实现了Map接口,根据键的HashCode值存储数据,最多允许一条记录的键为null,不支持线程同步。
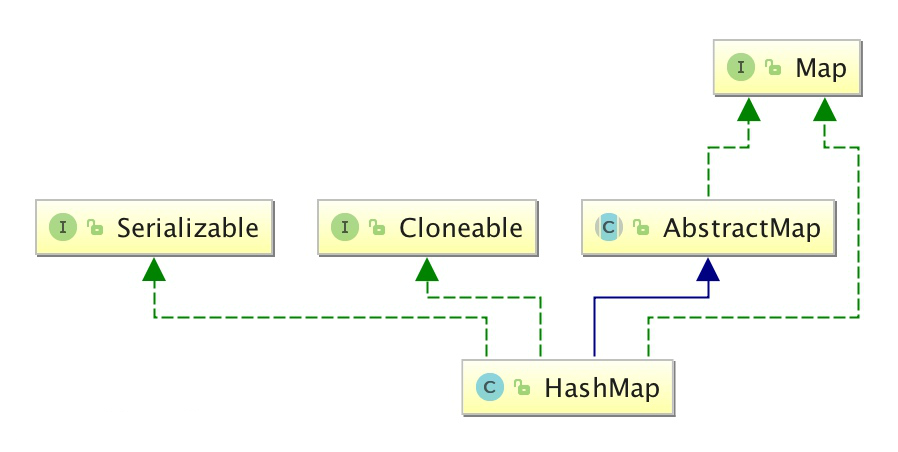
HashMap继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
工作原理
参考链接:https://www.cnblogs.com/liufarui/p/12968553.html
HashMap使用put(key,value)存储对象,使用get(key)获取对象。
HashMap的初始化(简单模拟):
Node table = new Node[16] //散列桶初始化,table
class Node{
hash; //hash值
key; //键
value; //值
Node next; // 用于指向链表的下一层()
}
get过程
参考链接:https://blog.csdn.net/weixin_44198363/article/details/88105800
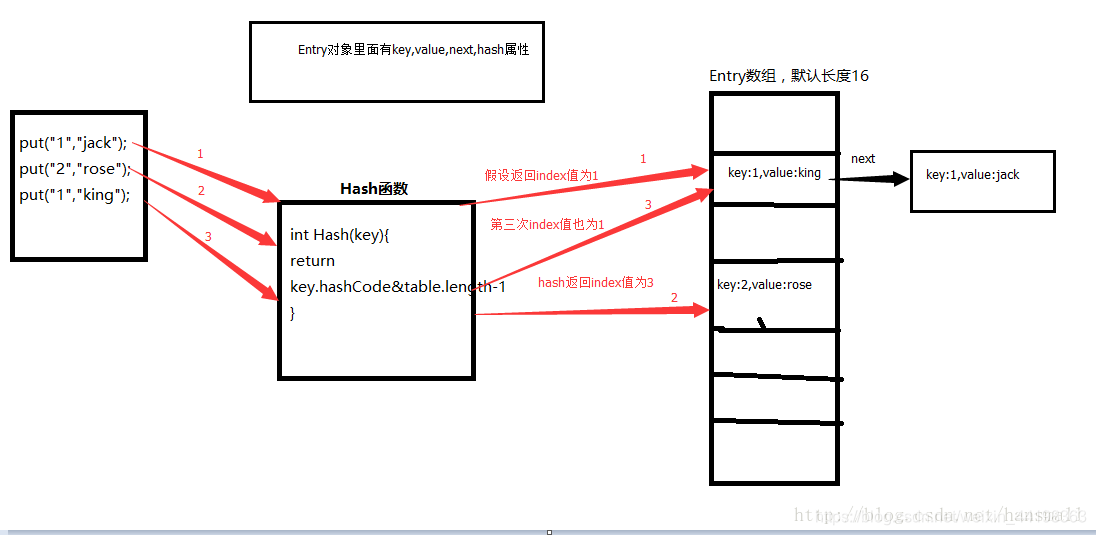
HashMap的数据结构为数组+链表,以key,value的形式存值,通过调用put与get方法来存值与取值。
它内部维护了一个Entry数组,得到key的hashCode值将其移位按位与运算,然后再通过跟数组的长度-1作逻辑与运算得到一个index值来确定数据存储在Entry数组当中的位置,通过链表来解决hash冲突问题。当发生碰撞了,对象将会储存在链表的下一个节点中。
get方法调用
1.当调用get方法时会调用hash函数,这个hash函数会将key的hashCode值返回,返回的hashCode与Entry数组长度-1进行逻辑与运算得到一个index值,用这个index值来确定数据存储在Entry数组当中的位置
2.通过循环来遍历索引位置对应的链表,初始值为数据存储在Entry数组当中的位置,循环条件为Entry对象不为null,改变循环条件为Entry对象的下一个节点
3.如果hash函数得到的hash值与Entry对象当中key的hash值相等,并且Entry对象当中的key值与get方法传进来的key值equals相同则返回该Entry对象的value值,否则返回null

put方法调用
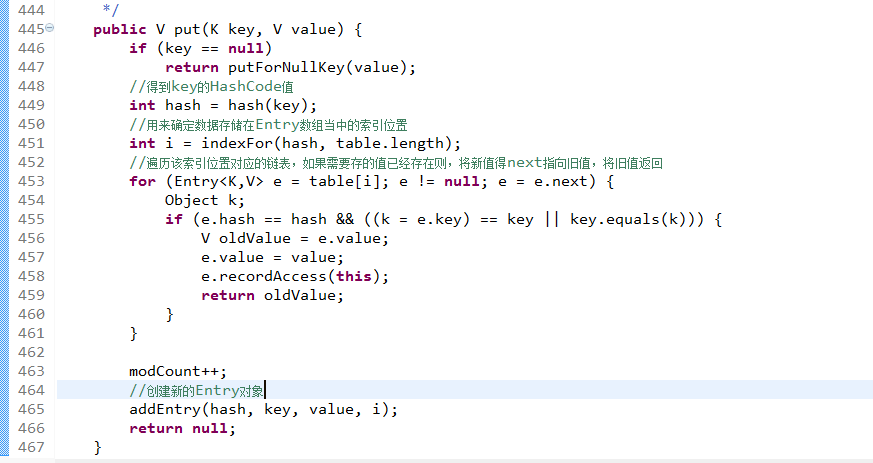
1.调用hash函数得到key的HashCode值
2.通过HashCode值与数组长度-1逻辑与运算得到一个index值
3.遍历索引位置对应的链表,如果Entry对象的hash值与hash函数得到的hash值相等,并且该Entry对象的key值与put方法传过来的key值相等则,将该Entry对象的value值赋给一个变量,将该Entry对象的value值重新设置为put方法传过来的value值。将旧的value返回。
4.添加Entry对象到相应的索引位置
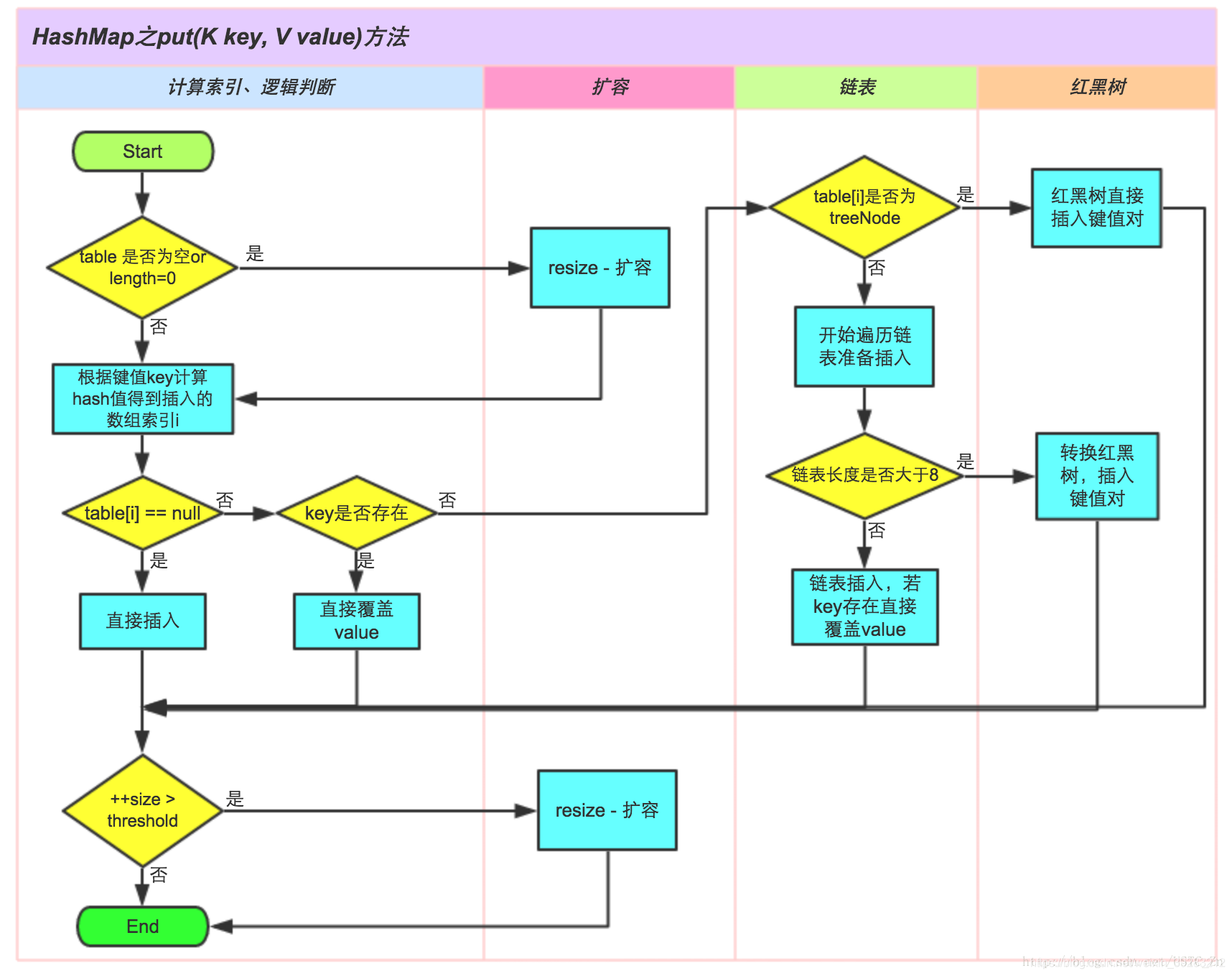
put过程
参考链接:https://blog.csdn.net/kris_lh123/article/details/102841924
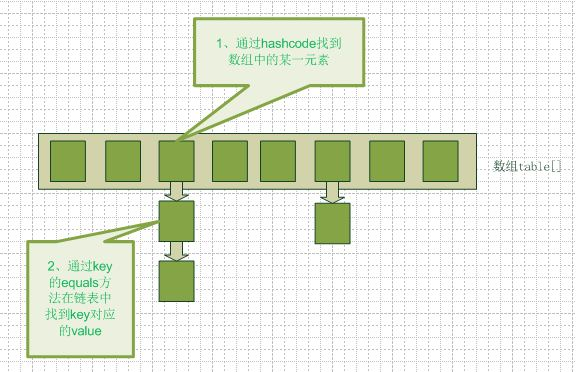
HashMap是一个数组+链表构成的哈希表结构,支持多种数据结构,key和value都可以为null,但是key只能有一个为null;key和value都不可以存放基本数据类型,可以存放他们的封装类;key可以是任意对象,需要重写hashcode方法。
1.计算key的hashcode值
(hashcode是object基类的方法,如果是String类型,他已经重写了hashcode方法,所以保证了同样的值,hashcode值相等;如果是其他类型,需要自己重写hashcode方法,因为,object的hashcode方法只是返回对象的内存地址,相同值的对象,由于在堆中存放的位置不同,hashcode也不同,这就违反了hashmap的key唯一性的定义)。
2.根据hashcode计算key的hash值。
(使用hash散列算法,目前采用的是:key==null?0:(h=key.hashCode())^(h>>>16);)
3.根据hash值计算数组index。
(Entry[]数组的长度在初始化的时候会被指定,index需要尽可能的分布均匀;两种算法:取模运算(index=hash%length)和位运算(index=hash&(length-1);但是位运算有个前置条件:length的值必须是2的n次幂,因为只有这样,hash%length=hash&(length-1)才成立,实践证明,这样可以降低hash碰撞,就减少存放在链表的可能性,相对的,查询的时候就不用遍历某个位置上的链表,这样查询效率也就较高了。 );两者都能保证key分布在Entry[0,length-1]上,但是取模运算效率低,所以选用位运算进行映射。)
得到index之后,判断Entry[index]当前数组位置上是否已经有值,如果没有,直接插入;如果有值,需要根据equals方法判断key是否已经存在,存在的话直接覆盖;不存在的话,判断Entry[index]是否是treeNode,是的话直接红黑树插入value;如果不是的话,开始遍历链表准备插入,插入后判断此时链表长度是否大于8,大于的话转换为红黑树,插入,不大于的话,根据equals方法判断key是否已经存在,存在的话直接覆盖,不存在的话,直接插入到最前面,其他value后移。
插入之后判断此时size是否大于阈值,大于的话需要resize进行扩容,重新映射。
总结:
1.底层存储数据的数组,在第一次put元素的时候初始化,同时发生第一次扩容;
2.相比较JDK 1.8之前的版本,JDK 1.8在链表长度大于8的时候,会转化为红黑树处理,主要是基于效率的考量;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号