YOLO V2
YOLOV2
paper link
YOLO9000: Better, Faster, Stronger
Yolov2概述

先解释概念:Yolov2和Yolo9000算法内核相同,区别是训练方式不同:Yolov2用coco数据集训练后,可以识别80个种类。而Yolo9000可以使用coco数据集 + ImageNet数据集联合训练,可以识别9000多个种类。上图为Yolo9000的检测效果图,可以看到图片中的人,被分为了leader、American、skin-diver、athlete。
本文首先介绍Yolov2,列举出基于v1所做的改进;之后解读Yolo9000的训练方法。
Yolo v2:Better, Faster
Yolov2论文标题就是更好,更快,更强。Yolov1发表之后,计算机视觉领域出现了很多trick,例如批归一化、多尺度训练,v2也尝试借鉴了R-CNN体系中的anchor box,所有的改进提升,下面逐一介绍。
Better
-
Batch Normalization(批归一化)
By adding batch normalization on all of the convolutional layers in YOLO we get more than 2% improvement in mAP.检测系列的网络结构中,BN逐渐变成了标配。在Yolo的每个卷积层中加入BN之后,mAP提升了2%,并且去除了Dropout。
-
High Resolution Classifier(分类网络高分辨率预训练)
在Yolov1中,网络的backbone部分会在ImageNet数据集上进行预训练,训练时网络输入图像的分辨率为\(224*224\)。在v2中,将分类网络在输入图片分辨率为\(448*448\)的ImageNet数据集上训练10个epoch,再使用检测数据集(例如coco)进行微调。高分辨率预训练使mAP提高了大约4%。
-
Convolutional With Anchor Boxes(Anchor Box替换全连接层)
解读v1时提到,每个格点预测两个矩形框,在计算loss时,只让与ground truth最接近的框产生loss数值,而另一个框不做修正。这样规定之后,作者发现两个框在物体的大小、长宽比、类别上逐渐有了分工。在v2中,神经网络不对预测矩形框的宽高的绝对值进行预测,而是预测与Anchor框的偏差(offset),每个格点指定n个Anchor框。在训练时,最接近ground truth的框产生loss,其余框不产生loss。在引入Anchor Box操作后,mAP由69.5下降至69.2,原因在于,每个格点预测的物体变多之后,召回率大幅上升,准确率有所下降,总体mAP略有下降。
v2中移除了v1最后的两层全连接层,全连接层计算量大,耗时久。文中没有详细描述全连接层的替换方案,这里笔者猜测是利用\(1*1\)的卷积层代替(欢迎指正),具体的网络结构原文中没有提及,官方代码也被yolo v3替代了。v2主要是各种trick引入后的效果验证,建议不必纠结于v2的网络结构。
-
Dimension Clusters(Anchor Box的宽高由聚类产生)
这里算是作者的一个创新点。Faster R-CNN中的九个Anchor Box的宽高是事先设定好的比例大小,一共设定三个面积大小的矩形框,每个矩形框有三个宽高比:\(1:1\),\(2:1\),\(1:2\),总共九个框。而在v2中,Anchor Box的宽高不经过人为获得,而是将训练数据集中的矩形框的宽和高\((w,h)\)作为一个向量全部拿出来,距离函数是iou,以此为基础用kmeans聚类得到先验框的宽和高。例如使用5个Anchor Box,那么kmeans聚类的类别中心个数设置为5。加入了聚类操作之后,引入Anchor Box之后,mAP上升。
需要强调的是,聚类必须要定义聚类点(矩形框\((w,h)\))之间的距离函数,文中使用如下函数:
\[d(box,centroid)=1-IoU(box,centroid) \]使用(\(1-IOU\))数值作为两个矩形框的的距离函数,这里的运用也是非常的巧妙。
-
Direct location prediction(绝对位置预测)
Yolo中的位置预测方法很清晰,就是相对于左上角的格点坐标预测偏移量。这里的Direct具体含义,应该是和其他算法框架对比后得到的。比如其他流行的位置预测公式如下:
\[\begin{matrix}x=(t_x)*w_a+x_a\\y=(t_y*h_a)+y_a \end{matrix} \]神经网络预测\(t_x,t_y\),而\(t_x,t_y\)又需要与先验框的宽高相乘才能得到相较于\(x_a,y_a\)的位置偏移值,在v2中,位置预测公式如下:
\[\begin{matrix}b_x=\sigma(t_x)+c_x\\b_y=\sigma(t_y)+c_y\\b_w=p_we^{t_w}\\b_h=p_he^{t_h}\end{matrix} \]Yolo的天然优势,就是格点的坐标可以作为参照点。此时\(t_x,t_y\)通过一个激活函数,直接产生偏移位置数值,与矩形框的宽高独立开,变得更加直接。
-
Fine-Grained Features(细粒度特征)
在\(26*26\)的特征图,经过卷积层等,变为\(13*13\)的特征图后,作者认为损失了很多细粒度的特征,导致小尺寸物体的识别效果不佳,所以在此加入了passthrough层。
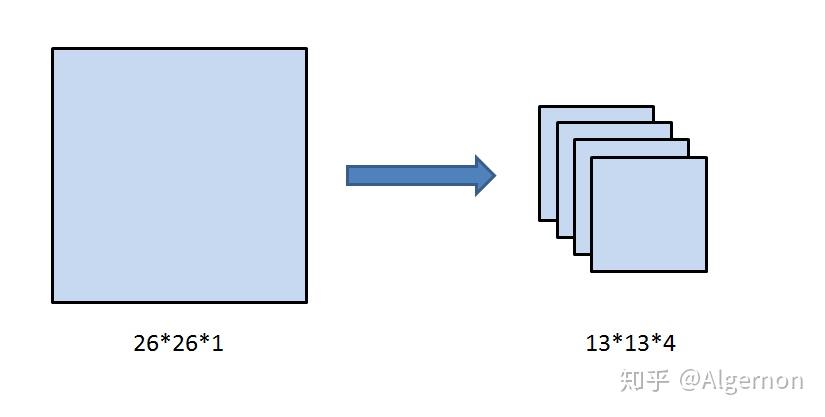
如上图所示,passthrough层就是将\(26*26*1\)的特征图,变成\(13*13*4\)的特征图,在这一次操作中不损失细粒度特征。有人说passthrough层分成四份的具体细节,并不是两刀切成4块,而是在每个\(2*2\)的小区域上都选择左上角块。其实这里怎么切都一样,在之后\(1*1\)卷积层中,不过是加法交换律的事。
-
Multi-Scale Training(多尺寸训练)
很关键的一点是,Yolo v2中只有卷积层与池化层,所以对于网络的输入大小,并没有限制,整个网络的降采样倍数为32,只要输入的特征图尺寸为32的倍数即可,如果网络中有全连接层,就不是这样了。所以Yolo v2可以使用不同尺寸的输入图片训练。
作者使用的训练方法是,在每10个batch之后,就将图片resize成\(\{320, 352, ..., 608\}\)中的一种。不同的输入,最后产生的格点数不同,比如输入图片是\(320*320\),那么输出格点是\(10*10\),如果每个格点的先验框个数设置为5,那么总共输出500个预测结果;如果输入图片大小是\(608*608\),输出格点就是\(19*19\),共1805个预测结果。
在引入了多尺寸训练方法后,迫使卷积核学习不同比例大小尺寸的特征。当输入设置为\(544*544\)甚至更大,Yolo v2的mAP已经超过了其他的物体检测算法。
Faster
-
Darknet-19
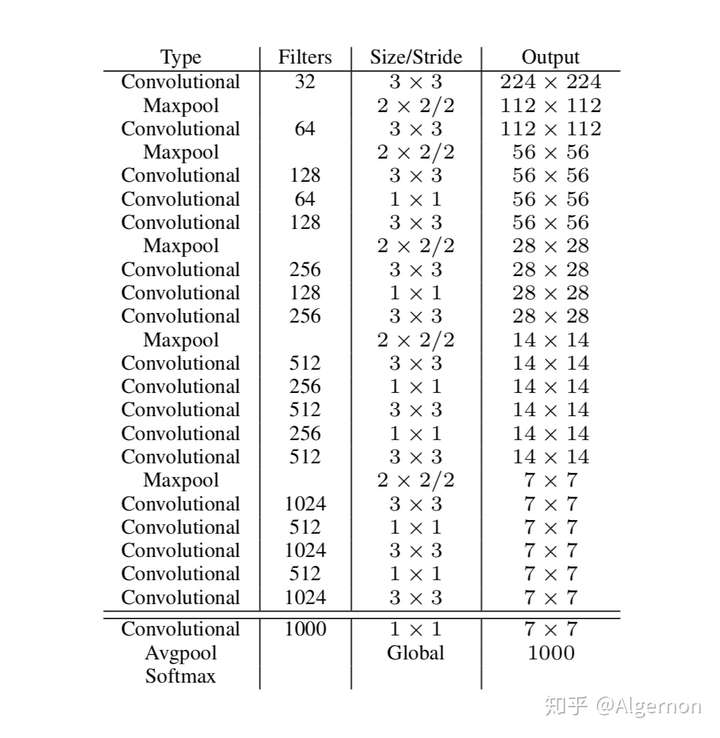
v2中作者提出了新的分类网络架构——Darknet-19,该架构的网络参数较VGG-16更少,在ImageNet上,仍然可以达到top-1 72.9%以及top-5 91.2%的精度。
Yolo v2精度与性能
全部的trick效果如下,除了直接引入人为指定宽高的Anchor Boxes,其他技巧都带来了一定的增益。
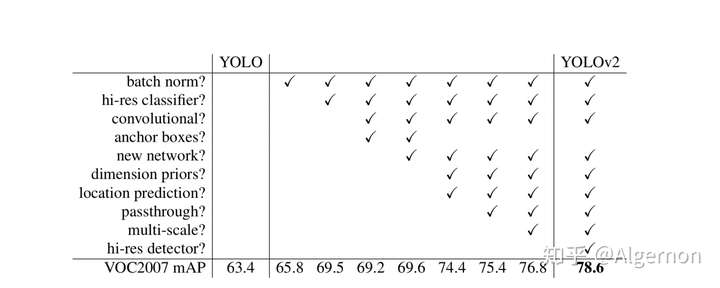
附一下Yolo v2与其他算法的对比图:
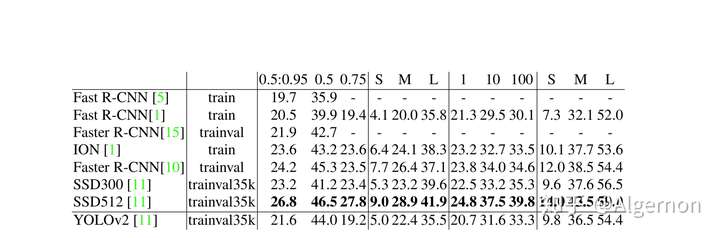
- Yolo v2精度对比(on COCO test-dev2015)
-
Yolo v2精度与速率对比(on PASCAL VOC)
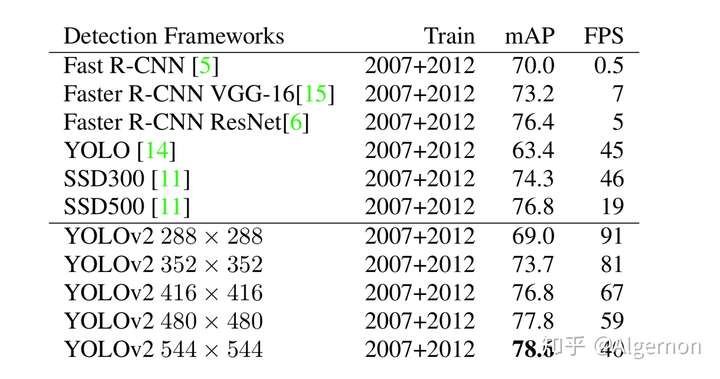
可见,Yolo v2的精度可以比肩业界前沿算法,同时仍然保持着大幅度速率领先。
Yolo9000:Stronger
Joint classification and detection
如果说整个Yolo v2的Better部分,都没有什么大的创新点,这里的分类与检测联合训练,就是Yolo v2的一大亮点,因为这一个技巧,Yolo v2才成为了Yolo9000。
如之前所说,物体分类,是对整张图片打标签,比如这张图片中含有人,另一张图片中的物体为狗;而物体检测不仅对物体的类别进行预测,同时需要框出物体在图片中的位置。物体分类的数据集,最著名的ImageNet,物体类别有上万个,而物体检测数据集,例如coco,只有80个类别,因为物体检测、分割的打标签成本比物体分类打标签成本要高很多。所以在这里,作者提出了分类、检测训练集联合训练的方案。
联合训练方法思路简单清晰,Yolo v2中物体矩形框生成,不依赖于物理类别预测,二者同时独立进行。当输入是检测数据集时,标注信息有类别、有位置,那么对整个loss函数计算loss,进行反向传播;当输入图片只包含分类信息时,loss函数只计算分类loss,其余部分loss为零。当然,一般的训练策略为,先在检测数据集上训练一定的epoch,待预测框的loss基本稳定后,再联合分类数据集、检测数据集进行交替训练,同时为了分类、检测数据量平衡,作者对coco数据集进行了上采样,使得coco数据总数和ImageNet大致相同。
联合分类与检测数据集,这里不同于将网络的backbone在ImageNet上进行预训练,预训练只能提高卷积核的鲁棒性,而分类检测数据集联合,可以扩充识别物体种类。例如,在检测物体数据集中,有类别人,当网络有了一定的找出人的位置的能力后,可以通过分类数据集,添加细分类别:男人、女人、小孩、成人、运动员等等。这里会遇到一个问题,类别之间并不一定是互斥关系,可能是包含(例如人与男人)、相交(运动员与男人),那么在网络中,该怎么对类别进行预测和训练呢?
Dataset combination with WordTree
在文中,作者使用WordTree,解决了ImageNet与coco之间的类别问题。
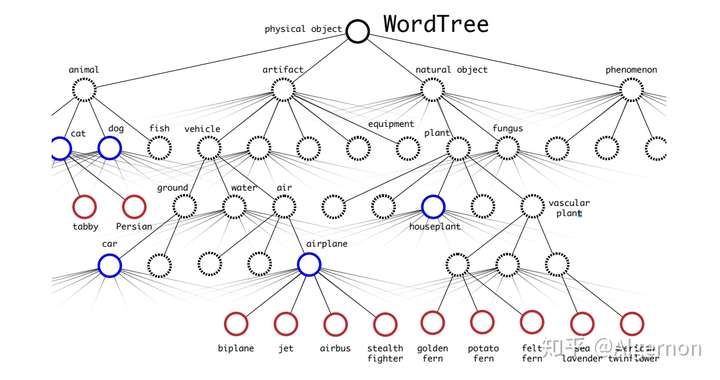
树结构表示物体之间的从属关系非常合适,第一个大类,物体,物体之下有动物、人工制品、自然物体等,动物中又有更具体的分类。此时,在类别中,不对所有的类别进行softmax操作,而对同一层级的类别进行softmax:
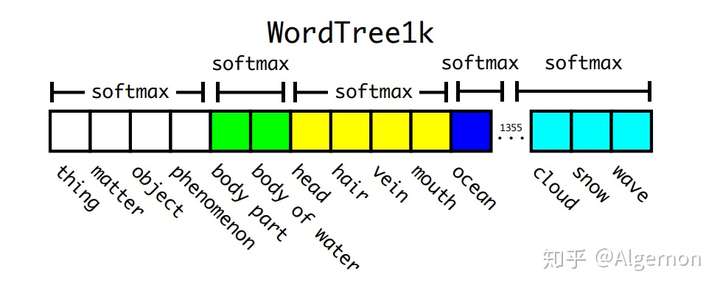
如图中所示,同一颜色的位置,进行softmax操作,使得同一颜色中只有一个类别预测分值最大。在预测时,从树的根节点开始向下检索,每次选取预测分值最高的子节点,直到所有选择的节点预测分值连乘后小于某一阈值时停止。在训练时,如果标签为人,那么只对人这个节点以及其所有的父节点进行loss计算,而其子节点,男人、女人、小孩等,不进行loss计算。
最后的结果是,Yolo v2可以识别超过9000个物体,作者美其名曰Yolo9000。当然原文中也提到,只有当父节点在检测集中出现过,子节点的预测才会有效。如果子节点是裤子、T恤、裙子等,而父节点衣服在检测集中没有出现过,那么整条预测类别支路几乎都是检测失效的状态。这也合理,给神经网络看的都是狗,让它去预测猫,目前神经网络还没有这么智能。
注:yolov2 9000联合训练的方式在实际中存在一些问题,imagenet图像是标准的数据集,图像中目标很显著,占的面积较大,而且图像中只存在单类的物体,所以能很明确的知道预测框的类别,但在实际中,图像可能存在多个类别的物体,也会存在其他未知的干扰,很难像imagenet数据集那么“干净”
本文来自博客园,作者:甫生,转载请注明原文链接:https://www.cnblogs.com/fusheng-rextimmy/p/15443202.html
