SLAM模块化总结
相机模型


坐标定义
-
世界坐标系
\[P_w(m):(x_w,y_w,z_w) \] -
相机坐标系
\[P_c(m):(x_c,y_c,z_c) \] -
图像坐标系
\[P(mm):(x,y) \] -
像素坐标系
\[p(pixel):(u,v) \]
坐标转换
-
世界坐标系$\longrightarrow $相机坐标系
\[P_c=T_{cw}P_w \]\[\begin{bmatrix} x_w\\ y_w \\ z_w\\1\end{bmatrix}=\begin{bmatrix}R & t\\0^T & 1\end{bmatrix}\begin{bmatrix}x_c\\y_c\\z_c\\1\end{bmatrix} \] -
相机坐标系$\longrightarrow $图像坐标系


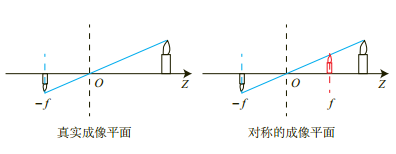 \[\frac{z_c}{f}=\frac{x_c}{x}=\frac{y_c}{y},f为焦距 \]
\[\frac{z_c}{f}=\frac{x_c}{x}=\frac{y_c}{y},f为焦距 \] -
像素坐标系$\longleftrightarrow $图像坐标系

-
像素坐标系以图像左上角为原点
-
图像坐标系理论上以图像中心为原点,但是由于相机生产制作产生的误差,需要我们对相机进行标定才能确定坐标原点
-
两个坐标系之间相差了一个缩放和一个原点的平移。我们设像素坐标在 u 轴上缩放了 1/dx倍,在 v 上缩放了 1/dy倍,那么我们可以表示为
\[\begin{cases} u=\frac{x}{dx}+c_x\\v=\frac{y}{dy}+c_y\end{cases} \]用矩阵形式可以表示为
\[\begin{bmatrix}u \\v \\1\end{bmatrix}=\begin{bmatrix} \frac{1}{dx}&0&c_x\\0&\frac{1}{dy}&c_y\\0&0&1\end{bmatrix}\begin{bmatrix}x\\y\\1\end{bmatrix} \]
-
-
像素坐标系$\longrightarrow $相机坐标系
\[\begin{cases} u=\frac{x}{dx}+c_x\\v=\frac{y}{dy}+c_y\end{cases}\longleftrightarrow \begin{bmatrix}u \\v \\1\end{bmatrix}=\frac{1}{z_c}\begin{bmatrix}f_x&0&c_x\\0&f_y&c_y\\0&0&1\end{bmatrix}\begin{bmatrix}x_c\\y_c\\z_c\end{bmatrix}=\frac{1}{z_c}KP_c=p \]由于齐次坐标的性质,有时转换时也会省略\(z_c\)
-
像素坐标系\(\longrightarrow\)世界坐标系
\[p=\begin{bmatrix}u \\v \\1\end{bmatrix}=\frac{1}{z_c}\begin{bmatrix}f_x&0&c_x\\0&f_y&c_y\\0&0&1\end{bmatrix}\begin{bmatrix}x_c\\y_c\\z_c\end{bmatrix}=\frac{1}{z_c}KTP_w \]
视觉里程计
相机的运动衡量其实就是上一时刻拍摄到的帧和当前时刻帧之间相机所做的平移和旋转操作所以计算R和t的过程就是视觉里程计
基于特征匹配的视觉里程计
基于特征的方法是当前视觉里程计的主流方式,对于两张图像,首先选取一些具有代表性的点,称为特征点。之后,仅针对这些特征点估计相机的运动,同时估计特征点的空间位置。图像里其他非特征点的信息,则被丢弃
特征点方法把一个对图像的运动估计转换为对两组点之间的运动估计。于是,它的主要问题为:
- 我们如何获取图像特征点?如何匹配它们?
- 如何根据已知特征点,计算相机的运动?
计算特征点
常用的特征点有Harris角点、SIFT、SURF、ORB等,下图采用的是Sift特征点

对于每一个特征点,为了说明它与其他点的区别,人们还使用“描述子”(Descriptor)对它们加以描述。描述子通常是一个向量,含有特征点和周围区域的信息。如果两个特征点的描述子相似,我们就可以认为它们是同一个点。根据特征点和描述子的信息,我们可以计算出两张图像中的匹配点。

根据匹配好的特征点估计相机运动
在匹配好特征点后,我们可以得到两个一一对应的像素点集。接下来要做的,就是根据两组匹配好的点集,计算相机的运动了。在普通的单目成像中,我们只知道这两组点的像素坐标。而在双目和RGBD配置中,我们还知道该特征点离相机的距离。因此,该问题就出现了多种形式:
-
2D-2D形式:通过两个图像的像素位置来估计相机的运动。
-
3D-2D形式:假设已知其中一组点的3D坐标,以及另一组点的2D坐标,求相机运动。
-
3D-3D形式:两组点的3D坐标均已知,估计相机的运动。
那么问题就来了:是否需要为这三种情况设计不同的计算方法呢?答案是:既可以单独做,也可以统一到一个大框架里去做。
- 单独做的时候,2D-2D使用对极几何的方法,3D-2D使用PnP求解算法,而3D-3D则称为ICP方法(准确地说,ICP不需要各点的配对关系)。
- 统一的框架,就是指把所有未知变量均作为优化变量,而几何关系则是优化变量之间的约束。由于噪声的存在,几何约束通常无法完美满足。于是,我们把与约束不一致的地方写进误差函数。通过最小化误差函数,来求得各个变量的估计值。这种思路也称为Bundle Adjustment(BA,中文亦称捆集优化或光束法平差)。
代数方法简洁优美,但是它们对于噪声的容忍性较差。存在误匹配,或者像素坐标存在较大误差时,它给出的解会不可靠。而在优化方法中,我们先猜测一个初始值,然后根据梯度方向进行迭代,使误差下降。Bundle Adjustment非常通用,适用于任意可以建模的模型。但是,由于优化问题本身非凸、非线性,使得迭代方法往往只能求出局部最优解,而无法获得全局最优解。也就是说,只有在初始值足够好的情况下,我们才能希望得到一个满意的解。
因此,在实际的VO中,我们会结合这两种方法的优点。先使用代数方法估计一个粗略的运动,然后再用Bundle Adjustment进行优化,求得可精确的值。
2D-2D
问题描述
已知条件: 每个特征点的像素坐标;两张图像之间的特征点的匹配关系;相机内参
求解:相机的R和t


特征点不共面——计算基础矩阵或者本质矩阵
我们需要把像素坐标系转化为世界坐标系,因为只有这一转换过程包含\(R\)和\(t\)
因为相机内参已知,我们首先可以把像素坐标转化为相机坐标
-
为何此处的\(z_c\)不见了?
- 因为像素坐标\(p=\begin{bmatrix}u \\v \\1\end{bmatrix}\)是齐次坐标,是否乘上\(z_c\)对齐次与非齐次之间的转换并不构成影响
- 此处也没有涉及旋转转换
-
为什么不直接将像素坐标系转换为世界坐标系?
- 因为这一阶段的转化只涉及同一帧图片两个坐标系之间坐标的转化,而不涉及选定世界坐标系的问题,当我们需要在两帧图像直接进行转换计算时,我们才需要选定世界坐标系,因为不同的世界坐标系对应不同的结果
这时我们将\(P_{c_1}\)和\(P_{c_2}\)两个坐标连接起来
因为选择任意一个点作为世界坐标系原点都可以,不妨我们选择相机的初始位置\(P_{c_1}\)作为此处世界坐标系的原点\(P_w\),这样处理的话,我们就可以把世界坐标系和像素坐标系之间的关系转换为不同时刻相机坐标系之间的计算
- 为何此处用\(R,t\)参与计算而不使用\(T\)
- 因为此处已经不是齐次坐标系,而是两个普通的坐标
- 如果要使用\(T\),则需要对\(P_{c_1},P_{c_2}\)增加一维变成齐次坐标,同时其他的转换矩阵都需要进行变换
上述关系式中将\(P_{c_1},P_{c_2}\)分别用\(p_1,p_2\)表示代入后可得
两边同时乘\(t^{\wedge}\),\(t^{\wedge}\)是反对称符号\(a=[a_1,a_2,a_3],a^{\wedge}=A=\begin{pmatrix}0&-a_3&a_2\\a_3&0&-a_1\\-a_2&a_1&0\end{pmatrix}\),\(a^{\wedge}\cdot b=a\times b,可以用右手定则确定结果,四指方向为a\rightarrow b,大拇指方向为结果向量方向\)
因为\(t^{\wedge }t=0\),所以消去得
两边同乘\((K^{-1}p_2)^T\)
因为\(t^{\wedge}p_2\)得到的向量垂直于\(t^{\wedge}\)和\(p_2\),所以\(t^{\wedge}p_2(K^{-1}p_2)^T=0\)
本质矩阵E
\(P_1\)是为物体\(P\)在\(O_1\)相机坐标系的位置,\(P_2\)是为物体\(P\)在\(O_2\)相机坐标系的位置,\(O_2\)相对于\(O_1\)的旋转矩阵为\(R\),位移为\(T\),则\(P_2=R(P_1-T)\),由于\(R\)为正交矩阵,可以改写成\((P_1-T)=R^TP_2\)。由于\(O_1P_1,O_1O_2,O_2P_2\)三个向量共面,所以混合积为0,即\((P_1-T)^T\cdot T\times P_1=(R^TP_2)^T\cdot T\times P_1=0\\P^T_2R\cdot (T\times P_1)=0\)
将叉乘写成矩阵相乘形式:
令\(S=\begin{bmatrix} 0&-T_z&T_y\\ T_z&0&-T_x\\ -T_y&T_x&0\end{bmatrix}\),\(S\)是一个秩为2的矩阵,则\(P^T_2RSP_1=0\)
显然,\(P_1,P_2\)可以通过矩阵\(E=RS\)来约束,我们称\(E\)为本质约束矩阵(Essential Matrix),其具有两个性质:
- 秩为2
- 只依赖于外部参数\(R,T\)
基础矩阵
由本质矩阵可知
此处\(p_1,p_2\)是在单位距离坐标系下的位置,如果我们想要分析图像,则需要转到像素坐标系下:
从而有
我们称矩阵\(F\)为基础矩阵\(F=M_2^{-T}RSM^{-1}_1\),性质为:
- 秩为2
- 依赖于相机内参和外部参数\(R,T\)
特征点共面——计算单应矩阵
所以最终2D-2D问题转化为:根据匹配点的像素坐标,求出\(E\ or\ F\)或者\(H\),然后求出\(R\ or\ t\)
存在的问题
-
尺度不确定性
-
用上面的方法估计出的相机平移向量t的值并没有单位,也就是说相机移动的距离只有相对值,没有绝对值,即齐次方程存在多解情况。这是单目相机固有的尺度不确定性问题,无法从根本上解决。
因此单目SLAM中一般把初始化后的t归一化,即把初始化时移动的距离默认为1,此后的距离都以这个1为单位。
-
-
初始化的纯旋转问题
- 单目初始化不能只有旋转,必须要有一定程度的平移,否则由于t趋近于0,导致无从求解R或者误差非常大。
- 估计出来的\(t\)是两帧之间的相机位移,其范数就是位移的长度,举例说明:如果向前2米,再向右1米,向后1米,向左1米,实际的轨迹应该是个英文字母"P",但是是纯2D-2D的VO的话,t的范数都为1,画出的轨迹会是一个"口"字。所以如果是纯2D-2D的VO,画出的轨迹是不对的(即使整体乘以一个scale也不行,除非知道每一步的t的范数/长度),所以要正确的画出轨迹,必须要这样:第一第二帧用2D-2D,然后三角化得到3D点,后续帧通过3D-2D进行位姿估计,这样画出的轨迹整体与现实差一个比例scale,只需要对第一帧的t乘以某个scale,就可以得到跟现实一比一的轨迹,这应该这就是初始化的一种具体操作方式。
-
多于8对点的情况
- 如果匹配的点对数多于8(大多数情况都是这样),可以考虑充分利用这些点,而不是只从中选择8对用于计算。推荐的算法是随机采样一致性(Random Sample Consensus,RANSAC),该算法可以有效地避免错误数据对整体结果的影响。在代码中,只需要将
findFundamentalMat函数的第三个参数从CV_FM_8POINT换成CV_FM_RANSAC就可以了。
- 如果匹配的点对数多于8(大多数情况都是这样),可以考虑充分利用这些点,而不是只从中选择8对用于计算。推荐的算法是随机采样一致性(Random Sample Consensus,RANSAC),该算法可以有效地避免错误数据对整体结果的影响。在代码中,只需要将
代码
#include <iostream>
#include <opencv2/core/core.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/calib3d/calib3d.hpp>
// #include "extra.h" // use this if in OpenCV2
using namespace std;
using namespace cv;
/****************************************************
* 本程序演示了如何使用2D-2D的特征匹配估计相机运动
* **************************************************/
void find_feature_matches (
const Mat& img_1, const Mat& img_2,
std::vector<KeyPoint>& keypoints_1,
std::vector<KeyPoint>& keypoints_2,
std::vector< DMatch >& matches );
void pose_estimation_2d2d (
std::vector<KeyPoint> keypoints_1,
std::vector<KeyPoint> keypoints_2,
std::vector< DMatch > matches,
Mat& R, Mat& t );
// 像素坐标转相机归一化坐标
Point2d pixel2cam ( const Point2d& p, const Mat& K );
int main ( int argc, char** argv )
{
if ( argc != 3 )
{
cout<<"usage: pose_estimation_2d2d img1 img2"<<endl;
return 1;
}
//-- 读取图像
Mat img_1 = imread ( argv[1], CV_LOAD_IMAGE_COLOR );
Mat img_2 = imread ( argv[2], CV_LOAD_IMAGE_COLOR );
//定义从图一和图二中获取的关键点
vector<KeyPoint> keypoints_1, keypoints_2;
//定义匹配关系
vector<DMatch> matches;
//将上述参数输入函数来获得特征点匹配
find_feature_matches ( img_1, img_2, keypoints_1, keypoints_2, matches );
cout<<"一共找到了"<<matches.size() <<"组匹配点"<<endl;
//-- 估计两张图像间运动
//定义了R和t
Mat R,t;
pose_estimation_2d2d ( keypoints_1, keypoints_2, matches, R, t );
//-- 验证E=t^R*scale
Mat t_x = ( Mat_<double> ( 3,3 ) <<
0, -t.at<double> ( 2,0 ), t.at<double> ( 1,0 ),
t.at<double> ( 2,0 ), 0, -t.at<double> ( 0,0 ),
-t.at<double> ( 1,0 ), t.at<double> ( 0,0 ), 0 );
cout<<"t^R="<<endl<<t_x*R<<endl;
//-- 验证对极约束
Mat K = ( Mat_<double> ( 3,3 ) << 520.9, 0, 325.1, 0, 521.0, 249.7, 0, 0, 1 );
for ( DMatch m: matches )
{
Point2d pt1 = pixel2cam ( keypoints_1[ m.queryIdx ].pt, K );
Mat y1 = ( Mat_<double> ( 3,1 ) << pt1.x, pt1.y, 1 );
Point2d pt2 = pixel2cam ( keypoints_2[ m.trainIdx ].pt, K );
Mat y2 = ( Mat_<double> ( 3,1 ) << pt2.x, pt2.y, 1 );
Mat d = y2.t() * t_x * R * y1;
cout << "epipolar constraint = " << d << endl;
}
return 0;
}
void find_feature_matches ( const Mat& img_1, const Mat& img_2,
std::vector<KeyPoint>& keypoints_1,
std::vector<KeyPoint>& keypoints_2,
std::vector< DMatch >& matches )
{
//-- 初始化
Mat descriptors_1, descriptors_2;
// used in OpenCV3
//创建ORB
Ptr<FeatureDetector> detector = ORB::create();
//创建ORB的描述子
Ptr<DescriptorExtractor> descriptor = ORB::create();
// use this if you are in OpenCV2
// Ptr<FeatureDetector> detector = FeatureDetector::create ( "ORB" );
// Ptr<DescriptorExtractor> descriptor = DescriptorExtractor::create ( "ORB" );
//匹配
Ptr<DescriptorMatcher> matcher = DescriptorMatcher::create ( "BruteForce-Hamming" );
//-- 第一步:检测 Oriented FAST 角点位置
detector->detect ( img_1,keypoints_1 );
detector->detect ( img_2,keypoints_2 );
//-- 第二步:根据角点位置计算 BRIEF 描述子
descriptor->compute ( img_1, keypoints_1, descriptors_1 );
descriptor->compute ( img_2, keypoints_2, descriptors_2 );
//-- 第三步:对两幅图像中的BRIEF描述子进行匹配,使用 Hamming 距离
vector<DMatch> match;
//BFMatcher matcher ( NORM_HAMMING );
matcher->match ( descriptors_1, descriptors_2, match );
//-- 第四步:匹配点对筛选
double min_dist=10000, max_dist=0;
//找出所有匹配之间的最小距离和最大距离, 即是最相似的和最不相似的两组点之间的距离
for ( int i = 0; i < descriptors_1.rows; i++ )
{
double dist = match[i].distance;
if ( dist < min_dist ) min_dist = dist;
if ( dist > max_dist ) max_dist = dist;
}
printf ( "-- Max dist : %f \n", max_dist );
printf ( "-- Min dist : %f \n", min_dist );
//当描述子之间的距离大于两倍的最小距离时,即认为匹配有误.但有时候最小距离会非常小,设置一个经验值30作为下限.
for ( int i = 0; i < descriptors_1.rows; i++ )
{
if ( match[i].distance <= max ( 2*min_dist, 30.0 ) )
{
matches.push_back ( match[i] );
}
}
}
Point2d pixel2cam ( const Point2d& p, const Mat& K )
{
return Point2d
(
( p.x - K.at<double> ( 0,2 ) ) / K.at<double> ( 0,0 ),
( p.y - K.at<double> ( 1,2 ) ) / K.at<double> ( 1,1 )
);
}
void pose_estimation_2d2d ( std::vector<KeyPoint> keypoints_1,
std::vector<KeyPoint> keypoints_2,
std::vector< DMatch > matches,
Mat& R, Mat& t )
{
// 相机内参,TUM Freiburg2
Mat K = ( Mat_<double> ( 3,3 ) << 520.9, 0, 325.1, 0, 521.0, 249.7, 0, 0, 1 );
//-- 把匹配点转换为vector<Point2f>的形式
vector<Point2f> points1;
vector<Point2f> points2;
for ( int i = 0; i < ( int ) matches.size(); i++ )
{
points1.push_back ( keypoints_1[matches[i].queryIdx].pt );
points2.push_back ( keypoints_2[matches[i].trainIdx].pt );
}
//-- 计算基础矩阵
Mat fundamental_matrix;
fundamental_matrix = findFundamentalMat ( points1, points2, CV_FM_8POINT );
cout<<"fundamental_matrix is "<<endl<< fundamental_matrix<<endl;
//-- 计算本质矩阵
//定义相机内参
Point2d principal_point ( 325.1, 249.7 ); //相机光心, TUM dataset标定值
double focal_length = 521; //相机焦距, TUM dataset标定值
Mat essential_matrix;
essential_matrix = findEssentialMat ( points1, points2, focal_length, principal_point );
cout<<"essential_matrix is "<<endl<< essential_matrix<<endl;
//-- 计算单应矩阵
Mat homography_matrix;
homography_matrix = findHomography ( points1, points2, RANSAC, 3 );
cout<<"homography_matrix is "<<endl<<homography_matrix<<endl;
//-- 从本质矩阵中恢复旋转和平移信息.
recoverPose ( essential_matrix, points1, points2, R, t, focal_length, principal_point );
cout<<"R is "<<endl<<R<<endl;
cout<<"t is "<<endl<<t<<endl;
}
3D-2D(PnP)
PnP(Perspective-n-Point):当知道n个3D空间点及其投影位置时,估计相机位姿。
2D-2D的对极几何方法需要八个或八个以上的点对(以八点法为例),且存在着初始化、纯旋转和尺度的问题。然而,如果两张图像中,其中一张特征点的 3D 位置已知(特征点的 3D 位置可以由三角化,或者由 RGB-D 相机的深度图确定)。那么最少只需三个点对(需要至少一个额外点验证结果)就可以估计相机运动。
因此,在双目或 RGB-D 的视觉里程计中,我们可以直接使用 PnP 估计相机运动。
而在单目视觉里程计中,必须先进行初始化,然后才能使用 PnP。
3D-2D 方法不需要使用对极约束,又可以在很少的匹配点中获得较好的运动估计,是最重要的一种姿态估计方法。
PnP有多种方法求解:直线线性变换(DLT)、P3P还有非线性方法,构建最小二乘问题并迭代求解(Bundle Adjustment)。
DLT(直接线性方法)
已知条件: 每个特征点的像素坐标;两张图像之间的特征点的匹配关系;相机内参;第一张图片的深度信息\(z_c\)
求解:相机的R和t
因为要求解\(R,t\),所以需要利用世界坐标系和相机坐标系的关系,而世界坐标系可以用相机的初始位置表示
代码
#include <iostream>
#include <opencv2/core/core.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/calib3d/calib3d.hpp>
#include <Eigen/Core>
#include <Eigen/Geometry>
#include <g2o/core/base_vertex.h>
#include <g2o/core/base_unary_edge.h>
#include <g2o/core/block_solver.h>
#include <g2o/core/optimization_algorithm_levenberg.h>
#include <g2o/solvers/csparse/linear_solver_csparse.h>
#include <g2o/types/sba/types_six_dof_expmap.h>
#include <chrono>
using namespace std;
using namespace cv;
void find_feature_matches (
const Mat& img_1, const Mat& img_2,
std::vector<KeyPoint>& keypoints_1,
std::vector<KeyPoint>& keypoints_2,
std::vector< DMatch >& matches );
// 像素坐标转相机归一化坐标
Point2d pixel2cam ( const Point2d& p, const Mat& K );
void bundleAdjustment (
const vector<Point3f> points_3d,
const vector<Point2f> points_2d,
const Mat& K,
Mat& R, Mat& t
);
int main ( int argc, char** argv )
{
if ( argc != 5 )
{
cout<<"usage: pose_estimation_3d2d img1 img2 depth1 depth2"<<endl;
return 1;
}
//-- 读取图像
Mat img_1 = imread ( argv[1], CV_LOAD_IMAGE_COLOR );
Mat img_2 = imread ( argv[2], CV_LOAD_IMAGE_COLOR );
vector<KeyPoint> keypoints_1, keypoints_2;
vector<DMatch> matches;
find_feature_matches ( img_1, img_2, keypoints_1, keypoints_2, matches );
cout<<"一共找到了"<<matches.size() <<"组匹配点"<<endl;//特征匹配
// 建立3D点
Mat d1 = imread ( argv[3], CV_LOAD_IMAGE_UNCHANGED ); // 深度图为16位无符号数,单通道图像
Mat K = ( Mat_<double> ( 3,3 ) << 520.9, 0, 325.1, 0, 521.0, 249.7, 0, 0, 1 );
vector<Point3f> pts_3d;
vector<Point2f> pts_2d;
for ( DMatch m:matches )
{
ushort d = d1.ptr<unsigned short> (int ( keypoints_1[m.queryIdx].pt.y )) [ int ( keypoints_1[m.queryIdx].pt.x ) ];
if ( d == 0 ) // bad depth
continue;
float dd = d/5000.0;
Point2d p1 = pixel2cam ( keypoints_1[m.queryIdx].pt, K );//像素转相机(第一帧图像)
pts_3d.push_back ( Point3f ( p1.x*dd, p1.y*dd, dd ) );//第一帧图像(可以理解为世界坐标系)
pts_2d.push_back ( keypoints_2[m.trainIdx].pt );//第二帧图像
//对于第一张图片而言,那些已经匹配好的点不仅仅具备2D信息(像素坐标系),还具备距离信息(转成3D)(相机坐标系)
}
cout<<"3d-2d pairs: "<<pts_3d.size() <<endl;
Mat r, t;
solvePnP ( pts_3d, pts_2d, K, Mat(), r, t, false ); // 调用OpenCV 的 PnP 求解,可选择EPNP,DLS等方法
//用第一帧图像的相机坐标系(世界坐标系)和第二帧的像素坐标系
Mat R;
cv::Rodrigues ( r, R ); // r为旋转向量形式,用Rodrigues公式转换为矩阵
cout<<"R="<<endl<<R<<endl;
cout<<"t="<<endl<<t<<endl;
cout<<"calling bundle adjustment"<<endl;
bundleAdjustment ( pts_3d, pts_2d, K, R, t );
}
void find_feature_matches ( const Mat& img_1, const Mat& img_2,
std::vector<KeyPoint>& keypoints_1,
std::vector<KeyPoint>& keypoints_2,
std::vector< DMatch >& matches )
{
//-- 初始化
Mat descriptors_1, descriptors_2;
// used in OpenCV3
Ptr<FeatureDetector> detector = ORB::create();
Ptr<DescriptorExtractor> descriptor = ORB::create();
// use this if you are in OpenCV2
// Ptr<FeatureDetector> detector = FeatureDetector::create ( "ORB" );
// Ptr<DescriptorExtractor> descriptor = DescriptorExtractor::create ( "ORB" );
Ptr<DescriptorMatcher> matcher = DescriptorMatcher::create ( "BruteForce-Hamming" );
//-- 第一步:检测 Oriented FAST 角点位置
detector->detect ( img_1,keypoints_1 );
detector->detect ( img_2,keypoints_2 );
//-- 第二步:根据角点位置计算 BRIEF 描述子
descriptor->compute ( img_1, keypoints_1, descriptors_1 );
descriptor->compute ( img_2, keypoints_2, descriptors_2 );
//-- 第三步:对两幅图像中的BRIEF描述子进行匹配,使用 Hamming 距离
vector<DMatch> match;
// BFMatcher matcher ( NORM_HAMMING );
matcher->match ( descriptors_1, descriptors_2, match );
//-- 第四步:匹配点对筛选
double min_dist=10000, max_dist=0;
//找出所有匹配之间的最小距离和最大距离, 即是最相似的和最不相似的两组点之间的距离
for ( int i = 0; i < descriptors_1.rows; i++ )
{
double dist = match[i].distance;
if ( dist < min_dist ) min_dist = dist;
if ( dist > max_dist ) max_dist = dist;
}
printf ( "-- Max dist : %f \n", max_dist );
printf ( "-- Min dist : %f \n", min_dist );
//当描述子之间的距离大于两倍的最小距离时,即认为匹配有误.但有时候最小距离会非常小,设置一个经验值30作为下限.
for ( int i = 0; i < descriptors_1.rows; i++ )
{
if ( match[i].distance <= max ( 2*min_dist, 30.0 ) )
{
matches.push_back ( match[i] );
}
}
}
Point2d pixel2cam ( const Point2d& p, const Mat& K )
{
return Point2d
(
( p.x - K.at<double> ( 0,2 ) ) / K.at<double> ( 0,0 ),
( p.y - K.at<double> ( 1,2 ) ) / K.at<double> ( 1,1 )
);
}
void bundleAdjustment (
const vector< Point3f > points_3d,
const vector< Point2f > points_2d,
const Mat& K,
Mat& R, Mat& t )
{
// 初始化g2o
typedef g2o::BlockSolver< g2o::BlockSolverTraits<6,3> > Block; // pose 维度为 6, landmark 维度为 3
Block::LinearSolverType* linearSolver = new g2o::LinearSolverCSparse<Block::PoseMatrixType>(); // 线性方程求解器
Block* solver_ptr = new Block ( linearSolver ); // 矩阵块求解器
g2o::OptimizationAlgorithmLevenberg* solver = new g2o::OptimizationAlgorithmLevenberg ( solver_ptr );
g2o::SparseOptimizer optimizer;
optimizer.setAlgorithm ( solver );
// vertex
g2o::VertexSE3Expmap* pose = new g2o::VertexSE3Expmap(); // camera pose
Eigen::Matrix3d R_mat;
R_mat <<
R.at<double> ( 0,0 ), R.at<double> ( 0,1 ), R.at<double> ( 0,2 ),
R.at<double> ( 1,0 ), R.at<double> ( 1,1 ), R.at<double> ( 1,2 ),
R.at<double> ( 2,0 ), R.at<double> ( 2,1 ), R.at<double> ( 2,2 );
pose->setId ( 0 );
pose->setEstimate ( g2o::SE3Quat (
R_mat,
Eigen::Vector3d ( t.at<double> ( 0,0 ), t.at<double> ( 1,0 ), t.at<double> ( 2,0 ) )
) );
optimizer.addVertex ( pose );
int index = 1;
for ( const Point3f p:points_3d ) // landmarks
{
g2o::VertexSBAPointXYZ* point = new g2o::VertexSBAPointXYZ();
point->setId ( index++ );
point->setEstimate ( Eigen::Vector3d ( p.x, p.y, p.z ) );
point->setMarginalized ( true ); // g2o 中必须设置 marg 参见第十讲内容
optimizer.addVertex ( point );
}
// parameter: camera intrinsics
g2o::CameraParameters* camera = new g2o::CameraParameters (
K.at<double> ( 0,0 ), Eigen::Vector2d ( K.at<double> ( 0,2 ), K.at<double> ( 1,2 ) ), 0
);
camera->setId ( 0 );
optimizer.addParameter ( camera );
// edges
index = 1;
for ( const Point2f p:points_2d )
{
g2o::EdgeProjectXYZ2UV* edge = new g2o::EdgeProjectXYZ2UV();
edge->setId ( index );
edge->setVertex ( 0, dynamic_cast<g2o::VertexSBAPointXYZ*> ( optimizer.vertex ( index ) ) );
edge->setVertex ( 1, pose );
edge->setMeasurement ( Eigen::Vector2d ( p.x, p.y ) );
edge->setParameterId ( 0,0 );
edge->setInformation ( Eigen::Matrix2d::Identity() );
optimizer.addEdge ( edge );
index++;
}
chrono::steady_clock::time_point t1 = chrono::steady_clock::now();
optimizer.setVerbose ( true );
optimizer.initializeOptimization();
optimizer.optimize ( 100 );
chrono::steady_clock::time_point t2 = chrono::steady_clock::now();
chrono::duration<double> time_used = chrono::duration_cast<chrono::duration<double>> ( t2-t1 );
cout<<"optimization costs time: "<<time_used.count() <<" seconds."<<endl;
cout<<endl<<"after optimization:"<<endl;
cout<<"T="<<endl<<Eigen::Isometry3d ( pose->estimate() ).matrix() <<endl;
}
P3P
已知:4个点的世界坐标,其中三个点用来求解,剩余一个点用来验证结果
求:相机的R与t
假设空间中有A,B,C三点,投影到成像平面中有a,b,c三点,在PnP问题中,A,B,C在世界坐标系下的坐标是已知的,但是在相机坐标系下的坐标是未知的。a,b,c的坐标是已知的。PnP的目的就是要求解A,B,C在相机坐标系下的坐标值。如下图所示。需要注意的是三角形abc和三角形ABC不一定是平行的。

记\(x=\frac{OA}{OC},y=\frac{OB}{OC}\),因为\(A,B,C\)在相机坐标系中的坐标未知,因此\(x,y\)是未知的。另记\(u=\frac{BC^2}{AB^2},w=\frac{AC}{AB}\),根据\(A,B,C\)的世界坐标,\(u,w\)是可以求出
通过一系列的转化可以得到两个等式:
该方程组是关于x,y的一个二元二次方程,可以通过吴消元法求解。最多可能得到四个解,因此在三个点之外还需要一组匹配点进行验证。
至此,通过x和y就可以求得A,B,C在相机坐标下的坐标值。因此3D-2D问题转变成了3D-3D的位姿估计问题。而带有匹配信息的3D-3D位姿求解非常容易。
Bundle Adjustment
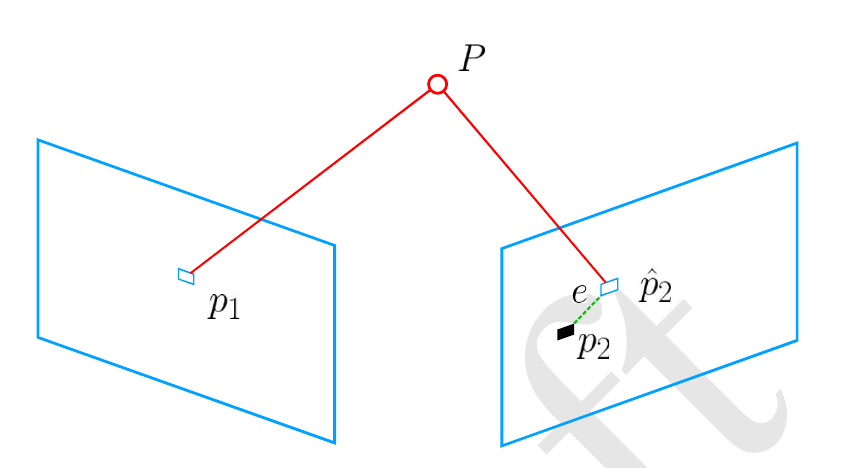
首先我们通过上述的DLT方法得到了R和t,但是想要更加精确的结果,于是可以通过第一帧的相机坐标系结合之前求出的R和t求出第二帧的相机坐标,再根据第二帧的相机坐标求解出像素坐标,最后用所得像素坐标与真正的第二帧相机观测到的像素坐标做差值,并希望以此来尽可能优化R和t:
\(p_2\)代表摄像头实际采集到的像素位置,\(\hat{p_2}\)代表通过R,t变换之后得到的像素位置
非线性优化(非线性最小二乘)
问题:已知\(z\),求\(x={x_1,...,x_N,y_1,...,y_M}\),即N个位姿(N帧图像),M个点的世界坐标(每张图中有几个特征点)
因为求解过程中有误差,所以需要应用采用概率模型处理误差 ,此时我们引入贝叶斯法则\(\overset{后验}{p(x|z)}=\frac{\overset{似然}{P(z|x)}\overset{先验}{P(x)}}{P(z)}\propto P(z|x)P(x)\)
如果要求解则有两种方法:
-
最大后验估计(Maximize a Posterior,MAP)
\[x^*MAP=argmax\overset{后验}{p(x|z)}=argmax\overset{似然}{P(z|x)}\overset{先验}{P(x)} \]就是估计当后验最大时,x的值取多少,我们可以使用贝叶斯法则将其转化为似然和先验的形式。
因为此问题中我们不知道先验概率,所以我们采用下面的方法
-
最大似然估计(Maximize Likelihood Estimation,MLE)
\[x^*MLE=argmaxP(z|x) \]我们只使用似然概率进行计算,即在哪种状态下,最容易产生当前的观测
我们假定\(P(x)\)的分布为高斯分布:
-
一般的高斯分布
\[P(x)=\frac{1}{\sqrt{(2\pi})^Ndet(\Sigma)}exp(-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu)) \]因为我们要寻找\(P(x)\)的极值,可以将高斯分布转换为负对数形式
-
负对数形式
\[-ln(P(x))=\frac{1}{2}ln((2\pi)^Ndet(\Sigma))+\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu) \]
则某次观测的数学形式表达可以写成
其中:
- \(z\)表示特征点的像素坐标 (观测,已知)
- \(x\)表示特征点的世界坐标 (状态,未知)
- \(y\)表示相机在每个时刻的位姿 (状态,未知)
- \(v\)表示高斯噪声 \(v_K\sim N(0,Q_{k,j})\)
我们把这个式子写成高斯分布的形式:
根据这个等式可以构造出一个最小二乘问题:
该问题的误差项,是将像素坐标与3D点按照当前估计的位姿进行投影得到的位置相比较得到的误差,所以称之为重投影误差。
这个最小二乘问题主要就是使得重投影误差最小以得到最佳的位姿和世界坐标
当然我们讨论的上述问题和方法都是基于线性方法,对于非线性问题我们需要对其进行线性近似。
首先我们将最小二乘问题转化为以下形式:
对\(x\)增加一个扰动增量\(\bigtriangleup x\)可得
对\(e(x+\bigtriangleup x)\)进行线性近似\(\rightarrow \overset{泰勒展开}{e(x)+J\bigtriangleup x}\)
只要\(\bigtriangleup E\)取最小值即可,我们对其求偏导以得到极值点
所以非线性优化的算法步骤如下:
- 给定初始值\(x_0\)
- 对于第\(k\)次迭代,求出当前的雅可比矩阵\(J(x_k)\)和误差\(f(x_k)\)
- 求解增量方程:\(H\bigtriangleup x_k=g\)
- 若\(\bigtriangleup x_k\)足够小,则停止。否则,令\(x_{k+1}=x_k+\bigtriangleup x_k\),返回步骤2
但是这种算法容易陷入局部最优化,因为可能会有多个极值点
下面回到我们的实际问题中来看:
对应着\(e=z-h(x,y)\rightarrow z-h(x)\),之后我们按部就班对其进行线性近似
对\(e(\xi \oplus \delta \xi)\)进行线性近似\(\rightarrow e(\xi) +J \delta \xi\)
此处需要引入李群和李代数的知识
为什么要引入李群和李代数的概念?
我们想要求最小误差\(e\),最基本的思路就是\(e\)对\(T\)求导,求极值。我们可以知道的是\(T\)对于乘法封闭,但是对于加法不封闭。微分的基本原理\(x=\delta(x)\), 如果一个数群加法不封闭,即做完加法后不能保证结构在该群类,微分运算没有意义。
因此我们想能否利用指数和对数变换将乘法运算变换为加法运算呢?答案是可以的!因此我们使用李群和李代数的性质来转换上述的封闭性转换。
李群和李代数
引入李群李代数的意义:
- 因为在欧式变换矩阵上不好定义导数,引入李群李代数使得导数定义变得自然合理
- 本来旋转矩阵与欧式变换矩阵具有本身的约束,使得将它们作为优化变量会引入额外约束,通过李群李代数可以使得问题变成一个无约束的优化问题
我们再复习一下反对称符号\(\wedge\)
那么李群上做乘法能否等于李代数上做加法?即:
答案是可以的,我们可以使用对数映射转化为李代数的加法,然后再用指数映射将结果转换回来,即:
下面我们来展示转换过程:
因为我们要处理的是矩阵,所以\(exp(\phi^{\wedge}_1)exp(\phi^{\wedge}_2)=exp((\phi_1+\phi_2)^{\wedge})\)在指数映射时是不满足的,如果公式中\(\phi^{\wedge}_1\)是标量的话是成立的。为了处理矩阵对应的公式我们需要使用BCH(Baker-Campbell-Hausdorff)公式
\(J_l\)即\(\mathfrak{se}(3)\)到\(SE(3)\)转换时求得的\(J\),称为左乘近似雅可比
如果上面的结果反过来,在李代数上做加法,则有:
基于李代数对姿态求导
我们想求的是旋转后的点关于旋转的导数\(\frac{\partial(Rp)}{\partial R}=\lim_{\bigtriangleup R \to 0}\frac{(R+\bigtriangleup R)P-RP}{\bigtriangleup R}\)
如果我们把\(p\)看做是相机坐标系,\(Rp\)是世界坐标系即上述公式可以理解成用世界坐标系来对旋转矩阵求导
但是\(R+\bigtriangleup R\)不再是旋转矩阵了,我们需要另想办法。
存在两种模型,其中因为扰动模型形式简单,所以经常被使用:
-
利用BCH公式的微分模型求导——\(SO(3)\)李代数上的微分模型
-
用李代数(旋转向量)表示姿态,然后根据李代数加法来对李代数求导。即传统求导的思路,把增量直接定义在旋转矩阵R对应的李代数上,求相对于增量的变化率
\[\underbrace{\frac{\partial(exp(\phi^{\wedge})p)}{\partial \phi}}_{旋转矩阵对旋转向量求导}=\lim_{\partial \phi \to 0}\frac{exp((\phi+\delta \phi)^{\wedge})p-exp(\phi^{\wedge})p}{\delta \phi} \\ =\lim_{\partial \phi \to 0}\frac{exp((J_l\delta \phi)^{\wedge})exp(\phi^{\wedge})p-exp(\phi^{\wedge})p}{\delta \phi}(BCH线性近似) \\ \approx \lim_{\partial \phi \to 0}\frac{(I+(J_l\delta \phi)^{\wedge})exp(\phi^{\wedge})p-exp(\phi^{\wedge})p}{\delta \phi} (泰勒展开舍去高阶项后近似)\\ =\lim_{\partial \phi \to 0}\frac{(J_l\delta \phi)^{\wedge}exp(\phi^{\wedge})p}{\delta \phi} (将反对称符号看做叉积,交换之后变号) \\=\lim_{\partial \phi \to 0}\frac{-(exp(\phi^{\wedge})p)^{\wedge}J_l\partial \phi}{\delta \phi}\\=-(Rp)^{\wedge}J_1\\\ (最后一步将exp(x)近似为1+x,得到\delta \phi^{\wedge},利用交换定理变为\delta \phi,Rp取负反对称矩阵,上下的\delta \phi相消) \]最终可得旋转后的点相对于李代数的导数:\(\frac{\partial(Rp)}{\partial \phi}=-(Rp)^{\wedge}J_l\)
-
-
扰动模型求导——\(SO(3)\)李代数上的扰动模型(左扰动)
-
把增量扰动直接添加在李群(旋转矩阵R)上,然后使用李代数表示此扰动,对\(R\)左乘或者右乘一个扰动,求相对于扰动增量的李代数的变化率
此处为左乘扰动模型,右乘模型的结果会有一点微小的差异
设左扰动\(\bigtriangleup R\)对应的李代数为\(\varphi\),对\(\varphi\)求导
\[\frac{\partial(Rp)}{\partial \varphi }=lim_{\varphi \to 0}\frac{exp(\varphi ^{\wedge})exp(\phi ^{\wedge})p-exp(\varphi ^{\wedge})p}{\varphi }\\\approx lim_{\varphi \to 0}\frac{(1+\varphi ^{\wedge})exp(\phi ^{\wedge})p-exp(\varphi ^{\wedge})p}{\varphi }\\=lim_{\varphi \to 0}\frac{\varphi^{\wedge}Rp}{\varphi}\\=lim_{\varphi \to 0}\frac{-(Rp)^{\wedge}\varphi}{\varphi}\\-(Rp)^{\wedge} \]可见扰动模型相比于直接对李代数求导,省去了一个雅可比\(J_l\)的计算量,这使得扰动模型更为实用
-
-
\(SE(3)\)上的扰动模型
-
含义是:考虑一个空间点\(P\)(需要是齐次坐标,否则维数不对),受到刚体变换\(T\),得到\(TP\)。
-
求解\(TP\)如何随着\(T\)变化
\[\frac{\partial(TP)}{\partial T}=\lim_{\delta \xi \to 0}\frac{exp((\delta\xi)^{\wedge})TP-TP}{\delta\xi}\\=(TP)^\odot \]其中\(\odot\)将一个\(4\times 4\)的矩阵变成\(4\times 6\)的矩阵
假设如下求导中左乘的扰动项的李代数为\(\delta\xi=[\delta\rho,\delta\phi]^T\),那么:
\[\frac{\partial(Tp)}{\partial \delta\xi}=\lim_{\delta \xi \to 0}\frac{exp(\delta\xi^{\wedge})exp(\xi^{\wedge})p-exp(\xi^{\wedge})p}{\delta\xi}\\=\lim_{\delta \xi \to 0}\frac{I+\delta\xi^{\wedge}exp(\xi^{\wedge})p-exp(\xi^{\wedge})p}{\delta\xi}\\=\lim_{\delta \xi \to 0}\frac{\delta\xi^{\wedge}exp(\xi^{\wedge})p}{\delta\xi}\\=\lim_{\delta \xi \to 0}\frac{\begin{bmatrix} \delta\phi^{\wedge} &\delta\rho \\ 0^T&0\end{bmatrix}\begin{bmatrix}Rp+t\\1\end{bmatrix}}{\delta\xi}\\=\lim_{\delta \xi \to 0}\frac{\begin{bmatrix}\delta\phi^{\wedge}(Rp+t)+\delta\rho\\0^T\end{bmatrix}}{[\delta\rho,\delta\phi]^T}\\=\begin{bmatrix}I&-(Rp+t)^{\wedge}\\0^T&0^T\end{bmatrix}\\\overset{\bigtriangleup }{=}(Tp)^\odot\]注:此处的\(p\)是相机坐标系的坐标
上面最后一行矩阵除法,与矩阵乘法规则类似,只是乘号变成了除号。其使用一个4×1矩阵除以一个1×6矩阵得到一个4×6矩阵
-
回到BA问题
在了解完李群和李代数的相关知识后,我们再来回顾一下我们想要解决的问题
我们想要求将像素坐标与3D点按照当前估计的位姿进行投影得到的位置相比较得到的最小误差\(e\),最基本的思路就是\(e\)对\(T\)求导,求极值。
因此我们利用最小二乘法处理非线性优化的问题,我们将问题代入下列模型中:
对\(x\)增加一个扰动增量\(\bigtriangleup x\)可得
对\(e(x+\bigtriangleup x)\)进行线性近似\(\rightarrow \overset{泰勒展开}{e(x)+J\bigtriangleup x}\)
可以得到
对\(e(\xi \oplus \delta \xi)\)进行线性近似\(\rightarrow e(\xi) +J \delta \xi\)
所以将\(e\)对我们想优化的变量\(\delta \xi(李代数)\)进行求导
上述计算使用了之前求出的\(SE(3)\)上的扰动模型
注:此处的\(p\)是相机坐标系的坐标
所以\(\underset{对变换矩阵的李代数求导}{\frac{\partial P_{c_2}}{\partial\delta\xi}}=\frac{\partial T P_{c_1}}{\partial\delta\xi}=\begin{bmatrix}I&-P_{c_2}^{\wedge}\\0^T&0^T\end{bmatrix}=\begin{bmatrix}1&0&0&0&-z_{c_2}&y_{c_2} \\0&1&0&z_{c_2}&0&-x_{c_2}\\0&0&1&-y_{c_2}&x_{c_2}&0 \end{bmatrix}\)
之后我们就知道了\(J\)的值
我们最后再来回顾一下BA的算法流程
- 给定初始值\(x_0\)
- 对于第\(k\)次迭代,求出当前的雅可比矩阵\(J(x_k)\)和误差\(f(x_k)\)
- 求解增量方程:\(H\bigtriangleup x_k=g\)
- 若\(\bigtriangleup x_k\)足够小,则停止。否则,令\(x_{k+1}=x_k+\bigtriangleup x_k\),返回步骤2
在第二步中我们已经知道了雅可比矩阵\(J\),误差\(f(x_K)\)为\(-J^T\Sigma^{-1}e\),之后按算法执行即可,程序会帮我们完成。
本文来自博客园,作者:甫生,转载请注明原文链接:https://www.cnblogs.com/fusheng-rextimmy/p/15426815.html
