
强化学习详解与代码实现
强化学习详解与代码实现
本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10789375.html
目录
1.引言
2.强化学习原理
2.1 强化学习定义(RL Reinforcement Learing)
2.2 马尔科夫决策过程(MDP Markov Decision Process)
2.3 状态价值和状态-动作价值关系
2.4 贝尔曼方程(Bellman)
2.5 贝尔曼最优化方程
3. 应用实例(grid world game)
4. 解决方案
5. 代码实现与分析
6. 运行结果
7. 参考文献
1.引言
相信大家对由Google开发的AlphaGo机器人在2016年围棋对弈中击败韩国的围棋大师李世石还记忆犹新吧。
当时,个人也确实被这场人机大战的结果深深震撼并且恐惧了。震撼是因为机器人的智慧超越了人类只有在科幻大片中看到,
而今,这种故事却真真实实的发生在我们的现实中,恐惧是对未知的一种自然反应,也正是因为这种恐惧,
我们才有了去探索未知的本能,去揭开AlphaGo机器人背后技术原理的面纱。
相信大家已经猜到了AlphaGo机器运用的技术原理,不错,那就是强化学习(Reinforcement Learning)。
2.强化学习原理
2.1 强化学习定义
强化学习是一种通过交互的目标导向学习方法,旨在找到连续时间序列的最优策略。这个定义比较抽象(说实话,抽象的东西虽然简洁、准确,但是也非常难以理解)。举个容易理解的例子:
在你面前有两条路,自然就有两个不同方向,只有一条路,一个方向可以到达目的地,有个前提条件是你不知道目的地在他们当中的哪个方向?
是不是感觉很抓瞎,完全没办法。对的,如果按照这种场景,我们肯定是没办法的,但是如果给你个机会,让你在两个不同方向都去尝试一下,你是不是就知道哪一个方向是正确的。
强化学习的一个核心点就是要尝试,因为只有尝试了之后,它才能发现哪些行为会导致奖励的最大化,而当前的行为可能不仅仅会影响即时奖励,还会影响下一步的奖励以及后续的所有奖励。因为一个目标的实现,是由一步一步的行为串联实现的。
在上面的场景当中,涉及到了强化学习的几个主要因素:智能体(Agent),环境(Environment),状态(State)、动作(Action)、奖励(Reward)、策略(Policy)。
智能体(Agent):强化学习的本体,作为学习者或者决策者,上述场景是指我们自己。
环境(Environment):强化学习智能体以外的一切,主要由状态集合组成。
状态(State):一个表示环境的数据,状态集则是环境中所有可能的状态。比如,走一步就会达到一个新的状态。
动作(Action):智能体可以做出的动作,动作集则是智能体可以做出的所有动作。比如,走一步这个过程就是一个动作。
奖励(Reward):智能体在执行一个动作后,获得的正/负反馈信号,奖励集则是智能体可以获得的所有反馈信息。走正确就奖励,错误就惩罚。
策略(Policy):强化学习是从环境状态到动作的映射学习,称该映射关系为策略。通俗的理解,即智能体如何选择动作的思考过程称为策略。
第一步:智能体尝试执行了某个动作后,环境将会转换到一个新的状态,当然,对于这个新的状态,环境会给出奖励或者惩罚。
第二步:智能体根据新的状态和环境反馈的奖励或惩罚,执行新的动作,如此反复,直至到达目标。
第三步:智能体根据奖励最大值找到到达目标的最佳策略,然后根据这个策略到达目标。
要注意的是,智能体要尝试执行所有可能的动作,到达目标,最终会有所有可能动作对应所有可能状态的一张映射表(Q-table)。
这里借用知乎论坛关于强化学习各个因素关系的一幅图(https://www.zhihu.com/topic/20039099/intro)

原理我们明白了,接下来我们就来看大神如何将这些原理抽象出来,如何用数学的公式来表示的。
2.2 马尔科夫决策过程(MDP Markov Decision Process)
马尔科夫决策过程由5个因素组成:
S:状态集(states)
A:动作集(actions)
P:状态转移概率
R:即时奖励(reward)
γ:折扣系数(未来反馈的reward相比当下的重要性,在 [0,1] 之间)
决策过程: 智能体初始状态 ![]() ,选择一个动作
,选择一个动作 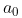 ,按概率转移矩阵
,按概率转移矩阵 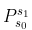 转移到下一个状态
转移到下一个状态 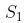 ,如此反复...
,如此反复...
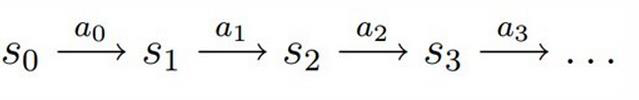
强化学习的目标:给定一个马尔科夫决策过程,寻找最优策略,最优就意味着回报最大。
策略用数学公式来定义:

它表示的是:在某个状态下一系列不同行为的概率,它是一个条件概率矩阵。
累积回报数学定义:
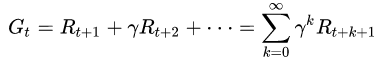
累积回报自然是一系列行为所产生回报的累加值,这是它的数学表达式, 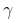 是折扣因子,从表达式可以看出
是折扣因子,从表达式可以看出 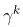
越来越小,因为后续行为的回报对当前状态的影响只会越来越弱。
因为策略是随机的,所以累积回报也是随机的,而评价状态和动作的价值,需要一个确定的值来进行描述,这样,累积回报的期望就被提出来了。

状态价值函数表示的是某个状态下一系列不同行为对应回报的期望值,而状态-动作价值函数表示的是在某个状态下,某个行为下,一系列行为产生产生回报的期望值。
那么,状态价值函数与状态-动作价值函数有什么关系呢?
2.3 状态价值和状态-动作价值关系
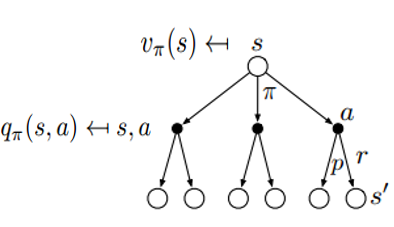
空心圆圈代表状态,实心圆圈代表状态-动作对。
状态 s 通过不同的行为到达不同的状态,我们把这个图分解一下
从 s -> (s, a) 过程,有当前状态价值 = 当前状态下,某个行为的概率与当前状态-动作价值的乘积,然后对不同的行为求和。(期望定义:概率*随机变量取值,然后求和)
从 (s, a) -> s1 过程,有当前状态-动作价值 = 即时奖励与下一个状态的价值之和
又这两个公式就能推出右边的这两个公式(相互代入),而右边这两个公式就是贝尔曼方程的基本形式。
2.4 贝尔曼方程(Bellman)
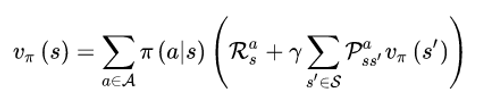
表示含义:当前状态的价值与当前的奖励以及下一个状态的价值有关。
为了加深对贝尔曼方程的理解,举一个实例。
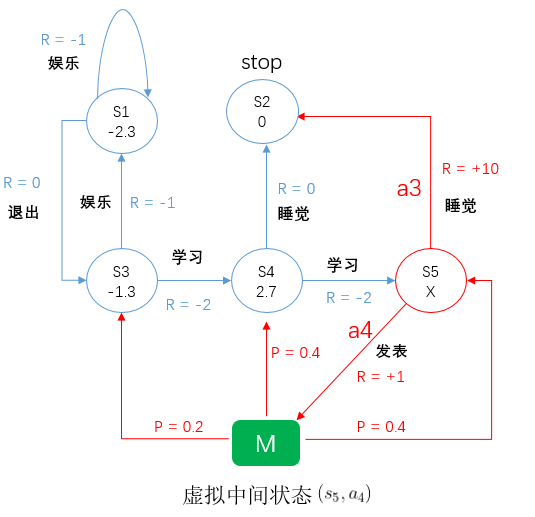
上图表示一个人一天所有的行为,规则:
椭圆:状态
椭圆内数值:状态价值
p : 转移概率
R:奖励
折扣因子 ![]()

求 S5 状态价值 X ?
由图可以看出,S5 状态有两个行为,睡觉和发表论文,而发表论文到达的不是一个确定的状态,它到达的状态可能是 S3, S4, S5。
睡觉对应的状态价值 = 它的即时奖励 ![]() + S2 的价值,因为 S2 已经终止,所以 S2 的价值为 0。
+ S2 的价值,因为 S2 已经终止,所以 S2 的价值为 0。
同样,发表行为对应的状态价值 = 它的即时奖励 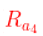 + M 状态的价值,而 M 状态价值是由 S3,S4,S5 组成的,那么发表对应的状态价值 = 即时奖励
+ M 状态的价值,而 M 状态价值是由 S3,S4,S5 组成的,那么发表对应的状态价值 = 即时奖励 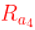
+ 转移概率 * S3 + 转移概率 * S4 + 转移概率 * S5,当然,前面还要乘上折扣因子,然后最外层再乘上 S5 状态下行为概率。
最后,将这两者的价值求和,就是 S5 状态的价值。
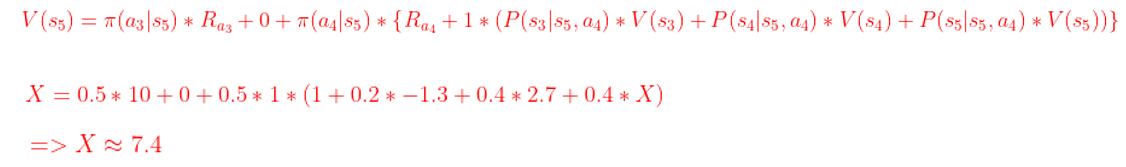
2.5 贝尔曼最优化方程
强化学习的目标就是找到一个最优的策略,使得总的回报最大。
那么,这里就有一个定理:对于任意一个马尔科夫决策过程,总是存在一个最优的策略,使得价值最大。
这也就意味着每个状态最优的行为只有一个,那么就可以将某个状态下行为的概率以及行为求和去掉,从而就能得到右边的两个表达式。
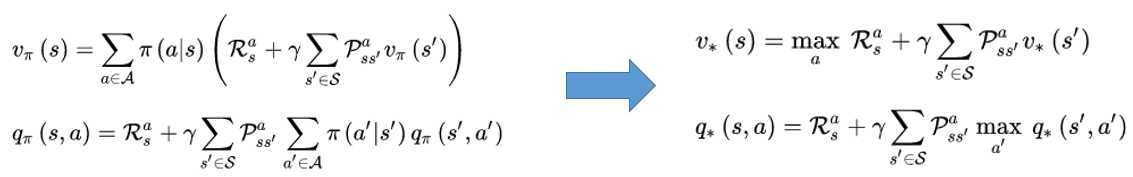
这两个表达式就是贝尔曼的最优化方程。
3. 应用实例(grid world game)
游戏规则:
这个网格有 16 个小方格,按顺序标号 0,1,2...15,0 和 15 是出口,游戏的目标是:在任意的一个小方格内,如何以最快的时间走出迷宫?
换句话说,在任意一个状态下,如何找到到达出口的最优路径?其实质就是求最优策略表。
4. 解决方案
解决这个问题采用的是 Q-Learning 学习算法,其实质是利用贝尔曼最优化方程( Q 函数)来寻找最优策略。
算法求解步骤是:
1、设定相关参数
2、令 V=0,这里的 V 对应的是 16 个状态的价值
3、从第 3 步开始,是一个循环迭代的过程,其目的就是不停的更新 Q 值。
具体步骤为:
3.1 随机选择一个初始状态;
3.2 若未达到目标状态(出口位置),就执行以下几步:
(1)在当前状态中随机选取一个行为;
(2)利用选定的行为,得到即时奖励,并转移到下一个状态;
(3)根据 Q 函数计算 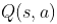 ,并更新
,并更新 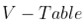 相应的值;
相应的值;
(4)更新状态 ;
4.1 具体计算过程
首先初始化 reward 表, 16 * 4 矩阵(横轴是行为,纵轴是状态),只有出口状态各个行为奖励为 0,其他状态的行为都是 -1,为简化计算,折扣因子和转移概率都设置为 1。
根据贝尔曼最优化方程,计算出每个状态的各个行为的价值,然后取最大值。
假定计算一下方格 5 的价值,方格 5 也有 4 种行为,先求出每种行为对应的价值。
方格 5 状态 0 行动的价值 = R(1,0) ,也就是 -1,加上折扣因子乘以转移概率,因为都是 1,就省略了。
0 行动对应的向上,那么它的下一个状态是方格 1,而 方格 1 也是有 4 种可能的行动,因为我们初始值都是 0,所以结果 = -1,
同样 方格 5 状态的其他行动就都能求出来了,然后取最大值,就为方格 5 状态的价值,更新 V-Table 对应位置的值,
同样,其他状态的价值也就能求出来,并同时更新 V-Table,这就得到了第一次迭代的状态价值表,然后循环迭代,
直至状态的新,旧价值差小于一个阈值,就停止,说明状态价值表已经趋于稳定,这时候得到的状态价值表,就是状态最大价值表 V-Table。

由 V-Table 就能求 Q-Table,再次利用贝尔曼最优化方程,就能得到最优策略表 Q-Table,
同样,横轴是行动,纵轴是状态,在最优策略表中,每个状态只有一个最优的行为,
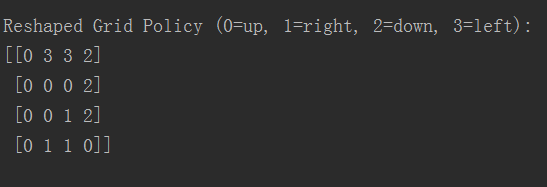
比如 方格 5 状态最优的行为是 0,而 0 表示向上,将策略表优化一下,每一行只需要最优行为对应的索引值,得到右边 4 * 4 的最优策略表。
举个例子,我们需要在状态 5 到达出口的最优策略?那么,状态 5 ,也就是 红色 0 位置,它是 0 也就是先向上,到达 1 状态,
1 状态的值是 3,也就是向左,然后到达出口,这跟我们的感受是一致的。
5. 代码实现与分析
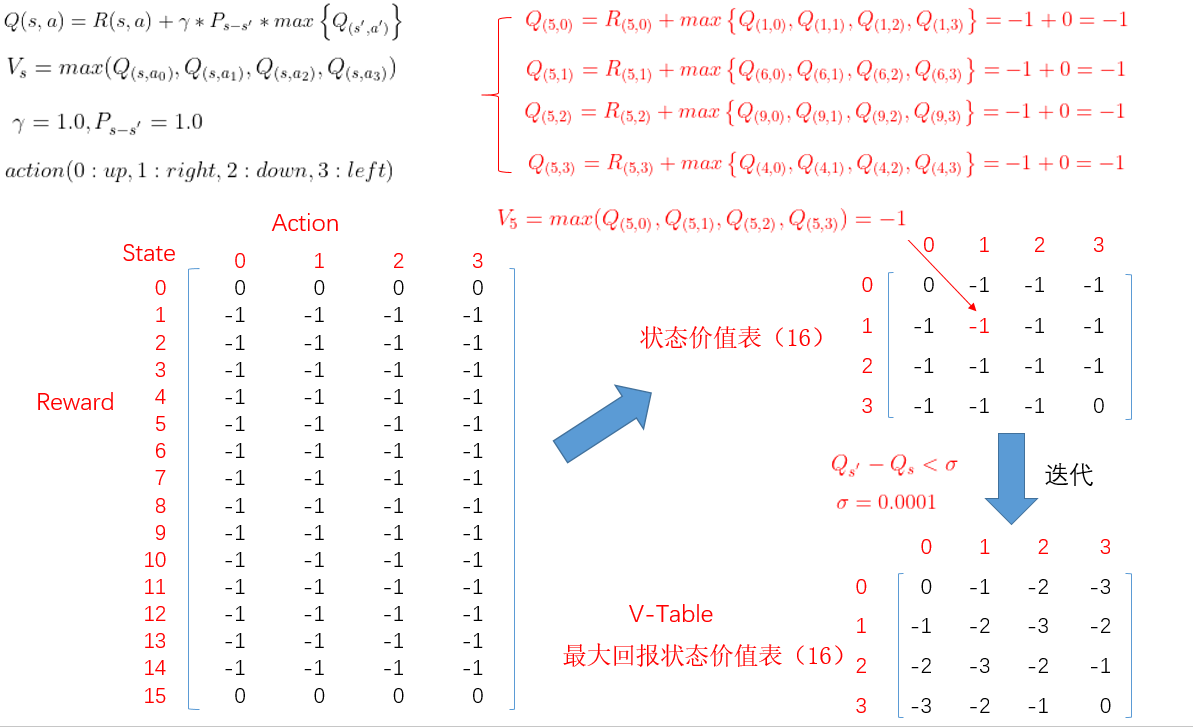
one_step_lookahead 方法是求出给定状态下,每个可能的行为的回报。利用贝尔曼方程求出的每个行为的价值,然后存放在 A 数组当中。
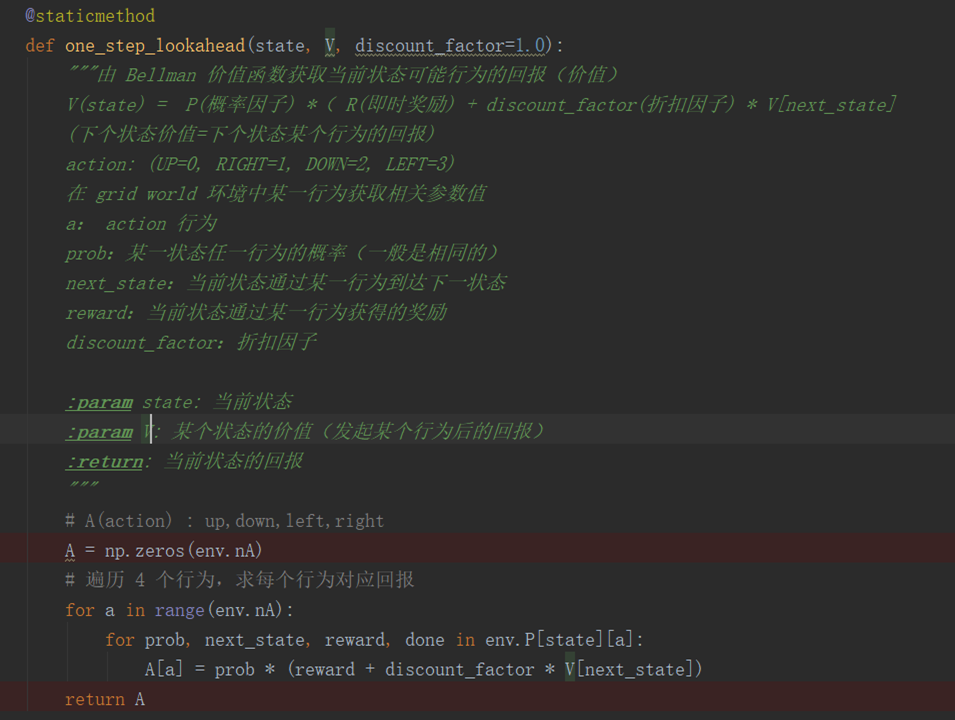
get_v_table 方法就是求每个状态对应的最大价值,也就是 V-Table。首先初始化 V 表,16个状态,然后就是循环迭代,
遍历 16 个状态,求出每个状态不同行为的价值,取最大价值作为当前状态的价值,与 V 表中对应位置价值做差,
如果差值大于设定的阈值,继续迭代,并更新 V 表中对应的值,如果小于阈值,就终止迭代。这样求得的结果就是最大回报对应的状态价值表。

得到状态最大价值表 V-Table,就能求最优策略表 Q-Table。
首先初始化策略表 16 * 4,然后还是遍历 16 个状态,将 V-Table 加载进来,获取每个状态各个行为的回报,
并求出最大回报对应的行为索引,更新策略表中状态和行为对应的值。最终得到的就是最优策略表。
6. 运行结果
完整样例代码放在百度网盘 :
链接:https://pan.baidu.com/s/1Q68Ono4sSSFpihwcEOr4aw
提取码:p5qz
每个方法都做了比较详细的注释,操作步骤见 .md 文档,感兴趣的话可以下载下来亲自体验一下。
游戏规则有16个状态(state),每个状态有4个行动方向(action),因此Q-Table大小是(16, 4),具体生成结果如下图:
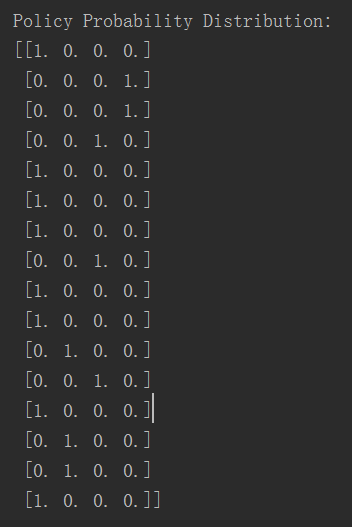
最终每个状态最佳行动方向大小(4, 4),结果为
7. 参考文献
[1] https://www.zhihu.com/topic/20039099/intro
[2] http://baijiahao.baidu.com/s?id=1597978859962737001&wfr=spider&for=pc
[3] https://applenob.github.io/gridworld.html
[4] https://leovan.me/cn/2020/05/introduction-of-reinforcement-learning/
[5] https://zhuanlan.zhihu.com/p/25498081
