


深度学习之卷积神经网络(CNN)详解与代码实现(一)
卷积神经网络(CNN)详解与代码实现
本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10430073.html
目录
1.应用场景
2.卷积神经网络结构
2.1 卷积(convelution)
2.2 Relu激活函数
2.3 池化(pool)
2.4 全连接(full connection)
2.5 损失函数(softmax_loss)
2.6 前向传播(forward propagation)
2.7 反向传播(backford propagation)
2.8 随机梯度下降(sgd_momentum)
3.代码实现流程图以及介绍
4.代码实现(python3.6)
5.运行结果以及分析
6.参考文献
1.应用场景
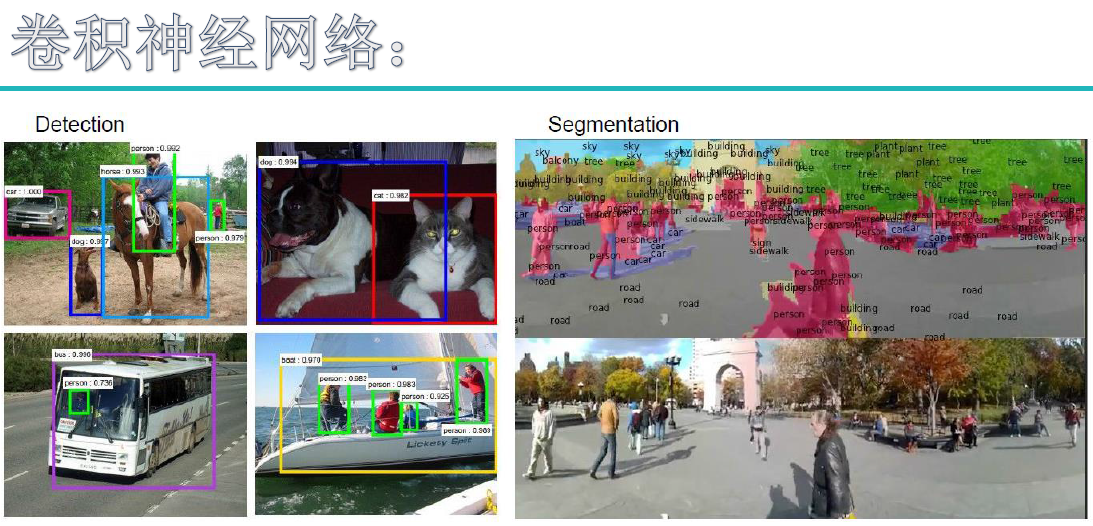
卷积神经网络的应用不可谓不广泛,主要有两大类,数据预测和图片处理。数据预测自然不需要多说,图片处理主要包含有图像分类,检测,识别,以及分割方面的应用。
图像分类:场景分类,目标分类
图像检测:显著性检测,物体检测,语义检测等等
图像识别:人脸识别,字符识别,车牌识别,行为识别,步态识别等等
图像分割:前景分割,语义分割
2.卷积神经网络结构
卷积神经网络主要是由输入层、卷积层、激活函数、池化层、全连接层、损失函数组成,表面看比较复杂,其实质就是特征提取以及决策推断。
要使特征提取尽量准确,就需要将这些网络层结构进行组合,比如经典的卷积神经网络模型AlexNet:5个卷积层+3个池化层+3个连接层结构。
2.1 卷积(convolution)
卷积的作用就是提取特征,因为一次卷积可能提取的特征比较粗糙,所以多次卷积,以及层层纵深卷积,层层提取特征(千万要区别于多次卷积,因为每一层里含有多次卷积)。
这里可能就有小伙伴问:为什么要进行层层纵深卷积,而且还要每层多次?
你可以理解为物质A有自己的多个特征(高、矮、胖、瘦、、、),所以在物质A上需要多次提取,得到不同的特征,然后这些特征组合后发生化学反应生成物质B,
而物质B又有一些新的专属于自己的特征,所以需要进一步卷积。这是我个人的理解,不对的话或者有更形象的比喻还请不吝赐教啊。

在卷积层中,每一层的卷积核是不一样的。比如AlexNet
第一层:96*11*11(96表示卷积核个数,11表示卷积核矩阵宽*高) stride(步长) = 4 pad(边界补零) = 0
第二层:256*5*5 stride(步长) = 1 pad(边界补零) = 2
第三,四层:384*3*3 stride(步长) = 1 pad(边界补零) = 1
第五层:256*3*3 stride(步长) = 1 pad(边界补零) = 2
卷积的篇幅说了这么多,那么到底是如何进行运算的呢,虽说网络上关于卷积运算原理铺天盖地,但是个人总感觉讲得不够透彻,或者说本人智商有待提高,
希望通过如下这幅图(某位大神的杰作)来使各位看官们能够真正理解。

这里举的例子是一个输入图片(5*5*3),卷积核(3*3*3),有两个(Filter W0,W1),偏置b也有两个(Bios b0,b1),卷积结果Output Volumn(3*3*2),步长stride = 2。
输入:7*7*3 是因为 pad = 1 (在图片边界行和列都补零,补零的行和的数目是1),
(对于彩色图片,一般都是RGB3种颜色,号称3通道,7*7指图片高h * 宽w)
,补零的作用是能够提取图片边界的特征。
卷积核深度为什么要设置成3呢?这是因为输入是3通道,所以卷积核深度必须与输入的深度相同。至于卷积核宽w,高h则是可以变化的,但是宽高必须相等。
卷积核输出o[0,0,0] = 3 (Output Volumn下浅绿色框结果),这个结果是如何得到的呢? 其实关键就是矩阵对应位置相乘再相加(千万不要跟矩阵乘法搞混淆啦)
=> w0[:,:,0] * x[:,:,0]蓝色区域矩阵(R通道) + w0[:,:,1] * x[:,:,1]蓝色区域矩阵(G通道)+ w0[:,:,2] * x[:,:,2]蓝色区域矩阵(B通道) + b0(千万不能丢,因为 y = w * x + b)
第一项 => 0 * 1 + 0 * 1 + 0 * 1 + 0 * (-1) + 1 * (-1) + 1 * 0 + 0 * (-1) + 1 * 1 + 1 * 0 = 0
第二项 => 0 * (-1) + 0 * (-1) + 0 * 1 + 0 * (-1) + 0 * 1 + 1 * 0 + 0 * (-1) + 2 * 1 + 2 * 0 = 2
第三项 => 0 * 1 + 0 * 0 + 0 * (-1) + 0 * 0 + 2 * 0 + 2 * 0 + 0 * 1 + 0 * (-1) + 0 * (-1) = 0
卷积核输出o[0,0,0] = > 第一项 + 第二项 + 第三项 + b0 = 0 + 2 + 0 + 1 = 3
o[0,0,1] = -5 又是如何得到的呢?
因为这里的stride = 2 ,所以 输入的窗口就要滑动两个步长,也就是红色框的区域,而运算跟之前是一样的
第一项 => 0 * 1 + 0 * 1 + 0 * 1 + 1 * (-1) + 2 * (-1) + 2 * 0 + 1 * (-1) + 1 * 1 + 2 * 0 = -3
第二项 => 0 * (-1) + 0 * (-1) + 0 * 1 + 1 * (-1) + 2 * 1 + 0 * 0 + 2 * (-1) + 1 * 1 + 1 * 0 = 0
第三项 => 0 * 1 + 0 * 0 + 0 * (-1) + 2 * 0 + 0 * 0 + 1 * 0 + 0 * 1 + 2 * (-1) + 1 * (-1) = - 3
卷积核输出o[0,0,1] = > 第一项 + 第二项 + 第三项 + b0 = (-3) + 0 + (-3) + 1 = -5
之后以此卷积核窗口大小在输入图片上滑动,卷积求出结果,因为有两个卷积核,所有就有两个输出结果。
这里小伙伴可能有个疑问,输出窗口是如何得到的呢?
这里有一个公式:输出窗口宽 w = (输入窗口宽 w - 卷积核宽 w + 2 * pad)/stride + 1 ,输出高 h = 输出窗口宽 w
以上面例子, 输出窗口宽 w = ( 5 - 3 + 2 * 1)/2 + 1 = 3 ,则输出窗口大小为 3 * 3,因为有2个输出,所以是 3*3*2。
2.2 Relu激活函数

相信看过卷积神经网络结构(CNN)的伙伴们都知道,激活函数无处不在,特别是CNN中,在卷积层后,全连接(FC)后都有激活函数Relu的身影,
那么这就自然不得不让我们产生疑问:
问题1、为什么要用激活函数?它的作用是什么?
问题2、在CNN中为什么要用Relu,相比于sigmoid,tanh,它的优势在什么地方?
对于第1个问题:由 y = w * x + b 可知,如果不用激活函数,每个网络层的输出都是一种线性输出,而我们所处的现实场景,其实更多的是各种非线性的分布。
这也说明了激活函数的作用是将线性分布转化为非线性分布,能更逼近我们的真实场景。
对于第2个问题: 先看sigmoid,tanh分布

他们在 x ->![]() 时,输出就变成了恒定值,因为求梯度时需要对函数求一阶偏导数,而不论是sigmoid,还是tanhx,他们的偏导都为0,
时,输出就变成了恒定值,因为求梯度时需要对函数求一阶偏导数,而不论是sigmoid,还是tanhx,他们的偏导都为0,
也就是存在所谓的梯度消失问题,最终也就会导致权重参数w , b 无法更新。相比之下,Relu就不存在这样的问题,另外在 x > 0 时,
Relu求导 = 1,这对于反向传播计算dw,db,是能够大大的简化运算的。
使用sigmoid还会存在梯度爆炸的问题,比如在进行前向传播和反向传播迭代次数非常多的情况下,sigmoid因为是指数函数,其结果中
某些值会在迭代中累积,并成指数级增长,最终会出现NaN而导致溢出。
2.3 池化
池化层一般在卷积层+ Relu之后,它的作用是:
1、减小输入矩阵的大小(只是宽和高,而不是深度),提取主要特征。(不可否认的是,在池化后,特征会有一定的损失,所以,有些经典模型就去掉了池化这一层)。
它的目的是显而易见的,就是在后续操作时能降低运算。
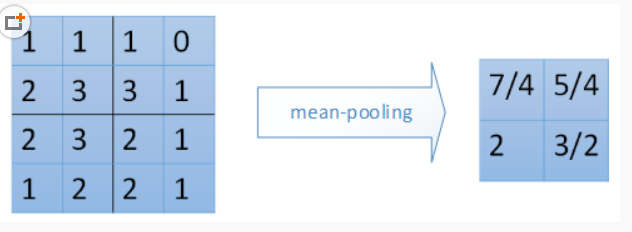
2、一般采用mean_pooling(均值池化)和max_pooling(最大值池化),对于输入矩阵有translation(平移),rotation(旋转),能够保证特征的不变性。
mean_pooling 就是输入矩阵池化区域求均值,这里要注意的是池化窗口在输入矩阵滑动的步长跟stride有关,一般stride = 2.(图片是直接盗过来,这里感谢原创)
最右边7/4 => (1 + 1 + 2 + 3)/4
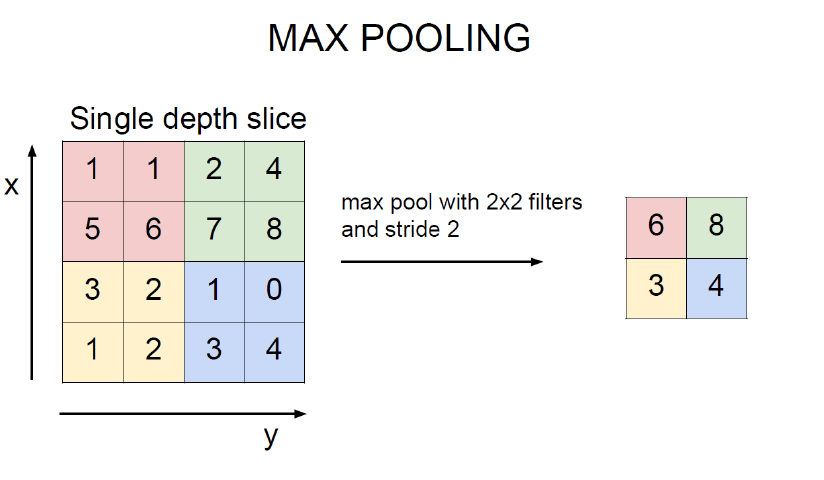
max_pooling 最大值池化,就是每个池化区域的最大值放在输出对应位置上。
2.4 全连接(full connection)
作用:分类器角色,将特征映射到样本标记空间,本质是矩阵变换(affine)。
至于变换的实现见后面的代码流程图,或者最好是跟一下代码,这样理解更透彻。
2.5 损失函数(softmax_loss)
作用:计算损失loss,从而求出梯度grad。
常用损失函数有:MSE均方误差,SVM(支持向量机)合页损失函数,Cross Entropy交叉熵损失函数。
这几种损失函数目前还看不出谁优谁劣,估计只有在具体的应用场景中去验证了。至于这几种损失函数的介绍,
大家可以去参考《常用损失函数小结》https://blog.csdn.net/zhangjunp3/article/details/80467350,这个哥们写得比较详细。
在后面的代码实例中,用到的是softmax_loss,它属于Cross Entropy交叉熵损失函数。
softmax计算公式:
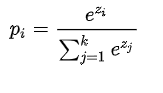
其中, 是要计算的类别
的网络输出,分母是网络输出所有类别之和(共有
个类别),
表示第
类的概率。
交叉熵损失:
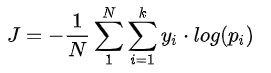
其中, 是类别
的真实标签,
表示第
类的概率,
是样本总数,
是类别数。
梯度:
=
当
!=
=
- 1 当
=
其中 表示真实标签对应索引下预测的目标值,
类别索引。
这个有点折磨人,原理讲解以及推导请大家可以参考这位大神的博客:http://www.cnblogs.com/zongfa/p/8971213.html。
2.6 前向传播(forward propagation)
前向传播包含之前的卷积,Relu激活函数,池化(pool),全连接(fc),可以说,在损失函数之前操作都属于前向传播。
主要是权重参数w , b 初始化,迭代,以及更新w, b,生成分类器模型。
2.7 反向传播(back propagation)
反向传播包含损失函数,通过梯度计算dw,db,Relu激活函数逆变换,反池化,反全连接。
2.8 随机梯度下降(sgd_momentum)
作用:由梯度grad计算新的权重矩阵w
sgd公式:
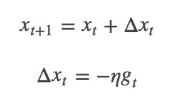
其中,η为学习率,gt为x在t时刻的梯度。
一般我们是将整个数据集分成n个epoch,每个epoch再分成m个batch,每次更新都利用一个batch的数据,而非整个训练集。
优点:batch的方法可以减少机器的压力,并且可以更快地收敛。
缺点:其更新方向完全依赖于当前的batch,因而其更新十分不稳定。
为了解决这个问题,momentum就横空出世了,具体原理详解见下路派出所(这名字霸气)的博客http://www.cnblogs.com/callyblog/p/8299074.html。
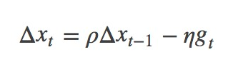
momentum即动量,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。
这样一来,可以在一定程度上增加稳定性,从而学习地更快,并且还有一定摆脱局部最优的能力:
其中,ρ 即momentum,表示要在多大程度上保留原来的更新方向,这个值在0-1之间,在训练开始时,由于梯度可能会很大,所以初始值一般选为0.5;
当梯度不那么大时,改为0.9。η 是学习率,即当前batch的梯度多大程度上影响最终更新方向,跟普通的SGD含义相同。ρ 与 η 之和不一定为1。
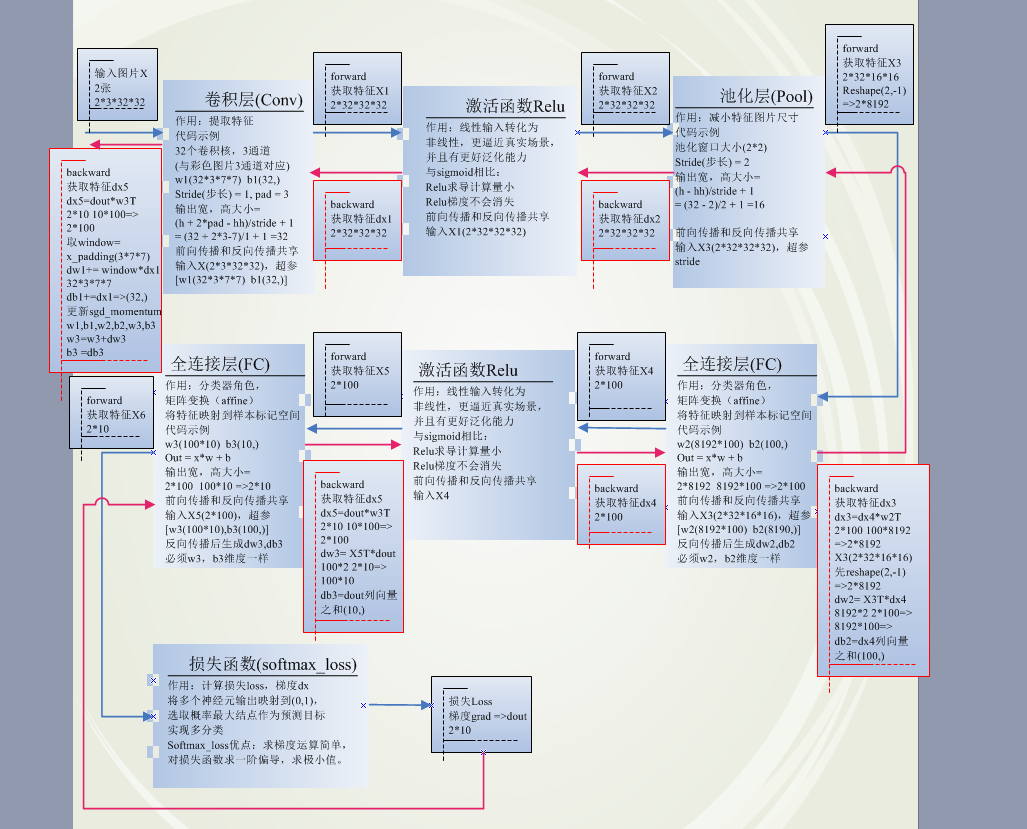
3.代码实现流程图以及介绍
代码流程图:费了老大劲,终于弄完了,希望对各位看官们有所帮助,建议对比流程图和跟踪代码,加深对原理的理解。
特别是前向传播和反向传播维度的变换,需要重点关注。
4.代码实现
当然,代码的整个实现是某位大神实现的,我只是在上面做了些小改动以及重点函数做了些注释,有不妥之处也希望大家不吝指教。
因为原始图片数据集太大,不好上传,大家可以直接在http://www.cs.toronto.edu/~kriz/cifar.html下载CIFAR-10 python version,
有163M,放在代码文件同路径下即可。

start.py


1 # -*- coding: utf-8 -*-
2 import matplotlib.pyplot as plt
3 '''同路径下py模块引用'''
4
5 try:
6 from . import data_utils
7 from . import solver
8 from . import cnn
9 except Exception:
10 import data_utils
11 import solver
12 import cnn
13
14 import numpy as np
15 # 获取样本数据
16 data = data_utils.get_CIFAR10_data()
17 # model初始化(权重因子以及对应偏置 w1,b1 ,w2,b2 ,w3,b3,数量取决于网络层数)
18 model = cnn.ThreeLayerConvNet(reg=0.9)
19 solver = solver.Solver(model, data,
20 lr_decay=0.95,
21 print_every=10, num_epochs=5, batch_size=2,
22 update_rule='sgd_momentum',
23 optim_config={'learning_rate': 5e-4, 'momentum': 0.9})
24 # 训练,获取最佳model
25 solver.train()
26
27 plt.subplot(2, 1, 1)
28 plt.title('Training loss')
29 plt.plot(solver.loss_history, 'o')
30 plt.xlabel('Iteration')
31
32 plt.subplot(2, 1, 2)
33 plt.title('Accuracy')
34 plt.plot(solver.train_acc_history, '-o', label='train')
35 plt.plot(solver.val_acc_history, '-o', label='val')
36 plt.plot([0.5] * len(solver.val_acc_history), 'k--')
37 plt.xlabel('Epoch')
38 plt.legend(loc='lower right')
39 plt.gcf().set_size_inches(15, 12)
40 plt.show()
41
42
43 best_model = model
44 y_test_pred = np.argmax(best_model.loss(data['X_test']), axis=1)
45 y_val_pred = np.argmax(best_model.loss(data['X_val']), axis=1)
46 print ('Validation set accuracy: ',(y_val_pred == data['y_val']).mean())
47 print ('Test set accuracy: ', (y_test_pred == data['y_test']).mean())
48 # Validation set accuracy: about 52.9%
49 # Test set accuracy: about 54.7%
50
51
52 # Visualize the weights of the best network
53 """
54 from vis_utils import visualize_grid
55
56 def show_net_weights(net):
57 W1 = net.params['W1']
58 W1 = W1.reshape(3, 32, 32, -1).transpose(3, 1, 2, 0)
59 plt.imshow(visualize_grid(W1, padding=3).astype('uint8'))
60 plt.gca().axis('off')
61 show_net_weights(best_model)
62 plt.show()
63 """
cnn.py
1 # -*- coding: utf-8 -*-
2 try:
3 from . import layer_utils
4 from . import layers
5 except Exception:
6 import layer_utils
7 import layers
8 import numpy as np
9
10 class ThreeLayerConvNet(object):
11 """
12 A three-layer convolutional network with the following architecture:
13 conv - relu - 2x2 max pool - affine - relu - affine - softmax
14 """
15
16 def __init__(self, input_dim=(3, 32, 32), num_filters=32, filter_size=7,
17 hidden_dim=100, num_classes=10, weight_scale=1e-3, reg=0.0,
18 dtype=np.float32):
19 self.params = {}
20 self.reg = reg
21 self.dtype = dtype
22
23 # Initialize weights and biases
24 C, H, W = input_dim
25 self.params['W1'] = weight_scale * np.random.randn(num_filters, C, filter_size, filter_size)
26 self.params['b1'] = np.zeros(num_filters)
27 self.params['W2'] = weight_scale * np.random.randn(num_filters*H*W//4, hidden_dim)
28 self.params['b2'] = np.zeros(hidden_dim)
29 self.params['W3'] = weight_scale * np.random.randn(hidden_dim, num_classes)
30 self.params['b3'] = np.zeros(num_classes)
31
32 for k, v in self.params.items():
33 self.params[k] = v.astype(dtype)
34
35
36 def loss(self, X, y=None):
37 W1, b1 = self.params['W1'], self.params['b1']
38 W2, b2 = self.params['W2'], self.params['b2']
39 W3, b3 = self.params['W3'], self.params['b3']
40
41 # pass conv_param to the forward pass for the convolutional layer
42 filter_size = W1.shape[2]
43 conv_param = {'stride': 1, 'pad': (filter_size - 1) // 2}
44
45 # pass pool_param to the forward pass for the max-pooling layer
46 pool_param = {'pool_height': 2, 'pool_width': 2, 'stride': 2}
47
48 # compute the forward pass
49 a1, cache1 = layer_utils.conv_relu_pool_forward(X, W1, b1, conv_param, pool_param)
50 a2, cache2 = layer_utils.affine_relu_forward(a1, W2, b2)
51 scores, cache3 = layers.affine_forward(a2, W3, b3)
52
53 if y is None:
54 return scores
55
56 # compute the backward pass
57 data_loss, dscores = layers.softmax_loss(scores, y)
58 da2, dW3, db3 = layers.affine_backward(dscores, cache3)
59 da1, dW2, db2 = layer_utils.affine_relu_backward(da2, cache2)
60 dX, dW1, db1 = layer_utils.conv_relu_pool_backward(da1, cache1)
61
62 # Add regularization 引入修正因子,重新计算损失,梯度
63 dW1 += self.reg * W1
64 dW2 += self.reg * W2
65 dW3 += self.reg * W3
66 reg_loss = 0.5 * self.reg * sum(np.sum(W * W) for W in [W1, W2, W3])
67
68 loss = data_loss + reg_loss
69 grads = {'W1': dW1, 'b1': db1, 'W2': dW2, 'b2': db2, 'W3': dW3, 'b3': db3}
70
71 return loss, grads
data.utils.py
1 # -*- coding: utf-8 -*-
2 import pickle
3 import numpy as np
4 import os
5
6 #from scipy.misc import imread
7
8 def load_CIFAR_batch(filename):
9 """ load single batch of cifar """
10 with open(filename, 'rb') as f:
11 datadict = pickle.load(f, encoding='bytes')
12 X = datadict[b'data']
13 Y = datadict[b'labels']
14 X = X.reshape(10000, 3, 32, 32).transpose(0,2,3,1).astype("float")
15 Y = np.array(Y)
16 return X, Y
17
18 def load_CIFAR10(ROOT):
19 """ load all of cifar """
20 xs = []
21 ys = []
22 for b in range(1,2):
23 f = os.path.join(ROOT, 'data_batch_%d' % (b, ))
24 X, Y = load_CIFAR_batch(f)
25 xs.append(X)
26 ys.append(Y)
27 Xtr = np.concatenate(xs)
28 Ytr = np.concatenate(ys)
29 del X, Y
30 Xte, Yte = load_CIFAR_batch(os.path.join(ROOT, 'test_batch'))
31 return Xtr, Ytr, Xte, Yte
32
33
34 def get_CIFAR10_data(num_training=500, num_validation=50, num_test=50):
35
36 """
37 Load the CIFAR-10 dataset from disk and perform preprocessing to prepare
38 it for classifiers. These are the same steps as we used for the SVM, but
39 condensed to a single function.
40 """
41 # Load the raw CIFAR-10 data
42
43 #cifar10_dir = 'C://download//cifar-10-python//cifar-10-batches-py//'
44 cifar10_dir = '.\\cifar-10-batches-py\\'
45 X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir)
46 print (X_train.shape)
47 # Subsample the data
48 mask = range(num_training, num_training + num_validation)
49 X_val = X_train[mask]
50 y_val = y_train[mask]
51 mask = range(num_training)
52 X_train = X_train[mask]
53 y_train = y_train[mask]
54 mask = range(num_test)
55 X_test = X_test[mask]
56 y_test = y_test[mask]
57
58 # 标准化数据,求样本均值,然后 样本 - 样本均值,作用:使样本数据更收敛一些,便于后续处理
59 # Normalize the data: subtract the mean image
60 # 如果2维空间 m*n np.mean()后 => 1*n
61 # 对于4维空间 m*n*k*j np.mean()后 => 1*n*k*j
62 mean_image = np.mean(X_train, axis=0)
63 X_train -= mean_image
64 X_val -= mean_image
65 X_test -= mean_image
66
67 # 把通道channel 提前
68 # Transpose so that channels come first
69 X_train = X_train.transpose(0, 3, 1, 2).copy()
70 X_val = X_val.transpose(0, 3, 1, 2).copy()
71 X_test = X_test.transpose(0, 3, 1, 2).copy()
72
73 # Package data into a dictionary
74 return {
75 'X_train': X_train, 'y_train': y_train,
76 'X_val': X_val, 'y_val': y_val,
77 'X_test': X_test, 'y_test': y_test,
78 }
79
80 """
81 def load_tiny_imagenet(path, dtype=np.float32):
82
83 Load TinyImageNet. Each of TinyImageNet-100-A, TinyImageNet-100-B, and
84 TinyImageNet-200 have the same directory structure, so this can be used
85 to load any of them.
86
87 Inputs:
88 - path: String giving path to the directory to load.
89 - dtype: numpy datatype used to load the data.
90
91 Returns: A tuple of
92 - class_names: A list where class_names[i] is a list of strings giving the
93 WordNet names for class i in the loaded dataset.
94 - X_train: (N_tr, 3, 64, 64) array of training images
95 - y_train: (N_tr,) array of training labels
96 - X_val: (N_val, 3, 64, 64) array of validation images
97 - y_val: (N_val,) array of validation labels
98 - X_test: (N_test, 3, 64, 64) array of testing images.
99 - y_test: (N_test,) array of test labels; if test labels are not available
100 (such as in student code) then y_test will be None.
101
102 # First load wnids
103 with open(os.path.join(path, 'wnids.txt'), 'r') as f:
104 wnids = [x.strip() for x in f]
105
106 # Map wnids to integer labels
107 wnid_to_label = {wnid: i for i, wnid in enumerate(wnids)}
108
109 # Use words.txt to get names for each class
110 with open(os.path.join(path, 'words.txt'), 'r') as f:
111 wnid_to_words = dict(line.split('\t') for line in f)
112 for wnid, words in wnid_to_words.iteritems():
113 wnid_to_words[wnid] = [w.strip() for w in words.split(',')]
114 class_names = [wnid_to_words[wnid] for wnid in wnids]
115
116 # Next load training data.
117 X_train = []
118 y_train = []
119 for i, wnid in enumerate(wnids):
120 if (i + 1) % 20 == 0:
121 print 'loading training data for synset %d / %d' % (i + 1, len(wnids))
122 # To figure out the filenames we need to open the boxes file
123 boxes_file = os.path.join(path, 'train', wnid, '%s_boxes.txt' % wnid)
124 with open(boxes_file, 'r') as f:
125 filenames = [x.split('\t')[0] for x in f]
126 num_images = len(filenames)
127
128 X_train_block = np.zeros((num_images, 3, 64, 64), dtype=dtype)
129 y_train_block = wnid_to_label[wnid] * np.ones(num_images, dtype=np.int64)
130 for j, img_file in enumerate(filenames):
131 img_file = os.path.join(path, 'train', wnid, 'images', img_file)
132 img = imread(img_file)
133 if img.ndim == 2:
134 ## grayscale file
135 img.shape = (64, 64, 1)
136 X_train_block[j] = img.transpose(2, 0, 1)
137 X_train.append(X_train_block)
138 y_train.append(y_train_block)
139
140 # We need to concatenate all training data
141 X_train = np.concatenate(X_train, axis=0)
142 y_train = np.concatenate(y_train, axis=0)
143
144 # Next load validation data
145 with open(os.path.join(path, 'val', 'val_annotations.txt'), 'r') as f:
146 img_files = []
147 val_wnids = []
148 for line in f:
149 img_file, wnid = line.split('\t')[:2]
150 img_files.append(img_file)
151 val_wnids.append(wnid)
152 num_val = len(img_files)
153 y_val = np.array([wnid_to_label[wnid] for wnid in val_wnids])
154 X_val = np.zeros((num_val, 3, 64, 64), dtype=dtype)
155 for i, img_file in enumerate(img_files):
156 img_file = os.path.join(path, 'val', 'images', img_file)
157 img = imread(img_file)
158 if img.ndim == 2:
159 img.shape = (64, 64, 1)
160 X_val[i] = img.transpose(2, 0, 1)
161
162 # Next load test images
163 # Students won't have test labels, so we need to iterate over files in the
164 # images directory.
165 img_files = os.listdir(os.path.join(path, 'test', 'images'))
166 X_test = np.zeros((len(img_files), 3, 64, 64), dtype=dtype)
167 for i, img_file in enumerate(img_files):
168 img_file = os.path.join(path, 'test', 'images', img_file)
169 img = imread(img_file)
170 if img.ndim == 2:
171 img.shape = (64, 64, 1)
172 X_test[i] = img.transpose(2, 0, 1)
173
174 y_test = None
175 y_test_file = os.path.join(path, 'test', 'test_annotations.txt')
176 if os.path.isfile(y_test_file):
177 with open(y_test_file, 'r') as f:
178 img_file_to_wnid = {}
179 for line in f:
180 line = line.split('\t')
181 img_file_to_wnid[line[0]] = line[1]
182 y_test = [wnid_to_label[img_file_to_wnid[img_file]] for img_file in img_files]
183 y_test = np.array(y_test)
184
185 return class_names, X_train, y_train, X_val, y_val, X_test, y_test
186
187 """
188 def load_models(models_dir):
189 """
190 Load saved models from disk. This will attempt to unpickle all files in a
191 directory; any files that give errors on unpickling (such as README.txt) will
192 be skipped.
193
194 Inputs:
195 - models_dir: String giving the path to a directory containing model files.
196 Each model file is a pickled dictionary with a 'model' field.
197
198 Returns:
199 A dictionary mapping model file names to models.
200 """
201 models = {}
202 for model_file in os.listdir(models_dir):
203 with open(os.path.join(models_dir, model_file), 'rb') as f:
204 try:
205 models[model_file] = pickle.load(f)['model']
206 except pickle.UnpicklingError:
207 continue
208 return models
layer.utils.py
1 # -*- coding: utf-8 -*-
2 try:
3 from . import layers
4 except Exception:
5 import layers
6
7
8
9
10 def affine_relu_forward(x, w, b):
11 """
12 Convenience layer that perorms an affine transform followed by a ReLU
13
14 Inputs:
15 - x: Input to the affine layer
16 - w, b: Weights for the affine layer
17
18 Returns a tuple of:
19 - out: Output from the ReLU
20 - cache: Object to give to the backward pass
21 """
22 a, fc_cache = layers.affine_forward(x, w, b)
23 out, relu_cache = layers.relu_forward(a)
24 cache = (fc_cache, relu_cache)
25 return out, cache
26
27
28 def affine_relu_backward(dout, cache):
29 """
30 Backward pass for the affine-relu convenience layer
31 """
32 fc_cache, relu_cache = cache
33 da = layers.relu_backward(dout, relu_cache)
34 dx, dw, db = layers.affine_backward(da, fc_cache)
35 return dx, dw, db
36
37
38 pass
39
40
41 def conv_relu_forward(x, w, b, conv_param):
42 """
43 A convenience layer that performs a convolution followed by a ReLU.
44
45 Inputs:
46 - x: Input to the convolutional layer
47 - w, b, conv_param: Weights and parameters for the convolutional layer
48
49 Returns a tuple of:
50 - out: Output from the ReLU
51 - cache: Object to give to the backward pass
52 """
53 a, conv_cache = layers.conv_forward_fast(x, w, b, conv_param)
54 out, relu_cache = layers.relu_forward(a)
55 cache = (conv_cache, relu_cache)
56 return out, cache
57
58
59 def conv_relu_backward(dout, cache):
60 """
61 Backward pass for the conv-relu convenience layer.
62 """
63 conv_cache, relu_cache = cache
64 da = layers.relu_backward(dout, relu_cache)
65 dx, dw, db = layers.conv_backward_fast(da, conv_cache)
66 return dx, dw, db
67
68
69 def conv_relu_pool_forward(x, w, b, conv_param, pool_param):
70 """
71 Convenience layer that performs a convolution, a ReLU, and a pool.
72
73 Inputs:
74 - x: Input to the convolutional layer
75 - w, b, conv_param: Weights and parameters for the convolutional layer
76 - pool_param: Parameters for the pooling layer
77
78 Returns a tuple of:
79 - out: Output from the pooling layer
80 - cache: Object to give to the backward pass
81 """
82 a, conv_cache = layers.conv_forward_naive(x, w, b, conv_param)
83 s, relu_cache = layers.relu_forward(a)
84 out, pool_cache = layers.max_pool_forward_naive(s, pool_param)
85 cache = (conv_cache, relu_cache, pool_cache)
86 return out, cache
87
88
89 def conv_relu_pool_backward(dout, cache):
90 """
91 Backward pass for the conv-relu-pool convenience layer
92 """
93 conv_cache, relu_cache, pool_cache = cache
94 ds = layers.max_pool_backward_naive(dout, pool_cache)
95 da = layers.relu_backward(ds, relu_cache)
96 dx, dw, db = layers.conv_backward_naive(da, conv_cache)
97 return dx, dw, db
layers.py
1 import numpy as np
2
3 '''
4 全连接层:矩阵变换,获取对应目标相同的行与列
5 输入x: 2*32*16*16
6 输入x_row: 2*8192
7 超参w:8192*100
8 输出:矩阵乘法 2*8192 ->8192*100 =>2*100
9 '''
10 def affine_forward(x, w, b):
11 """
12 Computes the forward pass for an affine (fully-connected) layer.
13 The input x has shape (N, d_1, ..., d_k) and contains a minibatch of N
14 examples, where each example x[i] has shape (d_1, ..., d_k). We will
15 reshape each input into a vector of dimension D = d_1 * ... * d_k, and
16 then transform it to an output vector of dimension M.
17 Inputs:
18 - x: A numpy array containing input data, of shape (N, d_1, ..., d_k)
19 - w: A numpy array of weights, of shape (D, M)
20 - b: A numpy array of biases, of shape (M,)
21 Returns a tuple of:
22 - out: output, of shape (N, M)
23 - cache: (x, w, b)
24 """
25 out = None
26 # Reshape x into rows
27 N = x.shape[0]
28 x_row = x.reshape(N, -1) # (N,D) -1表示不知道多少列,指定行,就能算出列 = 2 * 32 * 16 * 16/2 = 8192
29 out = np.dot(x_row, w) + b # (N,M) 2*8192 8192*100 =>2 * 100
30 cache = (x, w, b)
31
32 return out, cache
33 '''
34 反向传播之affine矩阵变换
35 根据dout求出dx,dw,db
36 由 out = w * x =>
37 dx = dout * w
38 dw = dout * x
39 db = dout * 1
40 因为dx 与 x,dw 与 w,db 与 b 大小(维度)必须相同
41 dx = dout * wT 矩阵乘法
42 dw = dxT * dout 矩阵乘法
43 db = dout 按列求和
44 '''
45 def affine_backward(dout, cache):
46 """
47 Computes the backward pass for an affine layer.
48 Inputs:
49 - dout: Upstream derivative, of shape (N, M)
50 - cache: Tuple of:
51 - x: Input data, of shape (N, d_1, ... d_k)
52 - w: Weights, of shape (D, M)
53 Returns a tuple of:
54 - dx: Gradient with respect to x, of shape (N, d1, ..., d_k)
55 dx = dout * w
56 - dw: Gradient with respect to w, of shape (D, M)
57 dw = dout * x
58 - db: Gradient with respect to b, of shape (M,)
59 db = dout * 1
60 """
61
62 x, w, b = cache
63 dx, dw, db = None, None, None
64 dx = np.dot(dout, w.T) # (N,D)
65 # dx维度必须跟x维度相同
66 dx = np.reshape(dx, x.shape) # (N,d1,...,d_k)
67 # 转换成二维矩阵
68 x_row = x.reshape(x.shape[0], -1) # (N,D)
69 dw = np.dot(x_row.T, dout) # (D,M)
70
71 db = np.sum(dout, axis=0, keepdims=True) # (1,M)
72
73 return dx, dw, db
74
75 def relu_forward(x):
76 """ 激活函数,解决sigmoid梯度消失问题,网络性能比sigmoid更好
77 Computes the forward pass for a layer of rectified linear units (ReLUs).
78 Input:
79 - x: Inputs, of any shape
80 Returns a tuple of:
81 - out: Output, of the same shape as x
82 - cache: x
83 """
84 out = None
85 out = ReLU(x)
86 cache = x
87
88 return out, cache
89
90 def relu_backward(dout, cache):
91 """
92 Computes the backward pass for a layer of rectified linear units (ReLUs).
93 Input:
94 - dout: Upstream derivatives, of any shape
95 - cache: Input x, of same shape as dout
96 Returns:
97 - dx: Gradient with respect to x
98 """
99 dx, x = None, cache
100 dx = dout
101 dx[x <= 0] = 0
102
103 return dx
104
105 def svm_loss(x, y):
106 """
107 Computes the loss and gradient using for multiclass SVM classification.
108 Inputs:
109 - x: Input data, of shape (N, C) where x[i, j] is the score for the jth class
110 for the ith input.
111 - y: Vector of labels, of shape (N,) where y[i] is the label for x[i] and
112 0 <= y[i] < C
113 Returns a tuple of:
114 - loss: Scalar giving the loss
115 - dx: Gradient of the loss with respect to x
116 """
117 N = x.shape[0]
118 correct_class_scores = x[np.arange(N), y]
119 margins = np.maximum(0, x - correct_class_scores[:, np.newaxis] + 1.0)
120 margins[np.arange(N), y] = 0
121 loss = np.sum(margins) / N
122 num_pos = np.sum(margins > 0, axis=1)
123 dx = np.zeros_like(x)
124 dx[margins > 0] = 1
125 dx[np.arange(N), y] -= num_pos
126 dx /= N
127
128 return loss, dx
129 '''
130 softmax_loss 求梯度优点: 求梯度运算简单,方便
131 softmax: softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,
132 可以看成概率来理解,从而来进行多分类。
133 Si = exp(i)/[exp(j)求和]
134 softmax_loss:损失函数,求梯度dx必须用到损失函数,通过梯度下降更新超参
135 Loss = -[Ypred*ln(Sj真实类别位置的概率值)]求和
136 梯度dx : 对损失函数求一阶偏导
137 如果 j = i =>dx = Sj - 1
138 如果 j != i => dx = Sj
139 '''
140 def softmax_loss(x, y):
141 """
142 Computes the loss and gradient for softmax classification. Inputs:
143 - x: Input data, of shape (N, C) where x[i, j] is the score for the jth class
144 for the ith input.
145 - y: Vector of labels, of shape (N,) where y[i] is the label for x[i] and
146 0 <= y[i] < C
147 Returns a tuple of:
148 - loss: Scalar giving the loss
149 - dx: Gradient of the loss with respect to x
150 """
151 '''
152 x - np.max(x, axis=1, keepdims=True) 对数据进行预处理,
153 防止np.exp(x - np.max(x, axis=1, keepdims=True))得到结果太分散;
154 np.max(x, axis=1, keepdims=True)保证所得结果维度不变;
155 '''
156 probs = np.exp(x - np.max(x, axis=1, keepdims=True))
157 # 计算softmax,准确的说应该是soft,因为还没有选取概率最大值的操作
158 probs /= np.sum(probs, axis=1, keepdims=True)
159 # 样本图片个数
160 N = x.shape[0]
161 # 计算图片损失
162 loss = -np.sum(np.log(probs[np.arange(N), y])) / N
163 # 复制概率
164 dx = probs.copy()
165 # 针对 i = j 求梯度
166 dx[np.arange(N), y] -= 1
167 # 计算每张样本图片梯度
168 dx /= N
169
170 return loss, dx
171
172 def ReLU(x):
173 """ReLU non-linearity."""
174 return np.maximum(0, x)
175 '''
176 功能:获取图片特征
177 前向卷积:每次用一个3维的卷积核与图片RGB各个通道分别卷积(卷积核1与R进行点积,卷积核2与G点积,卷积核3与B点积),
178 然后将3个结果求和(也就是 w*x ),再加上 b,就是新结果某一位置输出,这是卷积核在图片某一固定小范围内(卷积核大小)的卷积,
179 要想获得整个图片的卷积结果,需要在图片上滑动卷积核(先右后下),直至遍历整个图片。
180 x: 2*3*32*32 每次选取2张图片,图片大小32*32,彩色(3通道)
181 w: 32*3*7*7 卷积核每个大小是7*7;对应输入x的3通道,所以是3维,有32个卷积核
182 pad = 3(图片边缘行列补0),stride = 1(卷积核移动步长)
183 输出宽*高结果:(32-7+2*3)/1 + 1 = 32
184 输出大小:2*32*32*32
185 '''
186 def conv_forward_naive(x, w, b, conv_param):
187 stride, pad = conv_param['stride'], conv_param['pad']
188 N, C, H, W = x.shape
189 F, C, HH, WW = w.shape
190 x_padded = np.pad(x, ((0, 0), (0, 0), (pad, pad), (pad, pad)), mode='constant')
191 '''// : 求整型'''
192 H_new = 1 + (H + 2 * pad - HH) // stride
193 W_new = 1 + (W + 2 * pad - WW) // stride
194 s = stride
195 out = np.zeros((N, F, H_new, W_new))
196
197 for i in range(N): # ith image
198 for f in range(F): # fth filter
199 for j in range(H_new):
200 for k in range(W_new):
201 #print x_padded[i, :, j*s:HH+j*s, k*s:WW+k*s].shape
202 #print w[f].shape
203 #print b.shape
204 #print np.sum((x_padded[i, :, j*s:HH+j*s, k*s:WW+k*s] * w[f]))
205 out[i, f, j, k] = np.sum(x_padded[i, :, j*s:HH+j*s, k*s:WW+k*s] * w[f]) + b[f]
206
207 cache = (x, w, b, conv_param)
208
209 return out, cache
210
211 '''
212 反向传播之卷积:卷积核3*7*7
213 输入dout:2*32*32*32
214 输出dx:2*3*32*32
215 '''
216 def conv_backward_naive(dout, cache):
217
218 x, w, b, conv_param = cache
219 # 边界补0
220 pad = conv_param['pad']
221 # 步长
222 stride = conv_param['stride']
223 F, C, HH, WW = w.shape
224 N, C, H, W = x.shape
225 H_new = 1 + (H + 2 * pad - HH) // stride
226 W_new = 1 + (W + 2 * pad - WW) // stride
227
228 dx = np.zeros_like(x)
229 dw = np.zeros_like(w)
230 db = np.zeros_like(b)
231
232 s = stride
233 x_padded = np.pad(x, ((0, 0), (0, 0), (pad, pad), (pad, pad)), 'constant')
234 dx_padded = np.pad(dx, ((0, 0), (0, 0), (pad, pad), (pad, pad)), 'constant')
235 # 图片个数
236 for i in range(N): # ith image
237 # 卷积核滤波个数
238 for f in range(F): # fth filter
239 for j in range(H_new):
240 for k in range(W_new):
241 # 3*7*7
242 window = x_padded[i, :, j*s:HH+j*s, k*s:WW+k*s]
243 db[f] += dout[i, f, j, k]
244 # 3*7*7
245 dw[f] += window * dout[i, f, j, k]
246 # 3*7*7 => 2*3*38*38
247 dx_padded[i, :, j*s:HH+j*s, k*s:WW+k*s] += w[f] * dout[i, f, j, k]
248
249 # Unpad
250 dx = dx_padded[:, :, pad:pad+H, pad:pad+W]
251
252 return dx, dw, db
253 '''
254 功能:减少特征尺寸大小
255 前向最大池化:在特征矩阵中选取指定大小窗口,获取窗口内元素最大值作为输出窗口映射值,
256 先有后下遍历,直至获取整个特征矩阵对应的新映射特征矩阵。
257 输入x:2*32*32*32
258 池化参数:窗口:2*2,步长:2
259 输出窗口宽,高:(32-2)/2 + 1 = 16
260 输出大小:2*32*16*16
261 '''
262 def max_pool_forward_naive(x, pool_param):
263 HH, WW = pool_param['pool_height'], pool_param['pool_width']
264 s = pool_param['stride']
265 N, C, H, W = x.shape
266 H_new = 1 + (H - HH) // s
267 W_new = 1 + (W - WW) // s
268 out = np.zeros((N, C, H_new, W_new))
269 for i in range(N):
270 for j in range(C):
271 for k in range(H_new):
272 for l in range(W_new):
273 window = x[i, j, k*s:HH+k*s, l*s:WW+l*s]
274 out[i, j, k, l] = np.max(window)
275
276 cache = (x, pool_param)
277
278 return out, cache
279
280 '''
281 反向传播之池化:增大特征尺寸大小
282 在缓存中取出前向池化时输入特征,选取某一范围矩阵窗口,
283 找出最大值所在的位置,根据这个位置将dout值映射到新的矩阵对应位置上,
284 而新矩阵其他位置都初始化为0.
285 输入dout:2*32*16*16
286 输出dx:2*32*32*32
287 '''
288 def max_pool_backward_naive(dout, cache):
289 x, pool_param = cache
290 HH, WW = pool_param['pool_height'], pool_param['pool_width']
291 s = pool_param['stride']
292 N, C, H, W = x.shape
293 H_new = 1 + (H - HH) // s
294 W_new = 1 + (W - WW) // s
295 dx = np.zeros_like(x)
296 for i in range(N):
297 for j in range(C):
298 for k in range(H_new):
299 for l in range(W_new):
300 # 取前向传播时输入的某一池化窗口
301 window = x[i, j, k*s:HH+k*s, l*s:WW+l*s]
302 # 计算窗口最大值
303 m = np.max(window)
304 # 根据最大值所在位置以及dout对应值=>新矩阵窗口数值
305 # [false,false
306 # true, false] * 1 => [0,0
307 # 1,0]
308 dx[i, j, k*s:HH+k*s, l*s:WW+l*s] = (window == m) * dout[i, j, k, l]
309
310 return dx
optim.py
1 import numpy as np
2
3 def sgd(w, dw, config=None):
4 """
5 Performs vanilla stochastic gradient descent.
6 config format:
7 - learning_rate: Scalar learning rate.
8 """
9 if config is None: config = {}
10 config.setdefault('learning_rate', 1e-2)
11 w -= config['learning_rate'] * dw
12
13 return w, config
14 '''
15 SGD:随机梯度下降:由梯度计算新的权重矩阵w
16 sgd_momentum 是sgd的改进版,解决sgd更新不稳定,陷入局部最优的问题。
17 增加一个动量因子momentum,可以在一定程度上增加稳定性,
18 从而学习地更快,并且还有一定摆脱局部最优的能力。
19
20 '''
21 def sgd_momentum(w, dw, config=None):
22 """
23 Performs stochastic gradient descent with momentum.
24 config format:
25 - learning_rate: Scalar learning rate.
26 - momentum: Scalar between 0 and 1 giving the momentum value.
27 Setting momentum = 0 reduces to sgd.
28 - velocity(速度): A numpy array of the same shape as w and dw used to store a moving
29 average of the gradients.
30 """
31 if config is None: config = {}
32 config.setdefault('learning_rate', 1e-2)
33 config.setdefault('momentum', 0.9)
34 # config 如果存在属性velocity,则获取config['velocity'],否则获取np.zeros_like(w)
35 v = config.get('velocity', np.zeros_like(w))
36 next_w = None
37 v = config['momentum'] * v - config['learning_rate'] * dw
38 next_w = w + v
39 config['velocity'] = v
40
41 return next_w, config
42
43 def rmsprop(x, dx, config=None):
44 """
45 Uses the RMSProp update rule, which uses a moving average of squared gradient
46 values to set adaptive per-parameter learning rates.
47 config format:
48 - learning_rate: Scalar learning rate.
49 - decay_rate: Scalar between 0 and 1 giving the decay rate for the squared
50 gradient cache.
51 - epsilon: Small scalar used for smoothing to avoid dividing by zero.
52 - cache: Moving average of second moments of gradients.
53 """
54 if config is None: config = {}
55 config.setdefault('learning_rate', 1e-2)
56 config.setdefault('decay_rate', 0.99)
57 config.setdefault('epsilon', 1e-8)
58 config.setdefault('cache', np.zeros_like(x))
59 next_x = None
60 cache = config['cache']
61 decay_rate = config['decay_rate']
62 learning_rate = config['learning_rate']
63 epsilon = config['epsilon']
64 cache = decay_rate * cache + (1 - decay_rate) * (dx**2)
65 x += - learning_rate * dx / (np.sqrt(cache) + epsilon)
66 config['cache'] = cache
67 next_x = x
68
69 return next_x, config
70
71 def adam(x, dx, config=None):
72 """
73 Uses the Adam update rule, which incorporates moving averages of both the
74 gradient and its square and a bias correction term.
75 config format:
76 - learning_rate: Scalar learning rate.
77 - beta1: Decay rate for moving average of first moment of gradient.
78 - beta2: Decay rate for moving average of second moment of gradient.
79 - epsilon: Small scalar used for smoothing to avoid dividing by zero.
80 - m: Moving average of gradient.
81 - v: Moving average of squared gradient.
82 - t: Iteration number.
83 """
84 if config is None: config = {}
85 config.setdefault('learning_rate', 1e-3)
86 config.setdefault('beta1', 0.9)
87 config.setdefault('beta2', 0.999)
88 config.setdefault('epsilon', 1e-8)
89 config.setdefault('m', np.zeros_like(x))
90 config.setdefault('v', np.zeros_like(x))
91 config.setdefault('t', 0)
92 next_x = None
93 m = config['m']
94 v = config['v']
95 beta1 = config['beta1']
96 beta2 = config['beta2']
97 learning_rate = config['learning_rate']
98 epsilon = config['epsilon']
99 t = config['t']
100 t += 1
101 m = beta1 * m + (1 - beta1) * dx
102 v = beta2 * v + (1 - beta2) * (dx**2)
103 m_bias = m / (1 - beta1**t)
104 v_bias = v / (1 - beta2**t)
105 x += - learning_rate * m_bias / (np.sqrt(v_bias) + epsilon)
106 next_x = x
107 config['m'] = m
108 config['v'] = v
109 config['t'] = t
110
111 return next_x, config
solver.py
1 import numpy as np
2 try:
3 from . import optim
4 except Exception:
5 import optim
6
7 class Solver(object):
8 """
9 A Solver encapsulates all the logic necessary for training classification
10 models. The Solver performs stochastic gradient descent using different
11 update rules defined in optim.py.
12
13 The solver accepts both training and validataion data and labels so it can
14 periodically check classification accuracy on both training and validation
15 data to watch out for overfitting.
16
17 To train a model, you will first construct a Solver instance, passing the
18 model, dataset, and various optoins (learning rate, batch size, etc) to the
19 constructor. You will then call the train() method to run the optimization
20 procedure and train the model.
21
22 After the train() method returns, model.params will contain the parameters
23 that performed best on the validation set over the course of training.
24 In addition, the instance variable solver.loss_history will contain a list
25 of all losses encountered during training and the instance variables
26 solver.train_acc_history and solver.val_acc_history will be lists containing
27 the accuracies of the model on the training and validation set at each epoch.
28
29 Example usage might look something like this:
30
31 data = {
32 'X_train': # training data
33 'y_train': # training labels
34 'X_val': # validation data
35 'X_train': # validation labels
36 }
37 model = MyAwesomeModel(hidden_size=100, reg=10)
38 solver = Solver(model, data,
39 update_rule='sgd',
40 optim_config={
41 'learning_rate': 1e-3,
42 },
43 lr_decay=0.95,
44 num_epochs=10, batch_size=100,
45 print_every=100)
46 solver.train()
47
48
49 A Solver works on a model object that must conform to the following API:
50
51 - model.params must be a dictionary mapping string parameter names to numpy
52 arrays containing parameter values.
53
54 - model.loss(X, y) must be a function that computes training-time loss and
55 gradients, and test-time classification scores, with the following inputs
56 and outputs:
57
58 Inputs:
59 - X: Array giving a minibatch of input data of shape (N, d_1, ..., d_k)
60 - y: Array of labels, of shape (N,) giving labels for X where y[i] is the
61 label for X[i].
62
63 Returns:
64 If y is None, run a test-time forward pass and return:
65 - scores: Array of shape (N, C) giving classification scores for X where
66 scores[i, c] gives the score of class c for X[i].
67
68 If y is not None, run a training time forward and backward pass and return
69 a tuple of:
70 - loss: Scalar giving the loss
71 - grads: Dictionary with the same keys as self.params mapping parameter
72 names to gradients of the loss with respect to those parameters.
73 """
74
75 def __init__(self, model, data, **kwargs):
76 """
77 Construct a new Solver instance.
78
79 Required arguments:
80 - model: A model object conforming to the API described above
81 - data: A dictionary of training and validation data with the following:
82 'X_train': Array of shape (N_train, d_1, ..., d_k) giving training images
83 'X_val': Array of shape (N_val, d_1, ..., d_k) giving validation images
84 'y_train': Array of shape (N_train,) giving labels for training images
85 'y_val': Array of shape (N_val,) giving labels for validation images
86
87 Optional arguments:
88 - update_rule: A string giving the name of an update rule in optim.py.
89 Default is 'sgd'.
90 - optim_config: A dictionary containing hyperparameters that will be
91 passed to the chosen update rule. Each update rule requires different
92 hyperparameters (see optim.py) but all update rules require a
93 'learning_rate' parameter so that should always be present.
94 - lr_decay: A scalar for learning rate decay; after each epoch the learning
95 rate is multiplied by this value.
96 - batch_size: Size of minibatches used to compute loss and gradient during
97 training.
98 - num_epochs: The number of epochs to run for during training.
99 - print_every: Integer; training losses will be printed every print_every
100 iterations.
101 - verbose: Boolean; if set to false then no output will be printed during
102 training.
103 """
104 self.model = model
105 self.X_train = data['X_train']
106 self.y_train = data['y_train']
107 self.X_val = data['X_val']
108 self.y_val = data['y_val']
109
110 # Unpack keyword arguments
111 # pop(key, default):删除kwargs对象中key,如果存在该key,返回该key对应的value,否则,返回default值。
112 self.update_rule = kwargs.pop('update_rule', 'sgd')
113 self.optim_config = kwargs.pop('optim_config', {})
114 self.lr_decay = kwargs.pop('lr_decay', 1.0)
115 self.batch_size = kwargs.pop('batch_size', 2)
116 self.num_epochs = kwargs.pop('num_epochs', 10)
117
118 self.print_every = kwargs.pop('print_every', 10)
119 self.verbose = kwargs.pop('verbose', True)
120
121 # Throw an error if there are extra keyword arguments
122 # 删除kwargs中参数后,校验是否还有多余参数
123 if len(kwargs) > 0:
124 extra = ', '.join('"%s"' % k for k in kwargs.keys())
125 raise ValueError('Unrecognized arguments %s' % extra)
126
127 # Make sure the update rule exists, then replace the string
128 # name with the actual function
129 # 检查optim对象中是否有属性或方法名为self.update_rule
130 if not hasattr(optim, self.update_rule):
131 raise ValueError('Invalid update_rule "%s"' % self.update_rule)
132 self.update_rule = getattr(optim, self.update_rule)
133
134 self._reset()
135
136
137 def _reset(self):
138 """
139 Set up some book-keeping variables for optimization. Don't call this
140 manually.
141 """
142 # Set up some variables for book-keeping
143 self.epoch = 0
144 self.best_val_acc = 0
145 self.best_params = {}
146 self.loss_history = []
147 self.train_acc_history = []
148 self.val_acc_history = []
149
150 # Make a deep copy of the optim_config for each parameter
151 self.optim_configs = {}
152 for p in self.model.params:
153 d = {k: v for k, v in self.optim_config.items()}
154 self.optim_configs[p] = d
155
156
157 def _step(self):
158 """
159 Make a single gradient update. This is called by train() and should not
160 be called manually.
161 """
162 # Make a minibatch of training data
163 # 500 张图片
164 num_train = self.X_train.shape[0]
165 # 随机选出batch_size:2 张
166 batch_mask = np.random.choice(num_train, self.batch_size)
167
168 # batch_mask = [t%(num_train//2), num_train//2 + t%(num_train//2)]
169
170
171
172 # 训练样本矩阵[2,3,32,32]
173 X_batch = self.X_train[batch_mask]
174 # 标签矩阵[2,] 图片类型
175 y_batch = self.y_train[batch_mask]
176
177 # Compute loss and gradient
178 loss, grads = self.model.loss(X_batch, y_batch)
179 self.loss_history.append(loss)
180
181 # 更新模型超参(w1,b1),(w2,b2),(w3,b3),以及保存更新超参时对应参数因子
182 # Perform a parameter update
183 for p, w in self.model.params.items():
184 dw = grads[p]
185 config = self.optim_configs[p]
186 next_w, next_config = self.update_rule(w, dw, config)
187 self.model.params[p] = next_w
188 # 保存参数因子,learning_rate(学习率),velocity(速度)
189 self.optim_configs[p] = next_config
190
191
192 def check_accuracy(self, X, y, num_samples=None, batch_size=2):
193 """
194 Check accuracy of the model on the provided data.
195
196 Inputs:
197 - X: Array of data, of shape (N, d_1, ..., d_k)
198 - y: Array of labels, of shape (N,)
199 - num_samples: If not None, subsample the data and only test the model
200 on num_samples datapoints.
201 - batch_size: Split X and y into batches of this size to avoid using too
202 much memory.
203
204 Returns:
205 - acc: Scalar giving the fraction of instances that were correctly
206 classified by the model.
207 """
208
209 # Maybe subsample the data
210 N = X.shape[0]
211 if num_samples is not None and N > num_samples:
212 # 随机选取num_samples张图片,返回选取图片索引
213 mask = np.random.choice(N, num_samples)
214 N = num_samples
215 X = X[mask]
216 y = y[mask]
217
218 # Compute predictions in batches
219 num_batches = N // batch_size
220 if N % batch_size != 0:
221 num_batches += 1
222 y_pred = []
223 for i in range(num_batches):
224 start = i * batch_size
225 end = (i + 1) * batch_size
226 scores = self.model.loss(X[start:end])
227 y_pred.append(np.argmax(scores, axis=1))
228 y_pred = np.hstack(y_pred)
229 acc = np.mean(y_pred == y)
230
231 return acc
232
233 '''
234 训练模型:核心方法
235 epoch > batch_size > iteration >= 1
236 训练总的次数 = num_epochs * iterations_per_epoch
237 '''
238 def train(self):
239 """
240 Run optimization to train the model.
241 """
242 num_train = self.X_train.shape[0]
243 iterations_per_epoch = max(num_train // self.batch_size, 1)
244 num_iterations = self.num_epochs * iterations_per_epoch
245 # 迭代总的次数
246 for t in range(num_iterations):
247 # 某次iteration训练
248 self._step()
249
250 # Maybe print training loss
251 # verbose:是否显示详细信息
252 if self.verbose and t % self.print_every == 0:
253 print ('(Iteration %d / %d) loss: %f' % (
254 t + 1, num_iterations, self.loss_history[-1]))
255
256 # At the end of every epoch, increment the epoch counter and decay the
257 # learning rate.
258 # 每迭代完一次epoch后,更新学习率learning_rate,加快运算效率。
259 epoch_end = (t + 1) % iterations_per_epoch == 0
260 if epoch_end:
261 self.epoch += 1
262 for k in self.optim_configs:
263 self.optim_configs[k]['learning_rate'] *= self.lr_decay
264
265 # Check train and val accuracy on the first iteration, the last
266 # iteration, and at the end of each epoch.
267 # 在第1次迭代,最后1次迭代,或者运行完一个epoch后,校验训练结果。
268 first_it = (t == 0)
269 last_it = (t == num_iterations + 1)
270 if first_it or last_it or epoch_end:
271 train_acc = self.check_accuracy(self.X_train, self.y_train,
272 num_samples=4)
273 val_acc = self.check_accuracy(self.X_val, self.y_val,num_samples=4)
274 self.train_acc_history.append(train_acc)
275 self.val_acc_history.append(val_acc)
276
277 if self.verbose:
278 print ('(Epoch %d / %d) train acc: %f; val_acc: %f' % (
279 self.epoch, self.num_epochs, train_acc, val_acc))
280
281 # Keep track of the best model
282 if val_acc > self.best_val_acc:
283 self.best_val_acc = val_acc
284 self.best_params = {}
285 for k, v in self.model.params.items():
286 self.best_params[k] = v.copy()
287
288 # At the end of training swap the best params into the model
289 self.model.params = self.best_params
5.运行结果以及分析
这里选取500张图片作为训练样本,epoch = 5,batch = 2,每次随机选取2张图片,迭代 5 * 500/2 = 1250次,测试样本选取50张。
由运行结果可以看出,损失loss是逐步下降的。
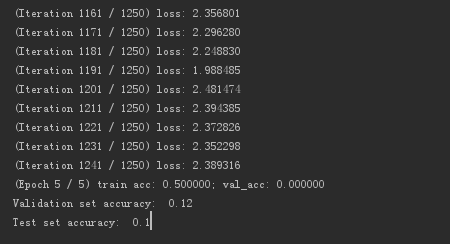
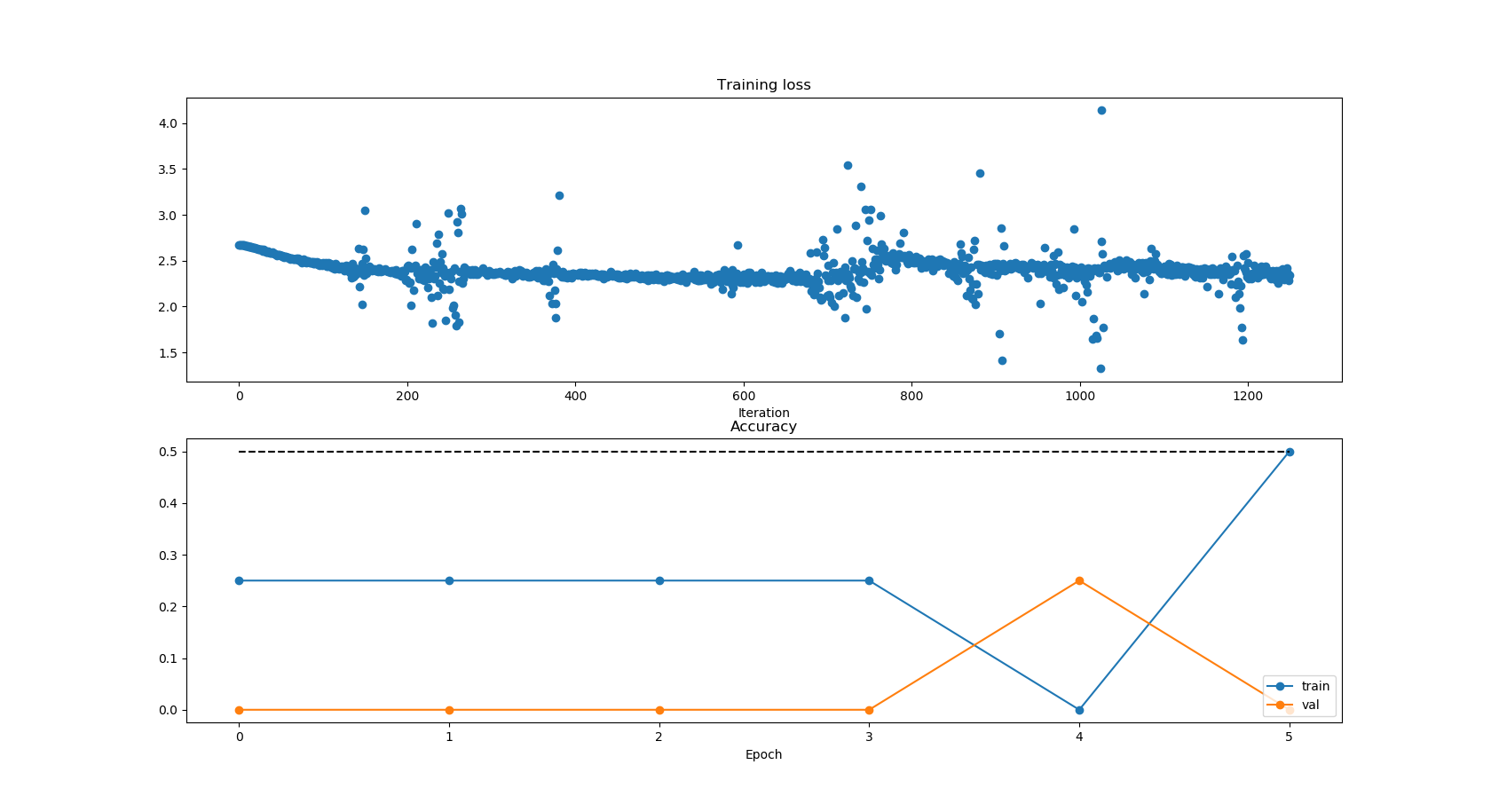
测试结果只有12%左右,原因有以下几点:
1. 模型比较简单,特征提取不能反映真实特征(一次卷积);
2. 会出现过拟合问题;
3. 原始训练数据分类图片纹理复杂,这些图片可变性大,从而导致分类结果准确度低;
(airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck)
后续会通过tensorflow来实现CNN,测试准确率可以达到71.95%。
6. 参考文献
视觉一只白的博客《常用损失函数小结》https://blog.csdn.net/zhangjunp3/article/details/80467350
理想万岁的博客《Softmax函数详解与推导》:http://www.cnblogs.com/zongfa/p/8971213.html
下路派出所的博客《深度学习(九) 深度学习最全优化方法总结比较(SGD,Momentum,Nesterov Momentum,Adagrad,Adadelta,RMSprop,Adam)》
http://www.cnblogs.com/callyblog/p/8299074.html
不要让懒惰占据你的大脑,不要让妥协拖垮了你的人生。青春就是一张票,能不能赶上时代的快车,你的步伐就掌握在你的脚下。
