MySQL 删除后插入 与 插入或更新
MySQL 删除后插入 与 插入或更新
一般操作:查询->判断【(存在更新,不存在插入)或(存在删除插入,不存在插入)】
在单条插入/更新的时候这样做是没有问题的,但是在批量导入的环境下由于数据量过大所以这里出现里的严重的性能问题
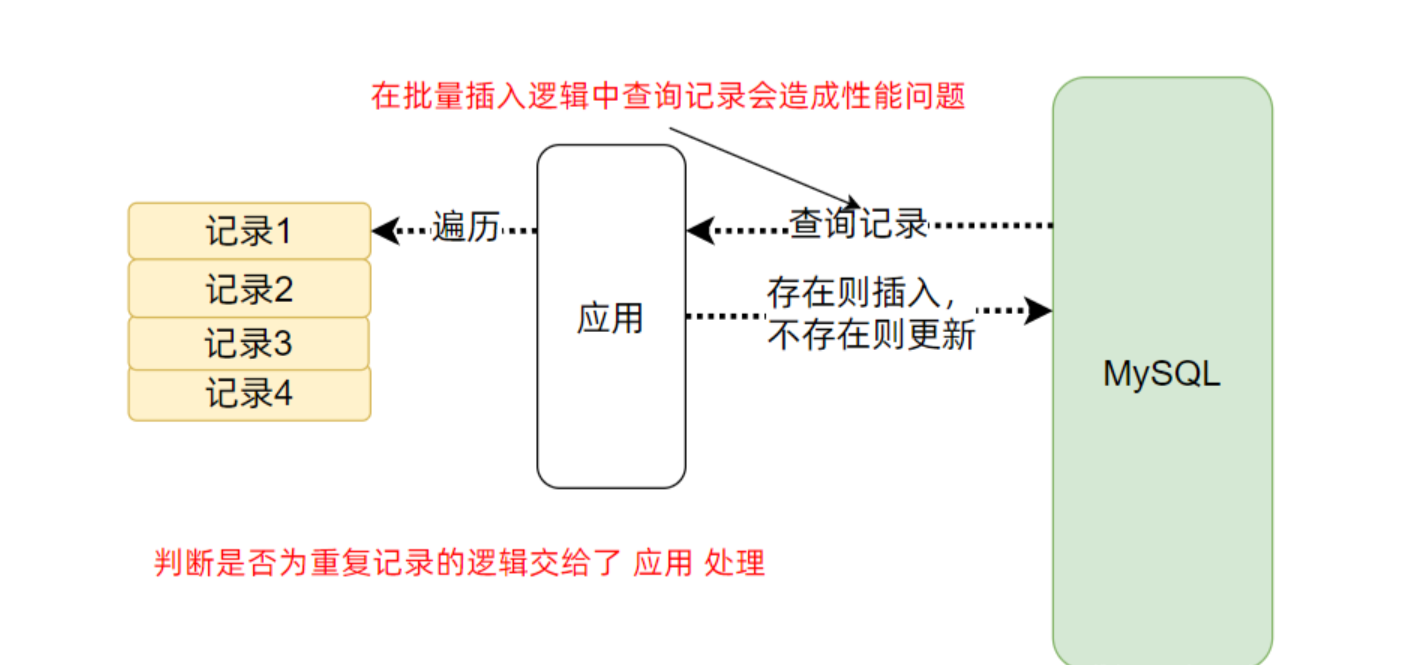
优化方案 “插入或更新” INSERT FOR UPDATE
INSERT FOR UPDATE语法
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[(col_name [, col_name] ...)]
{VALUES | VALUE} (value_list) [, (value_list)] ...
[ON DUPLICATE KEY UPDATE assignment_list]
带有
ON DUPLICATE KEY UPDATE的INSERT语句允许当插入一行时由于唯一索引或者主键索引而产生的重复值情况时则对已经存在的行执行更新操作。
-- 演示数据
DROP TABLE IF EXISTS test;
CREATE TABLE test (
id INT PRIMARY KEY auto_increment,
name VARCHAR ( 30 ) UNIQUE NOT NULL COMMENT '姓名',
age INT COMMENT '年龄',
address VARCHAR ( 100 ) COMMENT '地址',
version int(11) not null default 1 COMMENT '版本',
update_time datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) COMMENT '测试表';
-- 单条插入或更新的 SQL 可以这样写
-- 注意这样实现的方式不支持批量,否则就有批量记录的所有 name 都更新成了张三,age 更新成了 22
INSERT INTO test ( name, age, address ) VALUE ( '李四', 20, '上海' ) ON DUPLICATE KEY UPDATE name = "张三", age = 22;
-- 在批量插入或更新时我们的 UPDATE 可以通过 VALUES(field) 获取我们插入的对应记录的值
-- 如 name = VALUES(name) 则表示将 name 更新成为我们输入的值
-- 通过 VALUES() 函数获取在(VALUE|VALUES) 中映射的对应的值
INSERT INTO test ( NAME, age, address )
VALUES
( '张三', 199, '北京市' ),
( '王五', 221, '天津市' )
ON DUPLICATE KEY UPDATE
name = VALUES ( name ),
age = VALUES ( age );
-- 这里的插入逻辑表示当存在id为1 的记录时则更新 name 为输入的name,age为输入的age
-- 这里当我们的记录发生重复的时候我们只更新 age 字段,同时将我们的 version 字段加1
INSERT INTO test ( id, NAME, age, address )
VALUE
( 1, '李四', 20, '上海' )
ON DUPLICATE KEY UPDATE
age = VALUES ( age ),
version = version + 1,
update_time = date_add( now(), INTERVAL 1 DAY );
on duplicate key update 使用总结
-
on duplicate key update 语句根据主键id或唯一键来判断当前插入是否已存在。
-
记录已存在时,只会更新on duplicate key update之后指定的字段。
-
如果同时传递了主键和唯一键,以主键为判断存在依据,唯一键字段内容可以被修改。
-
on dupdate key update之后没有用values的情况
- name = "abc",则会一直更新为"abc".
- name = name ,则name会保持数据库中的值
-
对values使用判断name = ifnull(values(name),name)达到的效果是,如果传入的name值为null,则不更新。不为null则更新
优化方案 “删除后插入” REPLACE INTO
REPLACE INTO 语法
REPLACE [LOW_PRIORITY | DELAYED]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
[(col_name [, col_name] ...)]
{VALUES | VALUE} (value_list) [, (value_list)] ...
REPLACE INTO的语法其实和INSERT INTO的语法已经很像了,不同的是REPLACE INTO在遇到由于主键或唯一键导致的重复记录时,它会首先删除已经存在的记录,然后再插入新的记录
-- 当 id=1 的记录存在时,会删除原有记录,然后插入我们给出的记录
REPLACE INTO test ( id, NAME, age, address )
VALUES
( 1, '张三', 199, '北京市' );
总结:使用过程中,主要看主键跟唯一键


 浙公网安备 33010602011771号
浙公网安备 33010602011771号