
基于mysql实现group by 取分组第一条 最后一条
测试数据
DROP TABLE IF EXISTS `tb_dept`;
CREATE TABLE `tb_dept` (
`id` bigint(20) UNSIGNED NOT NULL,
`parent_id` bigint(20) NULL DEFAULT NULL,
`dept_code` char(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`dept_name` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_parent_id_code`(`parent_id`, `dept_code`) USING BTREE,
INDEX `idx_code_parent_id`(`dept_code`, `parent_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '部门表' ROW_FORMAT = Dynamic;
INSERT INTO `tb_dept` VALUES (1, NULL, '01', '葫芦科技');
INSERT INTO `tb_dept` VALUES (2, 1, '001', '运营部');
INSERT INTO `tb_dept` VALUES (3, 1, '002', '技术部');
INSERT INTO `tb_dept` VALUES (4, 1, '003', '产品部');
INSERT INTO `tb_dept` VALUES (5, 1, '004', '设计部');
INSERT INTO `tb_dept` VALUES (6, 2, '00101', '运营一部');
INSERT INTO `tb_dept` VALUES (7, 2, '00102', '运营二部');
INSERT INTO `tb_dept` VALUES (8, 3, '00201', '技术一部');
INSERT INTO `tb_dept` VALUES (9, 3, '00202', '技术二部');
INSERT INTO `tb_dept` VALUES (10, 3, '00203', '技术三部');
INSERT INTO `tb_dept` VALUES (11, 3, '00204', '技术四部');
INSERT INTO `tb_dept` VALUES (12, 4, '00301', '运营一部');
INSERT INTO `tb_dept` VALUES (13, 4, '00302', '运营二部');
INSERT INTO `tb_dept` VALUES (14, 4, '00303', '运营三部');
INSERT INTO `tb_dept` VALUES (15, 5, '00401', '设计一部');
INSERT INTO `tb_dept` VALUES (16, 8, '0020101', '技术一部一组');
INSERT INTO `tb_dept` VALUES (17, 8, '0020102', '技术一部二组');
INSERT INTO `tb_dept` VALUES (18, 9, '0020201', '技术二部一组1111');
INSERT INTO `tb_dept` VALUES (19, 10, '0020301', '技术三部一组');
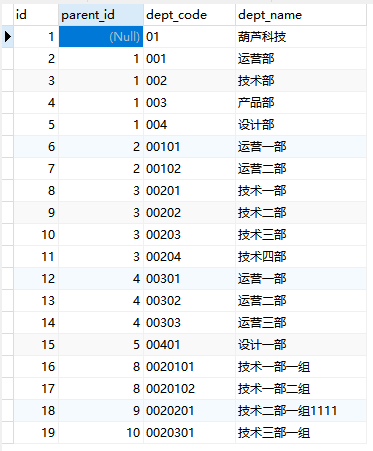
获取分组里的首条数据
SELECT
*,
GROUP_CONCAT( dept_code )
FROM
tb_dept
GROUP BY
dept_name
sql语句后面跟不跟排序都不起作用 按默认asc排序 留首条
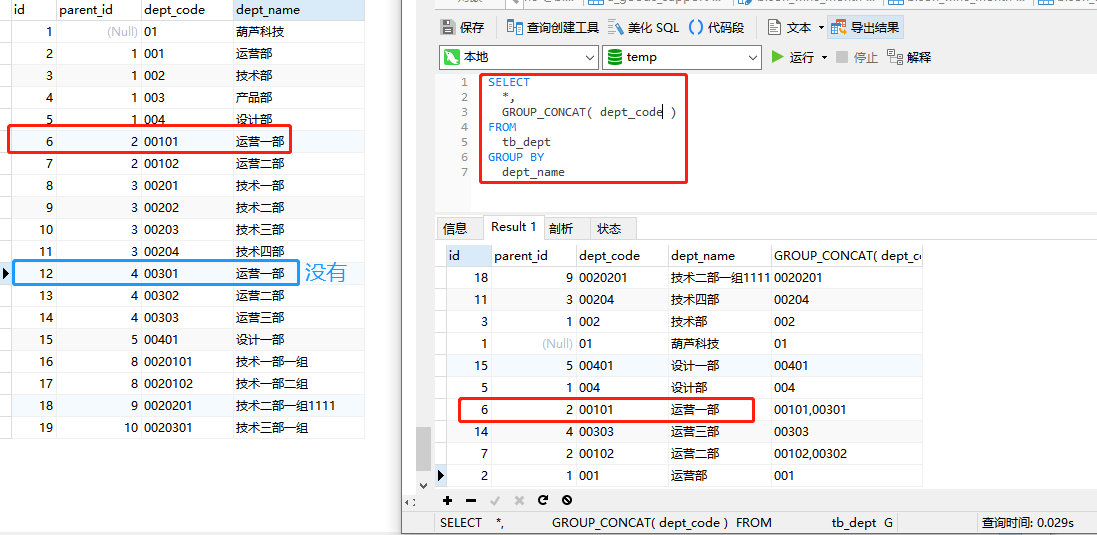
获取分组里的最后一条数据
- 先order by之后再分组(注意:不加LIMIT可能会无效,由于mysql的版本问题)
SELECT
*,
GROUP_CONCAT( dept_code )
FROM
( SELECT * FROM tb_dept ORDER BY id DESC LIMIT 10000 ) a
GROUP BY
dept_name;
有缺点就是limit条件有局限性
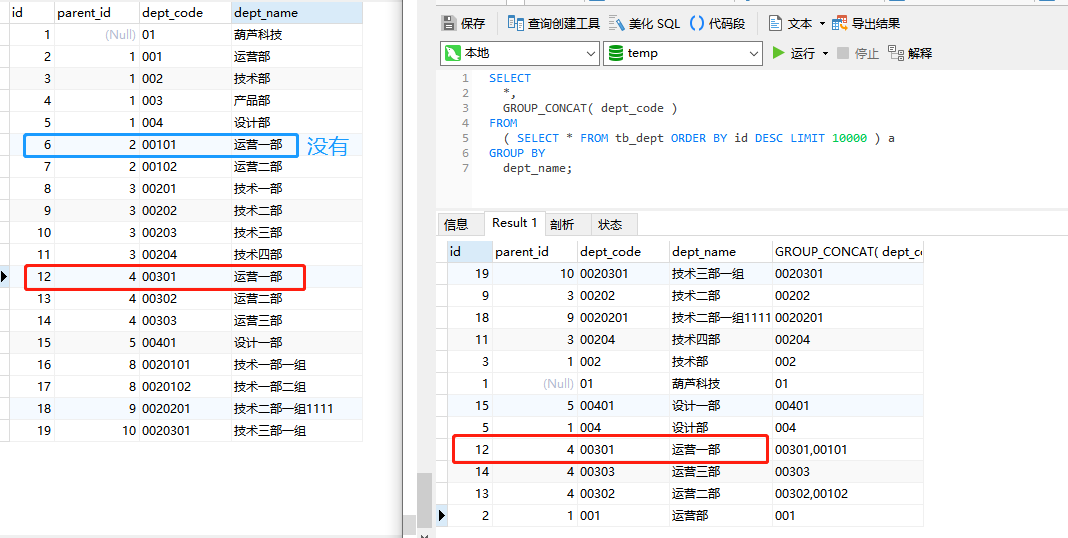
- 利用max() 函数:(根据业务, max(id))
SELECT
*
FROM
tb_dept td,
( SELECT max( id ) id FROM tb_dept GROUP BY dept_name ) md
WHERE
td.id = md.id;
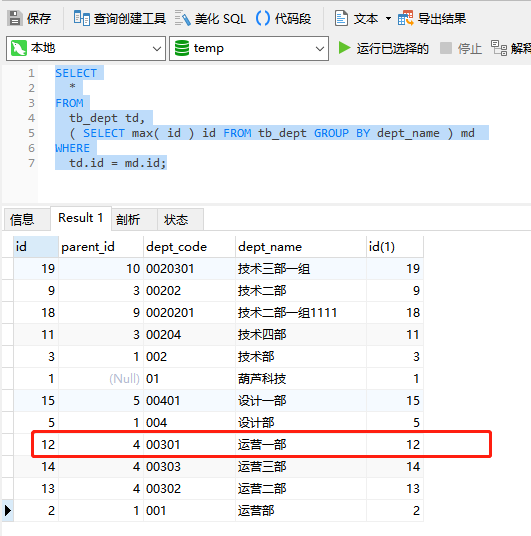
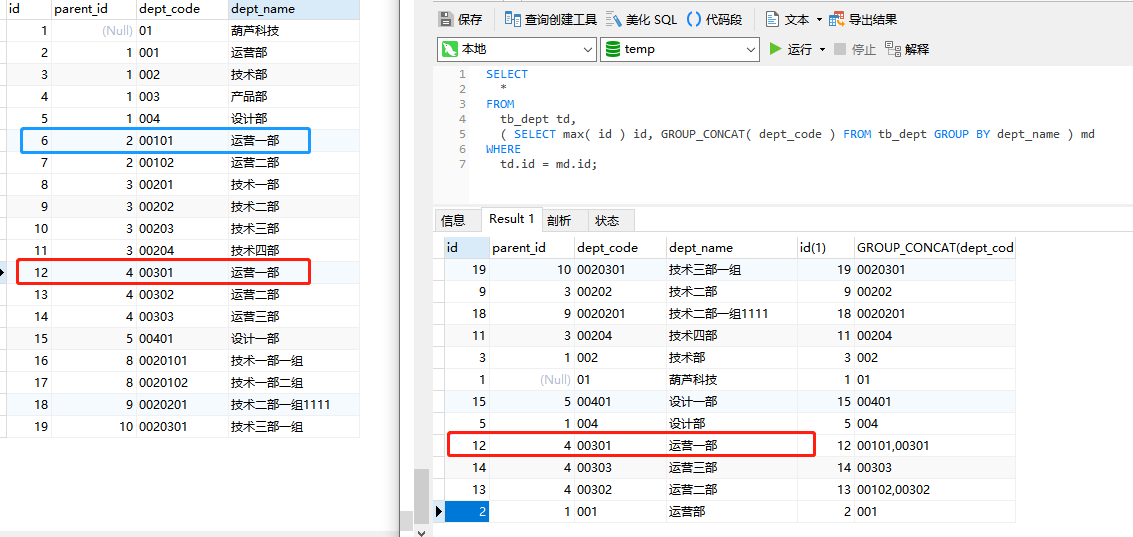
SELECT
*
FROM
tb_dept td,
( SELECT max( id ) id, GROUP_CONCAT( dept_code ) FROM tb_dept GROUP BY dept_name ) md
WHERE
td.id = md.id;
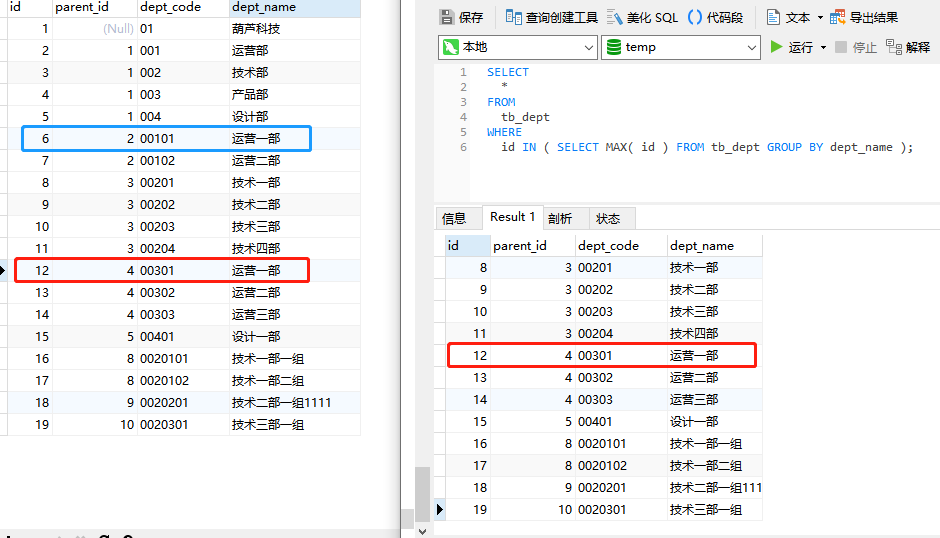
- 利用 where 字段名称 in (...) 函数
SELECT
*
FROM
tb_dept
WHERE
id IN ( SELECT MAX( id ) FROM tb_dept GROUP BY dept_name );



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?