Hadoop大数据通用处理平台
Hadoop
Hadoop是一款开源的大数据通用处理平台,其提供了3个组件,分别是HDFS分布式文件系统、YARN分布式资源调度、MapReduce分布式离线计算。
MapReduce适合大规模的数据同时对实时性要求不高的场景,不适合大量的小文件以及频繁修改的文件。
Hadoop的特点
1.水平扩展:Hadoop集群可以达到上千个节点,同时能够动态的新增和删除节点,能够存储和处理PB级的数据量。
2.低成本:不需要依赖机器的性能,只需要普通的PC机就能运行。
目前一般会使用HDFS作为文件存储,使用YARN对资源进行管理。
1.HDFS
HDFS是分布式文件系统,可以存储海量的文件。
HDFS由NameNode、DataNode、SecondaryNameNode节点组成。
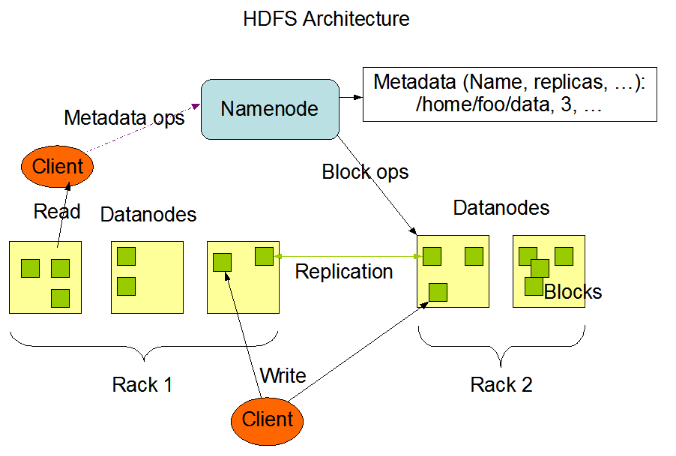
1.1 关于Block数据块
Block是HDFS中最小的存储单元,每个Block的大小默认为128M。
一个大文件会被拆分成多个Block进行存储,如果一个文件的大小小于Block的大小,那么Block实际占用的大小为文件本身的大小。
每个Block都会在不同的DataNode节点中存在备份。
1.2 DataNode节点
DataNode节点用于保存Block,同时负责数据的读写和复制操作。
DataNode节点启动时会向NameNode节点汇报当前存储的Block信息。
1.3 NameNode节点
NameNode节点用于存储文件的元信息、文件与Block和DataNode的关系。
NameNode运行时的所有数据都保存在内存当中,因此整个HDFS可存储的文件数量受限于NameNode节点的内存大小。
NameNode节点中的数据会定时保存到磁盘文件当中(只有文件的元信息),但不保存文件与Block和DataNode的关系,这部分数据由DataNode启动时上报和运行时维护。
DataNode节点会定期向NameNode节点发送心跳请求,一旦NameNode节点在一定的时间内没有收到DataNode节点发送的心跳则认为其已经宕机,不会再给该DataNode节点分配任何的IO请求。
每个Block在NameNode中都对应一条记录,如果是大量的小文件将会消耗大量内存,因此HDFS适合存储大文件。
1.4 SecondaryNameNode
SecondaryNameNode节点会定时与NameNode节点进行同步(HA)
往HDFS写入文件的流程
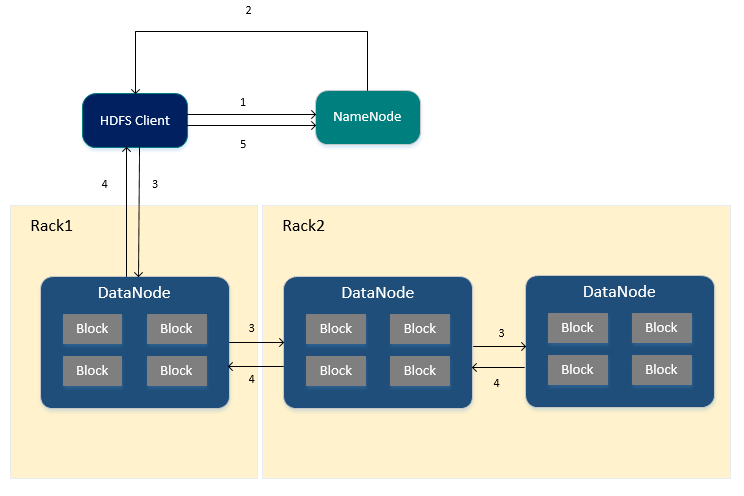
1.HDFS Client向NameNode节点申请写入文件。
2.NameNode节点根据文件的大小,返回文件要写入的BlockId以及DataNode节点列表,同时存储文件的元信息以及文件与Block和DataNode节点之间的关系。
3.HDFS Client接收到NameNode节点的返回之后,会将数据依次写入到指定的DataNode节点当中,每个DataNode节点接收到数据之后会把数据写入到磁盘文件,然后将数据同步给其他的DataNode节点进行备份(备份数-1个DataNode节点)
4.在进行备份的过程中,每一个DataNode节点接收到数据后都会向前一个DataNode节点进行响应,最终第一个DataNode节点返回HDFS Client成功。
5.当HDFS Client接收到DataNode节点的响应后,会向NameNode节点发送最终确认请求,此时NameNode节点才会提交文件。
在进行备份的过程中,如果某个DataNode节点写入失败,NameNode节点会重新寻找DataNode节点继续复制,以保证数据的可靠性。
只有当向NameNode节点发送最终确认请求后文件才可见,如果在发送最终确认请求前NameNode就已经宕机,那么文件将会丢失。
从HDFS读取文件的流程
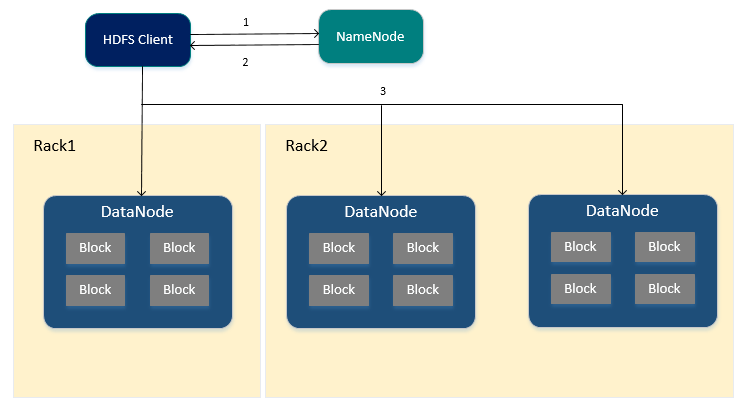
1.HDFS Client向NameNode节点申请读取文件。
2.NameNode节点返回文件所有对应的BlockId以及这些BlockId所在的DataNode节点列表(包括备份节点)
3.HDFS Client会优先从本地的DataNode中进行读取Block,否则通过网络从备份节点中进行读取。
机架感知
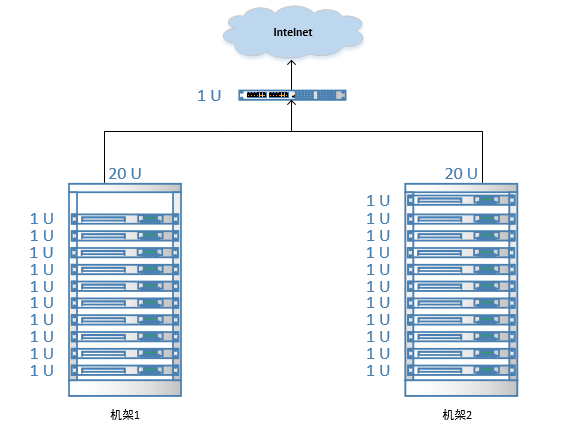
分布式集群中通常会包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群。
机架内的机器之间的网络速度通常高于跨机架机器之间的网络速度,并且机架之间机器的网络通信通常会受到上层交换机网络带宽的限制。
Hadoop默认没有开启机架感知功能,默认情况下每个Block都是随机分配DataNode节点,当Hadoop开启机架感知功能后,那么当NameNode节点启动时,会将机器与机架之间的关系保存在内存中,当HDFS Client申请写入文件时,能够根据预先定义的机架关系合理的分配DataNode。
机架感知默认对Block的3个备份的存放策略
第1个Block备份存放在与HDFS Client同一个节点的DataNode节点中(若HDFS Client不在集群范围内则随机选取)
第2个Block备份存放在与第一个节点不同机架下的节点中。
第3个Block备份存放在与第2个备份所在节点的机架下的另一个节点中,如果还有更多的副本则随机存放在集群的节点中。
使用此策略可以保证对文件的访问能够优先在本机架下找到,并且如果整个机架上发生了异常也可以在另外的机架上找到该Block的备份。
2 YARN
YARN是分布式资源调度框架,由ResourceManger、NodeManager以及ApplicationMaster组成。
2.1 ResourceManager
ResourceManager是集群的资源管理者,负责集群中资源的分配以及调度,同时管理各个NodeManager,同时负责处理客户端的任务请求。
2.2 NodeManager
NodeManager是节点的管理者,负责处理来自ResourceManager和ApplicationMaster的请求。
2.3 ApplicationMaster
ApplicationMaster用于计算任务所需要的资源。
2.4 任务运行在YARN的流程
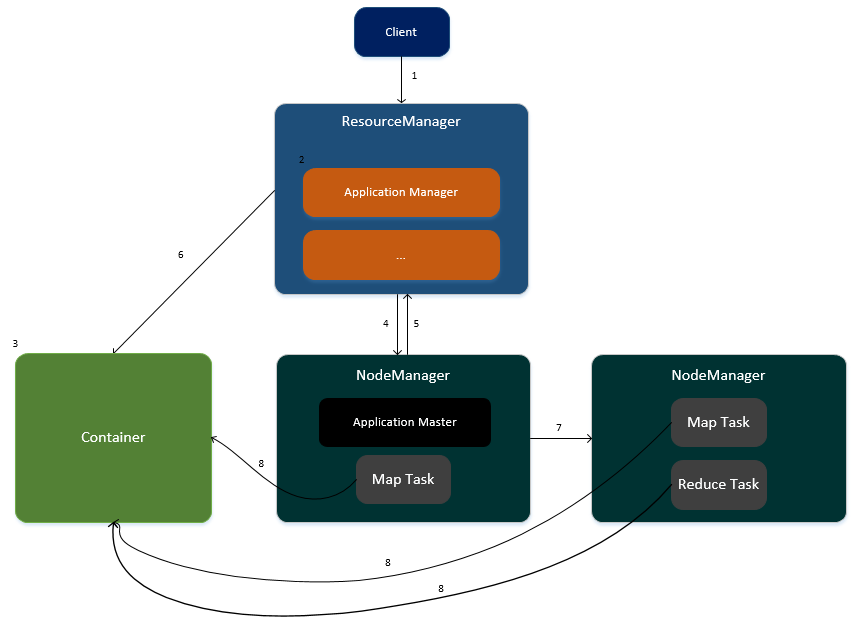
1.客户端向ResourceManager提交任务请求。
2.ResourceManager生成一个ApplicationManager进程,用于任务的管理。
3.ApplicationManager创建一个Container容器用于存放任务所需要的资源。
4.ApplicationManager寻找其中一个NodeManager,在此NodeManager中启动一个ApplicationMaster,用于任务的管理以及监控。
5.ApplicationMaster向ResourceManager进行注册,并计算任务所需的资源汇报给ResourceManager(CPU与内存)
6.ResourceManager为此任务分配资源,资源封装在Container容器中。
7.ApplicationMaster通知集群中相关的NodeManager进行任务的执行。
8.各个NodeManager从Container容器中获取资源并执行Map、Reduce任务。
3 MapReduce
MapReduce是分布式离线计算框架,其原理是将数据拆分成多份,然后通过多个节点并行处理。
MapReduce执行流程
MapReduce分为Map任务以及Reduce任务两部分。
3.1 Map任务
1.读取文件中的内容,解析成Key Value的形式 (Key为偏移量,Value为每行的数据)
2.重写map方法,生成新的Key和Value。
3.对输出的Key和Value进行分区。
4.将数据按照Key进行分组,key相同的value放到一个集合中(数据汇总)
处理的文件必须要在HDFS中。
3.2 Reduce任务
1.对多个Map任务的输出,按照不同的分区,通过网络复制到不同的reduce节点。
2.对多个Map任务的输出进行合并、排序。
3.将reduce的输出保存到文件,存放在HDFS中。
4.搭建Hadoop
4.1 安装
1.由于Hadoop使用Java语言进行编写,因此需要安装JDK。
2.从CDH中下载Hadoop 2.X并进行解压,CDH是Cloudrea公司对各种开源框架的整合与优化(较稳定)

4.2 修改配置
1.修改环境配置
编辑etc/hadoop/hadoop-env.sh文件,修改JAVA_HOME配置(此文件是Hadoop启动时加载的环境变量)
编辑/etc/hosts文件,添加主机名与IP的映射关系。

2.配置Hadoop公共属性(core-site.xml)
<configuration> <!-- Hadoop工作目录,用于存放Hadoop运行时产生的临时数据 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop/hadoop-2.9.0/data</value> </property> <!-- NameNode的通信地址,1.x默认9000,2.x可以使用8020 --> <property> <name>fs.default.name</name> <value>hdfs://192.168.1.80:8020</value> </property> </configuration>
3.配置HDFS(hdfs-site.xml)
<configuration> <!--指定block的备份数量(将block复制到集群中备份数-1个DataNode节点中)--> <property> <name>dfs.replication</name> <value>1</value> </property> <!-- 关闭HDFS的访问权限 --> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> </configuration>
4.配置YARN(yarn-site.xml)
<configuration> <!-- 配置Reduce取数据的方式是shuffle(随机) --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
5.配置MapReduce(mapred-site.xml)
<configuration> <!-- 让MapReduce任务使用YARN进行调度 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
6.配置SSH
由于在启动HDFS和YARN时都需要对用户的身份进行验证,因此可以配置SSH设置免密码登录。
//生成秘钥
ssh-keygen -t rsa
//复制秘钥到本机
ssh-copy-id 192.168.1.80
4.3 启动HDFS
1.格式化NameNode
bin/hdfs namenode -format

2.启动HDFS
sbin/start-dfs.sh

启动HDFS后将会启动NameNode、DataNode、SecondaryNameNode三个进程。

启动时若出现错误可以进入logs目录查看相应的日志文件。
3.访问HDFS的可视化管理界面
当HDFS启动完毕后,可以访问http://localhost:50070进入HDFS的可视化管理界面,在此页面中可以对整个HDFS集群进行监控以及文件的上传和下载。
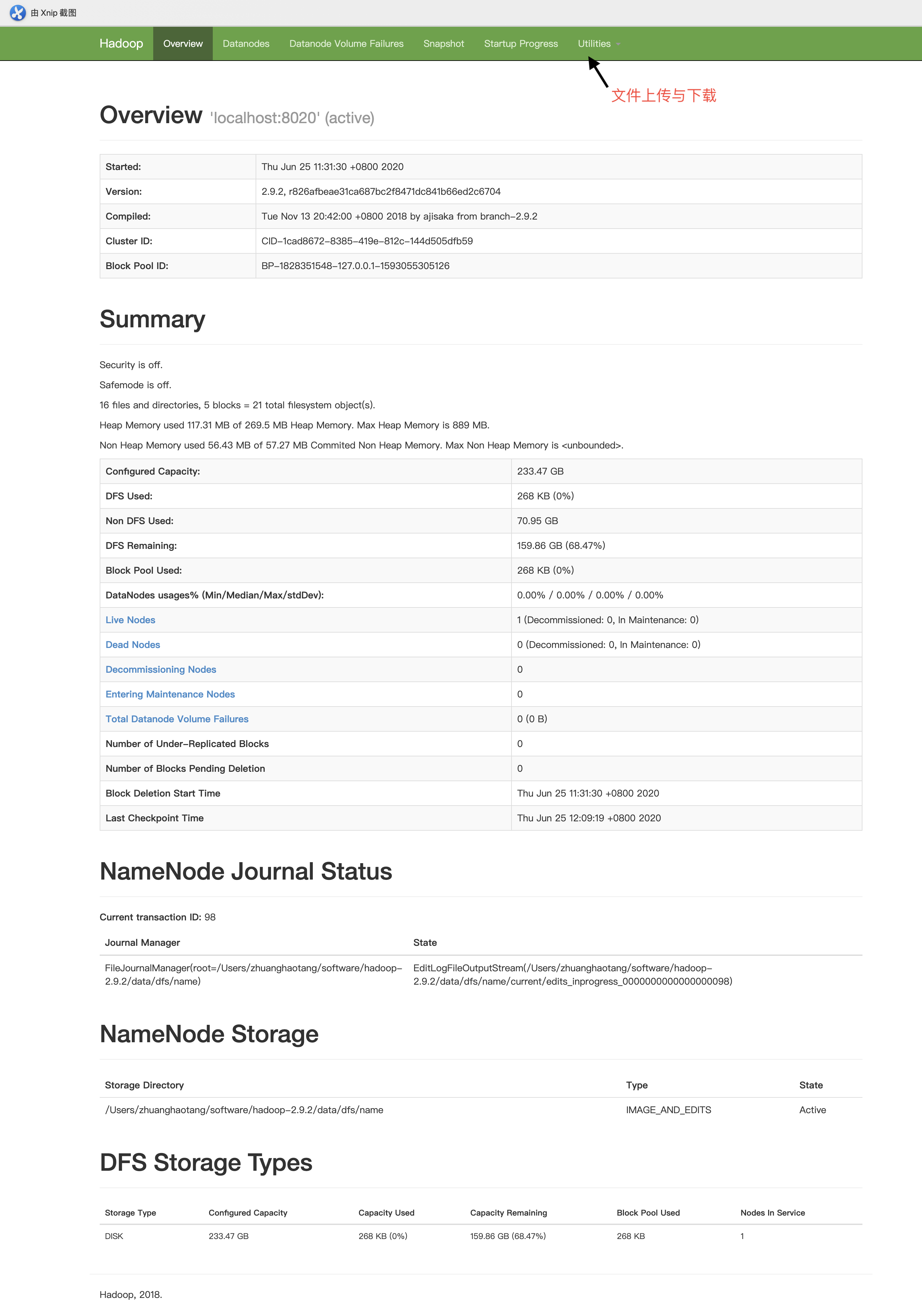
当下载文件时会进行请求的重定向,重定向的地址的host为NameNode的主机名,因此客户端本地的host文件中需要配置NameNode主机名与IP的映射关系。
4.4 启动YARN
sbin/start-yarn.sh

启动YARN后,将会启动ResourceManager以及NodeManager进程。

可以访问http://localhost:8088进入YARN的可视化管理界面,可以在此页面中查看任务的执行情况以及资源的分配。

4.5 使用Shell操作HDFS
HDFS与Linux类似,有/根目录。
#显示文件中的内容 bin/hadoop fs -cat <src> 将本地中的文件上传到HDFS bin/hadoop fs -copyFromLocal <localsrc> <dst> #将本地中的文件上传到HDFS bin/hadoop fs -put <localsrc> <dst> #将HDFS中的文件下载到本地 bin/hadoop fs -copyToLocal <src> <localdst> #将HDFS中的文件下载到本地 bin/hadoop fs -get <src> <localdst> #将本地中的文件剪切到HDFS中 bin/hadoop fs -moveFromLocal <localsrc> <dst> #将HDFS中的文件剪切到本地中 bin/hadoop fs -moveToLocal <src> <localdst> #在HDFS内对文件进行移动 bin/hadoop fs -mv <src> <dst> #在HDFS内对文件进行复制 bin/hadoop fs -cp <src> <dst> #删除HDFS中的文件 bin/hadoop fs -rm <src> #创建目录 bin/hadoop fs -mkdir <path> #查询指定路径下文件的个数 bin/hadoop fs -count <path> #显示指定目录下的内容 bin/hadoop fs -ls <path>
4.6 使用JAVA操作HDFS
/** * @Auther: ZHUANGHAOTANG * @Date: 2018/11/6 11:49 * @Description: */ public class HDFSUtils { private static Logger logger = LoggerFactory.getLogger(HDFSUtils.class); /** * NameNode URL */ private static final String NAMENODE_URL = "192.168.1.80:8020"; /** * HDFS文件系统连接对象 */ private static FileSystem fs = null; static { Configuration conf = new Configuration(); try { fs = FileSystem.get(URI.create(NAMENODE_URL), conf); } catch (IOException e) { logger.info("初始化HDFS连接失败:{}", e); } } /** * 创建目录 */ public static void mkdir(String dir) throws Exception { dir = NAMENODE_URL + dir; if (!fs.exists(new Path(dir))) { fs.mkdirs(new Path(dir)); } } /** * 删除目录或文件 */ public static void delete(String dir) throws Exception { dir = NAMENODE_URL + dir; fs.delete(new Path(dir), true); } /** * 遍历指定路径下的目录和文件 */ public static List<String> listAll(String dir) throws Exception { List<String> names = new ArrayList<>(); dir = NAMENODE_URL + dir; FileStatus[] files = fs.listStatus(new Path(dir)); for (FileStatus file : files) { if (file.isFile()) { //文件 names.add(file.getPath().toString()); } else if (file.isDirectory()) { //目录 names.add(file.getPath().toString()); } else if (file.isSymlink()) { //软或硬链接 names.add(file.getPath().toString()); } } return names; } /** * 上传当前服务器的文件到HDFS中 */ public static void uploadLocalFileToHDFS(String localFile, String hdfsFile) throws Exception { hdfsFile = NAMENODE_URL + hdfsFile; Path src = new Path(localFile); Path dst = new Path(hdfsFile); fs.copyFromLocalFile(src, dst); } /** * 通过流上传文件 */ public static void uploadFile(String hdfsPath, InputStream inputStream) throws Exception { hdfsPath = NAMENODE_URL + hdfsPath; FSDataOutputStream os = fs.create(new Path(hdfsPath)); BufferedInputStream bufferedInputStream = new BufferedInputStream(inputStream); byte[] data = new byte[1024]; int len; while ((len = bufferedInputStream.read(data)) != -1) { if (len == data.length) { os.write(data); } else { //最后一次读取 byte[] lastData = new byte[len]; System.arraycopy(data, 0, lastData, 0, len); os.write(lastData); } } inputStream.close(); bufferedInputStream.close(); os.close(); } /** * 从HDFS中下载文件 */ public static byte[] readFile(String hdfsFile) throws Exception { hdfsFile = NAMENODE_URL + hdfsFile; Path path = new Path(hdfsFile); if (fs.exists(path)) { FSDataInputStream is = fs.open(path); FileStatus stat = fs.getFileStatus(path); byte[] data = new byte[(int) stat.getLen()]; is.readFully(0, data); is.close(); return data; } else { throw new Exception("File Not Found In HDFS"); } } }
4.7 执行一个MapReduce任务
Hadoop提供了hadoop-mapreduce-examples-2.9.0.jar,其封装了很多任务计算的方法,用户可以直接进行调用。
#使用hadoop jar命令来执行JAR包
hadoop jar
1.创建一个文件同时将此文件上传到HDFS中
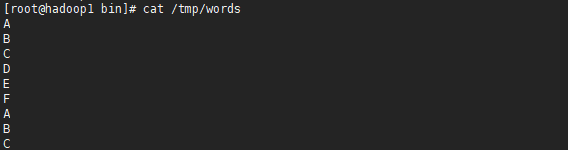
2.使用Hadoop提供的hadoop-mapreduce-examples-2.9.0.jar执行wordcount词频统计功能
bin/hadoop jar /usr/hadoop/hadoop-2.0.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar wordcount /words /result

3.在YARN的可视化管理界面中可以查看任务的执行情况
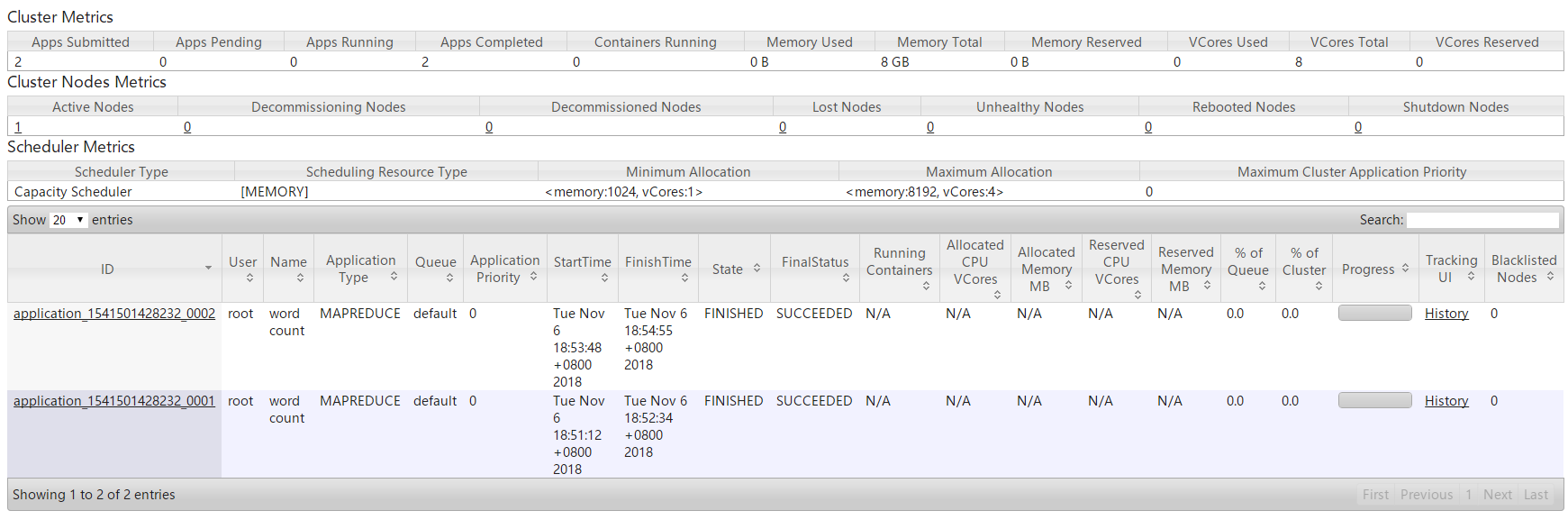
4.当任务执行完毕后可以查看任务的执行结果

任务的执行结果将会保存到HDFS的文件中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号