Flume日志采集系统
1.简介
Flume是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统。
Flume支持在日志系统中定制各类数据发送方用于收集数据,同时Flume提供对数据进行简单的处理并写到各种数据接受方的能力。
当前Flume有两个版本,Flume 0.9X版本的统称Flume-og,Flume1.X版本的统称Flume-ng (由于Flume-ng经过重大重构与Flume-og有很大不同,使用时需注意区分)
两个版本的区别
Flume-og采用了多Master的方式,为了保证配置数据的一致性,Flume引入了ZooKeeper用于保存配置文件,在配置文件发生变化时,ZooKeeper可以通知Flume Master节点,Flume Master间使用gossip协议同步数据。
Flume-og中读入线程同样做写操作,如果写出慢的话将阻塞 Flume 接收数据的能力。
Flume-ng最明显的改动就是取消了集中管理配置的 Master 和 Zookeeper,变为一个纯粹的传输工具。
Flume-ng读入数据和写出数据现在由不同的工作线程处理(Runner),这种异步的设计使读入线程可以顺畅的工作而无需关注下游的任何问题。
Flume的优势
1.Flume可以将应用产生的数据存储到任何集中存储器中,比如HDFS、HBase。
2.当收集数据的速度超过写入数据的时候,此时Flume会在数据生产者和数据收容器间做出调整,保证其能够在两者之间提供平稳的数据。
3.Flume的管道是基于事务的,保证了数据在传送和接收时的一致性。
Flume的应用场景
1.Flume可以高效的将多个网站服务器的日志信息存入HDFS/HBase中。
2.除了日志信息以外,Flume也可以用来收集规模宏大的社交网络节点事件数据(比如facebook、twitter、亚马逊)
*本文只阐述Flume-ng版本的组件及使用。
2.Flume的结构模型
Flume由Source、Channel、Sink三大组件组成。
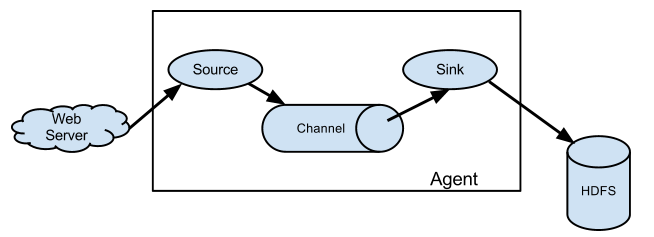
Source:从Client上收集数据并对数据进行格式化,以Event(事件)的形式传递给单个或多个Channel。
Flume的数据流由事件(Event)充当,事件是Flume的基本数据单位,事件携带日志数据(字节数组形式,包含头信息)
Channel:短暂的存储容器,将从Source接收到的Event进行缓存直到被Sink消费掉,Channel是Source和Sink之间的桥梁,Channal是一个完整的事务,能保证了数据在收发时的一致性,并且一个Channel可以同时和任意数量的Source和Sink建立连接。
Sink:从Channel中消费数据(Event)并传递到存储容器(Hbase、HDFS)或其他的Source中。
*Flume以Agent为最小的独立运行单元,Agent依赖于JVM,一个Agent的运行就伴随一个JVM实例的产生。
*一台机器可以运行多个Agent,一个Agent中可以包含多个Source和Sink。
3.各个组件的实现
*Flume提供了大量内置的Source、Channel和Sink类型,不同类型的Source,Channel和Sink可以自由组合,组合方式基于用户设置的配置文件。
Source组件

Channel组件
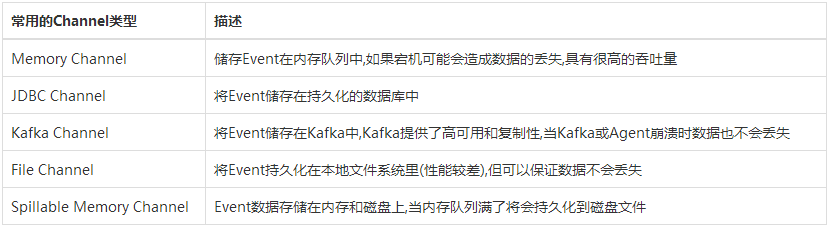
Sink组件

*不同类型的Source、Channel、Sink有其特定的属性,配置时需要根据实际情况去设置。
4.Flume的使用
1.安装
Flume依赖于JDK6以上的版本,因此首先要安装JDK并且添加环境变量JAVA_HOME。

从Flume官网中下载对应的tar.gz安装包 ,将下载后的安装包放到Linux中并进行解压(系统软件放到/usr目录下)
添加Flume的bin目录到PATH环境变量中以便使用

2. 配置文件
在flume的conf目录下创建flume.conf,在该配置文件中进行组件的配置。
#指定Agent的组件名称
agentA.sources = x
agentA.sinks = z
agentA.channels = y
#Source组件的相关配置
agentA.sources.x.type = spooldir
agentA.sources.x.spoolDir = /data
#Sink组件的相关配置
agentA.sinks.z.type = logger
#Channel组件的相关配置
agentA.channels.y.type = memory
agentA.channels.y.capacity = 1000
agentA.channels.y.transactionCapacity = 100
#绑定Source和Sink到Channel上
agentA.sources.x.channels = y
agentA.sinks.z.channel = y
使用Spooling Directory Source类型,监听/data目录下的文件.
使用Memory Channel,事件存储在内存中。
使用Logger Sink,将数据写入Flume的log中。
*当/data目录新增文件后,Spooling Directory Source就会读取文件中的数据,然后将数据以Event形式传给Channel,Logger Sink再消费Channel中的事件将数据写入Log中。
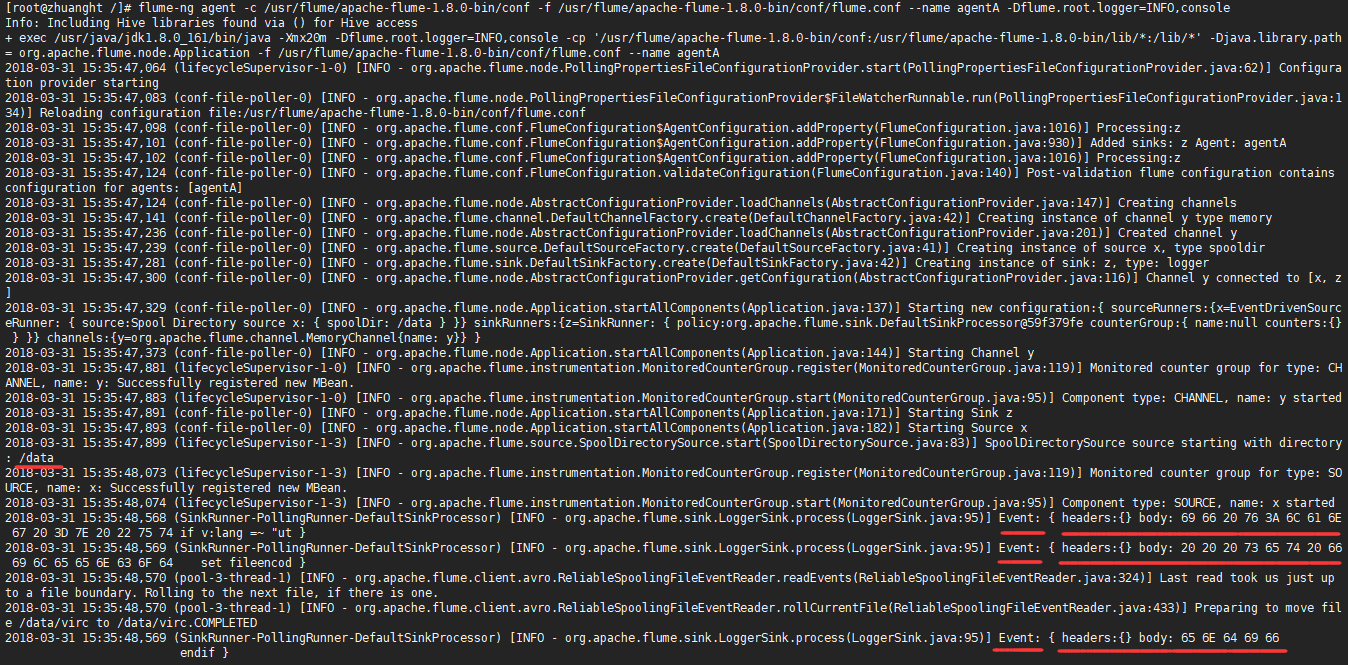
3 .启动
flume-ng agent -c $指定flume的conf目录 -f $指定使用的配置文件 --name $指定要启动的agent名称

 浙公网安备 33010602011771号
浙公网安备 33010602011771号