TensorFlow实现VGG识别10-monkey-species
In [1]:
from tensorflow import keras
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
In [2]:
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M']
}
In [3]:
def make_feature(cfg):
feature_layers = []
for v in cfg:
if v == 'M':
feature_layers.append(keras.layers.MaxPool2D(pool_size=2, strides=2))
else:
feature_layers.append(keras.layers.Conv2D(v, kernel_size=3, padding='SAME', activation='selu'))
return keras.Sequential(feature_layers, name='feature')
In [4]:
# 定义网络结构
def VGG(feature, height=224, width=224, classes=1000):
input_image = keras.layers.Input(shape=(height, width, 3), dtype=tf.float32)
x = feature(input_image)
x = keras.layers.Flatten()(x)
x = keras.layers.AlphaDropout(0.5)(x)
x = keras.layers.Dense(2048, activation='selu')(x)
x = keras.layers.AlphaDropout(0.5)(x)
x = keras.layers.Dense(2048, activation='selu')(x)
x = keras.layers.Dense(classes)(x)
output = keras.layers.Softmax()(x)
return keras.models.Model(inputs=input_image, outputs=output)
# 获取模型
def get_vgg_model(model_name='vgg16', height=224, width=224, classes=10):
cfg = cfgs[model_name]
return VGG(make_feature(cfg), height=height, width=width, classes=classes)
In [5]:
# 文件下载地址 https://www.kaggle.com/datasets/slothkong/10-monkey-species
train_dir = './10-monkey-species/training/training'
valid_dir = './10-monkey-species/validation/validation'
label_file = './10-monkey-species/monkey_labels.txt'
df = pd.read_csv(label_file, header=0)
df
| Label | Latin Name | Common Name | Train Images | Validation Images | |
|---|---|---|---|---|---|
| 0 | n0 | alouatta_palliata\t | mantled_howler | 131 | 26 |
| 1 | n1 | erythrocebus_patas\t | patas_monkey | 139 | 28 |
| 2 | n2 | cacajao_calvus\t | bald_uakari | 137 | 27 |
| 3 | n3 | macaca_fuscata\t | japanese_macaque | 152 | 30 |
| 4 | n4 | cebuella_pygmea\t | pygmy_marmoset | 131 | 26 |
| 5 | n5 | cebus_capucinus\t | white_headed_capuchin | 141 | 28 |
| 6 | n6 | mico_argentatus\t | silvery_marmoset | 132 | 26 |
| 7 | n7 | saimiri_sciureus\t | common_squirrel_monkey | 142 | 28 |
| 8 | n8 | aotus_nigriceps\t | black_headed_night_monkey | 133 | 27 |
| 9 | n9 | trachypithecus_johnii | nilgiri_langur | 132 | 26 |
In [6]:
# 图片数据生成器
height = 224
width = 224
channels = 3
batch_size = 32
classes = 10
train_datagen = keras.preprocessing.image.ImageDataGenerator(
rescale = 1. / 255, # 归一化&浮点数
rotation_range = 40, # 随机旋转 0~40°之间
width_shift_range = 0.2, # 随机水平移动
height_shift_range = 0.2, # 随机垂直移动
shear_range = 0.2, # 随机裁剪比例
zoom_range = 0.2, # 随机缩放比例
horizontal_flip = True, # 随机水平翻转
vertical_flip = True, # 随机垂直翻转
fill_mode = 'nearest', # 填充模式
)
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(height, width),
batch_size=batch_size, shuffle=True, class_mode='categorical')
valid_datagen = keras.preprocessing.image.ImageDataGenerator(
rescale = 1. / 255, # 归一化&浮点数
)
valid_generator = valid_datagen.flow_from_directory(valid_dir, target_size=(height, width),
batch_size=batch_size, shuffle=False, class_mode='categorical')
Found 1098 images belonging to 10 classes. Found 272 images belonging to 10 classes.
In [7]:
# 配置网络
model = get_vgg_model(model_name='vgg16', height=height, width=width, classes=classes)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
# 训练
history = model.fit(train_generator, steps_per_epoch=train_generator.samples//batch_size, epochs=10,
validation_data=valid_generator, validation_steps=valid_generator.samples//batch_size)
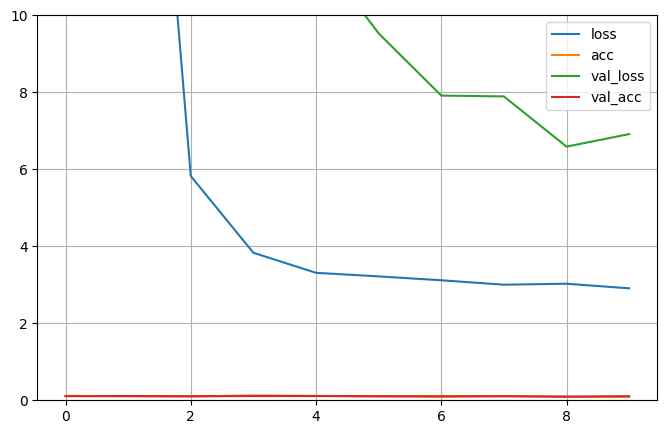
Epoch 1/10 34/34 [==============================] - 267s 8s/step - loss: 499.8480 - acc: 0.1144 - val_loss: 42.7053 - val_acc: 0.1055 Epoch 2/10 34/34 [==============================] - 286s 8s/step - loss: 25.4051 - acc: 0.1041 - val_loss: 22.3587 - val_acc: 0.1094 Epoch 3/10 34/34 [==============================] - 282s 8s/step - loss: 5.8247 - acc: 0.0976 - val_loss: 12.3608 - val_acc: 0.1055 Epoch 4/10 34/34 [==============================] - 293s 9s/step - loss: 3.8310 - acc: 0.1257 - val_loss: 11.0524 - val_acc: 0.1094 Epoch 5/10 34/34 [==============================] - 283s 8s/step - loss: 3.3107 - acc: 0.1135 - val_loss: 11.6788 - val_acc: 0.1094 Epoch 6/10 34/34 [==============================] - 284s 8s/step - loss: 3.2179 - acc: 0.1004 - val_loss: 9.5298 - val_acc: 0.1055 Epoch 7/10 34/34 [==============================] - 278s 8s/step - loss: 3.1169 - acc: 0.0891 - val_loss: 7.9141 - val_acc: 0.1055 Epoch 8/10 34/34 [==============================] - 276s 8s/step - loss: 3.0021 - acc: 0.1069 - val_loss: 7.8924 - val_acc: 0.1055 Epoch 9/10 34/34 [==============================] - 271s 8s/step - loss: 3.0272 - acc: 0.0844 - val_loss: 6.5881 - val_acc: 0.0977 Epoch 10/10 34/34 [==============================] - 268s 8s/step - loss: 2.9080 - acc: 0.0910 - val_loss: 6.9141 - val_acc: 0.1055
In [8]:
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid()
plt.gca().set_ylim(0, 10)
plt.show()
In [10]:
model.evaluate(valid_generator) # 效果很差,用官方的 keras.applications.VGG19 进行训练,也是一样的结果
9/9 [==============================] - 16s 2s/step - loss: 6.7439 - acc: 0.0993
Out[10]:
[6.7438836097717285, 0.0992647036910057]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号