TensorFlow卷积神经网络识别CiFar10物品分类
In [1]:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from sklearn.preprocessing import StandardScaler
In [2]:
(x_train_all, y_train_all), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
x_train_all.shape
Out[2]:
(50000, 32, 32, 3)
In [3]:
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform( x_train.astype(np.float32).reshape(-1, 1) ).reshape(-1, 32, 32, 3)
x_valid_scaled = scaler.transform( x_valid.astype(np.float32).reshape(-1, 1) ).reshape(-1, 32, 32, 3)
x_test_scaled = scaler.transform( x_test.astype(np.float32).reshape(-1, 1) ).reshape(-1, 32, 32, 3)
In [4]:
def make_dataset(data, target, repeat, batch_size, shuffle=True):
dataset = tf.data.Dataset.from_tensor_slices((data, target))
if shuffle:
dataset = dataset.shuffle(10000)
dataset = dataset.repeat(repeat).batch(batch_size).prefetch(50)
return dataset
batch_size = 64
train_dataset = make_dataset(x_train_scaled, y_train, repeat=10, batch_size=batch_size)
eval_dataset = make_dataset(x_valid_scaled, y_valid, repeat=1, batch_size=32, shuffle=False)
In [5]:
model = tf.keras.models.Sequential()
# 卷积 # input_shape 输入参数为 (height, width, channels)
model.add(tf.keras.layers.Conv2D(filters = 32, kernel_size = 3, padding = 'same', activation = 'selu', input_shape = (32, 32, 3)))
model.add(tf.keras.layers.Conv2D(filters = 32, kernel_size = 3, padding = 'same', activation = 'selu')) # 卷积
model.add(tf.keras.layers.MaxPool2D()) # 池化
model.add(tf.keras.layers.Conv2D(filters = 64, kernel_size = 3, padding = 'same', activation = 'selu')) # 卷积
model.add(tf.keras.layers.Conv2D(filters = 64, kernel_size = 3, padding = 'same', activation = 'selu')) # 卷积
model.add(tf.keras.layers.MaxPool2D()) # 池化
model.add(tf.keras.layers.Conv2D(filters = 128, kernel_size = 3, padding = 'same', activation = 'selu')) # 卷积
model.add(tf.keras.layers.Conv2D(filters = 128, kernel_size = 3, padding = 'same', activation = 'selu')) # 卷积
model.add(tf.keras.layers.MaxPool2D()) # 池化
# 输入输出shape: 具体而言,是将一个维度大于或等于3的高维矩阵,“压扁”为一个二维矩阵。即保留第一个维度(如:batch的个数),
# 然后将剩下维度的值相乘为“压扁”矩阵的第二个维度。如输入是(None, 32,32,3),则输出是(None, 3072)
model.add(tf.keras.layers.Flatten()) # Flatten层用来将输入“压平”,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
model.add(tf.keras.layers.Dense(1536, activation='selu'))
model.add(tf.keras.layers.AlphaDropout(0.3))
model.add(tf.keras.layers.Dense(768, activation='selu'))
model.add(tf.keras.layers.AlphaDropout(0.25))
model.add(tf.keras.layers.Dense(256, activation='selu'))
model.add(tf.keras.layers.Dense(128, activation='selu'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
# 配置网络
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['acc'])
In [6]:
# 训练
steps_per_epoch = x_train_scaled.shape[0] // batch_size
display(steps_per_epoch)
history = model.fit(train_dataset, steps_per_epoch=steps_per_epoch, epochs=8, validation_data=eval_dataset)
703
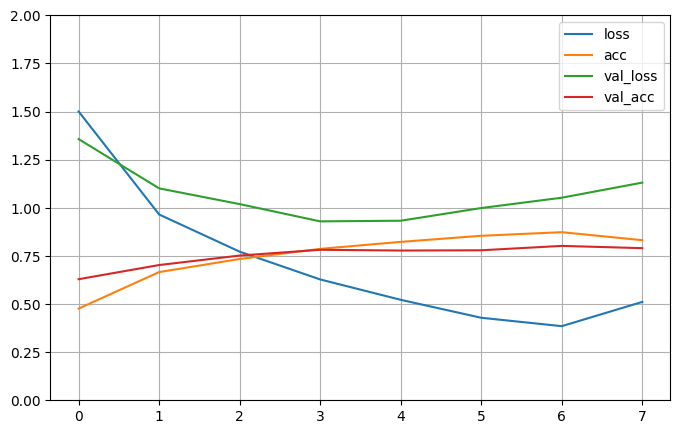
Epoch 1/8 703/703 [==============================] - 69s 97ms/step - loss: 1.5001 - acc: 0.4765 - val_loss: 1.3568 - val_acc: 0.6290 Epoch 2/8 703/703 [==============================] - 69s 98ms/step - loss: 0.9650 - acc: 0.6660 - val_loss: 1.1008 - val_acc: 0.7026 Epoch 3/8 703/703 [==============================] - 70s 99ms/step - loss: 0.7719 - acc: 0.7339 - val_loss: 1.0191 - val_acc: 0.7518 Epoch 4/8 703/703 [==============================] - 68s 97ms/step - loss: 0.6277 - acc: 0.7866 - val_loss: 0.9294 - val_acc: 0.7818 Epoch 5/8 703/703 [==============================] - 69s 99ms/step - loss: 0.5219 - acc: 0.8229 - val_loss: 0.9327 - val_acc: 0.7778 Epoch 6/8 703/703 [==============================] - 71s 102ms/step - loss: 0.4287 - acc: 0.8546 - val_loss: 0.9987 - val_acc: 0.7792 Epoch 7/8 703/703 [==============================] - 71s 101ms/step - loss: 0.3850 - acc: 0.8732 - val_loss: 1.0523 - val_acc: 0.8020 Epoch 8/8 703/703 [==============================] - 68s 97ms/step - loss: 0.5110 - acc: 0.8316 - val_loss: 1.1307 - val_acc: 0.7902
In [7]:
pd.DataFrame(history.history)
In [8]:
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid()
plt.gca().set_ylim(0, 2)
plt.show()
In [9]:
model.evaluate(x_test_scaled, y_test)
313/313 [==============================] - 5s 17ms/step - loss: 1.2527 - acc: 0.7781
Out[9]:
[1.2527273893356323, 0.7781000137329102]
In [10]:
model.summary()
Model: "sequential" ______________________________________________________________________ Layer (type) Output Shape Param # ====================================================================== conv2d (Conv2D) (None, 32, 32, 32) 896 conv2d_1 (Conv2D) (None, 32, 32, 32) 9248 max_pooling2d (MaxPooling2D) (None, 16, 16, 32) 0 conv2d_2 (Conv2D) (None, 16, 16, 64) 18496 conv2d_3 (Conv2D) (None, 16, 16, 64) 36928 max_pooling2d_1 (MaxPooling2D) (None, 8, 8, 64) 0 conv2d_4 (Conv2D) (None, 8, 8, 128) 73856 conv2d_5 (Conv2D) (None, 8, 8, 128) 147584 max_pooling2d_2 (MaxPooling2D) (None, 4, 4, 128) 0 flatten (Flatten) (None, 2048) 0 dense (Dense) (None, 1536) 3147264 alpha_dropout (AlphaDropout) (None, 1536) 0 dense_1 (Dense) (None, 768) 1180416 alpha_dropout_1 (AlphaDropout) (None, 768) 0 dense_2 (Dense) (None, 256) 196864 dense_3 (Dense) (None, 128) 32896 dense_4 (Dense) (None, 10) 1290 ====================================================================== Total params: 4845738 (18.49 MB) Trainable params: 4845738 (18.49 MB) Non-trainable params: 0 (0.00 Byte) ______________________________________________________________________

 浙公网安备 33010602011771号
浙公网安备 33010602011771号