
TensorFlow手写数字识别
In [1]:
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from sklearn.preprocessing import StandardScaler
import pandas as pd
In [2]:
(x_train_all, y_train_all), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
In [3]:
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]
In [4]:
scaler = StandardScaler()
x_train.shape
Out[4]:
(55000, 28, 28)
In [5]:
x_train = x_train.astype(np.float32).reshape(-1, 1) # 转化成一维的列向量,下面好做标准化(均值和方差好得到)
x_train.shape
Out[5]:
(43120000, 1)
In [6]:
x_train_scaled = scaler.fit_transform(x_train)
x_train_scaled
Out[6]:
array([[-0.4241323],
[-0.4241323],
[-0.4241323],
...,
[-0.4241323],
[-0.4241323],
[-0.4241323]], dtype=float32)
In [7]:
x_train_scaled = x_train_scaled.reshape(-1, 28, 28) # 做完标准化了,把维度还原回去
display(x_train_scaled.shape)
x_train_scaled
(55000, 28, 28)
Out[7]:
array([[[-0.4241323, -0.4241323, -0.4241323, ..., -0.4241323,
-0.4241323, -0.4241323],
[-0.4241323, -0.4241323, -0.4241323, ..., -0.4241323,
-0.4241323, -0.4241323],
[-0.4241323, -0.4241323, -0.4241323, ..., -0.4241323,
-0.4241323, -0.4241323],
...,
[-0.4241323, -0.4241323, -0.4241323, ..., -0.4241323,
-0.4241323, -0.4241323],
[-0.4241323, -0.4241323, -0.4241323, ..., -0.4241323,
-0.4241323, -0.4241323],
[-0.4241323, -0.4241323, -0.4241323, ..., -0.4241323,
-0.4241323, -0.4241323]],
...,
[-0.4241323, -0.4241323, -0.4241323, ..., -0.4241323,
-0.4241323, -0.4241323],
[-0.4241323, -0.4241323, -0.4241323, ..., -0.4241323,
-0.4241323, -0.4241323],
[-0.4241323, -0.4241323, -0.4241323, ..., -0.4241323,
-0.4241323, -0.4241323]]], dtype=float32)
In [8]:
x_valid_scaled = scaler.transform(x_valid.astype(np.float32).reshape(-1,1)).reshape(-1, 28, 28)
x_test_scaled = scaler.transform(x_test.astype(np.float32).reshape(-1,1)).reshape(-1, 28, 28)
In [9]:
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=[28, 28]), # 定义输入数据的格式
tf.keras.layers.Dense(512, activation='relu', kernel_regularizer='l2'),
# tf.keras.layers.AlphaDropout(0.5), 也可以取消正则化,使用改进版的dropout(均值和方差不变,归一化性质也不变)
tf.keras.layers.Dense(256, activation='relu', kernel_regularizer='l2'),
tf.keras.layers.Dense(128, activation='relu', kernel_regularizer='l2'),
tf.keras.layers.Dense(10, activation='softmax')
])
# 配置模型
model.compile(loss='sparse_categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
In [10]:
history = model.fit(x_train_scaled, y_train, epochs=10, validation_data=(x_valid_scaled, y_valid))
Epoch 1/10 1719/1719 [==============================] - 6s 3ms/step - loss: 8.6431 - accuracy: 0.9008 - val_loss: 6.0468 - val_accuracy: 0.9378 Epoch 2/10 1719/1719 [==============================] - 5s 3ms/step - loss: 4.4879 - accuracy: 0.9441 - val_loss: 3.2259 - val_accuracy: 0.9522 Epoch 3/10 1719/1719 [==============================] - 5s 3ms/step - loss: 2.4530 - accuracy: 0.9499 - val_loss: 1.8176 - val_accuracy: 0.9588 Epoch 4/10 1719/1719 [==============================] - 5s 3ms/step - loss: 1.4275 - accuracy: 0.9535 - val_loss: 1.1065 - val_accuracy: 0.9584 Epoch 5/10 1719/1719 [==============================] - 5s 3ms/step - loss: 0.9053 - accuracy: 0.9570 - val_loss: 0.7327 - val_accuracy: 0.9618 Epoch 6/10 1719/1719 [==============================] - 5s 3ms/step - loss: 0.6368 - accuracy: 0.9602 - val_loss: 0.5478 - val_accuracy: 0.9636 Epoch 7/10 1719/1719 [==============================] - 5s 3ms/step - loss: 0.4966 - accuracy: 0.9621 - val_loss: 0.4502 - val_accuracy: 0.9652 Epoch 8/10 1719/1719 [==============================] - 5s 3ms/step - loss: 0.4213 - accuracy: 0.9641 - val_loss: 0.3981 - val_accuracy: 0.9632 Epoch 9/10 1719/1719 [==============================] - 5s 3ms/step - loss: 0.3795 - accuracy: 0.9664 - val_loss: 0.3607 - val_accuracy: 0.9688 Epoch 10/10 1719/1719 [==============================] - 5s 3ms/step - loss: 0.3548 - accuracy: 0.9671 - val_loss: 0.3446 - val_accuracy: 0.9684
In [12]:
pd.DataFrame(history.history)
| loss | accuracy | val_loss | val_accuracy | |
|---|---|---|---|---|
| 0 | 8.643057 | 0.900800 | 6.046839 | 0.9378 |
| 1 | 4.487876 | 0.944073 | 3.225888 | 0.9522 |
| 2 | 2.453013 | 0.949891 | 1.817613 | 0.9588 |
| 3 | 1.427526 | 0.953509 | 1.106460 | 0.9584 |
| 4 | 0.905319 | 0.956964 | 0.732748 | 0.9618 |
| 5 | 0.636785 | 0.960236 | 0.547793 | 0.9636 |
| 6 | 0.496599 | 0.962145 | 0.450182 | 0.9652 |
| 7 | 0.421305 | 0.964127 | 0.398070 | 0.9632 |
| 8 | 0.379490 | 0.966382 | 0.360747 | 0.9688 |
| 9 | 0.354765 | 0.967055 | 0.344589 | 0.9684 |
In [13]:
pd.DataFrame(history.history).plot(figsize=(8,5))
plt.grid()
plt.gca().set_ylim(0,1)
plt.show()
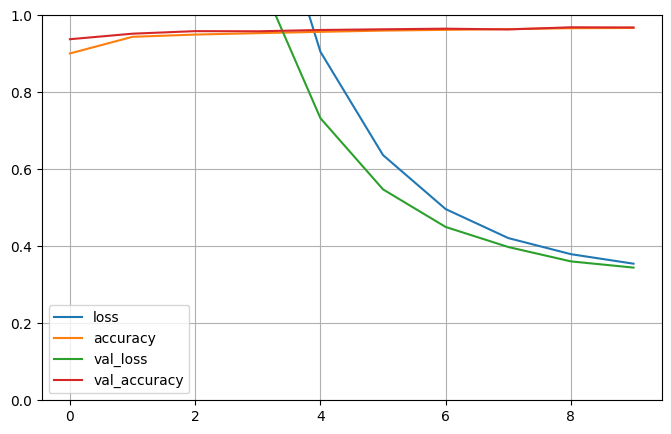
In [14]:
model.evaluate(x_test_scaled, y_test)
313/313 [==============================] - 0s 1ms/step - loss: 0.3469 - accuracy: 0.9676
Out[14]:
[0.3468884527683258, 0.9675999879837036]
In [15]:
model.summary()
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= flatten (Flatten) (None, 784) 0 dense (Dense) (None, 512) 401920 dense_1 (Dense) (None, 256) 131328 dense_2 (Dense) (None, 128) 32896 dense_3 (Dense) (None, 10) 1290 ================================================================= Total params: 567434 (2.16 MB) Trainable params: 567434 (2.16 MB) Non-trainable params: 0 (0.00 Byte) _________________________________________________________________

 浙公网安备 33010602011771号
浙公网安备 33010602011771号