土制Excel导入导出及相关问题探讨
转载请注明出处https://www.cnblogs.com/funnyzpc/p/10392085.html
新的一年,又一个开始,不见收获,却见年龄,好一个猪年,待我先来一首里尔克的诗:
《沉重的时刻》(里尔克)
此刻有谁在世上某处哭,无缘无故在世上哭,在哭我。
此刻有谁在夜间某处笑,无缘无故在夜间笑,在笑我。
此刻有谁在世上某处走,无缘无故在世上走,走向我。
此刻有谁在世上某处死,无缘无故在世上死,望着我。
ok,这次说说项目中经常用到的Excel导出问题,目前就用到的可以操作Excel的技术(在java中)大致有两类:
-
JXL
- 仅仅支持对xls的文件读写,
- 仅包含Excel基础api,比较老,很久不更新
- 读写速度还行,对于要求低同时兼容性较好的推荐
-
POI
- 可支持xls、xlsx两种格式的Excel文件读写
- HSSF:操作Excel 97(.xls)格式
- XSSF:操作Excel 2007 OOXML (.xlsx)格式,操作EXCEL内存占用高于HSSF
- SXSSF: 从POI3.8 beta3开始支持,基于XSSF,低内存占用。
- 技术较新,保留了最大兼容性,可对Excel做复杂对数据极样式处理
- 读写速度上 SXSSF快于XSSF ,HSSF速度同略逊于JXL
- 可支持xls、xlsx两种格式的Excel文件读写
以上对于这两种技术做了简要对描述,在开发中,我们一般将POI作为首选,同时以上还可能存在一个问题是:大数据量导出。大数据导出,一般我们需要解决两个问题:
- 大数据量读写容易造成内存不足问题
- 长时读写容易造成客户端请求超时,造成导出失败问题
- 大数据量处理耗时问题
对于以上几个问题,解决思路大致有下:
- 数据库数据查询阶段建议使用fetch分批次查询,减少数据库压力
- 单个文件读写建议使用SXSSF,以减少内存占用
- 对于单个sheet超过十万的建议分sheet做多线程写入,这里分享一个网友写的Demo
- example:CreateMultipleSheetDemo.java
- 对于POI写入效率的问题官方给了个Demo,这个例子大致是使用xml文档拼接的方式+xml文件压缩的方式
- example:BigGridDemo.java
ok,对于以上核心问题个人都尝试过,惮于目前项目进度较为紧张,个人做了个限制导出处理,以避免(客户端请求)超时问题,说白了就是将问题扔给下一期去集中解决。
不考虑以上所说的问题,个人花了些许时间写了两个Excel 工具类:ExcelReadUtil以及ExcelWriteUtil (代码地址见篇尾),集中处理了包含单不仅限于以下问题:
- 对象列表("List
")类型数据导出问题 - 数据分sheet问题
- 表头字体极单元格内换行问题
- 数据单元格多样式问题
- 数据单元格多数据类型及格式化问题
- 单元格列宽度调整问题
- 大数据拆分问题
- 通用对象导出问题(使用泛型)
当然,解决这些问题也查阅了不少官方资料,同时也做了大量的测试才得以投入正式项目使用,在这中间也跳过一些坑,接下来我就讲一讲我在开发所跳过的坑,这些坑均是相对于上一个版本而言的:
- 使用通用泛型接收参数对象问题
一开始(在上一个项目)做了个初稿,在调用导出方法时直接传入固定类型对象,一开始这样:
toXlsxByMap(List<Map<String,Object>> dataList,
String[] headerNames,
String[] cellNames,
CellFmt[] cellFmts)
导致的问题是传入的dataList内部的Map的value必须是Object类型,之后钻研了下java泛型,使用这种方式轻松解决问题!
public static <V extends Object> File toXlsxByMap(List<Map<String,V>> dataList,
String[] headerNames,
String[] cellNames,
CellFmt[] cellFmts)
- 分数据分sheet问题
这个问题其实很简单,就是先数据分组,然后循环每组数据时再createSheet,代码片段:
//数据分组
List<List<Map<String, V>>> mData = splitMapList(dataList);
//循环每组数据 并创建sheet>写单元格
for (List<Map<String, V>> subList : mData) {
//第一个sheet 参数(sheet名称,sheet的序号)
sheet = workbook.createSheet(String.format("%s~%s",
(dataList.size() > DATA_SPLIT_GROP_SIZE ?
mData.indexOf(subList) * DATA_SPLIT_GROP_SIZE + 1
: 0) + "",
(dataList.size() > DATA_SPLIT_GROP_SIZE ?
(mData.size() == (mData.indexOf(subList) + 1) ? dataList.size() : DATA_SPLIT_GROP_SIZE * (mData.indexOf(subList) + 1))
: dataList.size()) + "")
);
LOGGER.info(">>>sheet name : {}",sheet.getSheetName());
PoiCellProcess.writeHeaderCell(sheet,headerCellStyle,headerNames);
PoiCellProcess.writeBodyCellByMap(sheet,bodyCellStyle,cellNames,subList, cellFmts);
}
- 单元格内换行问题
其实这是个小问题,只需给CellStyle设置一个setWrapText(true),大致逻辑这样:
public static CellStyle headerCellStyle(SXSSFWorkbook wb){
CellStyle headerStyle = wb.createCellStyle();
//...some code
//允许单元格内换行
headerStyle.setWrapText(true);
return headerStyle;
}
-
单元格类型及格式处理问题
这个问题其实分为多个,而且密切相关,大致有这几个:
- 单元格样式类
- 单元格样式类
- 单元格数据类型
- 单元格写入数据格式但是,处理了这几个问题其实还不够完美
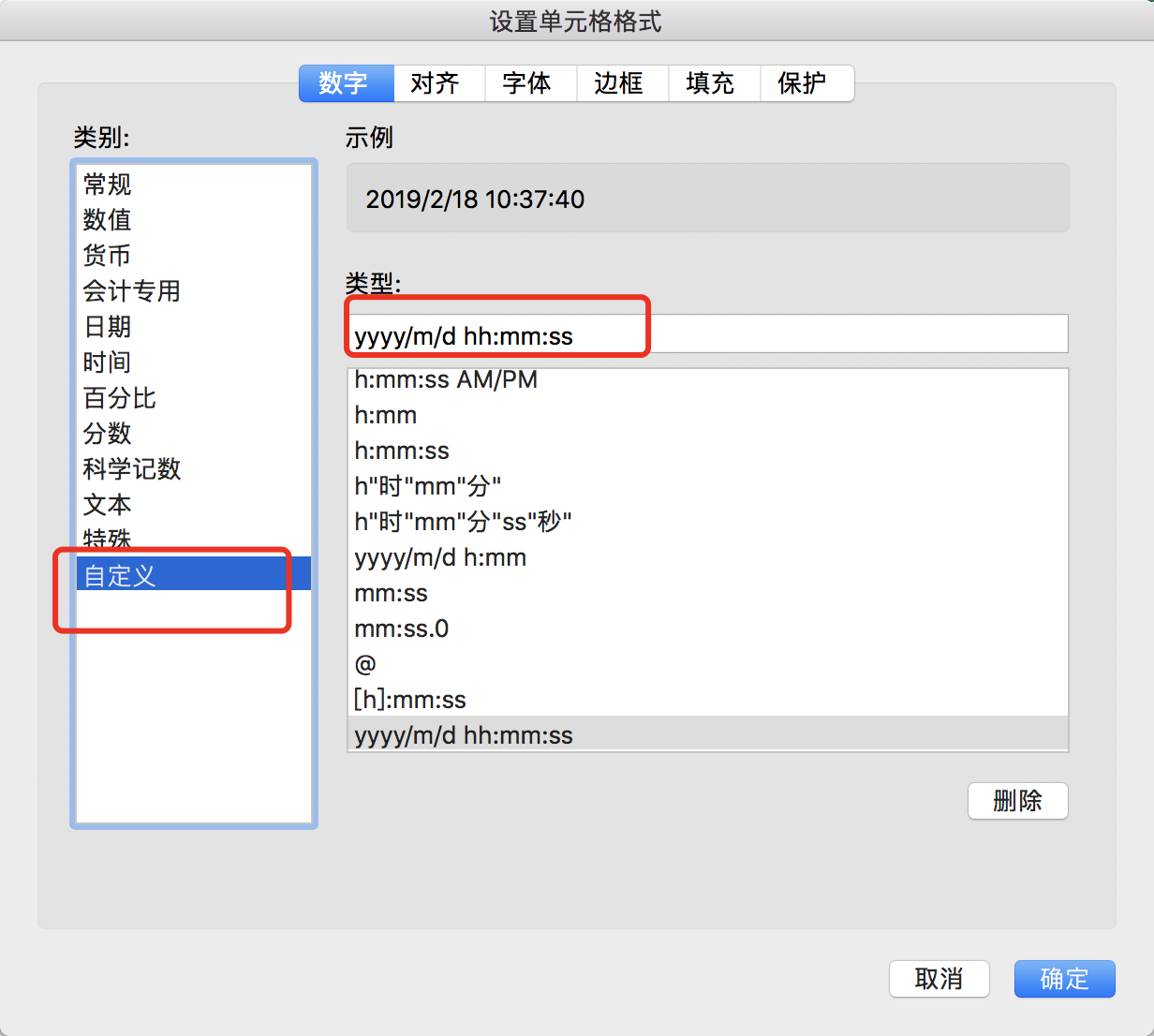
至于不完美的原因是什么呢,一个是Excel数据格式与java数据格式不一致(这个体现在日期,长数字,小数的处理上),比如你要格式化的日期后为“yyyy-mm-dd” 这种类型,
但是在Excel中相近的格式类型只有这样“yyyy/M/d”,如果强制单元格样式类型为“yyyy-mm-dd HH24:mi:ss” 其实也是可以的,只不过会变成自定义格式,而且是Excel的自定义格式,
具体如下图:
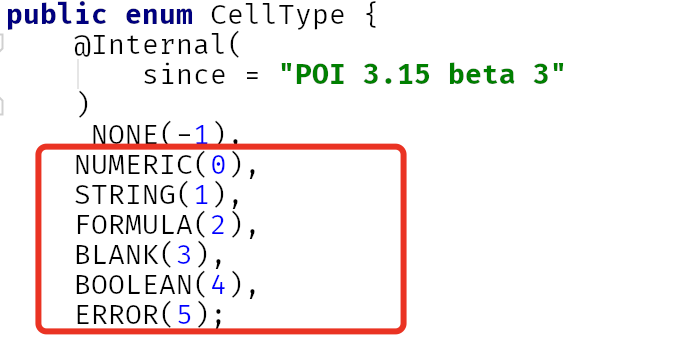
另外一个问题是单元格类型与编程语言的数据类型相异同时与poi所能提供的数据类型也相异,如图:
- 列宽调整问题
记得在第一版的时候列宽问题其实并不重要,遂就做个了固定长度
在第二版的时候为了保证可以动态调整列宽,就剔除了第一版的固定长度处理,将长度数据作为一个Integer数组传入
由于第二版先期已经投入开发中了,再在方法里面加入长度数组实感觉不合适,于是,想了个用代码做动态列宽,这里实现的思路大致有下:- 由于表头也是作为一个参数传入的,所以将表头字符个数作为字段倍数长度,数据行过长时将表头字段添加适当个数的空格即可(数据传入的时候)
- 实际显示的时候由于存在单元格内换行问题,所以在代码处理的时候先判断换行,所以:
- 有换行时 单元格列宽=基准长度(自己定义的单字符长度)*字符个数/2
- 无换行时 单元格列宽=基准长度(自己定义的单字符长度)*字符个数
这是最终的代码:
public static void writeHeaderCell(SXSSFSheet sheet, CellStyle headerCellStyle, String[] headerNames) {
SXSSFRow row = sheet.createRow(0);
row.setHeight((short) 30);
row.setHeightInPoints((short) 30);
SXSSFCell headerCell;
for (int i = 0; i < headerNames.length; i++) {
headerCell = row.createCell(i);
headerCell.setCellStyle(headerCellStyle);
headerCell.setCellValue(headerNames[i]);
sheet.setColumnWidth(i,
null == headerNames[i] ? CELL_BASE_LENGTH
: (headerNames[i].contains("\r\n") ? CELL_CHARSET_LENGTH * headerNames[i].length() / 2
: CELL_CHARSET_LENGTH * headerNames[i].length()));
}
}
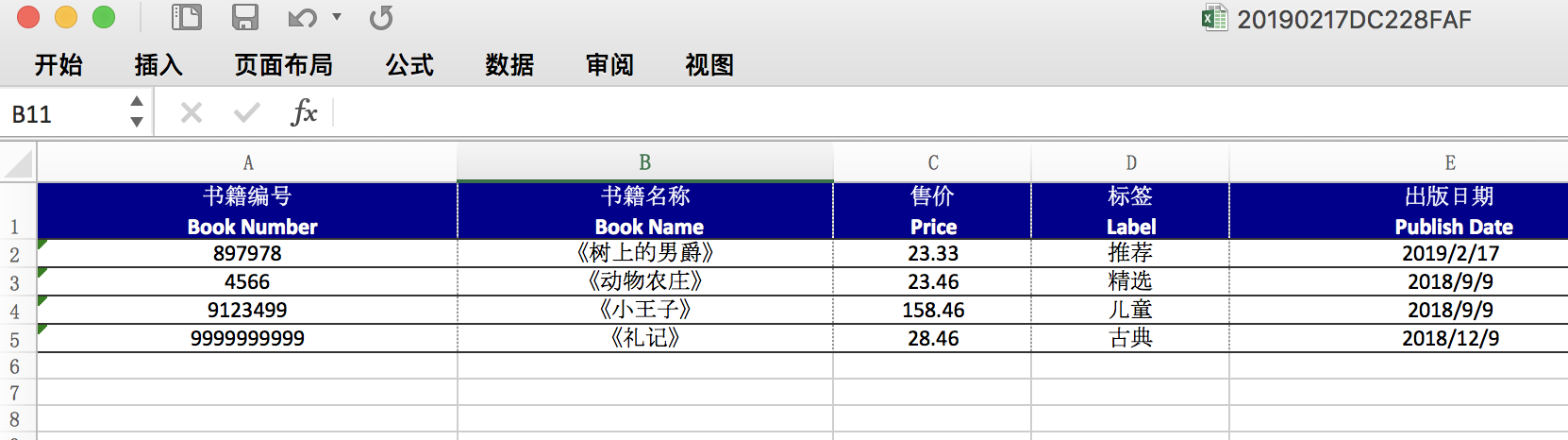
这是最终处理的结果:
- 对象导出问题
这个问题耗时较多,由于我的同事所处理的源数据是这样子 "List" ,这样做其实有个很大的问题就是 java代码没法动态针对不同对象做getter和setter处理,遂每一个导出功能就需要单独写poi的导出逻辑,缓慢而且耽搁开发进度,这个时候在写第二版的时候彻底优化了,这里的思路和注意事项大致有下: - 利用反射动态获取字段数据,这里是不得已而为之(其实jvm做频繁反射处理时并不慢)
- 反射处理时必需要将最终数据排序,不然循环 Field[] 获取到的数据结果并不一定与表头字段数据一致
这里是最终代码:
public static Object[] fieldValues(final Object obj, final String[] fieldNames,Object[] valueList) {
for (Class<?> superClass = obj.getClass(); superClass != Object.class; superClass = superClass.getSuperclass()) {
try {
Field[] fields = superClass.getDeclaredFields();
for(int k=0;k<fields.length;k++){
if ((!Modifier.isPublic(fields[k].getModifiers()) ||
!Modifier.isPublic(fields[k].getDeclaringClass().getModifiers()) ||
Modifier.isFinal(fields[k].getModifiers())) &&
!fields[k].isAccessible()) {
fields[k].setAccessible(true);
}
/**
* 需要排序,否则顺序不一致
*/
for(int j=0;j<fieldNames.length;j++){
if(fields[k].getName().equals(fieldNames[j])){
valueList[j] = fields[k].get(obj);
break;
}
}
}
return valueList;
} catch (Exception e) {
e.printStackTrace();
}
}
//这里新增一个,否则数组越界
return new Object[fieldNames.length];
}
&最后
**先展示导出的效果: **
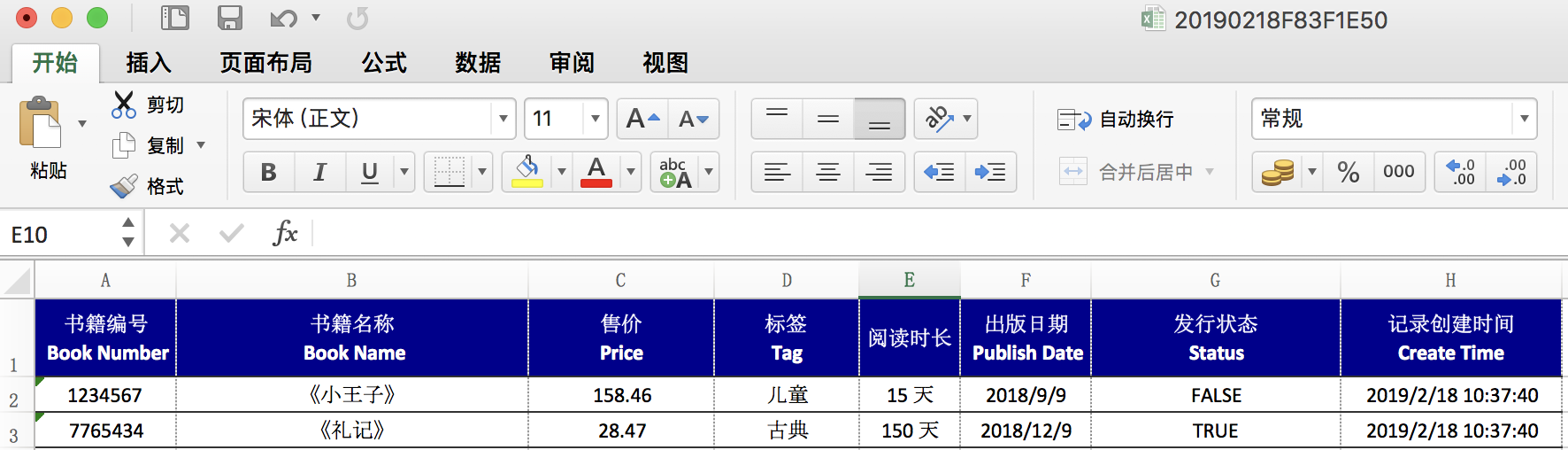
由于导入并没有做严格要求,所以将读取的数据全部放入这种对象里面 "List<Map<String,String>>",详细请看代码,这里就不做详细介绍了
这里共享下我的 “土制Excel导入导出”:
代码地址 :https://github.com/funnyzpc/excel-process
笔记写的略微简单,建议使用前使用看下这两个测试样例:
- 样例 example
以上写的过于粗糙,各位有更好的想法请分享下哈~
现在是 2019-02-18 星期一,各位中午好~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号