Transformer论文解读——Attention is all your need
Transformer
Transformer是Google2017年发表在NIPS上的文章《Attention is all your need》
论文地址:https://arxiv.org/abs/1706.03762
摘要
摘要首先说在此之前序列数据的处理上表现最好的还是基于注意力机制的编码器和解码器结构,但是我们提出了一个新的、简单的网络结构,名为Transformer,它仅仅依赖于注意力机制,完全摒弃了rnn和cnn,并且并行度很好,训练时间也更短。其次,在WMT的英语翻德语和英语翻法语任务上都SOTA了

引言
作者指出现有的模型对于长序列数据的处理并行度不高,计算效率低,因此提出transformer模型,完全基于注意力机制来描述输入和输出之间的全局依赖关系,并且Transformer允许更高的并行化。

背景
作者提出根据目前的研究来看,Transformer是第一个完全依赖于自注意力来计算输入输出表示的模型,并且不适用任何的RNN和卷积。
模型结构
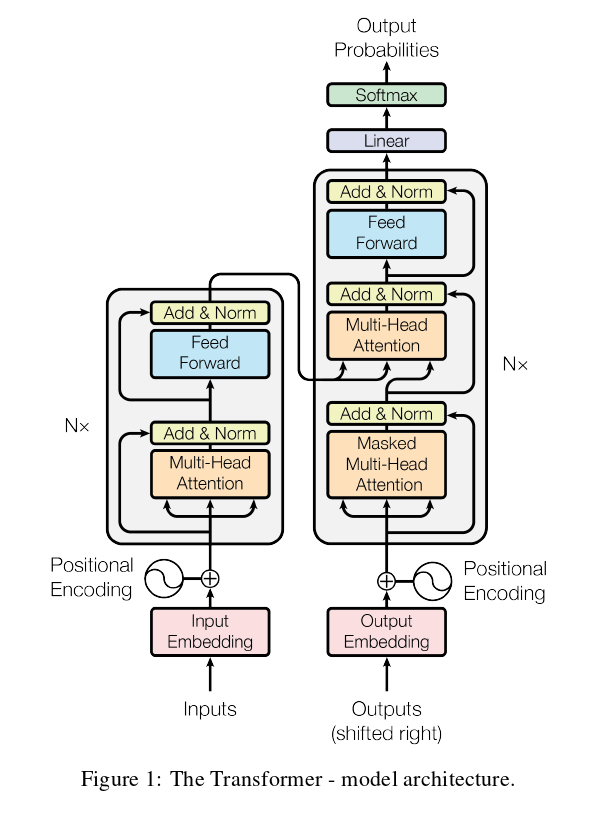
编码器
编码器有6个相同的层堆叠组成,每层有两个子层。第一个sub-layer是多头注意力机制,第二个sub-layer是一个简单的、基于位置的全连接前馈网络(其实就是一个MLP),子层之间通过残差连接和LN。那么每个子层的输出就是LN(x + sublayer(x))
解码器
解码器也有6个相同的层堆叠组成,每个层有三个子层。第一个子层是带掩码的多头注意力层,第二个是多头注意力层,第三层也是一个前馈网络,最后通过softmax进行输出。
Attention
作者表示注意力函数可以描述为将一个Query和一组Key-Value键值对的输出。

具体的结构呢,作者给了这样两张图和下面两个公式。
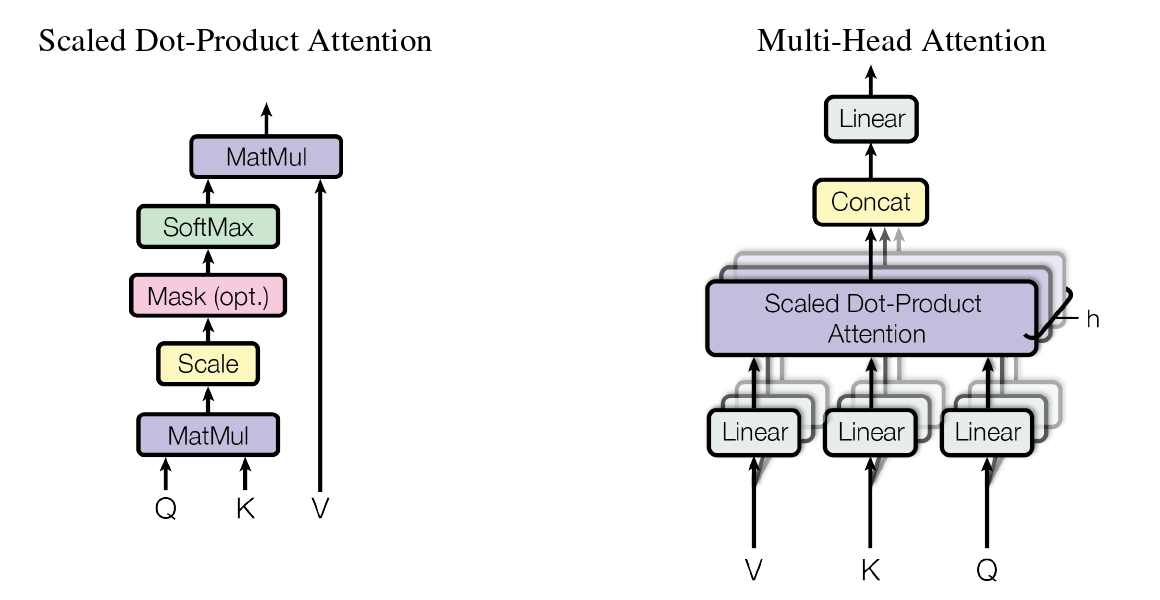
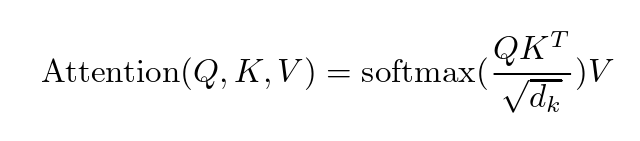
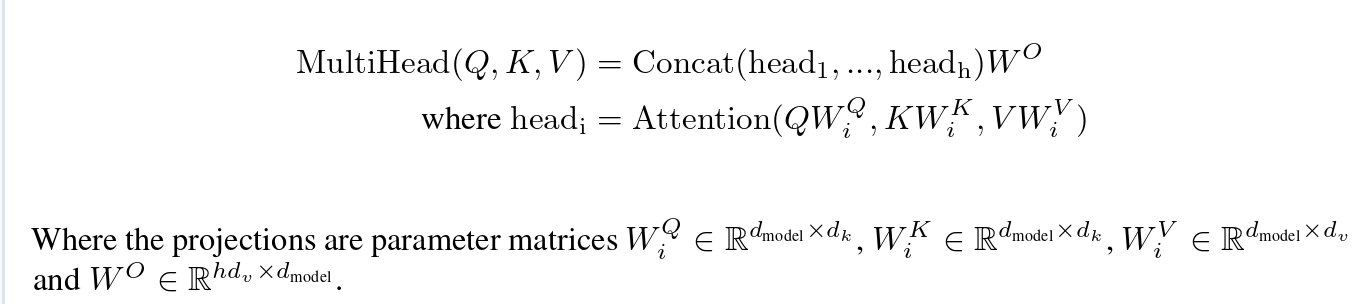
那么下面我们就是具体解释这两张图表示的含义和公式的推导。
多头注意力模型的话其联合了不同位置的不同表示子空间的信息,在单个注意头的情况下,进行了平均。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号