LLaMa.cpp
基本介绍
LLaMa.cpp是由开发者 Georgi Gerganov 发起的一个C++编写的轻量级、高性能的CPU/GPU大语言模型推理框架,专为在本地CPU上部署量化模型而设计,它提供了一种在资源有限的设备上对LLM从模型转换、量化到推理的一站式解决方案,让LLM的部署流程变得简单而高效,能够将训练好的量化模型转换为可在CPU上运行的低配推理版本,其主要开发目标就是让开发者在消费级设备或边缘设备上本地部署运行大模型,也可以作为依赖库集成的到应用程序中提供类GPT的功能。在高性能和低资源消耗之间取得平衡,是 LLaMa.cpp 的一大亮点。
LLama.cpp支持开发者通过其提供的工具将各类开源大语言模型转换并量化成gguf格式的文件,然后实现本地量化和推理。
官方仓库:https://github.com/ggerganov/llama.cpp/releases
量化基本介绍
LLM 虽然功能强大,但由于模型规模较大,因此会消耗大量资源。这对资源受限的设备上部署带来了挑战,并且会阻碍推理速度和效率。量化提供了一种解决方案,即在保持性能的同时降低模型参数的精度。
在深度学习和计算机科学中,量化(Quantize)就是一种将模型中的参数或数据从高精度格式(通常是 FP32 位或 FP16 位)转换为低精度格式(如 8 位、4 位或整数格式)的一种模型压缩技术。量化的主要目的是减少模型的内存占用和计算资源需求,从而加速推理速度,降低硬件要求,使模型能够在低配设备上运行。
常用的模型压缩技术:量化、剪枝、蒸馏、低秩自适应
基本概念
想象一下:如果把一个LLM理解成像一座繁华的大城市,城市里密集的房屋(模型的参数)无处不在,这时候如果你作为一个画家,你怎么绘制出这个城市?
如果你有钱(资源),有超强的绘画天赋(技术),那么你可能会选择一比一还原这座城市。(这表示你没有使用任何的量化手段,直接简单粗暴的运行大模型)
如果你没有那么多钱,但是也没有有超强的绘画天赋,那么你会选择在绘制过程中仅仅画出最重要的房屋(参数)并把房屋等比例缩小或者聚集到一块(较低精度),甚至把一些不重要的房屋移除掉(设置零值),当然这样会让你绘制出来的城市看起来房屋密度较低,空间稀疏。(这表示你使用了量化手段,提高大模型的稀疏性,较低大模型参数的空间密度。)
稀疏性:保留LLM中重要参数,忽略不影响性能的参数。计算公式:稀疏性 =(零值参数的数量)/(参数总数)。
空间密度:各种非零值参数占LLM总参数的百分比。计算公式:密度 =(非零参数的数量)/(参数总数)
量化优缺点
优点:
- 减少内存占用:通过降低参数精度,量化显著降低了模型的内存需求,这对于在内存有限的设备上部署至关重要。
- 提高速度:较低精度的计算执行速度更快,从而加快模型推理速度,这对实时应用尤其有益。
- 保持性能:量化旨在简化模型,同时保持其性能,确保模型在提高稀疏性和降低参数空间密度后仍拥有必要的推理和预测能力。
缺点:
- LLM量化必然会导致模型的精度下降,损失信息,使得LLM的推理和预测能力下降,增加幻觉出现的概率。
- 并非所有硬件都支持低精度运算,部分硬件设备并不支持。
量化对象
模型量化的对象主要包括以下几种参数:
- 权重(weight):weight的量化是最常规也是最常见的。量化weight可达到减少模型大小内存和占用空间。
- 激活(activation):实际中activation往往是占内存使用的大头,因此量化activation不仅可以大大减少内存占用。更重要的是,结合weight的量化可以充分利用整数计算获得性能提升。
- KV cache:量化 KV 缓存对于提高长序列生成的吞吐量至关重要。
- 梯度(Gradients):相对上面两者略微小众一些,因为主要用于训练。在训练深度学习模型时,梯度通常是浮点数,它主要作用是在分布式计算中减少通信开销,同时,也可以减少backward时的开销。

GGUF
GGUF(GPT-Generated Unified Format)是一种由Georgi Gerganov定义发布的大模型通用量化文件格式,主要由 LLaMa.cpp 项目引入,专为高效存储和推理大型语言模型而设计,支持各种模型,并允许添加新功能同时保持兼容性。
GGUF 格式可以支持不同量化方案,包括 8 位、4 位、5 位等多种精度的量化,使得用户能够根据硬件性能和精度需求选择合适的量化模型。
Q_K_M
在 LLama.cpp 的上下文中,Q<数字>_K_M 指的是一种特定量化文件命令格式。例如:q5_k_m中
- q 代表当前模型为量化模型,Quantize的首字母
- 5 表示量化过程中使用的位数(bit数),数字越小,占用内存越少。
- k 表示在量化过程中使用了块状量化技术(K-means算法)。
- m 表示量化后的模型大小。S = 小,M = 中,L = 大。
- _0 表示当前量化位数的第一个版本。
查看LLama.cpp中支持的量化方案:
llama-quantize
快速安装
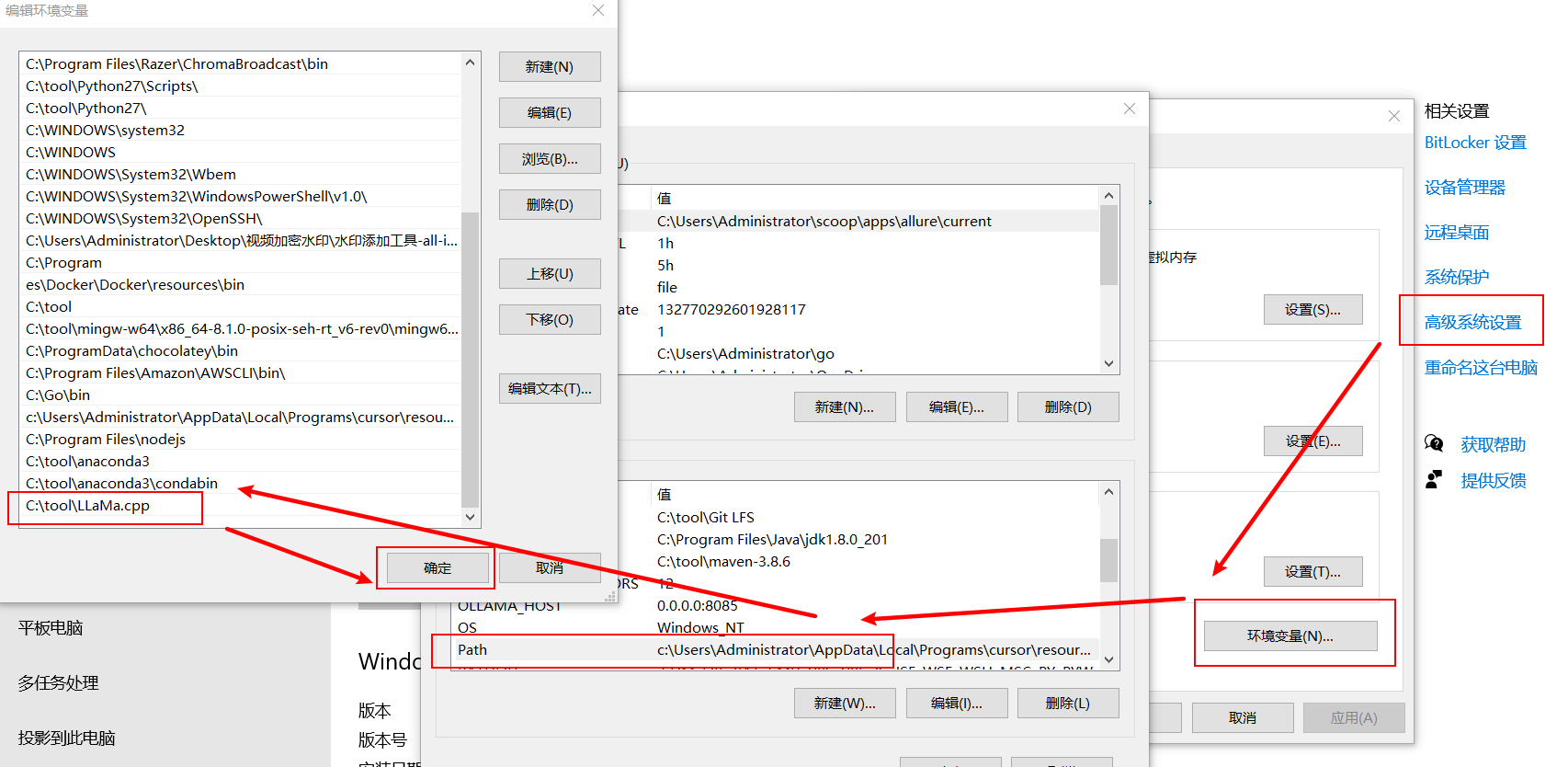
根据自己的系统类型选择下载对应的压缩包,并解压到本地,接着设置环境变量指向到当前安装目录。
windows下设置安装目录为环境变量:
快速使用
这里我们使用魔塔社区提供的Qwen2.5-7B-Instruct量化模型来举例:
模型地址:https://modelscope.cn/models/Qwen/Qwen2.5-7B-Instruct-GGUF/summary
合并分割文件:
llama-gguf-split --merge qwen2.5-7b-instruct-q5_k_m-00001-of-00002.gguf qwen2.5-7b-instruct-q5_k_m.gguf
启动模型服务:
llama-server -m qwen2.5-7b-instruct-q5_k_m.gguf --port 8088 -c 2048
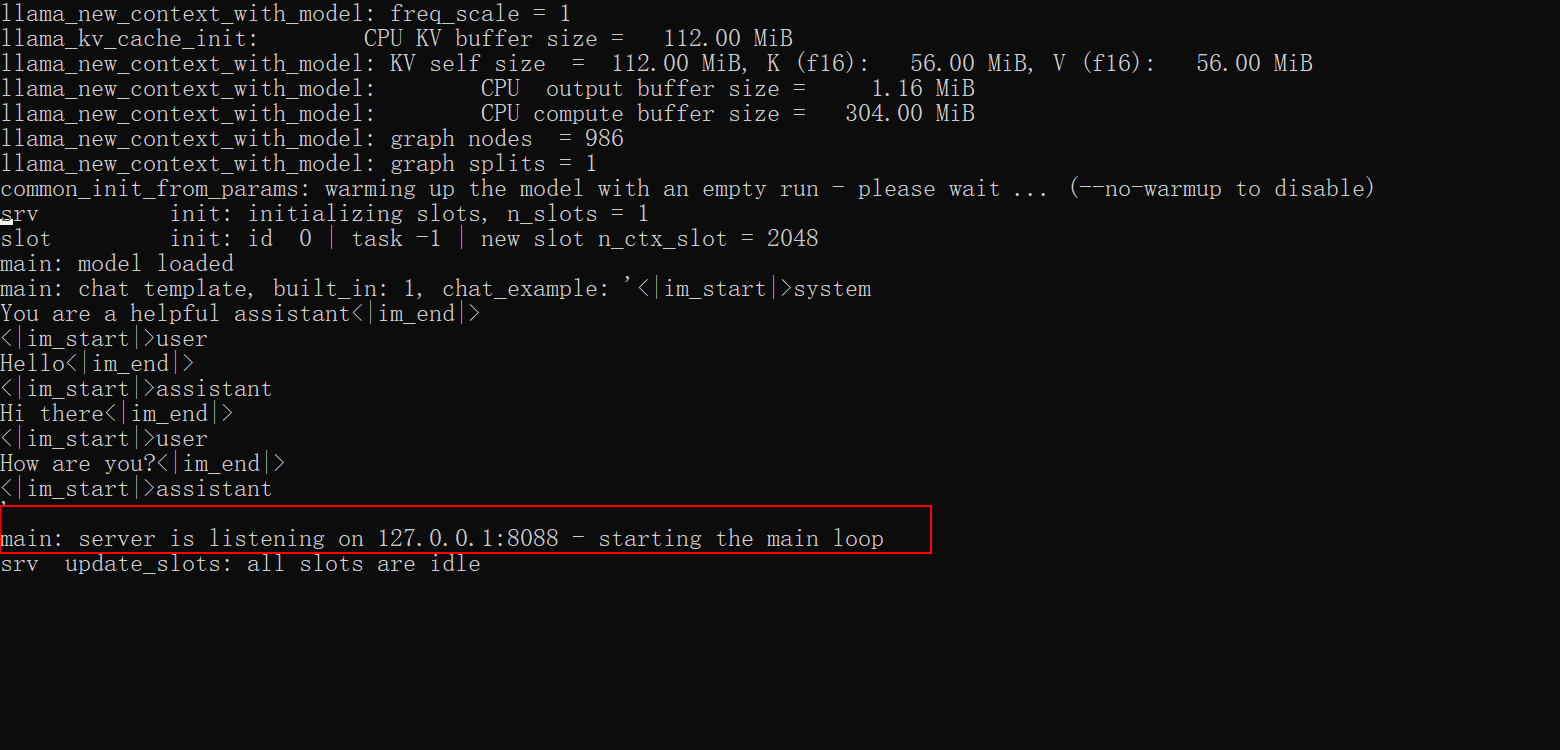
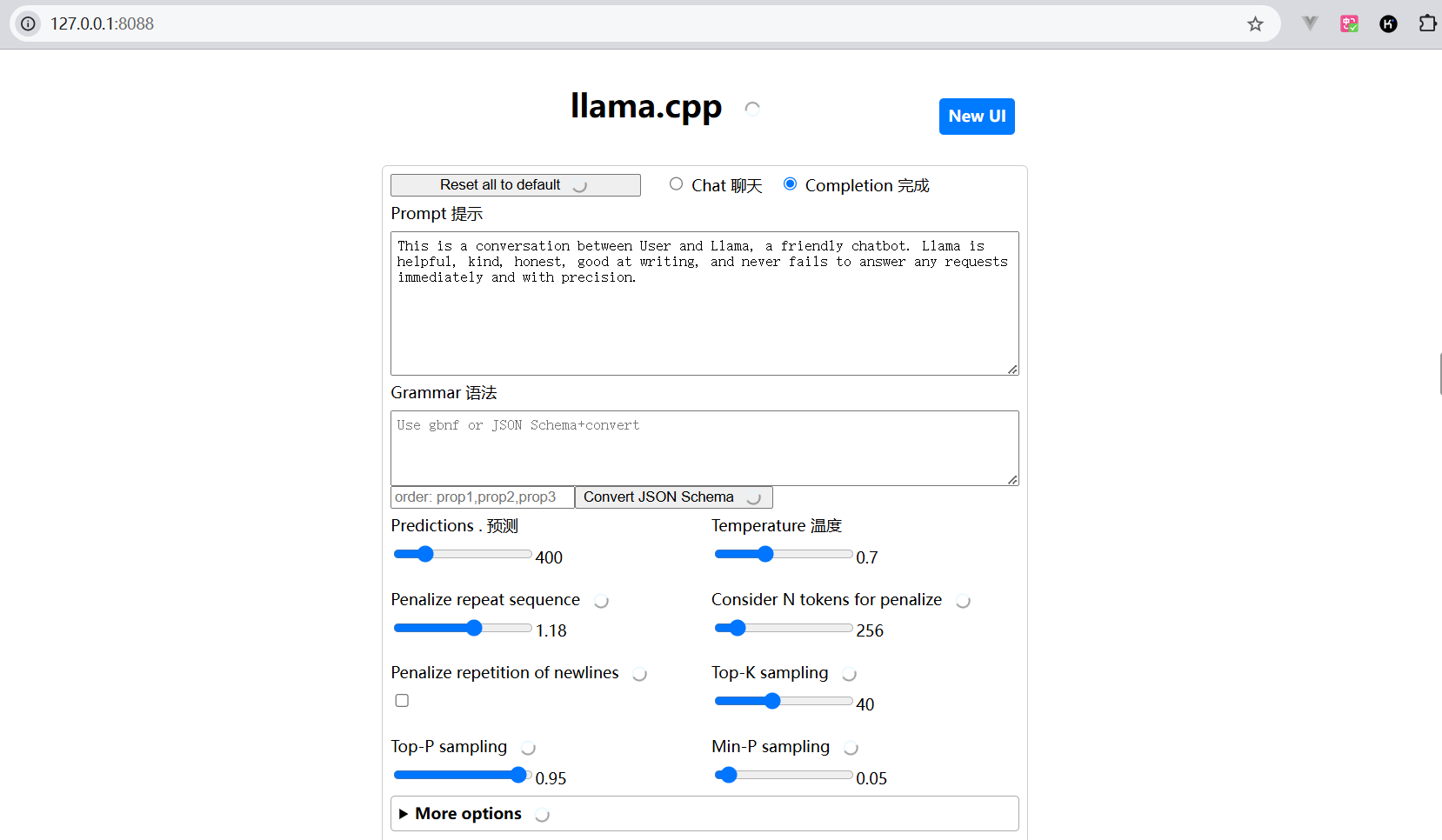
访问API服务:
模型的尺寸所需要的显存
模型本身的尺寸被几个因素影响:参数类型(32BF[4字节]、16BF[2字节]、Int8[1字节],Int4[0.5字节]等等)、模型所处阶段(推理、训练、部署)。
推理阶段
模型的显存(GB) ≈ 参数量(B)* 参数类型
7B大模型(BF16) ≈ 7 * 2 ≈ 14G显存
训练阶段
模型的显存(GB) ≈ 参数量(B)* 参数类型 * 4
7B大模型(BF16) ≈ 7 * 2 * 4 ≈ 56G显存
部署阶段
模型的显存(GB) ≈ 参数量(B)* 参数类型 * 1.3
7B大模型(BF16) ≈ 7 * 2 * 1.3 ≈ 18G显存

 浙公网安备 33010602011771号
浙公网安备 33010602011771号