第1章 python基础
第一模块
day01 计算机基础和环境搭建
课程目标:让大家了解计算机基础知识并完成Python的环境搭建。
课程概要:
- 计算机基础
- 编程的本质
- Python的介绍
- Python环境的搭建
1.计算机基础
1.1 基本概念
-
计算机的组成
计算机是由多个硬件组合而成,常见的硬件有:CPU、硬盘、内存、网卡、显示器、机箱、电源.... 注意事项:机械将零件组合在一起,他们之间是无法进行协作。 -
操作系统
用于协调计算机的各个硬件,让硬件之间进行协同工作,以完成某个目标。 常见的操作系统分类: - windows,优点:生态牛逼、工具多;缺点:略慢、收费。【个人】 - xp - win7 - win10 ... - linux,优点:资源占用少、免费(很多公司的服务器上安装Linux);缺点:工具少、告别游戏。【企业的服务器】 - centos - ubuntu - redhat ... - mac,优点:生态还行、工具差不多都有、用户体验和交互; 缺点:不能玩游戏 -
软件(应用程序)
在安装上操作系统之后,我们会在自己电脑上安装一些常用的软件,例如:QQ、杀毒、微信... 问题来了:这些软件是由谁开发的?是由各大公司的程序员开发的。 以后的你肯定是写`软件`,可以把软件理解成为一大堆的代码(一篇文章)。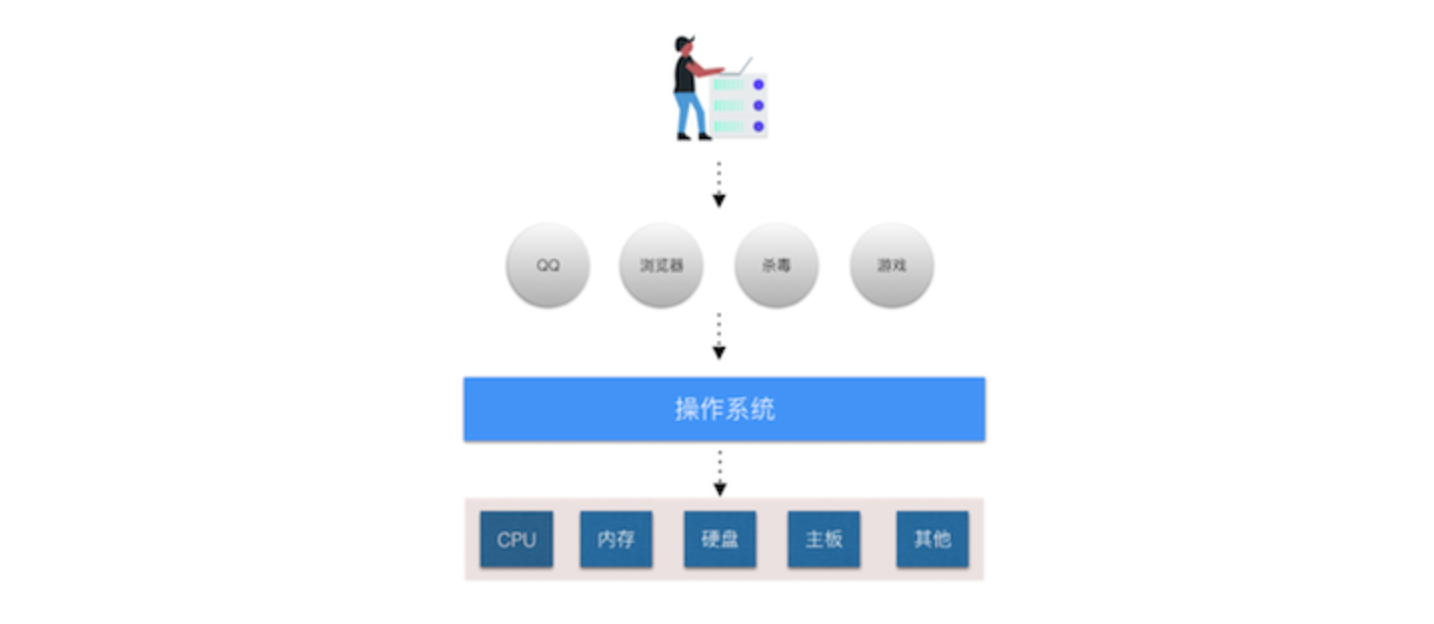
1.2 编程语言
软件,是由程序员使用 编程语言 开发出来的一大堆代码的集合。全球的编程语言有2500+多种,常见的编程语言:Java、C#、Python、PHP、C...
作文,是由小学生使用 汉语/英语/法语/日语... 写出来一大堆的文字的集合。
本质上学习编程语言就是学习他的语法,根据语法再去编写相应的软件中的功能。
-
Python语言中输出的语法规则
print("我是Alex的二大爷") -
Golang语言中的输出的语法规则
fmt.Println("我是Alex二大爷")
1.3 编译器/解释器
编译器/解释器,就是一个翻译官,将代码翻译成计算机能够识别的命令。
A使用Python开发了一个软件 1000 B使用Golang开发了一个软件 2000
Python解释器 Golang编译器
操 作 系 统
CPU 硬盘 网卡 内存 电源 .....
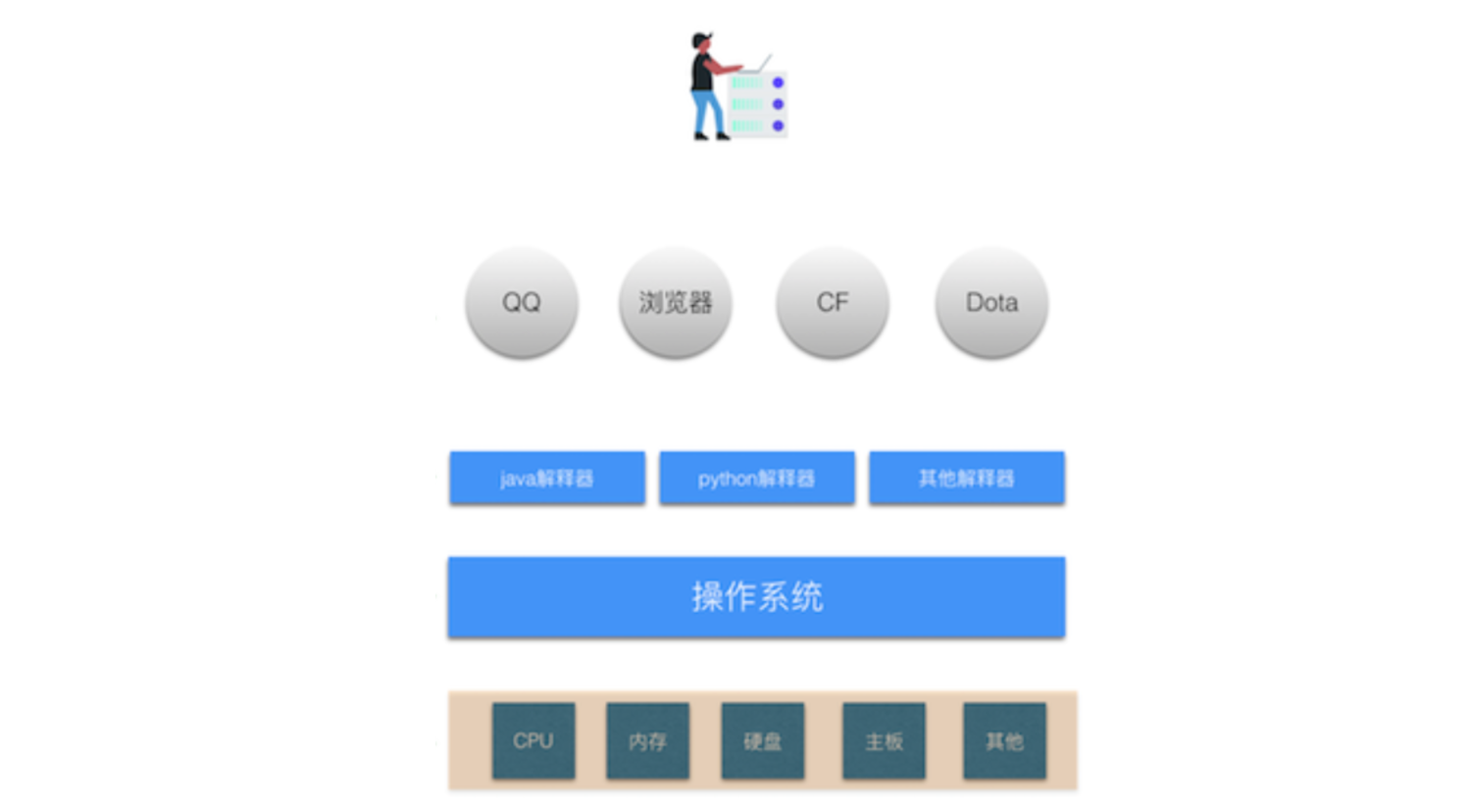
为什么有的叫解释器?有的叫编译器?
- 解释器,实时翻译。拿到1000行代码之后,解释一句交给操作系统一句。
- 编译器,全文翻译。拿到2000行代码之后会将他编译成一个临时文件(计算机能够识别命令),再把文件交给操作系统去读取。
Python、PHP、JavaScript、Ruby...一般称为解释型语言。
C、C++、Go、Java...一般称为编译型语言。
2.学习编程的本质
学编程本质上就是三件事:
- 选择一门编程语言,在自己的电脑上安装此编程语言相关的 编译器/解释器。
- 学习编程语言的语法规则,根据语法规则 + 业务背景 设计并开发你的软件(代码集合)。
- 使用 编译器/解释器 去运行自己写的代码。
3.Python的介绍
3.1 语言的分类
-
翻译的维度- 解释型语言,Python、Ruby....
- 编译型语言,C、C++、Golang
-
高低的维度-
低级编程语言,写出来的代码直接可以被计算机识别。
机器语言,101 001 00001 00010 001000100010001,机器码,交给计算机去执行。 汇编语言,MOV INC ... ,指令,交给计算机去执行。 -
高级编程语言,写出来的代码无法直接被计算机识别,但可以通过某中方式将其转换为计算机可以识别的语言。
C、C++、Java、Python、Ruby...,这类编程语言在编写代码时几乎是写英语作文。 交由相关编译器或解释器翻译成机器码,然后再交给计算机去执行。
-
注意:现在基本上都使用高级编程语言。
3.2 Python
Python的创始人为吉多·范罗苏姆(Guido van Rossum)。1989年的圣诞节期间,Guido开始写Python语言的编译器。Python这个名字,来自Guido所挚爱的电视剧Monty Python’s Flying Circus。他希望这个新的叫做Python的语言,能符合他的理想:创造一种C和shell之间,功能全面,易学易用,可拓展的语言。
全球众多编程语言,为何Python可以脱颖而出成为业界炙手可热的编程语言?目前位居TIOBE排行榜第三名并且一直呈上升趋势。
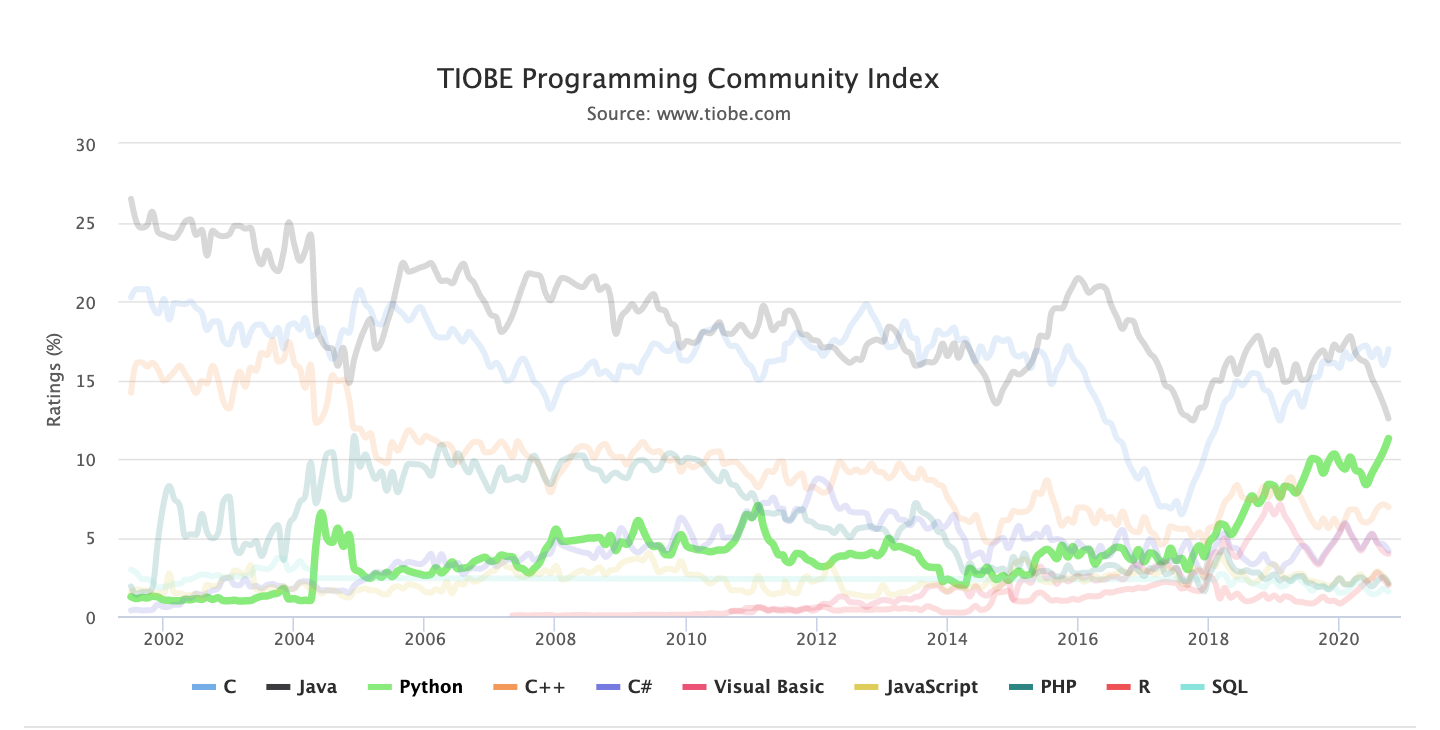
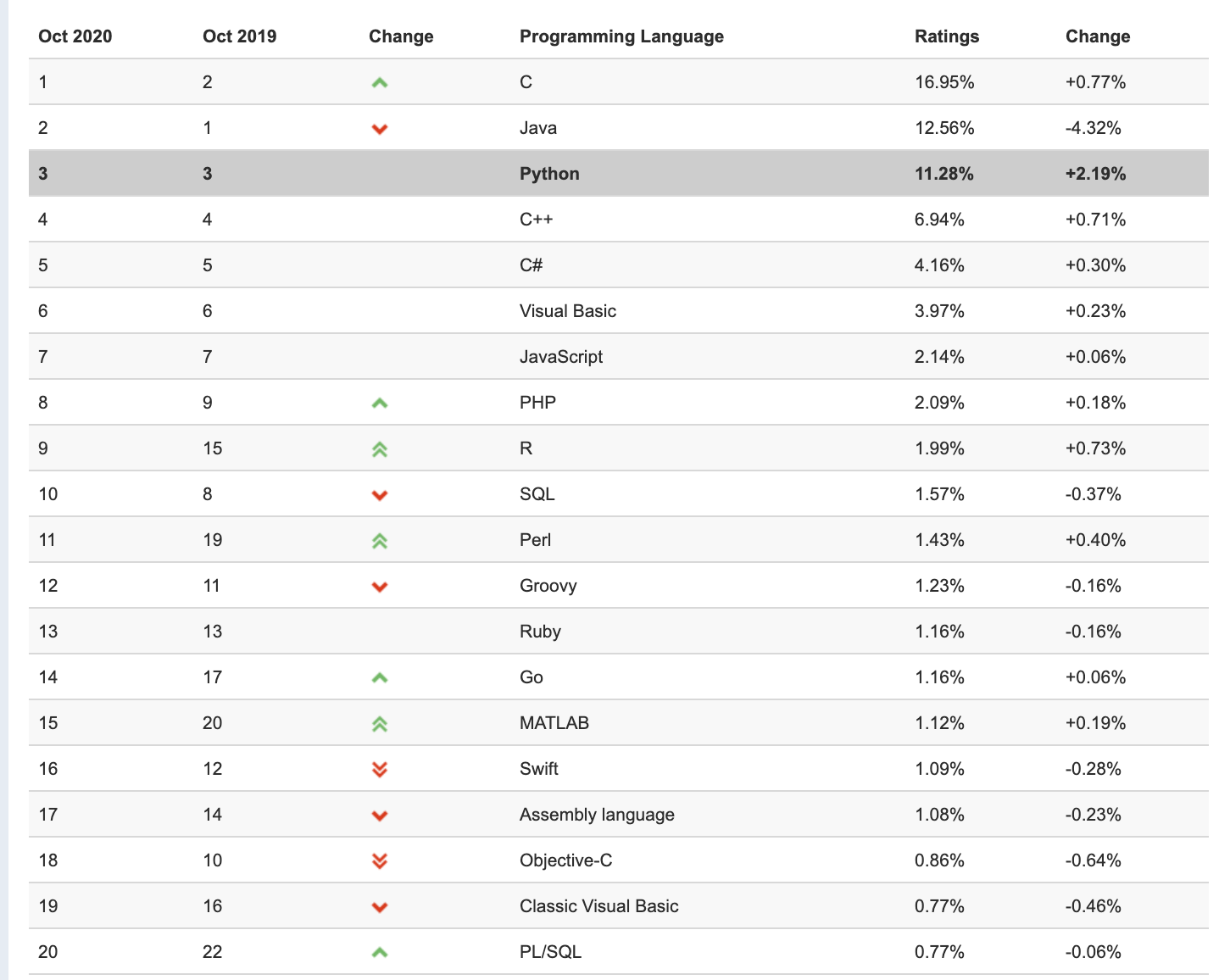
Python如此火爆的原因如下:
- 语法简洁 & 适合小白学习,相比较于其他编程语言Python的学习成本非常低,甚至可以让其他行业的人快速掌握编程技能,通过编程提供工作效率,例如:Excel自动化办公、文件和文件夹的处理等。
- 类库强大,Python自诞生之初就任其自然生长,经过多年的发展,造就其在很多领域都是积累了很多方便的类库,自然也成为了运维自动化、数据分析、机器学习首选编程语言。
- 开发效率极高,结合Python语法精炼和类库齐全的特点,所以在使用Python进行开发时可以用更少的代码完成更多的功能,大大提升开发效率。例如:Python10行代码实现的功能,用其他语言可能需要100+行才能完成。
3.3 Python的解释器种类(了解)
想要学一门编程语言:安装Python解释器、学习python语法并编写代码、使用Python解释器去执行编写好的代码。
Python在全球非常的火,很多公司都会想要来层热度。
由于Python太火了,所有就有很多的公司都开发了Python解释器(用来翻译python代码成为计算机能够识别的命令)。
- CPython【主流】,底层是由C语言开发出来的Python解释器。
- Jython,是由Java语言开发出来的Python解释器,方便与让Python和Java代码做集成。
- IronPython,是基于C#语言开发出来的Python解释器,方便与让Python和C#代码做集成。
- RubyPython,...
- PyPy,是对CPython的优化,他的执行效率提高了。引入编译器的功能,本质上将Python代码进行编译,再去执行编译后的代码。
- ...
注意:常说的Python解释器默认指的就是CPython解释器。
3.4 CPython解释器的版本
CPython的解释器主要有两大版本:
-
2.x,目前最新的Python2.7.18。(2020后不再维护)
Being the last of the 2.x series, 2.7 received bugfix support until 2020. Support officially stopped January 1 2020, and 2.7.18 code freeze occurred on January 1 2020, but the final release occurred after that date. -
3.x,目前最新的3.9.0版本(授课)。
4.环境搭建
- Python解释器,将程序员编写的python代码翻译成计算机能够识别的指令。
- 主流CPython
- 3.9.0版本
- 学习编程本质上的3件事
- 安装 CPython 3.9.0版本解释器
- 学习Python语法并写代码
- 解释器去运行代码
4.1 安装Python解释器
4.1.1 mac系统
-
去Python官网下载Python解释器(3.9.0版本)
https://www.python.org/ -
安装
默认Python解释器安装目录: /Library/Frameworks/Python.framework/Versions/3.9 有bin目录下有一个 python3.9 文件,他就是Python解释器的启动文件。 解释器路径:/Library/Frameworks/Python.framework/Versions/3.9/bin/python3.9 -
写一个简单的Python代码并且让解释器去运行。
name = input("请输入用户名:") print("欢迎使用NB系统:",name)将文件保存在:文稿/hello.py【/Users/wupeiqi/Documents/hello.py】
接下来要让解释器去运行代码文件:
- 打开终端 - 在终端输入:解释器 代码文件 /Library/Frameworks/Python.framework/Versions/3.9/bin/python3.9 /Users/wupeiqi/Documents/hello.py -
【补充】系统环境变量
- 假设你有30个Python文件要运行 /Library/Frameworks/Python.framework/Versions/3.9/bin/python3.9 /Users/wupeiqi/Documents/hello1.py ... /Library/Frameworks/Python.framework/Versions/3.9/bin/python3.9 /Users/wupeiqi/Documents/hello30.py - Python解释器的路径每次不用再写这么长。 - 将 /Library/Frameworks/Python.framework/Versions/3.9/bin 添加到系统的环境变量中。 - 以后再使用Python解释器去运行python代码时,就可以这样: python3.9 /Users/wupeiqi/Documents/hello1.py ... python3.9 /Users/wupeiqi/Documents/hello2.py - 如何将 /Library/Frameworks/Python.framework/Versions/3.9/bin 添加到系统的环境变量中 ? - 默认你不用添加,默认Python解释器在安装的过程中已经帮你添加了。 - 自己手动想添加: - 打开用户目录的下的 .bash_profile 文件(.zprofile) - 在文件中写如下内容# Setting PATH for Python 3.9 # The original version is saved in .zprofile.pysave PATH="/Library/Frameworks/Python.framework/Versions/3.9/bin:${PATH}" export PATH
4.1.2 windows系统
-
Python官网下载Python解释器
https://www.python.org/downloads/release/python-390/ -
在自己电脑上进行安装
python解释器安装目录:C:\Python39 python解释器的路径:C:\Python39\python.exe -
编写一个Python代码并交给Python解释器去运行
name = input("请输入用户名") print("欢迎使用NB系统",name)并将文件保存在:Y:\hello.py
怎么让解释器去运行写好的代码文件呢?
- 打开终端 - 在终端输入:解释器路径 代码路径 -
优化配置(让以后操作Python解释器去运行代码时候更加方便)
- 写了30个Python代码,想要使用解释器去运行。 C:\Python39\python.exe Y:\hello1.py C:\Python39\python.exe Y:\hello2.py ... C:\Python39\python.exe Y:\hello10.py - 然你以后可以方便的去运行代码,不用再写Python解释器所在的路径。 只要你将 C:\Python39 路径添加到系统的环境变量中。以后你在终端就可以: python.exe Y:\hello1.py - 如何将 C:\Python39 添加到环境变量呢?【默认在解释器安装的时已自动添加到环境变量了】
4.2 安装Pycharm编辑器(mac)
帮助我们快速编写代码,用Pycharm可以大大的提高咱们写代码的效率。 + 用解释器去运行代码。
print("asdfasdf")
-
下载Pycharm
https://www.jetbrains.com/pycharm/ -
安装
-
快速使用,写代码+运行代码
-
破解Pycharm(专业版)
4.3 安装Pycharm编辑器(win)
-
下载Pycharm
https://www.jetbrains.com/pycharm/download/other.html -
安装
-
快速使用:编写代码 + 运行代码
-
破解Pycharm(专业版)
day02 快速上手
课程目标:学习Python最基础的语法知识,可以用代码快速实现一些简单的功能。
课程概要:
-
初识编码(密码本)
-
编程初体验
-
编码必须要保持:保存和打开一直,否则会乱码。
-
默认Python解释器是以UTF-8编码的形式打开文件。如果想要修改Python的默认解释器编码,可以这样干:
# -*- coding:gbk -*- print("我是你二大爷") -
建议:所有Python代码文件的都要以UTF-8编码保存和读取。
-
-
输出
-
换行符\n
name = '本章的知识点属于理解为主,接下来对本节所有的知识点进行归纳总结:' \
'\n1. 计算机上所有的东西最终都会转换成为二进制再去运行。' \
'\n2. ascii编码、unicode字符集、utf-8编码本质上都是字符与二进制的关系。' \
'\n - ascii,字符和二进制的对照表。' \
'\n - unicode,字符和二进制(码位)的对照表。' \
'\n - utf-8,对unicode字符集的码位进行压缩处理,间接也维护了字符和二进制的对照表。' \
'\n3. ucs2和ucs4指的是使用多少个字节来表示unicode字符集的码位。' \
'\n4. 目前最广泛的编码为:utf-8,他可以表示所有的字符且存储或网络传输也不会浪费资源(对码位进行压缩了)。' \
'\n5. 二进制、八进制、十进制、十六进制其实就是进位的时机不同。' \
'\n6. 基于Python实现二进制、八进制、十进制、十六进制之间的转换。' \
'\n7. 一个字节8位' \
'\n8. 计算机中常见单位b/B/KB/M/G的关系。' \
'\n9. 汉字,用gbk编码需要用2个字节;用utf-8编码需要用3个字节。'
print(name)
-
想要不换行,则可以这样干
print("看着风景美如画",end=",") print("本想吟诗增天下",end=".") 输出: 看着风景美如画,本想吟诗增天下. print("看着风景美如画,",end="") print("本想吟诗增天下。",end="") 输出: 看着风景美如画,本想吟诗增天下。 name=""" 本章的知识点属于理解为主,了解这些基础之后有利于后面知识点的学习,接下来对本节所有的知识点进行归纳总结: 1. 计算机上所有的东西最终都会转换成为二进制再去运行。 2. ascii编码、unicode字符集、utf-8编码本质上都是字符与二进制的关系。 - ascii,字符和二进制的对照表。 - unicode,字符和二进制(码位)的对照表。 - utf-8,对unicode字符集的码位进行压缩处理,间接也维护了字符和二进制的对照表。 3. ucs2和ucs4指的是使用多少个字节来表示unicode字符集的码位。 4. 目前最广泛的编码为:utf-8,他可以表示所有的字符且存储或网络传输也不会浪费资源(对码位进行压缩了)。 5. 二进制、八进制、十进制、十六进制其实就是进位的时机不同。 6. 基于Python实现二进制、八进制、十进制、十六进制之间的转换。 7. 一个字节8位 8. 计算机中常见单位b/B/KB/M/G的关系。 9. 汉字,用gbk编码需要用2个字节;用utf-8编码需要用3个字节。 """ print(name) -
初识数据类型
-
整形(int)字符串(str)布尔类型(bool)
-
类型转换:
-
其他所有类型转换为布尔类型时,除了 空字符串、0以为其他都是True。
-
字符串转整形时,只有那种 "988" 格式的字符串才可以转换为整形,其他都报错。
-
想要转换为那种类型,就用这类型的英文包裹一下就行。
str(...) int(...) bool(...)
-
-
-
变量
-
变量名的命名规范和建议
-
变量名只能由 字母、数字、下划线 组成。
-
不能以数字开头
-
不能用Python内置的关键字
[‘and’, ‘as’, ‘assert’, ‘break’, ‘class’, ‘continue’, ‘def’, ‘del’, ‘elif’, ‘else’, ‘except’, ‘exec’, ‘finally’, ‘for’, ‘from’, ‘global’, ‘if’, ‘import’, ‘in’, ‘is’, ‘lambda’, ‘not’, ‘or’, ‘pass’, ‘print’, ‘raise’, ‘return’, ‘try’, ‘while’, ‘with’, ‘yield’]
两个建议:
-
下划线连接命名(小写)
-
见名知意
-
-
-
注释
-
输入
-
条件语句
day03 Python基础
课程目标:掌握Python基础中的必备语法知识。
课程概要:
-
循环语句
-
while循环
print("猜数字") flag=True while flag: shuzi=int(input("请输入数字:")) if shuzi>66: print("大了") elif shuzi<66: print("小了") else: print("结果正确") flag=False print("结束")break,用于在while循环中帮你终止循环。
示例:
print("开始运行系统") while True: user = input("请输入用户名:") pwd = input("请输入密码:") if user == 'wupeiqi' and pwd = "oldboy": print("登录成功") break else: print("用户名或密码错误,请重新登录") print("系统结束") # 输出 开始运行系统 >>> 用户名 >>> 密码 正确,登录成功 系统结束 不正确,一直循环输出所以,以后写代码时候,想要结束循环可以通过两种方式实现了,即:条件判断 和 break关键字,两种在使用时无好坏之分,只要能实现功能就行。
continue,在循环中用于 结束本次循环,开始下一次循环。
示例:
print("开始") i = 1 while True: if i == 7: i = i + 1 continue print(i) i = i + 1 if i == 101: break print("结束") # 输出 开始 1 2 3 4 5 6 8 9 10 ... 100 结束写在最后,对于break和continue都是放在循环语句中用于控制循环过程的,一旦遇到break就停止所有循环,一旦遇到continue就停止本次循环,开始下次循环。
while else
当while后的条件不成立时,else中的代码就会执行。
num=1 while num<5: print(num) num+=1 else: print(666)
-
-
字符串格式化
-
%
name="凫弥" age=23 text="我叫%s,今年%d岁,这个我下载90%%了"%(name,age) print(text)https://www.cnblogs.com/wupeiqi/articles/5484747.html
message = "%(name)s你什么时候过来呀?%(user)s今天不在呀。" % {"name": "死鬼", "user": "李杰"} print(message) -
format
text = "我叫{0},今年18岁".format("武沛齐") text = "我叫{0},今年{1}岁".format("武沛齐",18) text = "我叫{0},今年{1}岁,真是的姓名是{0}。".format("武沛齐",18)text = "我叫{},今年18岁".format("武沛齐") text = "我叫{},今年{}岁".format("武沛齐",18) text = "我叫{},今年{}岁,真是的姓名是{}。".format("武沛齐",18,"武沛齐")text = "我叫{n1},今年18岁".format(n1="武沛齐") text = "我叫{n1},今年{age}岁".format(n1="武沛齐",age=18) text = "我叫{n1},今年{age}岁,真是的姓名是{n1}。".format(n1="武沛齐",age=18)text = "我叫{0},今年{1}岁" data1 = text.format("武沛齐",666) data2 = text.format("alex",73)text = "我叫%s,今年%d岁" data1 = text %("武沛齐",20) data2 = text %("alex",84) -
f
到Python3.6版本,更便捷。
text = f"嫂子喜欢{'跑步'},跑完之后满身大汗"action = "跑步" text = f"嫂子喜欢{action},跑完之后满身大汗"name = "喵喵" age = 19 text = f"嫂子的名字叫{name},今年{age}岁" print(text)text = f"嫂子的名字叫喵喵,今年{19 + 2}岁" print(text)# 在Python3.8引入 text = f"嫂子的名字叫喵喵,今年{19 + 2=}岁" print(text)# 进制转换 v1 = f"嫂子今年{22}岁" print(v1) v2 = f"嫂子今年{22:#b}岁" print(v2) v3 = f"嫂子今年{22:#o}岁" print(v3) v4 = f"嫂子今年{22:#x}岁" print(v4)# 理解 text = f"我是{'alex'},我爱大铁锤" name = "alex" text = f"我是{name},我爱大铁锤" name = "alex" text = f"我是{ name.upper() },我爱大铁锤" # 输出:我是ALEX,我爱大铁锤
-
-
运算符
提到运算符,我想大家首先想到的就是加、减、乘、除之类, 本节要系统的跟大家来聊一聊,我们写代码时常见的运算符可以分为5种:
-
算数运算符,例如:加减乘除
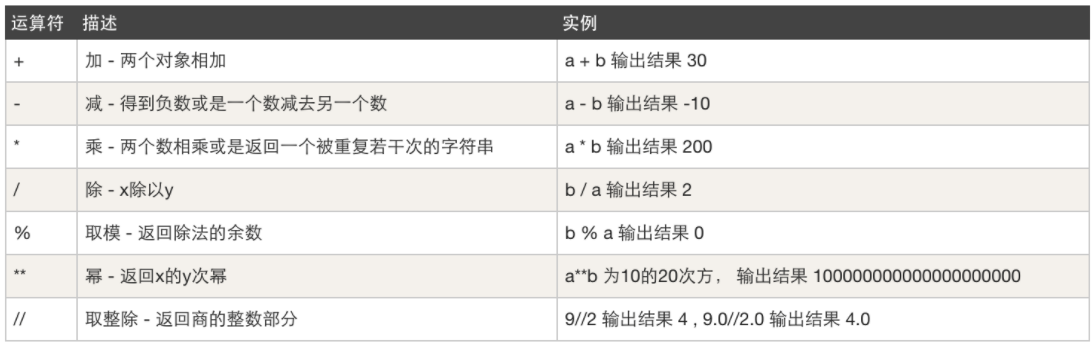
print( 9//2 ) -
比较运算符,例如:大于、小于

注意:python3中不支持
<>if 1 >2: pass while 1>2: pass data = 1 == 2 -
赋值运算,例如:变量赋值
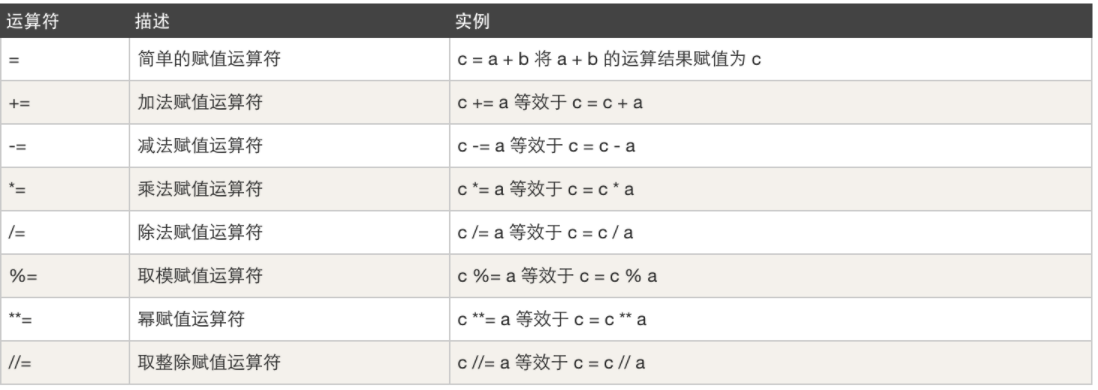
num = 1 while num < 100: print(num) # num = num + 1 num += 1 -
成员运算,例如:是否包含

v1 = "le" in "alex" # True/False # 让用户输入一段文本,检测文本中是否包含敏感词。 text = input("请输入内容:") if "苍老师" in text: print("少儿不宜") else: print(text) -
逻辑运算,例如:且或非

if username == "alex" and pwd == "123": pass data = 1 > 2 if not data: pass
运算符优先级
运算符的优先级有很多,常见的没几个,推荐你记住3个即可:
-
算数优先级优先级 大于 比较运算符
if 2 + 10 > 11: print("真") else: print("假") -
比较运算符优先级 大于 逻辑运算符
if 1>2 and 2<10: print("成立") else: print("不成立") -
逻辑运算符内部三个优先级 not > and > or
if not 1 and 1>2 or 3 == 8: print("真") else: print("假")
上述这3个优先级从高到低总结:
**加减乘除 > 比较 > not and or**。绝招:加括号。-
or比较时,第一个为真则为真;
-
and比较时,第一个为假则为假。
# or,看第一个值,如果第一个值为真,结果就应该是第一个值,否则就结果就是第二个值。 # and,看第一个值,如果第一个值真,结果就应该是第二个值,否则结果就是第一个值。作业
-
实现用户登录系统,并且要支持连续三次输错之后直接退出,并且在每次输错误时显示剩余错误次数(提示:使⽤字符串格式化)。
""" count = 0 while count < 3: count += 1 user = input("请输入用户名:") pwd = input("请输入密码:") if user == "wupeiqi" and pwd == "123": print("成功") break else: message = "用户名或者密码错误,剩余错误次数为{}次".format(3 - count) print(message) """ """ count = 3 while count > 0: count -= 1 user = input("请输入用户名:") pwd = input("请输入密码:") if user == "wupeiqi" and pwd == "123": print("成功") break else: message = "用户名或者密码错误,剩余错误次数为{}次".format(count) print(message) """ -
猜年龄游戏
要求:允许用户最多尝试3次,3次都没猜对的话,就直接退出,如果猜对了,打印恭喜信息并退出。count = 0 while count < 3: count += 1 age = input("请输入年龄:") age = int(age) if age == 73: print("恭喜你猜对了") break else: print("猜错了") print("程序结束") -
猜年龄游戏升级版
要求:允许用户最多尝试3次,每尝试3次后,如果还没猜对,就问用户是否还想继续玩,如果回答Y,就继续让其猜3次,以此往复,如果回答N,就退出程序,如何猜对了,就直接退出。count = 0 while count < 3: count += 1 age = input("请输入年龄:") age = int(age) if age == 73: print("恭喜你猜对了") break else: print("猜错了") if count == 3: choice = input("是否想继续玩(Y/N)?") if choice == "N": break elif choice == "Y": count = 0 continue else: print("内容输入错误") break print("程序结束")
-
day04 进制和编码
课程目标:讲解计算机中一些必备的常识知识,让学员了解一些常见名词背后的含义(重在理解)。
课程概要:
-
python代码的运行方式
-
进制
- 进制转换

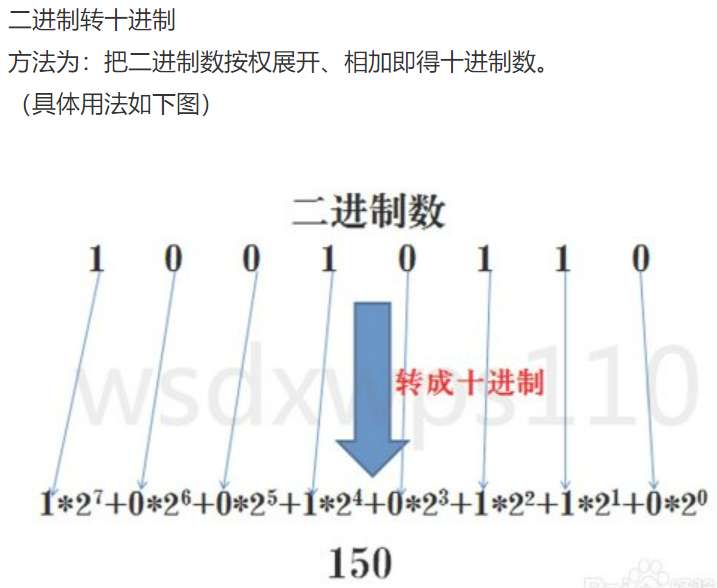
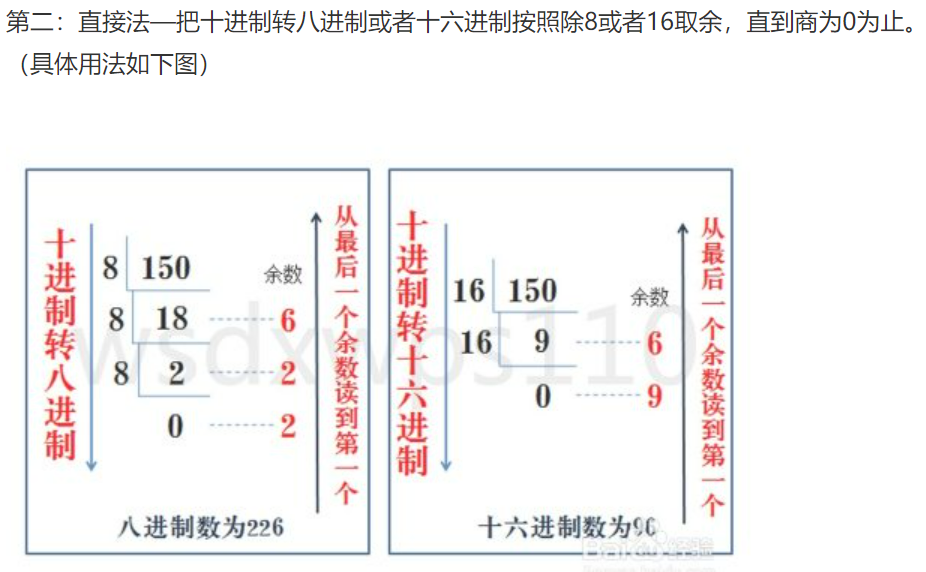

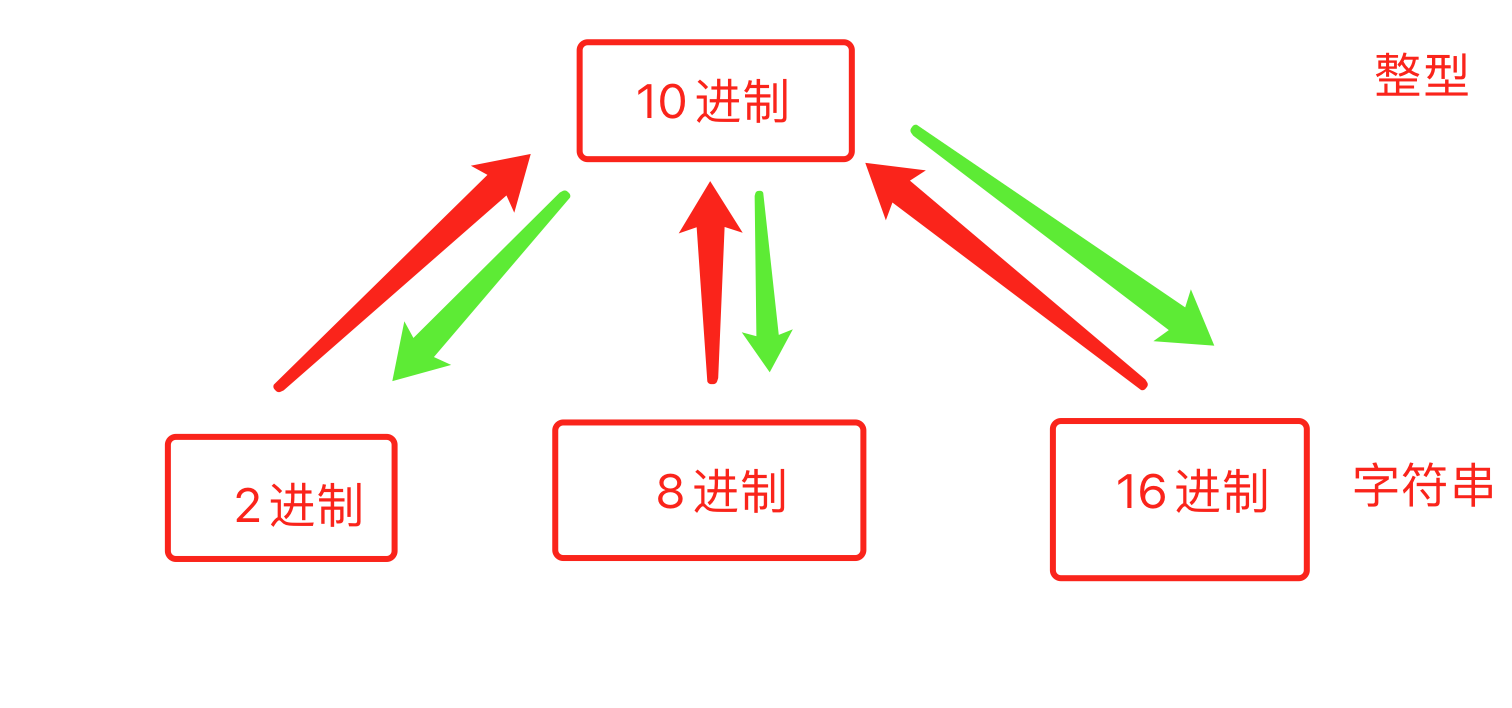
v1 = bin(25) # 十进制转换为二进制 print(v1) # "0b11001" v2 = oct(23) # 十进制转换为八进制 print(v2) # "0o27" v3 = hex(28) # 十进制转换为十六进制 print(v3) # "0x1c"i1 = int("0b11001",base=2) # 25 i2 = int("0o27",base=8) # 23 i3 = int("0x1c",base=16) # 28 -
计算机中的单位
-
编码
-
4.1 ascii编码
ascii规定使用1个字节来表示字母与二进制的对应关系。
00000000 00000001 w 00000010 B 00000011 a ... 11111111 2**8 = 256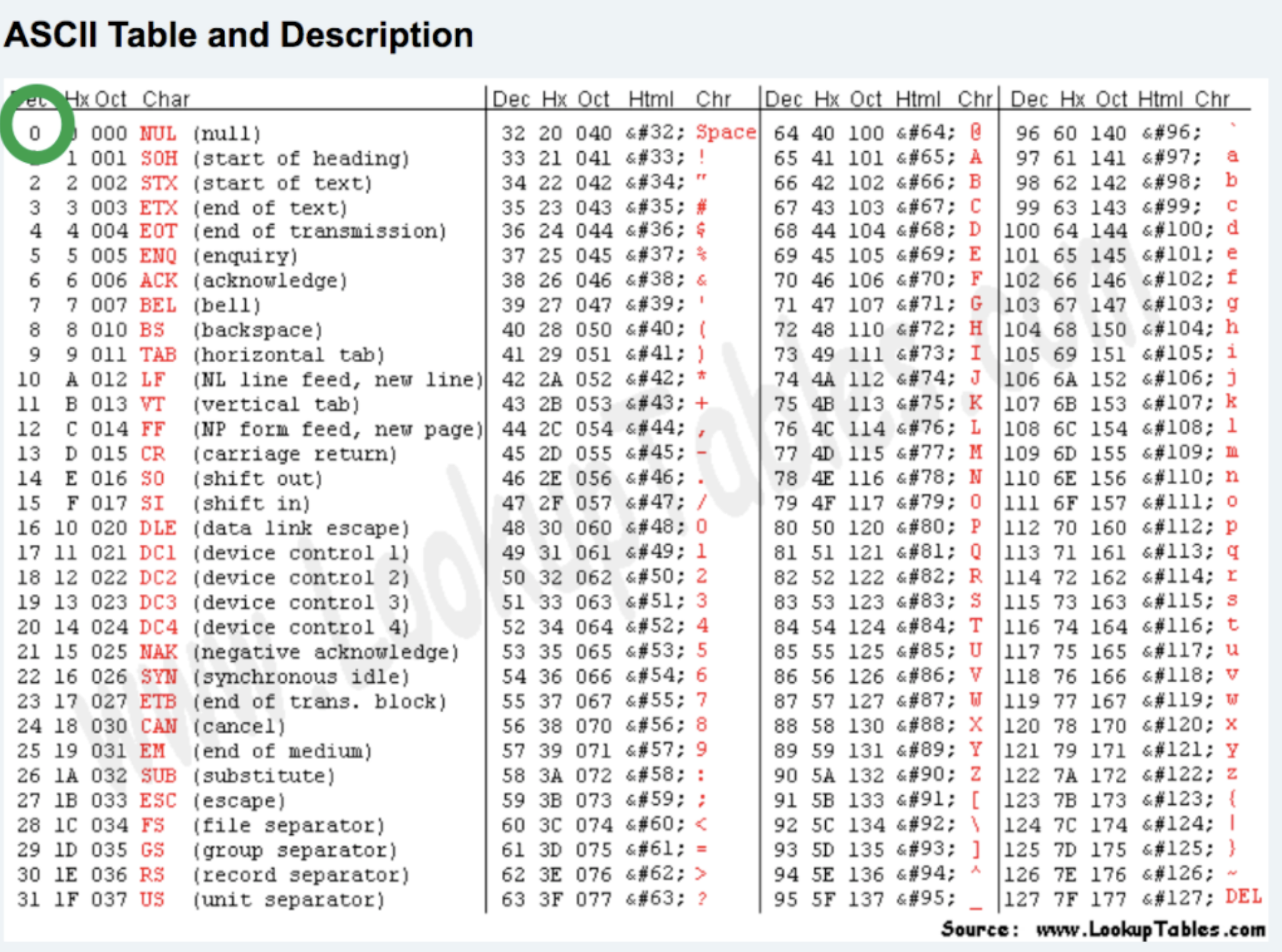
-
4.2 gb-2312编码
gb-2312编码,由国家信息标准委员会制作(1980年)。
gbk编码,对gb2312进行扩展,包含了中日韩等文字(1995年)。
在与二进制做对应关系时,由如下逻辑:
- 单字节表示,用一个字节表示对应关系。2**8 = 256
- 双字节表示,用两个字节表示对应关系。2**16 = 65536中可能性。
-
4.3 unicode
unicode也被称为万国码,为全球的每个文字都分配了一个码位(二进制表示)。
-
ucs2
用固定的2个字节去表示一个文字。 00000000 00000000 悟 ... 2**16 = 65535 -
ucs4
用固定的4个字节去表示一个文字。 00000000 00000000 00000000 00000000 无 ... 2**32 = 4294967296
文字 十六进制 二进制 ȧ 0227 1000100111 ȧ 0227 00000010 00100111 ucs2 ȧ 0227 00000000 00000000 00000010 00100111 ucs4 乔 4E54 100111001010100 乔 4E54 01001110 01010100 ucs2 乔 4E54 00000000 00000000 01001110 01010100 ucs4 😆 1F606 11111011000000110 😆 1F606 00000000 00000001 11110110 00000110 ucs4无论是ucs2和ucs4都有缺点:浪费空间
文字 十六进制 二进制 A 0041 01000001 A 0041 00000000 01000001 A 0041 00000000 00000000 00000000 01000001unicode的应用:在文件存储和网络传输时,不会直接使用unicode,而在内存中会unicode。
-
-
4.4 utf-8编码
包含所有文字和二进制的对应关系,全球应用最为广泛的一种编码(站在巨人的肩膀上功成名就)。
本质上:utf-8是对unicode的压缩,用尽量少的二进制去与文字进行对应。
unicode码位范围 utf-8 0000 ~ 007F 用1个字节表示 0080 ~ 07FF 用2个字节表示 0800 ~ FFFF 用3个字节表示 10000 ~ 10FFFF 用4个字节表示具体压缩的流程:
-
第一步:选择转换模板
码位范围(十六进制) 转换模板 0000 ~ 007F 0XXXXXXX 0080 ~ 07FF 110XXXXX 10XXXXXX 0800 ~ FFFF 1110XXXX 10XXXXXX 10XXXXXX 10000 ~ 10FFFF 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX 例如: "B" 对应的unicode码位为 0042,那么他应该选择的一个模板。 "ǣ" 对应的unicode码位为 01E3,则应该选择第二个模板。 "武" 对应的unicode码位为 6B66,则应该选择第三个模板。 "沛" 对应的unicode码位为 6C9B,则应该选择第三个模板。 "齐" 对应的unicode码位为 9F50,则应该选择第三个模板。 😆 对应的unicode码位为 1F606,则应该选择第四个模板。 注意:一般中文都使用第三个模板(3个字节),这也就是平时大家说中文在utf-8中会占3个字节的原因了。 -
第二步:在模板中填入数据
- "武" -> 6B66 -> 110 101101 100110 - 根据模板去套入数据 1110XXXX 10XXXXXX 10XXXXXX 1110XXXX 10XXXXXX 10100110 1110XXXX 10101101 10100110 11100110 10101101 10100110 在UTF-8编码中 ”武“ 11100110 10101101 10100110 - 😆 -> 1F606 -> 11111 011000 000110 - 根据模板去套入数据 11110000 10011111 10011000 10000110
-
-
4.5 Python相关的编码
字符串(str) "alex媳妇叫铁锤" unicode处理 一般在内存 字节(byte) b"alexfdsfdsdfskdfsd" utf-8编码 or gbk编码 一般用于文件存储或网络处理编码v1 = "武" v2 = "武".encode("utf-8") v2 = "武".encode("gbk")若网页根据meta=utf-8处理不成功,则使用字符串.encode("gbk", "ignore").decode("gbk", "ignore")处理即可
将一个字符串写入到一个文件中。
name = "嫂子热的满身大汗" data = name.encode("utf-8") # 打开一个文件 file_object = open("log.txt",mode="wb") # 在文件中写内容 file_object.write(data) # 关闭文件 file_object.close()
总结
本章的知识点属于理解为主,了解这些基础之后有利于后面知识点的学习,接下来对本节所有的知识点进行归纳总结:
-
计算机上所有的东西最终都会转换成为二进制再去运行。
-
ascii编码、unicode字符集、utf-8编码本质上都是字符与二进制的关系。
- ascii,字符和二进制的对照表。
- unicode,字符和二进制(码位)的对照表。
- utf-8,对unicode字符集的码位进行压缩处理,间接也维护了字符和二进制的对照表。
-
ucs2和ucs4指的是使用多少个字节来表示unicode字符集的码位。
-
目前最广泛的编码为:utf-8,他可以表示所有的字符且存储或网络传输也不会浪费资源(对码位进行压缩了)。
-
二进制、八进制、十进制、十六进制其实就是进位的时机不同。
-
基于Python实现二进制、八进制、十进制、十六进制之间的转换。
-
一个字节8位
-
计算机中常见单位b/B/KB/M/G的关系。
-
汉字,用gbk编码需要用2个字节;用utf-8编码需要用3个字节。
-
基于Python实现将字符串转换为字节(utf-8编码)
# 字符串类型 name = "武沛齐" print(name) # 武沛齐 # 字符串转换为字节类型 data = name.encode("utf-8") print(data) # b'\xe6\xad\xa6\xe6\xb2\x9b\xe9\xbd\x90' # 把字节转换为字符串 old = data.decode("utf-8") print(old) -
基于Python实现将字符串转换为字节(gbk编码)S
# 字符串类型 name = "武沛齐" print(name) # 武沛齐 # 字符串转换为字节类型 data = name.encode("gbk") # print(data) # b'\xe6\xad\xa6\xe6\xb2\x9b\xe9\xbd\x90' utf8,中文3个字节 print(data) # b'\xce\xe4\xc5\xe6\xc6\xeb' gbk,中文2个字节 # 把字节转换为字符串 old = data.decode("gbk") print(old)
-
day05 数据类型(上)
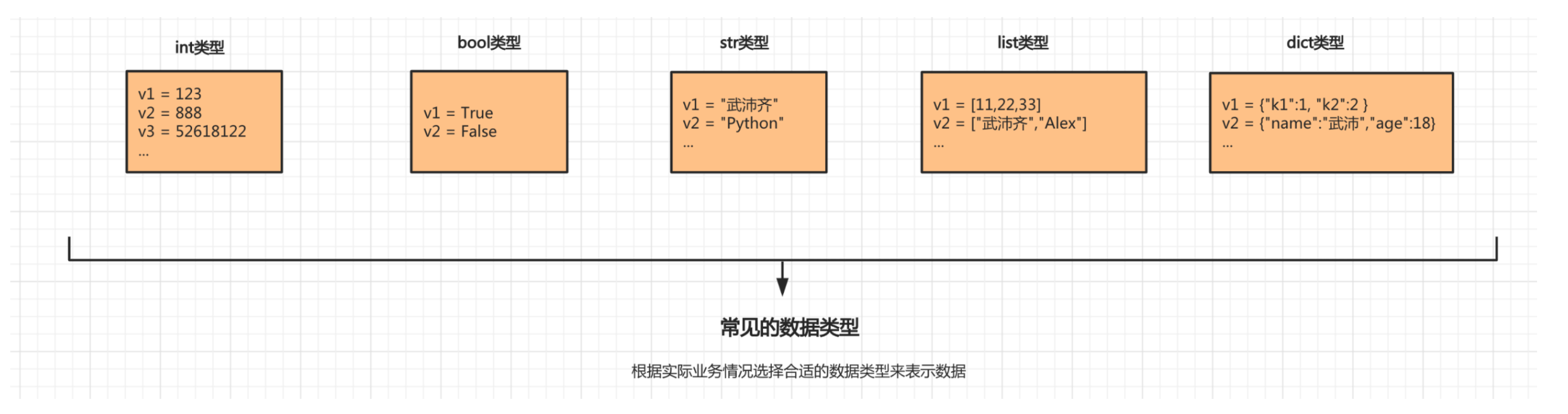
接下来的3天的课程都是来讲解数据类型的知识点,常见的数据类型:
- int,整数类型(整形)
- bool,布尔类型
- str,字符串类型
- list,列表类型
- tuple,元组类型
- dict,字典类型
- set,集合类型
- float,浮点类型(浮点型)
每种数据类型都有自己的特点及应用场景,以后的开发中需要根据实际的开发情况选择合适的数据类型。
1.整型
- 独有功能
num=20
print(bin(num)) #0b10100
wei=num.bit_length()
print(wei) #5
-
公共功能(加减乘除)
-
转换
# 字符串转整型 v1 = int("186",base=10) # 把字符串看成十进制的值,然后再转换为 十进制整数,结果:v1 = 186 v2 = int("0b1001",base=2) # 把字符串看成二进制的值,然后再转换为 十进制整数,结果:v1 = 9 (0b表示二进制) v3 = int("0o144",base=8) # 把字符串看成八进制的值,然后转换为 十进制整数,结果:v1 = 100 (0o表示八进制) v4 = int("0x59",base=16) # 把字符串看成十六进制的值,然后转换为 十进制整数,结果:v1 = 89 (0x表示十六进制) -
长整型
-
Python3:整型(无限制)
-
Python2:整型、长整形
-
在python2中跟整数相关的数据类型有两种:int(整型)、long(长整型),他们都是整数只不过能表示的值范围不同。
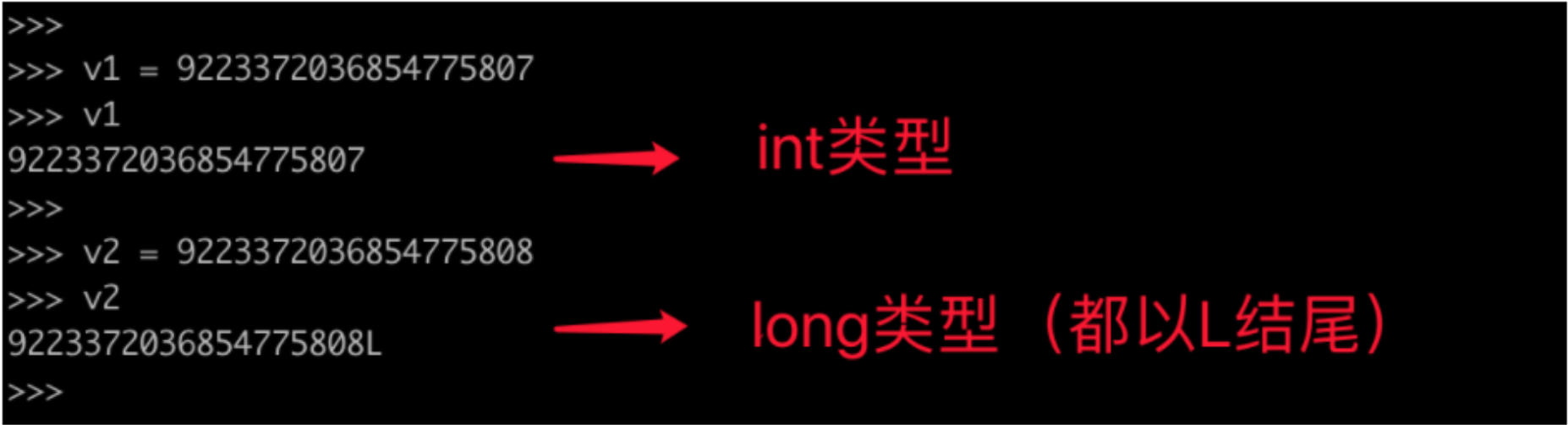
- int,可表示的范围:-9223372036854775808~9223372036854775807
- long,整数值超出int范围之后自动会转换为long类型(无限制)。
在python3中去除了long只剩下:int(整型),并且 int 长度不在限制。
-
地板除
-
Py3:
v1 = 9/2
print(v1) # 4.5
- py2:
v1 = 9/2
print(v1) # 4
from __future__ import division
v1 = 9/2
print(v1) # 4.5
2.布尔类型
-
转换
整数0、空字符串、空列表、空元组、空字典转换为布尔值时均为False 其他均为True 0 "" [] or list() () or tuple() set() None {} or dict()
3.字符串类型
独有功能
开头 .startswith()
v1 = "叨逼叨的一天,烦死了"
# True
result = v1.startswith("叨逼叨的一天")
print(result) # 值为True
# 案例
v1 = input("请输入住址:")
if v1.startswith("北京市"):
print("北京人口")
else:
print("非北京人口")
结尾 .endswitch()
v1 = "叨逼叨的一天,烦死了"
result = v1.endswith("烦死了")
print(result) # 值为True
# 案例
address = input("请输入地址:")
if address.endswith('村'):
print("农业户口")
else:
print("非农户口")
十进制数 .isdecimal()
v1 = "1238871"
result = v1.isdecimal()
print(result) # True
# 案例,两个数相加。
v1 = input("请输入值:") # ”666“
v2 = input("请输入值:") # ”999“
if v1.isdecimal() and v2.isdecimal():
data = int(v1) + int(v2)
print(data)
else:
print("请正确输入数字")
v1 = "123"
print(v1.isdecimal()) # True
v2 = "①"
print(v2.isdecimal()) # False
v3 = "123"
print(v3.isdigit()) # True
v4 = "①"
print(v4.isdigit()) # True
去除空格 .strip()
msg = " H e ll o啊,树哥 "
data = msg.strip()
print(data) # 将msg两边的空白去掉,得到"H e ll o啊,树哥"
msg = " H e ll o啊,树哥 "
data = msg.lstrip()
print(data) # 将msg左边的空白去掉,得到"H e ll o啊,树哥 "
msg = " H e ll o啊,树哥 "
data = msg.rstrip()
print(data) # 将msg右边的空白去掉,得到" H e ll o啊,树哥"
补充:去除 空格、换行符、制表符。
# 案例
code = input("请输入4位验证码:") # FB87
data = code.strip()
if data == "FB87":
print('验证码正确')
else:
print("验证码错误")
再补充:去除字符串两边指定的内容
msg = "哥H e ll o啊,树哥"
data = msg.strip("哥")
print(data) # 将msg两边的哥去掉,得到"H e ll o啊,树"
msg = " 哥H e ll o啊,树哥"
data = msg.lstrip().lstrip('哥')
print(data) # 将msg左边的空白和哥依次去掉,得到"H e ll o啊,树哥"
大写 .upper()
msg = "my name is oliver queen"
data = msg.upper()#全大写输出
date = msg.capitalize()#首字母大写输出
小写 .lower()
msg = "My Name Is Oliver Queen"
data = msg.lower()
print(data) # 输出为:my name is oliver queen
替换 .replace()
char_list = ["草拟吗","逗比","二蛋","钢球"]
content = input("请输入评论信息")
for item in char_list:
content = content.repalce(item,"**")
print(content)
切割 .split()
data = "武沛齐|root|wupeiqi@qq.com|s|e|d|g"
print(data.split("|"))#['武沛齐', 'root', 'wupeiqi@qq.com', 's', 'e', 'd', 'g']
print(data.split("|",1))#['武沛齐', 'root|wupeiqi@qq.com|s|e|d|g']
print(data.split("|",2))#['武沛齐', 'root', 'wupeiqi@qq.com|s|e|d|g']
print(data.split("|",3))#['武沛齐', 'root', 'wupeiqi@qq.com', 's|e|d|g']
print(data.split("|",4))#['武沛齐', 'root', 'wupeiqi@qq.com', 's', 'e|d|g']
print(data.split("|",5))#['武沛齐', 'root', 'wupeiqi@qq.com', 's', 'e', 'd|g']
# 案例:判断用户名密码是否正确
info = "武沛齐,root" # 备注:字符串中存储了用户名和密码
user_list = info.split(',') # 得到一个包含了2个元素的列表 [ "武沛齐" , "root" ]
# user_list[0]
# user_list[1]
user = input("请输入用户名:")
pwd = input("请输入密码:")
if user == user_list[0] and pwd == user_list[1]:
print("登录成功")
else:
print("用户名或密码错误")
拼接 "".join()
data_list = ["alex","是","大烧饼"]
v1 = "_".join(data_list) # alex_是_大烧饼
print(v1)
格式化 .format()
name = "{0}的喜欢干很多行业,例如有:{1}、{2} 等"
data = name.format("老王","护士","嫩模")
print(data) # 老王的喜欢干很多行业,例如有:护士、嫩模 等
print(name) # "{0}的喜欢干很多行业,例如有:{1}、{2} 等"
name = "{}的喜欢干很多行业,例如有:{}、{} 等"
data = name.format("老王","护士","嫩模")
print(data) # 老王的喜欢干很多行业,例如有:护士、嫩模 等
name = "{name}的喜欢干很多行业,例如有:{h1}、{h2} 等"
data = name.format(name="老王",h1="护士",h2="嫩模")
print(data) # 老王的喜欢干很多行业,例如有:护士、嫩模 等
转换字节 .encode("utf-8")
data = "嫂子" # unicode,字符串类型
v1 = data.encode("utf-8") # utf-8,字节类型
v2 = data.encode("gbk") # gbk,字节类型
print(v1) # b'\xe5\xab\x82 \xe5\xad\x90'
print(v2) # b'\xc9\xa9 \xd7\xd3'
s1 = v1.decode("utf-8") # 嫂子
s2 = v2.decode("gbk") # 嫂子
print(s1)
print(s2)
字符串居中 .center() .ljust() .rjust()
v1 = "王老汉"
# data = v1.center(21, "-")
# print(data) #---------王老汉---------
# data = v1.ljust(21, "-")
# print(data) # 王老汉------------------
# data = v1.rjust(21, "-")
# print(data) # ------------------王老汉
填充 0 .zfill()
data = "alex"
v1 = data.zfill(10)
print(v1) # 000000alex
# 应用场景:处理二进制数据
data = "101" # "00000101"
v1 = data.zfill(8)
print(v1) # "00000101"
回车换行 \n
text = """id,name,age,phone,job
1,alex,22,13651054608,IT
2,wusir,23,13304320533,Tearcher
3,老男孩,18,1333235322,IT"""
data = text.split("\n")
print(data)#['id,name,age,phone,job', '1,alex,22,13651054608,IT ', '2,wusir,23,13304320533,Tearcher', '3,老男孩,18,1333235322,IT']
公共功能
相加
v1 = "alex" + "大sb"
print(v1)
相乘
data = "嫂子" * 3
print(data) # 嫂子嫂子嫂子
长度
data = "嫂子满身大汉"
value = len(data)
print(value) # 6
索引
message = "来做点py交易呀"
# 0 1 2345 6 7
# ... -3 -2 -1
print(message[0]) # "来"
print(message[1]) # "做"
print(message[2]) # "点"
print(message[-1]) # 呀
print(message[-2]) # 呀
print(message[-3]) # 呀
注意:字符串中是能通过索引取值,无法修改值。【字符串在内部存储时不允许对内部元素修改,想修改只能重新创建。】
message = "来做点py交易呀"
index = 0
while index < len(message):
value = message[index]
print(value)
index += 1
message = "来做点py交易呀"
index = len(message) - 1
while index >=0:
value = message[index]
print(value)
index -= 1
切片
message = "来做点py交易呀"
print(message[0:2]) # "来做"
print(message[3:7]) # "py交易"
print( message[3:] ) # "py交易呀"
print( message[:5] ) # "来做点py"
print(message[4:-1]) # "y交易"
print(message[4:-2]) # "y交"
print( message[4:len(message)] ) # "y交易呀"
注意:字符串中的切片只能读取数据,无法修改数据。【字符串在内部存储时不允许对内部元素修改,想要修改只能重新创建】
message = "来做点py交易呀"
value = message[:3] + "Python" + message[5:]
print(value)
步长
name = "生活不是电影,生活比电影苦"
0 1 2 34 56 7 89101112
print( name[ 0:5:2 ] ) # 输出:生不电 【前两个值表示区间范围,最有一个值表示步长】
print( name[ :8:2 ] ) # 输出:生不电, 【区间范围的前面不写则表示起始范围为0开始】、
# 此处老师讲解时,错把 name[ 2::3 ]看成了name[ 2::2 ],更正下。(感谢 B站 放酱啊噗啊噗 同学的反馈)
# print( name[ 2::2 ] ) # 输出:不电,活电苦
# print( name[ 2::3 ] ) # 输出:不影活影
print( name[ 2::3 ] ) # 输出:不影活影【区间范围的后面不写则表示结束范围为最后】
print( name[ ::2 ] ) # 输出:生不电,活电苦 【区间范围不写表示整个字符串】
print( name[ 8:1:-1 ] ) # 输出:活生,影电是不 【倒序】
name = "生活不是电影,生活比电影苦"
print(name[8:1:-1]) # 输出:活生,影电是不 【倒序】
print(name[-1:1:-1]) # 输出:苦影电比活生,影电是不 【倒序】
# 面试题:给你一个字符串,请将这个字符串翻转。
value = name[-1::-1]
print(value) # 苦影电比活生,影电是不活生
循环
-
while循环
message = "来做点py交易呀" index = 0 while index < len(message): value = message[index] print(value) index += 1 -
for循环
message = "来做点py交易呀" for char in message: print(char) -
range,帮助我们创建一系列的数字
range(10) # [0,1,2,3,4,5,6,7,8,9] range(1,10) # [1,2,3,4,5,6,7,8,9] range(1,10,2) # [1,3,5,7,9] range(10,1,-1) # [10,9,8,7,6,5,4,3,2] -
For + range
for i in range(10): print(i)message = "来做点py交易呀" for i in range(5): # [0,1,2,3,4] print(message[i])message = "来做点py交易呀" for i in range( len(message) ): # [0,1,2,3,4,5,6,7] print(message[i])
一般应用场景:
-
while,一般在做无限制(未知)循环此处时使用。
while True: ...# 用户输入一个值,如果不是整数则一直输入,直到是整数了才结束。 num = 0 while True: data = input("请输入内容:") if data.isdecimal(): num = int(data) break else: print("输入错误,请重新输入!") -
for循环,一般应用在已知的循环数量的场景。
message = "来做点py交易呀" for char in message: print(char)for i in range(30): print(message[i]) -
break和continue关键字
message = "来做点py交易呀" for char in message: if char == "p": continue print(char) # 输出: 来 做 点 y 交 易 呀message = "来做点py交易呀" for char in message: if char == "p": break print(char) # 输出: 来 做 点for i in range(5): print(i)# 0 1 2 3 4 for j in range(3): break print(j) # 0 1 2 # 0 1 2 # 0 1 2 # 0 1 2 # 0 1 2
day06 数据类型(中)
常见的数据类型:
- int,整数类型(整形)
- bool,布尔类型
- str,字符串类型
- list,列表类型
- tuple,元组类型
- dict,字典类型
- set,集合类型
- float,浮点类型(浮点型)
1.列表(list)
列表(list),是一个有序且可变的容器,在里面可以存放多个不同类型的元素。
独有功能
追加 .append
# 案例2
welcome = "欢迎使用NB游戏".center(30, '*')
print(welcome)
user_count = 0
while True:
count = input("请输入游戏人数:")
if count.isdecimal():
user_count = int(count)
break
else:
print("输入格式错误,人数必须是数字。")
批量追加 .extend
tools = ["搬砖","菜刀","榔头"]
weapon = ["AK47","M6"]
#tools.extend(weapon) # weapon中的值逐一追加到tools中
#print(tools) # ["搬砖","菜刀","榔头","AK47","M6"]
weapon.extend(tools)
print(tools) # ["搬砖","菜刀","榔头"]
print(weapon) # ["AK47","M6","搬砖","菜刀","榔头"]
等价于:
tools = ["搬砖","菜刀","榔头"]
weapon = ["AK47","M6"]
for item in weapon:
tools.append(item)
print(tools) # ["搬砖","菜刀","榔头","AK47","M6"]
```
插入 .insert
# 案例
name_list = []
while True:
name = input("请输入购买火车票用户姓名(Q/q退出):")
if name.upper() == "Q":
break
if name.startswith("刁"):
name_list.insert(0, name)
else:
name_list.append(name)
print(name_list)
倒叙排列:.insert(0,i)
data_list = []
for i in range(51):
if i % 3 == 0:
data_list.append(i)
print(data_list)#[0, 3, 6, 9, 12, 15, 18, 21, 24, 27, 30, 33, 36, 39, 42, 45, 48]
data_list.insert(0,i)
print(data_list)#[48, 45, 42, 39, 36, 33, 30, 27, 24, 21, 18, 15, 12, 9, 6, 3, 0]
删除 .remove
li.remove --删除第一个
li.pop(i) --删除第i个
del li[2:4] -- 删除第2个,第3个
# 案例:自动抽奖程序
import random
data_list = ["iphone12", "女友", "大保健一次", "泰国5日游"]
while data_list:
name = input("自动抽奖程序,请输入自己的姓名:")
# 随机从data_list抽取一个值出来
value = random.choice(data_list) # "女友"
print( "恭喜{},抽中{}.".format(name, value) )
data_list.remove(value) # "女友"
索引删除 .pop
user_list = ["王宝强","陈羽凡","Alex","贾乃亮","Alex"]
# 0 1 2 3 4
user_list.pop(1)
print(user_list) # ["王宝强","Alex","贾乃亮","Alex"]
user_list.pop()#默认删除最后一位
print(user_list) # ["王宝强","Alex","贾乃亮"]
# 案例:排队买火车票
# ["alex","李杰","eric","武沛齐","老妖","肝胆"]
user_queue = []
while True:
name = input("北京~上海火车票,购买请输入姓名排队(Q退出):")
if name == "Q":
break
user_queue.append(name)
ticket_count = 3
for i in range(ticket_count):
username = user_queue.pop(0)
message = "恭喜{},购买火车票成功。".format(username)
print(message)
# user_queue = ["武沛齐","老妖","肝胆"]
faild_user = "、".join(user_queue) # "武沛齐、老妖、肝胆"
faild_message = "非常抱歉,票已售完,以下几位用户请选择其他出行方式,名单:{}。".format(faild_user)
print(faild_message)
清空原列表 .clear
user_list = ["王宝强","陈羽凡","Alex","贾乃亮","Alex"]
user_list.clear()
print(user_list) # []
获取索引 .index
user_list = ["王宝强","陈羽凡","Alex","贾乃亮","Alex"]
# 0 1 2 3 4
if "Alex" in user_list:
index = user_list.index("Alex")
print(index) # 2
else:
print("不存在")
列表元素排序 .sort
# 数字排序
num_list = [11, 22, 4, 5, 11, 99, 88]
print(num_list)
num_list.sort() # 让num_list从小到大排序
num_list.sort(reverse=True) # # 让num_list从大到小排序
print(num_list)
注意:排序时内部元素无法进行比较时,程序会报错(尽量数据类型统一)。
反转原列表 .reverse
user_list = ["王宝强","陈羽凡","Alex","贾乃亮","Alex"]
user_list.reverse()
print(user_list)
也可以:
user_list[-1::-1]等价于user_list.reverse()
公共功能
-
相加
-
相乘
-
运算符in包含
由于列表内部是由多个元素组成,可以通过in来判断元素是否在列表中。user_list = ["狗子","二蛋","沙雕","alex"] result = "alex" in user_list # result = "alex" not in user_list print(result) # True if "alex" in user_list: print("在,把他删除") user_list.remove("alex") else: print("不在")注意:列表检查元素是否存在时,是采用逐一比较的方式,效率会比较低。
获取长度 len()
索引
# 读
user_list = ["范德彪","刘华强",'尼古拉斯赵四']
print( user_list[0] )
print( user_list[2] )
print( user_list[3] ) # 报错
# 改
user_list = ["范德彪","刘华强",'尼古拉斯赵四']
user_list[0] = "武沛齐"
print(user_list) # ["武沛齐","刘华强",'尼古拉斯赵四']
# 删
user_list = ["范德彪","刘华强",'尼古拉斯赵四']
del user_list[1]
user_list.remove("刘华强")
ele = user_list.pop(1)
注意:超出索引范围会报错。
提示:由于字符串是不可变类型,所以他只有索引读的功能,而列表可以进行 读、改、删
切片
# 读
user_list = ["范德彪","刘华强",'尼古拉斯赵四']
print( user_list[0:2] ) # ["范德彪","刘华强"]
print( user_list[1:] )
print( user_list[:-1] )
# 改
user_list = ["范德彪", "刘华强", '尼古拉斯赵四']
user_list[0:2] = [11, 22, 33, 44]
print(user_list) # 输出 [11, 22, 33, 44, '尼古拉斯赵四']
user_list = ["范德彪", "刘华强", '尼古拉斯赵四']
user_list[2:] = [11, 22, 33, 44]
print(user_list) # 输出 ['范德彪', '刘华强', 11, 22, 33, 44]
#新增添加
user_list = ["范德彪", "刘华强", '尼古拉斯赵四']
user_list[3:] = [11, 22, 33, 44]
print(user_list) # 输出 ['范德彪', '刘华强', '尼古拉斯赵四', 11, 22, 33, 44]
步长
# 案例:实现列表的翻转
user_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"]
new_data = user_list[::-1]
print(new_data)
data_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"]
data_list.reverse()
print(data_list)
for循环
user_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"]
for item in user_list:
print(item)
等价:
user_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"]
for index in range( len(user_list) ):
item = user_index[index]
print(item)
切记,循环的过程中对数据进行删除会踩坑【面试题】。
# 错误方式, 有坑,结果不是你想要的。不能边循环边删除
user_list = ["刘的话", "范德彪", "刘华强", '刘尼古拉斯赵四', "宋小宝", "刘能"]
for item in user_list:
if item.startswith("刘"):
user_list.remove(item)
print(user_list)
# 正确方式,倒着删除。
user_list = ["刘的话", "范德彪", "刘华强", '刘尼古拉斯赵四', "宋小宝", "刘能"]
for index in range(len(user_list) - 1, -1, -1):
item = user_list[index]
if item.startswith("刘"):
user_list.remove(item)
print(user_list)
转换
-
int、bool无法转换成列表
-
str
name = "武沛齐" data = list(name) # ["武","沛","齐"] print(data) -
元组 集合
v1 = (11,22,33,44) # 元组 vv1 = list(v1) # 列表 [11,22,33,44] v2 = {"alex","eric","dsb"} # 集合 vv2 = list(v2) # 列表 ["alex","eric","dsb"]
嵌套
data = [ "谢广坤",["海燕","赵本山"],True,[11,22,33,44],"宋小宝" ]
print( data[0] ) # "谢广坤"
print( data[1] ) # ["海燕","赵本山"]
print( data[0][2] ) # "坤"
print( data[1][-1] ) # "赵本山"
data.append(666)
print(data) # [ "谢广坤",["海燕","赵本山"],True,[11,22,33,44],"宋小宝",666]
data[1].append("谢大脚")
print(data) # [ "谢广坤",["海燕","赵本山","谢大脚"],True,[11,22,33,44],"宋小宝",666 ]
del data[-2]
print(data) # [ "谢广坤",["海燕","赵本山","谢大脚"],True,[11,22,33,44],666 ]
data[-2][1] = "alex"
print(data) # [ "谢广坤",["海燕","赵本山","谢大脚"],True,[11,"alex",33,44],666 ]
data[1][0:2] = [999,666]
print(data) # [ "谢广坤",[999,666,"谢大脚"],True,[11,"alex",33,44],666 ]
# 创建用户列表
# 用户列表应该长: [ ["alex","123"],["eric","666"] ]
# user_list = [["alex","123"],["eric","666"],]
# user_list.append(["alex","123"])
# user_list.append(["eric","666"])
user_list = []
while True:
user = input("请输入用户名:")
pwd = input("请输入密码:")
data = []
data.append(user)
data.append(pwd)
user_list.append(data)
等价于:
user_list = []
while True:
user = input("请输入用户名(Q退出):")
if user == "Q":
break
pwd = input("请输入密码:")
data = [user,pwd]
user_list.append(data)
print(user_list)
2.元组(tuple)
列表(list),是一个有序且可变的容器,在里面可以存放多个不同类型的元素。
元组(tuple),是一个有序且不可变的容器,在里面可以存放多个不同类型的元素。
如何体现不可变呢?
记住一句话:《"我儿子永远不能换成是别人,但我儿子可以长大"》
-
公共功能
-
相加·
-
相乘
-
获取长度
-
索引
-
切片
-
步长
```python
# 字符串 & 元组。
user_list = ("范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能")
data = user_list[::-1]
# 列表
user_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"]
data = user_list[::-1]
user_list.reverse()
print(user_list)
```
for循环
目前:只有 str、list、tuple 可以被for循环。 "xxx" [11,22,33] (111,22,33)
# len + range + for + 索引
user_list = ("范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能")
for index in range(len(user_list)):
item = user_list[index]
print(item)
嵌套
tu = ( '今天姐姐不在家', '姐夫和小姨子在客厅聊天', ('姐夫问小姨子税后多少钱','小姨子低声说道说和姐夫还提钱') )
tu1 = tu[0]
tu2 = tu[1]
tu3 = tu[2][0]
tu4 = tu[2][1]
tu5 = tu[2][1][3]
print(tu1) # 今天姐姐不在家
print(tu2) # 姐夫和小姨子在客厅聊天
print(tu3) # 姐夫问小姨子税后多少钱
print(tu4) # 小姨子低声说道说和姐夫还提钱
data = ("123",666,[11,22,33], ("alex","李杰",[999,666,(5,6,7)]) )
# 1.将 “123” 替换成 9 报错
# 2.将 [11,22,33] 换成 "武沛齐" 报错
# 3.将 11 换成 99
data[2][0] = 99
print(data) # ("123",666,[99,22,33], ("alex","李杰",[999,666,(5,6,7)]) )
# 4.在列表 [11,22,33] 追加一个44
data[2].append(44)
print(data) # ("123",666,[11,22,33,44], ("alex","李杰",[999,666,(5,6,7)]) )
# 创建用户 5个
# user_list = [] # 用户信息
user_list = [ ("alex","132"),("admin","123"),("eric","123") ]
while True:
user = input("请输入用户名:")
if user == "Q":
brek
pwd = input("请输入密码:")
item = (user,pwd,)
user_list.append(item)
# 实现:用户登录案例
print("登录程序")
username = input("请输入用户名:")
password = input("请输入密码:")
is_success = False
for item in user_list:
# item = ("alex","132") ("admin","123") ("eric","123")
if username == item[0] and password == item[1]:
is_success = True
break
if is_success:
print("登录成功")
else:
print("登录失败")
day07 数据类型(下)
常见的数据类型:
- int,整数类型(整形)
- bool,布尔类型
- str,字符串类型
- list,列表类型
- tuple,元组类型
- dict,字典类型
- set,集合类型
- float,浮点类型(浮点型)
1.集合(set)
集合是一个 无序 、可变、不允许数据重复的容器。
v1 = []
v11 = list()#空列表
v2 = ()
v22 = tuple()#空元组
v3 = set()#空集合
v4 = {} # 空字典
v44 = dict()
独有功能
添加元素.add
data = {"刘嘉玲", '关之琳', "王祖贤"}
data.add("郑裕玲")
print(data)
data = set()
data.add("周杰伦")
data.add("林俊杰")
print(data)
删除元素.discard
```python
data = {"刘嘉玲", '关之琳', "王祖贤","张曼⽟", "李若彤"}
data.discard("关之琳")
print(data)
```
交集.intersection或&
```python
s1 = {"刘能", "赵四", "⽪⻓⼭"}
s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"}
s4 = s1.intersection(s2) # 取两个集合的交集
print(s4) # {"⽪⻓⼭"}
s3 = s1 & s2 # 取两个集合的交集
print(s3)
```
并集.union或|
```python
s1 = {"刘能", "赵四", "⽪⻓⼭"}
s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"}
s4 = s1.union(s2) # 取两个集合的并集 {"刘能", "赵四", "⽪⻓⼭","刘科⻓", "冯乡⻓", }
print(s4)
s3 = s1 | s2 # 取两个集合的并集
print(s3)
```
差集.difference或-
```python
s1 = {"刘能", "赵四", "⽪⻓⼭"}
s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"}
s4 = s1.difference(s2) # 差集,s1中有且s2中没有的值 {"刘能", "赵四"}
s6 = s2.difference(s1) # 差集,s2中有且s1中没有的值 {"刘科⻓", "冯乡⻓"}
s3 = s1 - s2 # 差集,s1中有且s2中没有的值
s5 = s2 - s1 # 差集,s2中有且s1中没有的值
print(s5,s6)
```
公共功能
减,计算差集-
```python
s1 = {"刘能", "赵四", "⽪⻓⼭"}
s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"}
s3 = s1 - s2
s4 = s2 - s1
print(s3)
print(s4)
```
&,计算交集
```python
s1 = {"刘能", "赵四", "⽪⻓⼭"}
s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"}
s3 = s1 & s2
print(s3)
```
|,计算并集
```python
s1 = {"刘能", "赵四", "⽪⻓⼭"}
s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"}
s3 = s1 | s2
print(s3)
```
长度
```python
v = {"刘能", "赵四", "尼古拉斯"}
data = len(v)
print(data)
```
for循环
```python
v = {"刘能", "赵四", "尼古拉斯"}
for item in v:
print(item)
```
转换
-
其他类型如果想要转换为集合类型,可以通过set进行转换,并且如果数据有重复自动剔除。
提示:int/list/tuple/dict都可以转换为集合。
v1 = "武沛齐" v2 = set(v1) print(v2) # {"武","沛","齐"}v1 = [11,22,33,11,3,99,22] v2 = set(v1) print(v2) # {11,22,33,3,99}v1 = (11,22,3,11) v2 = set(v1) print(v2) # {11,22,3}提示:这其实也是去重的一个手段。
data = {11,22,33,3,99} v1 = list(data) # [11,22,33,3,99] v2 = tuple(data) # (11,22,33,3,99)
其他
-
1.5.1 集合的存储原理

-
1.5.2 元素必须可哈希
因存储原理,集合的元素必须是可哈希的值,即:内部通过通过哈希函数把值转换成一个数字。
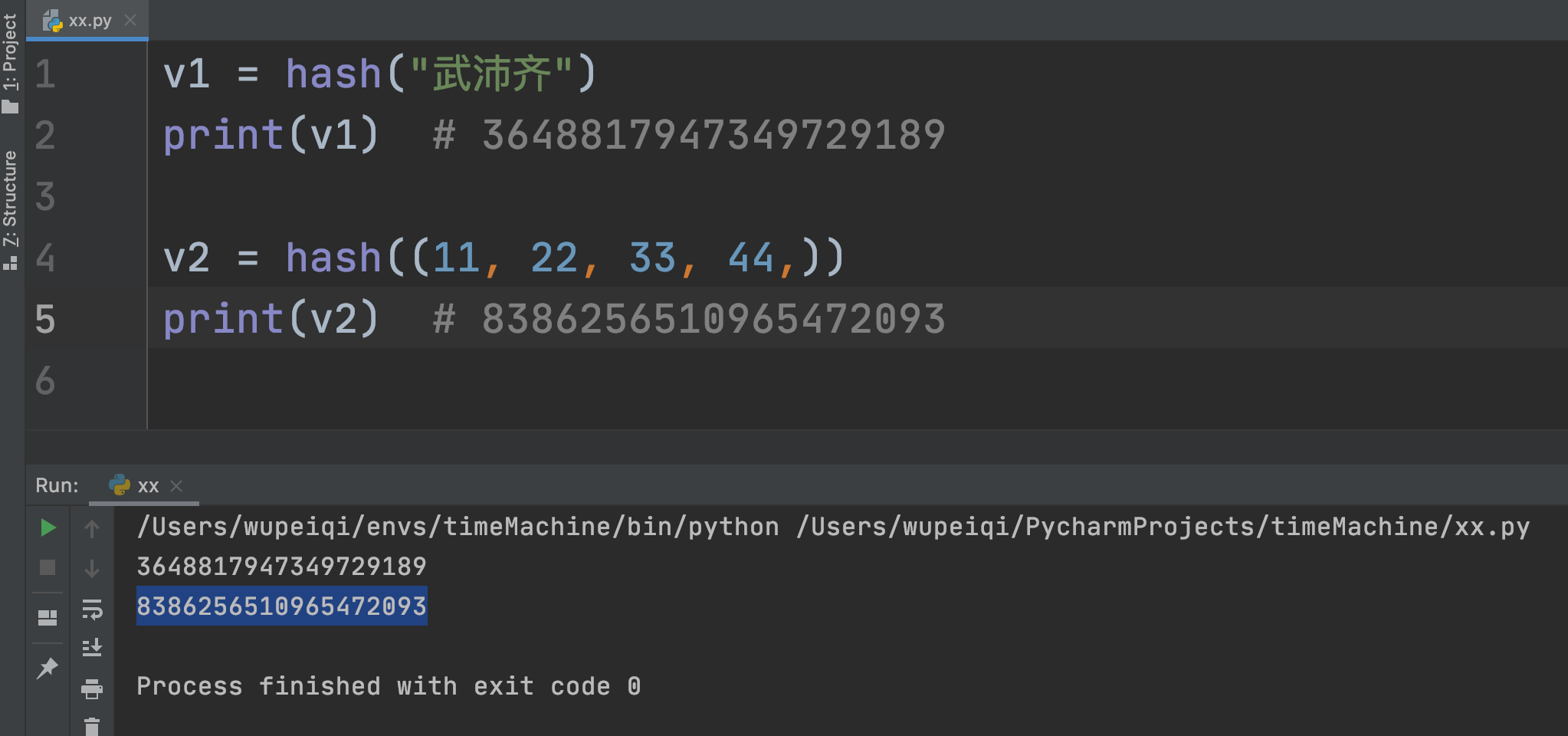
目前可哈希的数据类型:int、bool、str、tuple,而list、set是不可哈希的。
总结:集合的元素只能是 int、bool、str、tuple 。
-
转换成功
v1 = [11,22,33,11,3,99,22] v2 = set(v1) print(v2) # {11,22,33,3,99} -
转换失败
v1 = [11,22,["alex","eric"],33] v2 = set(v1) # 报错 print(v2)
-
-
1.5.3 查找速度特别快
因存储原理特殊,集合的查找效率非常高(数据量大了才明显)。
-
低
user_list = ["武沛齐","alex","李璐"] if "alex" in user_list: print("在") else: print("不在") user_tuple = ("武沛齐","alex","李璐") if "alex" in user_tuple: print("在") else: print("不在") -
效率高
user_set = {"武沛齐","alex","李璐"} if "alex" in user_set: print("在") else: print("不在")
-
-
1.5.4 对比和嵌套
类型 是否可变 是否有序 元素要求 是否可哈希 转换 定义空 list 是 是 无 否 list(其他) v=[]或v=list()tuple 否 是 无 是 tuple(其他) v=()或v=tuple()set 是 否 可哈希 否 set(其他) v=set()data_list = [ "alex", 11, (11, 22, 33, {"alex", "eric"}, 22), [11, 22, 33, 22], {11, 22, (True, ["中国", "北京"], "沙河"), 33} ]注意:由于True和False本质上存储的是 1 和 0 ,而集合又不允许重复,所以在整数 0、1和False、True出现在集合中会有如下现象:
v1 = {True, 1} print(v1) # {True} v2 = {1, True} print(v2) # {1} v3 = {0, False} print(v3) # {0} v4 = {False, 0} print(v4) # {False}
None类型
Python的数据类型中有一个特殊的值None,意味着这个值啥都不是 或 表示空。
-
目前所有转换为布尔值为False的值有:
0 "" [] or list() () or tuple() set() None
2.字典(dict)
字典是 无序、键不重复 且 元素只能是键值对的可变的 个 容器。
data = { "k1":1, "k2":2 }
-
容器
-
元素必须键值对
-
键不重复,重复则会被覆盖
data = { "k1":1, "k1":2 } print(data) # {"k1":2} -
无序(在Python3.6+字典就是有序了,之前的字典都是无序。)
data = { "k1":1, "k2":2 } print(data)字典中对键值得要求:
- 键:必须可哈希。 目前为止学到的可哈希的类型:int/bool/str/tuple;不可哈希的类型:list/set/dict。(集合)
- 值:任意类型。
-
当我们想要表示一组固定信息时,用字典可以更加的直观,例如:
# 用户列表 user_list = [ ("alex","123"), ("admin","666") ] ...# 用户列表 user_list = [ {"name":"alex","pwd":"123"}, {"name":"eric","pwd":"123"} ] -
独有功能
获取值.get()
# 案例:
user_list = {
"wupeiqi": "123",
"alex": "uk87",
}
username = input("请输入用户名:")
password = input("请输入密码:")
# None,用户名不存在
# 密码,接下来比较密码
pwd = user_list.get(username)
if pwd == None:
print("用户名不存在")
else:
if password == pwd:
print("登录成功")
else:
print("密码错误")
等价于:
if pwd:
if password == pwd:
print("登录成功")
else:
print("密码错误")
else:
print("用户名不存在")
抓取所有的键.keys()
info = {"age":12, "status":True, "name":"wupeiqi","email":"xx@live.com"}
data = info.keys()
print(data) # 输出:dict_keys(['age', 'status', 'name', 'email']) py2 -> ['age', 'status', 'name', 'email']
result = list(data)
print(result) # ['age', 'status', 'name', 'email']
注意:在Python2中 字典.keys()直接获取到的是列表,而Python3中返回的是高仿列表,这个高仿的列表可以被循环显示。
# for循环取每个键
info = {"age":12, "status":True, "name":"wupeiqi","email":"xx@live.com"}
for ele in info.keys():
print(ele)
# 是否存在
info = {"age":12, "status":True, "name":"wupeiqi","email":"xx@live.com"}
# info.keys() # dict_keys(['age', 'status', 'name', 'email'])
if "age" in info.keys():
print("age是字典的键")
else:
print("age不是")
抓取所有的值.values()
抓取所有的键值.items()
设置值.setdefault()
data = {
"name": "武沛齐",
"email": 'xxx@live.com'
}
data.setdefault("age", 18)
print(data) # {'name': '武沛齐', 'email': 'xxx@live.com', 'age': 18}
data.setdefault("name", "alex")
print(data) # {'name': '武沛齐', 'email': 'xxx@live.com', 'age': 18}
更新字典键值对.update()
info = {"age":12, "status":True}
info.update( {"age":14,"name":"武沛齐"} ) # info中没有的键直接添加;有的键则更新值
print(info) # 输出:{"age":14, "status":True,"name":"武沛齐"}
移除指定键值对.pop()
info = {"age":12, "status":True,"name":"武沛齐"}
data = info.pop("age")
print(info) # {"status":True,"name":"武沛齐"}
print(data) # 12
按照顺序移除(后进先出).popitem()
info = {"age":12, "status":True,"name":"武沛齐"}
data = info.popitem() # ("name","武沛齐" )
print(info) # {"age":12, "status":True}
print(data) # ("name","武沛齐")
-
py3.6后,popitem移除最后的值。
-
py3.6之前,popitem随机删除。
dic1={ 'name': ['alex', 2, 3, 5, 'wusir'], 'job': 'teacher', 'oldboy': {'alex': ['python1', 'python2', 100], '老男孩': 'linux'} } # 将oldboy对应的字典中的alex对应的列表中的python2删除 dic1['oldboy']['alex'].remove('python2') print(dic1) -
公共功能
并集(Python3.9新加入)()|()
v1 = {"k1": 1, "k2": 2}
v2 = {"k2": 22, "k3": 33}
v3 = v1 | v2
print(v3) # {'k1': 1, 'k2': 22, 'k3': 33}
长度len()
info = {"age":12, "status":True,"name":"武沛齐"}
data = len(info)
print(data) # 输出:3
是否包含
info = { "age":12, "status":True,"name":"武沛齐" }
v1 = "age" in info
print(v1)
v2 = "age" in info.keys()
print(v2)
if "age" in info:
pass
else:
pass
info = {"age":12, "status":True,"name":"武沛齐"}
v1 = "武佩奇" in info.values()
print(v1)
info = {"age": 12, "status": True, "name": "武沛齐"}
# 输出info.items()获取到的 dict_items([ ('age', 12), ('status', True), ('name', 'wupeiqi'), ('email', 'xx@live.com') ])
v1 = ("age", 12) in info.items()
print(v1)
索引(键)
字典不同于元组和列表,字典的索引是键,而列表和元组则是 0、1、2等数值 。
info = { "age":12, "status":True, "name":"武沛齐"}
print( info["age"] ) # 输出:12
print( info["name"] ) # 输出:武沛齐
print( info["status"] ) # 输出:True
print( info["xxxx"] ) # 报错,通过键为索引去获取之后时,键不存在会报错(以后项目开发时建议使用get方法根据键去获取值)
value = info.get("xxxxx") # None
print(value)
-
根据键 修改值 和 添加值 和 删除键值对
上述示例通过键可以找到字典中的值,通过键也可以对字典进行添加和更新操作info = {"age":12, "status":True,"name":"武沛齐"} info["gender"] = "男" print(info) # 输出: {"age":12, "status":True,"name":"武沛齐","gender":"男"}info = {"age":12, "status":True,"name":"武沛齐"} info["age"] = "18" print(info) # 输出: {"age":"18", "status":True,"name":"武沛齐"}info = {"age":12, "status":True,"name":"武沛齐"} del info["age"] # 删除info字典中键为age的那个键值对(键不存在则报错) print(info) # 输出: {"status":True,"name":"武沛齐"}info = {"age": 12, "status": True, "name": "武沛齐"} if "agea" in info: # del info["age"] data = info.pop("age") print(info)#{'status': True, 'name': '武沛齐'} print(data)#12 else: print("键不存在")
for循环
由于字典也属于是容器,内部可以包含多个键值对,可以通过循环对其中的:键、值、键值进行循环;
info = {"age":12, "status":True,"name":"武沛齐"}
for item in info:
print(item) # 所有键
info = {"age":12, "status":True,"name":"武沛齐"}
for item in info.key():
print(item)
info = {"age":12, "status":True,"name":"武沛齐"}
for item in info.values():
print(item)
info = {"age":12, "status":True,"name":"武沛齐"}
for key,value in info.items():
print(key,value)
转换
想要转换为字典.
v = dict( [ ("k1", "v1"), ["k2", "v2"] ] )
print(v) # { "k1":"v1", "k2":"v2" }
info = { "age":12, "status":True, "name":"武沛齐" }
v1 = list(info) # ["age","status","name"]
v2 = list(info.keys()) # ["age","status","name"]
v3 = list(info.values()) # [12,True,"武沛齐"]
v4 = list(info.items()) # [ ("age",12), ("status",True), ("name","武沛齐") ]
其他
存储原理

速度快
info = {
"alex":["肝胆","铁锤"],
"老男孩":["二蛋","缺货"]
}
for "alex" in info:
print("在")
info = {
"alex":["肝胆","铁锤"],
"老男孩":["二蛋","缺货"]
}
v1 = info["alex"]
v2 = info.get("alex")
嵌套
我们已学了很多数据类型,在涉及多种数据类型之间的嵌套时,需注意一下几点:
-
字典的键必须可哈希(list/set/dict不可哈希)。
info = { (11,22):123 } # 错误 info = { (11,[11,22,],22):"alex" } -
字典的值可以是任意类型。list/set/dict不可哈希
info = { "k1":{12,3,5}, "k2":{"xx":"x1"} } -
字典的键和集合的元素在遇到 布尔值 和 1、0 时,需注意重复的情况。
-
元组的元素不可以被替换。
dic = {
'name':'汪峰',
'age':48,
'wife':[ {'name':'国际章','age':38},{'name':'李杰','age':48} ],
'children':['第一个娃','第二个娃']
}
1. 获取汪峰的妻子名字
d1 = dic['wife'][0]['name']
print(d1)
2. 获取汪峰的孩子们
d2 = dic['children']
print(d2)
3. 获取汪峰的第一个孩子
d3 = dic['children'][0]
print(d3)
4. 汪峰的媳妇姓名变更为 章子怡
dic['wife'][0]['name] = "章子怡"
print(dic)
5. 汪峰再娶一任妻子
dic['wife'].append( {"name":"铁锤","age":19} )
print(dic)
6. 给汪峰添加一个爱好:吹牛逼
dic['hobby'] = "吹牛逼"
print(dic)
7. 删除汪峰的年龄
del dic['age']
或
dic.pop('age')
print(dic)
"""
3.浮点型(float)
浮点型,一般在开发中用于表示小数。
v1 = 3.14
v2 = 9.89
关于浮点型的其他知识点如下:
-
在类型转换时需要,在浮点型转换为整型时,会将小数部分去掉。
v1 = 3.14 data = int(v1) print(data) # 3 -
想要保留小数点后N位
v1 = 3.1415926 result = round(v1,3) print(result) # 3.142 -
浮点型的坑(所有语言中)
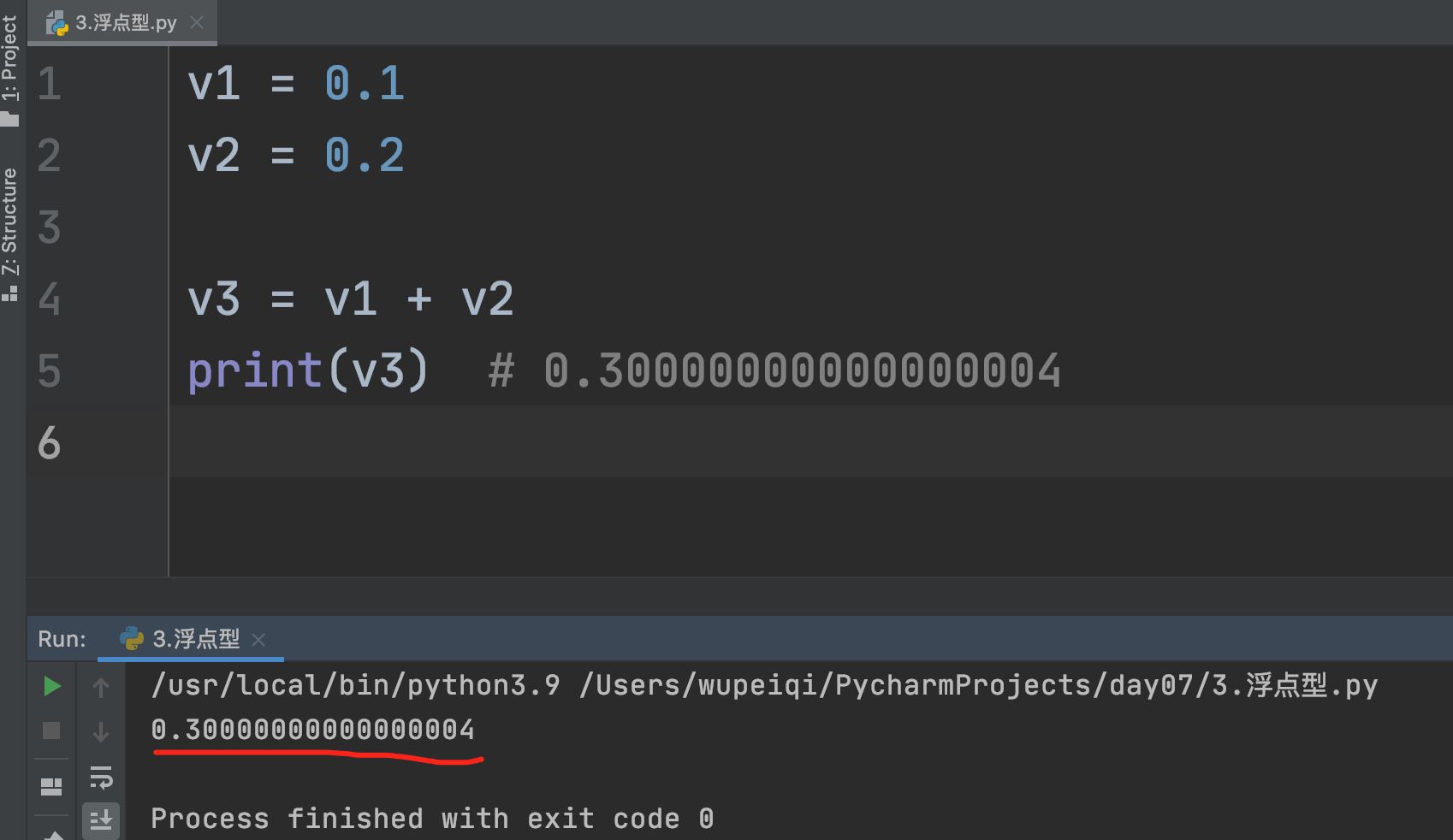
底层原理视频:https://www.bilibili.com/video/BV1354y1B7o1/
在项目中如果遇到精确的小数计算应该怎么办?
import decimal
v1 = decimal.Decimal("0.1")
v2 = decimal.Decimal("0.2")
v3 = v1 + v2
print(v3) # 0.3
##### 总结
1. 集合,是 无序、不重复、元素必须可哈希、可变的一个容器(子孙元素都必须是可哈希)。
2. 集合的查找速度比较快(底层是基于哈希进行存储)
3. 集合可以具有 交并差 的功能。
4. 字典是 无序、键不重复 且 元素只能是键值对的可变的一个容器(键子孙元素都必须是可哈希)。
5. py3.6+之后字典就变为有序了。
6. py3.9 新增了一个 `{} | {} `运算。
7. 字典的常见功能。
8. 在python2和python3中,字典的 keys() 、values()、items() 三个功能获取的数据类型不一样。
9. None是代表内存中的一个空值。
```python
0
""
[] or list()
() or tuple()
set()
None
{} or dict()
- 浮点型用于表示小数,但是由于其内部存储原理可能会引发数据存储不够精准。
day08 总结
str:
.startswith()
.endswith()
.upper()
.lower()
.strip()
.isdecimal()
.replace()
.split()
.center()
.zfill()
.encode()
.format()
.join()
list:
.append()
.extend()
.insert()
.remove()
.pop()
.clear()
.index()
.sort()
.reverse()
dict:
.get()
.keys()
.values()
.items()
.setdefault()
.update()
.pop()
.popitem()
1.1 todo
基于注释可以实现todo注释的效果,例如:

1.2 条件嵌套
以后写条件语句一定要想办法减少嵌套的层级(最好不要超过3层)。
1.3 简单逻辑先处理
示例1:
goods = [
{"name": "电脑", "price": 1999},
{"name": "鼠标", "price": 10},
{"name": "游艇", "price": 20},
{"name": "美女", "price": 998}
]
for index in range(len(goods)):
item = goods[index]
print(index + 1, item['name'], item['price'])
while True:
num = input("请输入要选择的商品序号(Q/q):") # "1"
if num.upper() == "Q":
break
if num.isdecimal():
num = int(num)
if 0 < num < 5:
target_index = num - 1
choice_item = goods[target_index]
print(choice_item["name"], choice_item['price'])
else:
print("序号范围选择错误")
else:
print("用户输入的序号格式错误")
示例2:
goods = [
{"name": "电脑", "price": 1999},
{"name": "鼠标", "price": 10},
{"name": "游艇", "price": 20},
{"name": "美女", "price": 998}
]
for index in range(len(goods)):
item = goods[index]
print(index + 1, item['name'], item['price'])
while True:
num = input("请输入要选择的商品序号(Q/q):") # "1"
if num.upper() == "Q":
break
if not num.isdecimal():
print("用输入的格式错误")
break
num = int(num)
if num > 4 or num < 0:
print("范围选择错误")
break
target_index = num - 1
choice_item = goods[target_index]
print(choice_item["name"], choice_item['price'])
1.4 循环
尽量少循环多干事,提高代码效率。
key_list = []
value_list = []
info = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
for key, value in info.items():
key_list.append(key)
value_list.append(value)
info = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
key_list = list(info.keys())
value_list = list(info.values())
2.知识补充
2.1 is 比较
is 和 ==的区别是什么?
==,用于比较两个值是否相等。- is,用于表示内存地址是否一致。
# 示例1
v1 = []
v2 = []
print( v1 == v2 ) # True,两个值相当
print( v1 is v2 ) # False,不属于同一块内存。
# 示例2
v1 = []
v2 = v1
print( v1 == v2 ) # True,两个值相当
print( v1 is v2 ) # True,属于同一块内存。
# 示例3
v1 = None
v2 = None
print(v1 == v2) # True,两个值相当
print(v1 is v2) # True,属于同一块内存。
2.2 位运算
计算机底层本质上都是二进制,我们平时在计算机中做的很多操作底层都会转换为二进制的操作,位运算就是对二进制的操作。
-
&,与(都为1)a = 60 # 60 = 0011 1100 b = 13 # 13 = 0000 1101 c = a & b # 12 = 0000 1100 -
|,或(只要有一个为1)a = 60 # 60 = 0011 1100 b = 13 # 13 = 0000 1101 c = a | b # 61 = 0011 1101 -
^,异或(值不同)a = 60 # 60 = 0011 1100 b = 13 # 13 = 0000 1101 c = a ^ b # 49 = 0011 0001 -
~,取反a = 60 # 60 = 0011 1100 c = ~a; # -61 = 1100 0011 -
<<,左移动a = 60 # 60 = 0011 1100 c = a << 2; # 240 = 1111 0000 -
>>,右移动a = 60 # 60 = 0011 1101 c = a >> 2; # 15 = 0000 1111
平时在开发中,二进制的位运算几乎很好少使用,在计算机底层 或 网络协议底层用的会比较多,例如:
-
计算 2**n
2**0 1 << 0 1 1 2**1 1 << 1 10 2 2**2 1 << 2 100 4 2**3 1 << 3 1000 8 ... -
计算一个数的一半【面试题】
v1 = 10 >> 1 print(v1) # 值为5 v2 = 20 >> 1 print(v2) # 值为 10 -
网络传输数据,文件太大还未传完(websocket源码为例)。
第1个字节 第2个字节 ... 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-------+-+-------------+-------------------------------+ |F|R|R|R| opcode|M| Payload len | Extended payload length | |I|S|S|S| (4) |A| (7) | (16/64) | |N|V|V|V| |S| | (if payload len==126/127) | | |1|2|3| |K| | | +-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - + FIN位置是0,表示这是一部分数据,后续还有数据。 FIN位置是1,表示这是最后数据,已发送完毕。# 例如:接收到的第一个字节的值为245(11110101),让v的二进制和 1000 0000 做 & 与运算。 v = 245 # 245 11110101 # 128 10000000 10000000 data = v & 128 if data == 0: print("还有数据") else: print("已完毕")
3.阶段总结
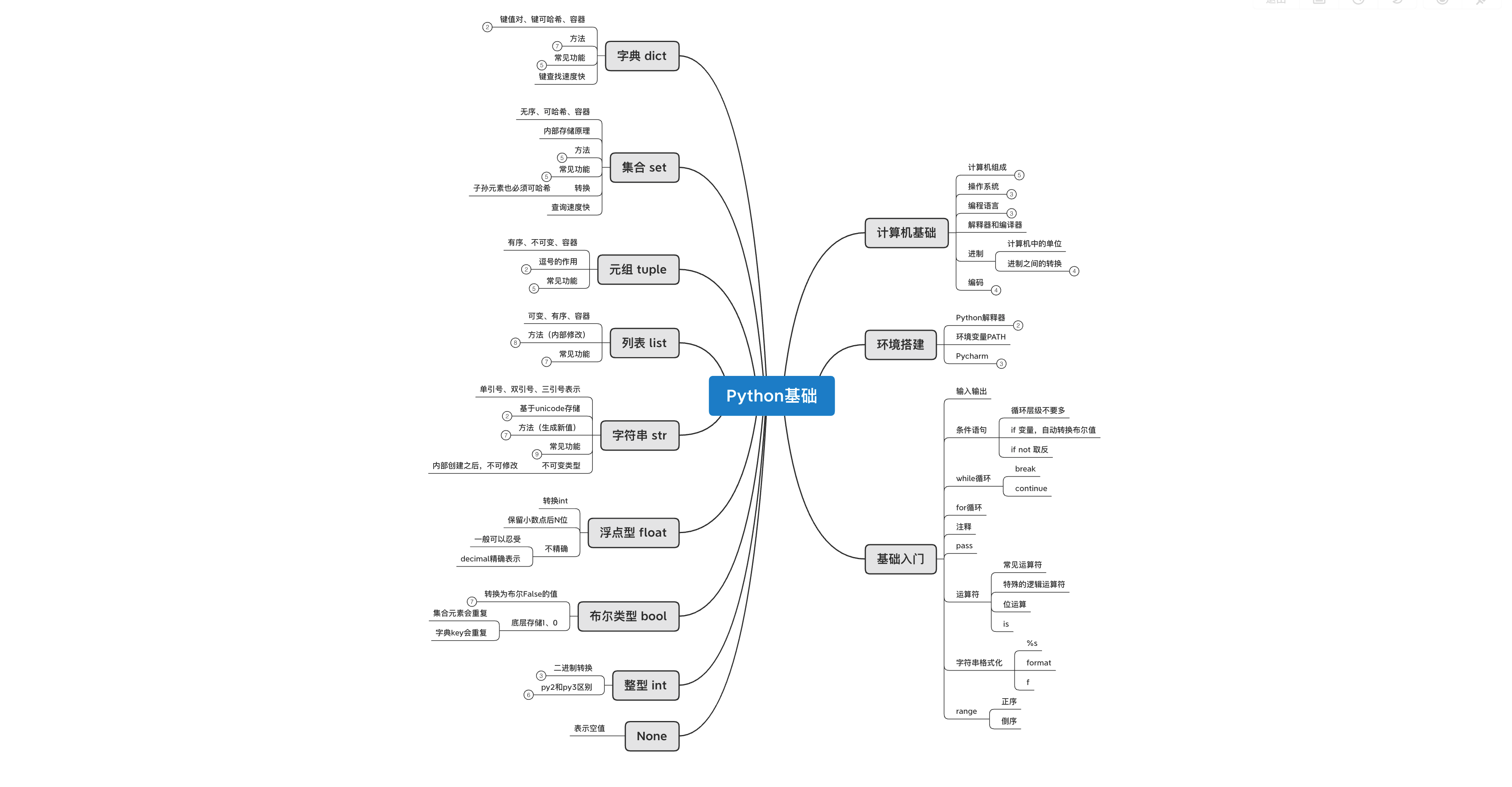
可使用思维导图( xmind 软件),对阶段知识点的内容进行梳理,将知识梗概和重点写出来,也便于以后的回顾和复习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号