

PyTorch常用代码
 PyTorch常用代码汇总
PyTorch常用代码汇总
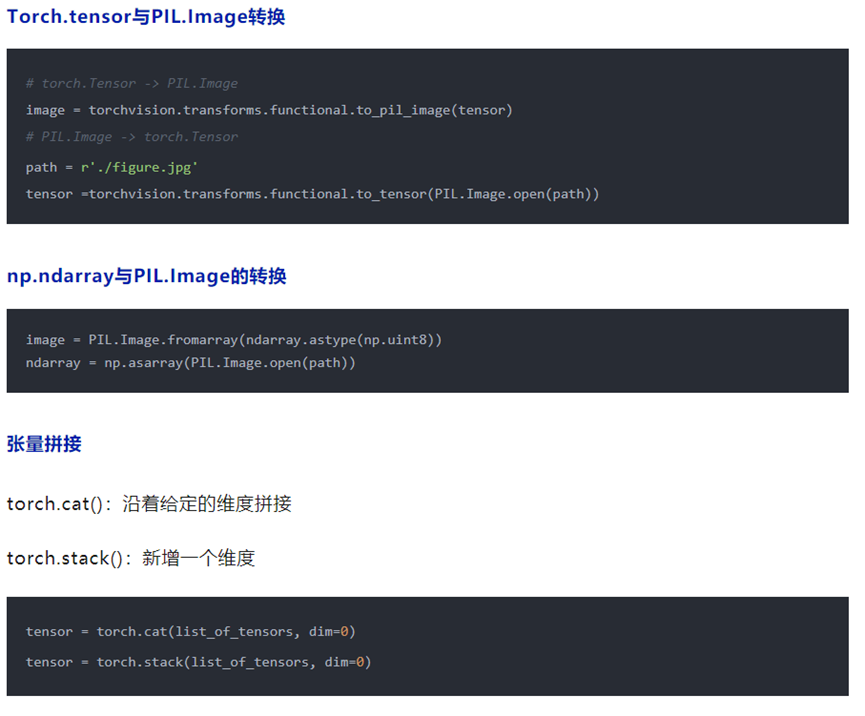
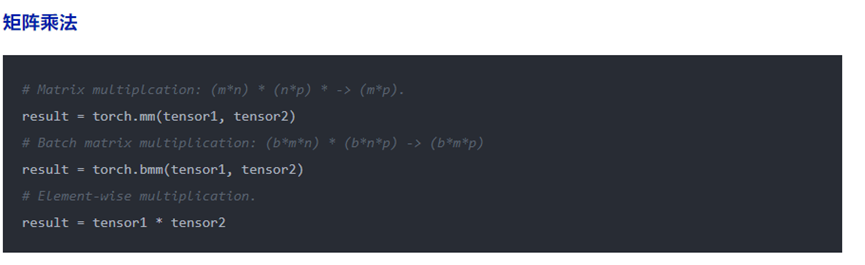
张量处理

将整数标签转为one-hot编码#
# pytorch 的标记默认从 0 开始
tensor = torch.tensor([0, 2, 1, 3])
N = tensor.size(0)
num_classes = 4
one_hot = torch.zeros(N, num_classes).long() one_hot.scatter_(dim=1,index=torch.unsqueeze(tensor,dim=1),src=torch.ones(N,num_classes).long())
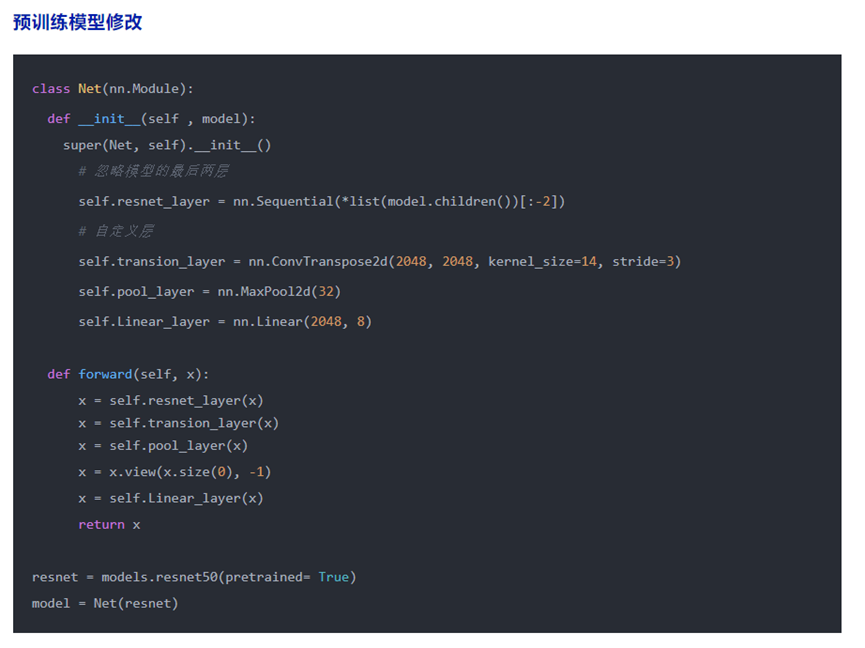
模型定义#
两层卷积网络的示例#
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(16), nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(32), nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*32,
num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out) return out
model = ConvNet(num_classes).to(device)


数据处理#
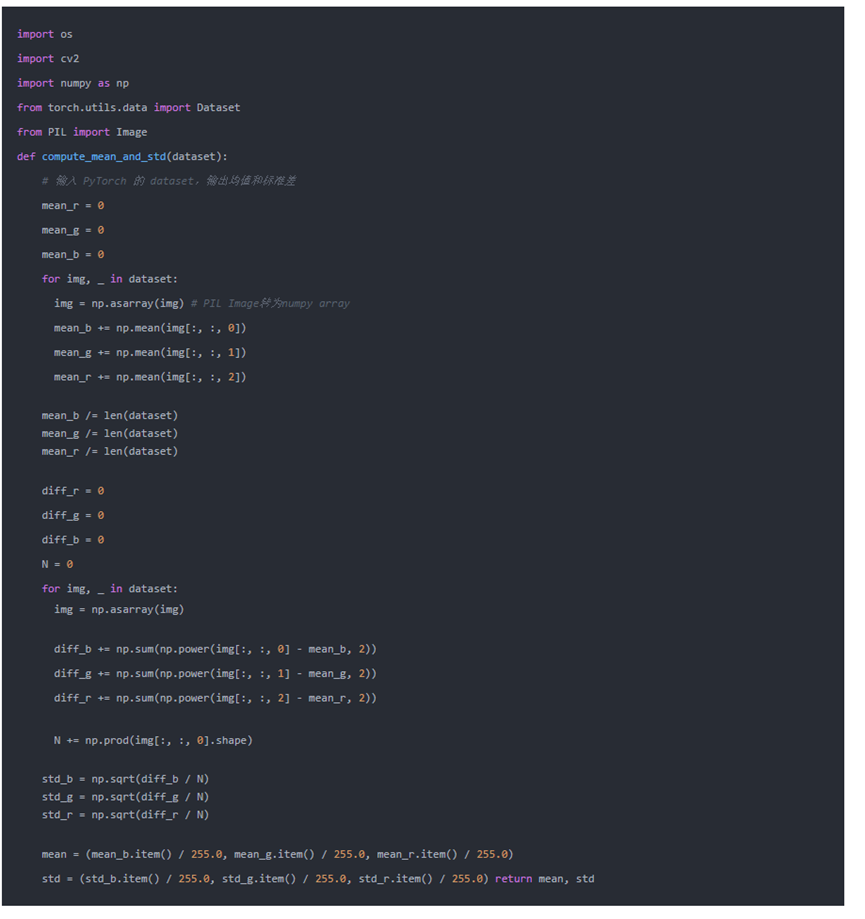
计算数据集的均值和标准差#
常用训练和验证数据预处理#
其中,ToTensor 操作会将 PIL.Image 或形状为 H×W×D,数值范围为 [0, 255] 的 np.ndarray 转换为形状为 D×H×W,数值范围为 [0.0, 1.0] 的 torch.Tensor。
train_transform
=
torchvision.transforms.Compose([torchvision.transforms.RandomResizedCrop(size=224,
scale=(0.08, 1.0)),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(), torchvision.transforms.Normalize(mean=(0.485,
0.456, 0.406), std=(0.229, 0.224, 0.225)), ])
val_transform =
torchvision.transforms.Compose([torchvision.transforms.Resize(256),
torchvision.transforms.CenterCrop(224), torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224,
0.225)), ])
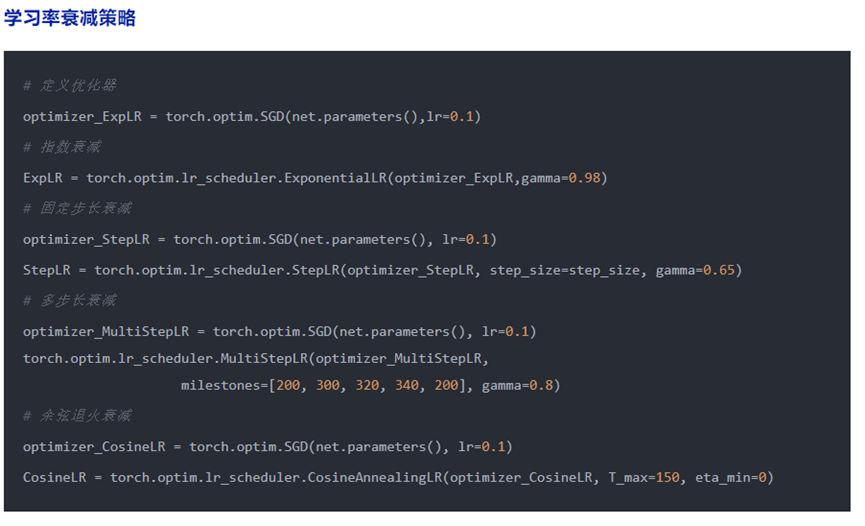
保存与加载断点#
#
加载模型
if resume:
model_path = os.path.join('model',
'best_checkpoint.pth.tar')
assert os.path.isfile(model_path)
checkpoint = torch.load(model_path)
best_acc = checkpoint['best_acc']
start_epoch = checkpoint['epoch'] model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
print('Load checkpoint at epoch
{}.'.format(start_epoch))
print('Best accuracy so far
{}.'.format(best_acc))
# 训练模型
for epoch in range(start_epoch, num_epochs):
...
# 测试模型
...
# 保存checkpoint
is_best = current_acc > best_acc
best_acc = max(current_acc, best_acc)
checkpoint = { 'best_acc': best_acc,
'epoch': epoch + 1, 'model':
model.state_dict(), 'optimizer': optimizer.state_dict(), }
model_path = os.path.join('model',
'checkpoint.pth.tar') best_model_path
= os.path.join('model', 'best_checkpoint.pth.tar') torch.save(checkpoint, model_path)
if is_best: shutil.copy(model_path,
best_model_path)
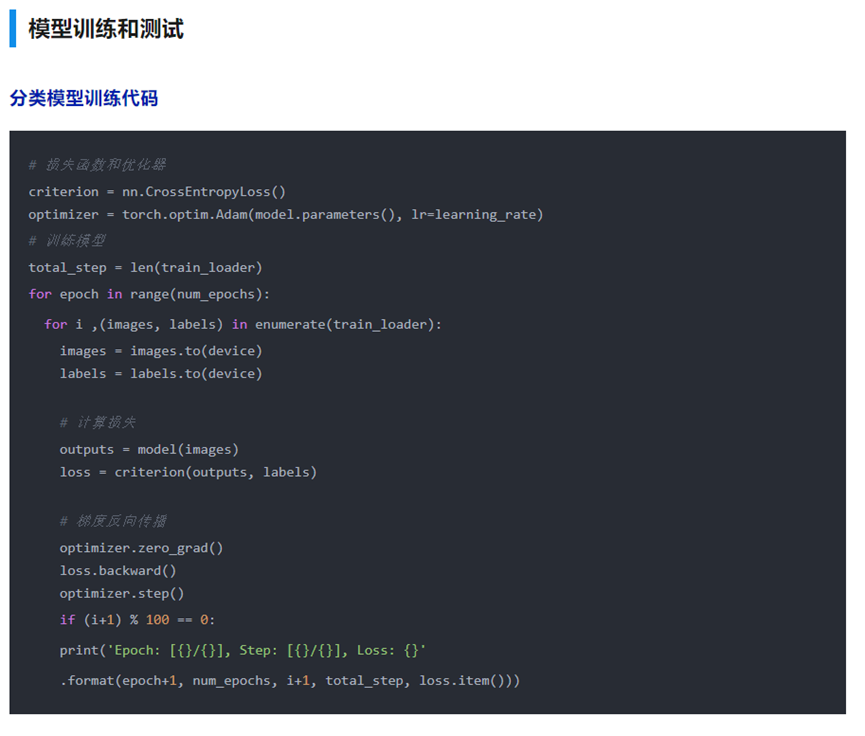
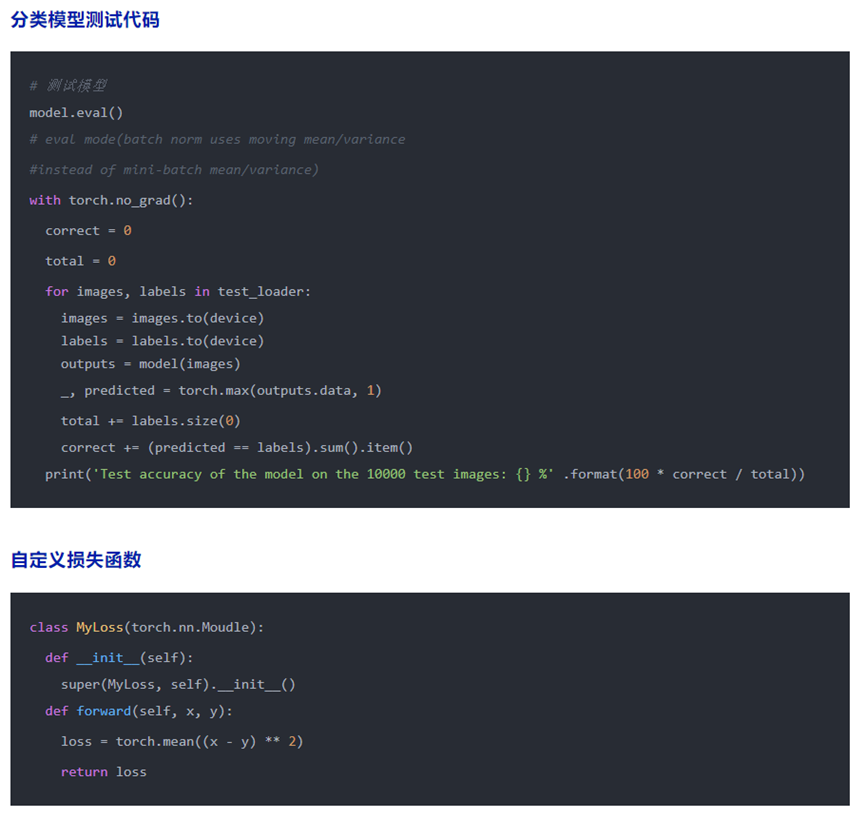
注意事项
- model(x) 定义好后,用 model.train() 和 model.eval() 切换模型状态。
- 使用with torch.no_grad() 包含无需计算梯度的代码块
- model.eval()与torch.no_grad的区别:前者是将模型切换为测试态,例如BN和Dropout在训练和测试阶段使用不同的计算方法;后者是关闭张量的自动求导机制,减少存储和加速计算。
- torch.nn.CrossEntropyLoss 等价于 torch.nn.functional.log_softmax + torch.nn.NLLLoss。
- ReLU可使用inplace操作减少显存消耗。
- 使用半精度浮点数 half() 可以节省计算资源同时提升模型计算速度,但需要小心数值精度过低带来的稳定性问题。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律