怎么训练出一个NB的Prophet模型
上篇《神器の争》主要是介绍Prophet的特点以及prophet入门的一些注意事项,但离真正的实际运用还有段距离。本篇主要讲解实际运用中Prophet调参的主要步骤以及一些本人实际经验。
一 参数理解篇
class Prophet(object):
def __init__(
self,
growth='linear',
changepoints=None,
n_changepoints=25,
changepoint_range=0.8,
yearly_seasonality='auto',
weekly_seasonality='auto',
daily_seasonality='auto',
holidays=None,
seasonality_mode='additive',
seasonality_prior_scale=10.0,
holidays_prior_scale=10.0,
changepoint_prior_scale=0.05,
mcmc_samples=0,
interval_width=0.80,
uncertainty_samples=1000,
stan_backend=None
):
1.1 趋势参数
| 参数 | 描述 |
|---|---|
| growth | growth是指模型的趋势函数,目前取值有2种,linear和logistic |
| changepoints | Changepoint是指一个特殊的日期,在这个日期,模型的趋势将发生改变。而changepoints是指潜在changepoint的所有日期,如果不指明则模型将自动识别。 |
| n_changepoints | 最大的Changepoint的数量。如果changepoints不为None,则本参数不生效。 |
| changepoint_range | 是指changepoint在历史数据中出现的时间范围,与n_changeponits配合使用,changepoint_range决定了changepoint能出现在离当前时间最近的时间点,changepont_range越大,changepoint可以出现的距离现在越近。当指定changepoints时,本参数不生效 |
| changepoint_prior_scale | 设定自动突变点选择的灵活性,值越大越容易出现changepoint |
1.1.1 growth
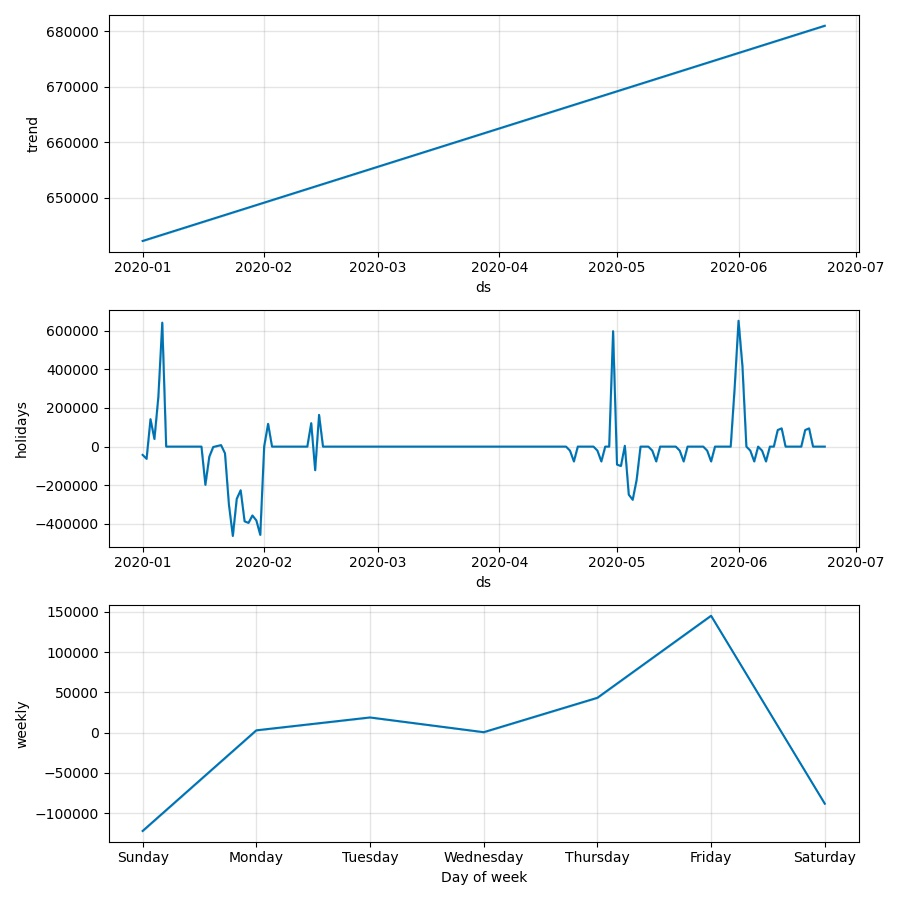
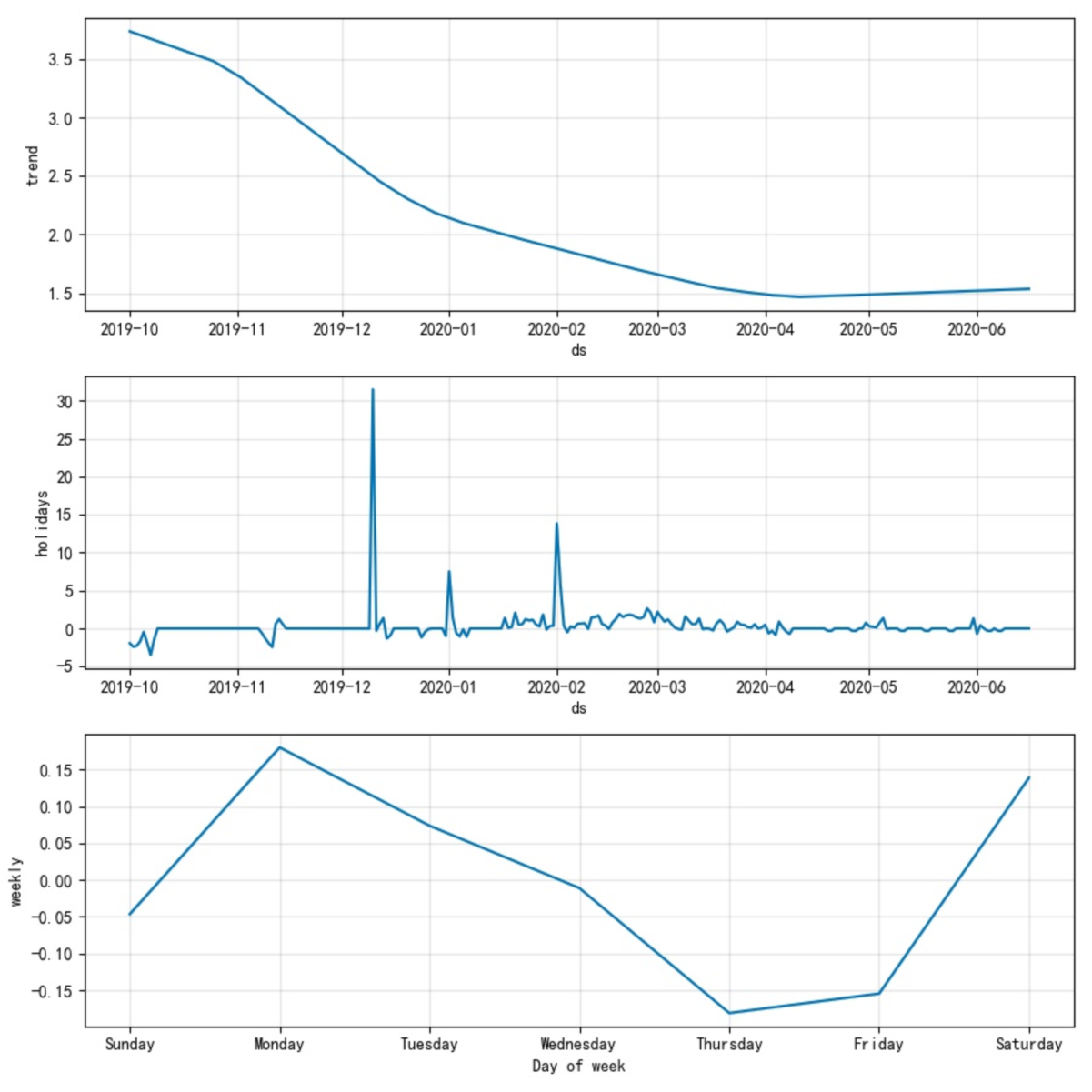
growth是指模型的趋势函数,目前取值有2种,linear和logistic,分别如图1-1及图1-2所示。趋势会在changepoint处出现突变点。
 |
|---|
| 图1-1 linear趋势 |
 |
| 图1-2 logistic趋势 |
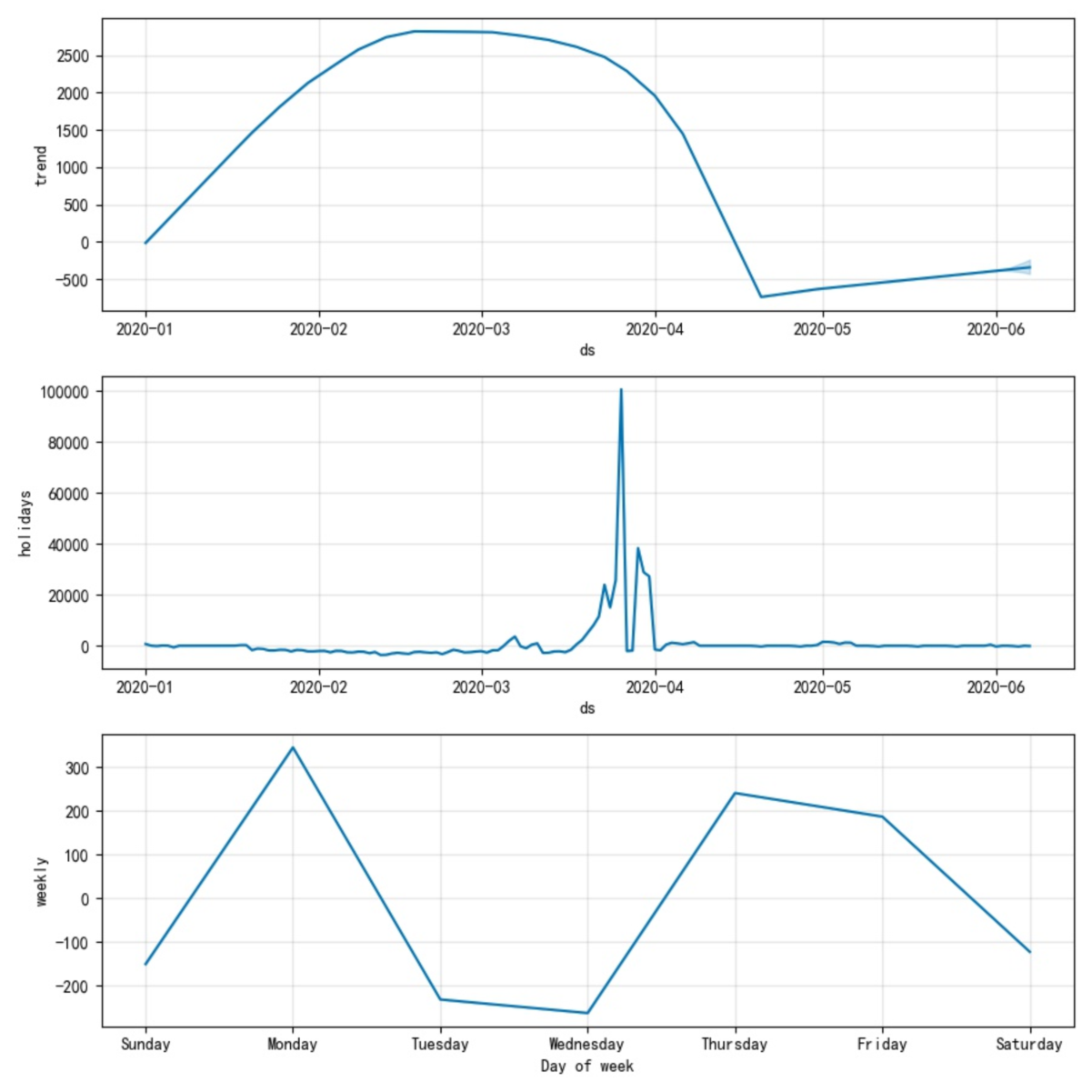
细心的同学可能会问,可不可能出现同一个模型既有linear趋势,又有logistic趋势,就像下面这样:
 |
|---|
| 图1-3 |
在这里福布湿要给大家纠正下这个错觉,请大家记住Prophet的趋势模型要么是linear要么是logistic。而上图之所以像是两种的叠加,是因为prophet的设计师为了让趋势函数可微(连续,就理解成连续吧)做了平滑处理,
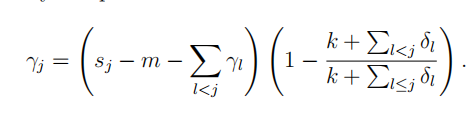
上面这货就是论文中做平滑处理的公式。
1.1.2 Changepoints
Changeponits形状如[‘2013-01-01’,’2013-09-01’,’2017-02-5’],是changepoint的列表。
Changepoints是一个非常重要的参数,但用户在决定设置此值时必须要注意,这个参数设置之后模型将不会自动寻找changepoints(同时n_changepoints和changepoint_range均不会生效),这就意味着手动设置的changeponits必须准确且完整,否则福布湿不建议大家设置此项。
1.1.3 n_changeponits、changepoint_range
这2个参数是模型自动识别changepoint时需要的,n_changepoints限制了changepoint的最大数量,changepoint_range限制了changepoint在历史数据中出现的时间范围。例如图1-1中changepoint_range福布湿设置的是0.5,而图1-3中福布湿设置的是0.8,如果福布湿把图1-3中的changepoint_range设置为0.2,那么所有的changpoint均只能出现在2020-01-01至2020-02-01的范围内。
1.2 周期性性参数
| 参数 | 描述 |
|---|---|
| yearly_seasonality | 年周期性,True为启用,false为关闭,如果设置为自然数n,则n代表傅里叶级数的项数,项数越多,模型将拟合的越好,但是也越容易过拟合,因此论文中推荐年周期性的项数取10,而周的(weekly_seasonality)取3。 一般来讲当历史数据大于1年时模型默认为True(项数默认为10),否则默认为False |
| weekly_seasonality | 周周期性,True为启用,false为关闭,如果设置为自然数n,则n代表傅里叶级数的项数,项数越多,模型将拟合的越好,但是也越容易过拟合,因此论文中推荐取3。 一般来讲当历史数据大于1周时模型默认为True(项数默认为3),否则默认为False |
| daily_seasonality | 天周期性,当时间序列为小时级别序列时才会开启。 |
| seasonality_mode | 季节模型方式,'additive'(加法模型) (默认) 或者 'multiplicative'(乘法模型) |
| seasonality_prior_scale | 改变周期性影响因素的强度,值越大,周期性因素在预测值中占比越大 |
周期性参数设置相对较为固化,除了seasonality_mode和seasonality_prior_scale可能需要手动调整外其余各项一般情况下保持为默认值即可(当然具体问题具体分析,傅里叶项数在某些特殊情况下也可能需要调整)。
傅里叶级数跟泰勒展开式一样,都是用特定的级数形式拟合某个函数,傅里叶级数是专门为周期性函数设计的,也就是说只要某个函数是周期函数就能使用傅里叶级数拟合。有兴趣的同学可以看下知乎上的这个文章:
seasonality_mode的季节模型类型如果大家不深究按字面意思理解即可。
1.3 节假日参数
| 参数 | 描述 |
|---|---|
| holidays | 节假日或特殊日期,商业活动中活动日期是这类日期的典型代表 |
| holiday_prior_scale | 改变假日模型的强度 |
1.3.1 holidays
Holidays参数是一个pd.DataFrame:
| holiday | ds | upper_window | lower_window |
|---|---|---|---|
| 元旦 | 2019/1/1 | 1 | -1 |
| 元旦 | 2018/1/1 | 1 | -1 |
holiday是特殊日期的时间,ds是时间(pd.Timestamp类型),upper_window和lower_window分别指特殊日期的影响上下限。
在Prophet中,认为holiday服从正态分布,正态分布的轴为ds。因此,prophet在预测节假日时会以正态分布作为来估计预测值,但这个过程只是一个先验估计的过程,如果模型后面发现这个holiday期间内不服从正态分布,那么模型将生硬的拟合该节假日。如图1-4中所示,大家可以自行体会。
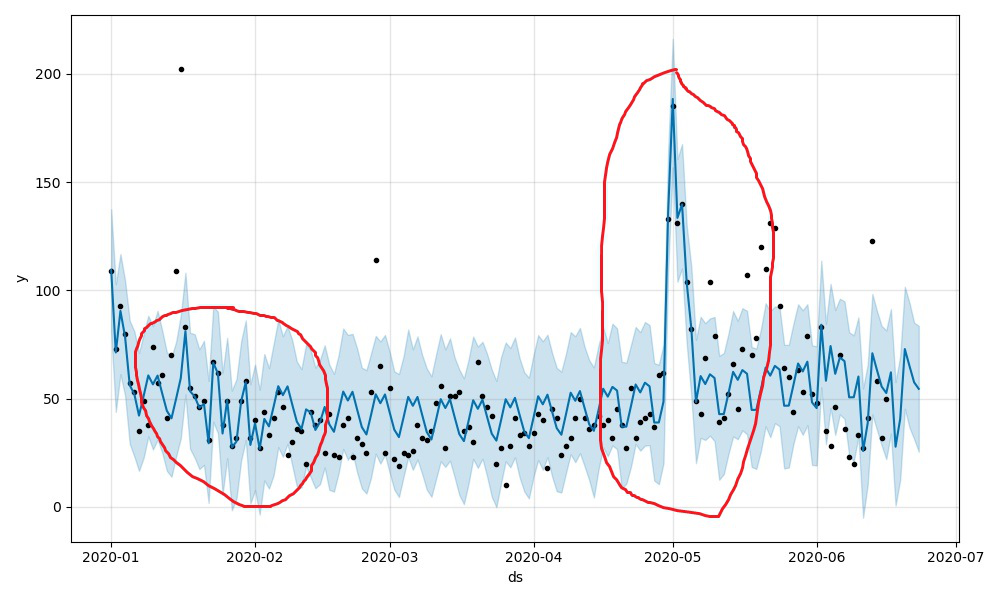 |
|---|
| 图1-4 |
holidays这个参数非常重要,对整个模型的影响极大,因此大家在构建这个参数时一定要给予相当的重视。
holidays在模型中是一个广义的概念,不仅指节假日,也指活动日期,特殊事件日期等,因此大家在设置holidays时一定要确保完整,同时对于upper_window和lower_window的设置也应符合实际情况。
值得注意的是holidays的数量应尽量少,过多的holidays会对模型的过拟合现象加重,如果holidays的数量超过了整体数据的30%,工程师就应该考虑是否去掉一些影响较小的节假日。
1.4 其他参数
| 参数 | 描述 |
|---|---|
| mcmc_samples | 概率估计方式。如果为0将会采用最大后验概率估计(MAP),如果为n(n>0)将会以n个马尔科夫采样样本做全贝叶斯推断。 估计有同学有疑问,这些个概率估计的东西跟本模型有毛关系?大家仔细看下图1-4中的蓝色曲线和淡蓝色区域,这其实就是预测结果,而采样估计就是用来给出淡蓝色区域的(uncertainty intervals),大家可以理解为置信区间或者是预测结果的上下限(虽然外国佬叫它‘不确定区间’)。 当mcmc_samples=0的时候,只有趋势因素会存在这种估计,当mcmc_samples>0时,周期性因素才会存在这种估计。 |
| interval_width | uncertainty intervals 的宽度,是一个浮点数,越大允许的uncertainty intervals范围越大 |
| uncertainty_samples | 用来估计uncertainty intervals的采样次数,如果设置为0或者False,就不会进行uncertainty intervals的估计,从而加快模型的训练速度。 |
| stan_backend | CMDSTANPY或者PYSTAN。一般PYSTAN在linux上使用,cmdstanpy在微软操作系统上使用。提示下在微软操作系统上使用的同学,最好不要开启马尔科夫采样(就是不要把mcmc_samples设成大于0),因为微软操作系统上马尔科夫采样非常慢。 |
二 参数调优实战
目前实际生产中,时序模型的训练往往是数量惊人,因此如果依靠以往的指标和经验调参以不大可行,所以只能采用机器寻参的方式。福布湿在这里给大家介绍下常用的网格寻参。
在调参之前,最重要的是要确定好模型的评价指标。Prophet中内置的评价指标有传统的mse、rmse、mae、mape、coverage。但这些不一定满足在座各位的胃口,比如福布湿在部分模型中就使用了相对误差的0.8分位数作为评价指标。
废话不多说,直接上代码。
class ProphetTrain(ABC):
def __init__(self, name=None):
self.name = name
self.data: pd.DataFrame = None
self.params = {'holidays': holidays}
self.mape = np.inf
self.model = None
self.grid_search_params_path = None
self.predict_freq_num = 7
self.freq = 'd'
@abstractmethod
def _load_data(self):
"""
加载训练及测试数据
:param rule: DataFrame.resample 中的rule
:return: 训练及测试数据集,类型是pd.DataFrame
"""
pass
@property
def data_size(self):
if self.data is None:
self.data = self._load_data()
return self.data.shape[0] if self.data is not None else 0
def _cv_run(self):
if self.data_size < 14:
raise Exception("数据量不足,请保证数据航速大于14条")
self.model = Prophet(**self.params)
self.model.fit(self.data)
cv_result = cross_validation(self.model, f'{self.predict_freq_num}{self.freq}',
f'{self.predict_freq_num}{self.freq}')
return performance_metrics(cv_result, metrics=['mape'])['mape'][0]
def run(self, show: int = 0, retrain=False):
"""
根据当前参数生成模型
:param retrain: 是否根据当前参数重新生成模型
:param show:
0: 不保存图片及预测结果 也 不展示图片
1: 展示图片
2: 保存图片及预测结果
3: 保存图片及预测结果 也 展示图片
:return:
"""
if self.data_size < 14:
raise Exception("数据量不足,请保证数据航速大于14条")
if retrain or self.model is None:
self.model = Prophet(**self.params)
self.model.fit(self.data)
future = self.model.make_future_dataframe(freq=self.freq,
periods=self.predict_freq_num) # 建立数据预测框架,数据粒度为天,预测步长为一年
forecast = self.model.predict(future)
if show & 0b01:
self.model.plot(forecast).show() # 绘制预测效果图
self.model.plot_components(forecast).show() # 绘制成分趋势图
if show & 0b10:
y = forecast[['ds', 'yhat_lower', 'yhat_upper', 'yhat']].iloc[-self.predict_freq_num:]
y.to_csv(f'csv/{self.name}.csv', index=False)
self.model.plot(forecast).savefig(f"img/{self.name}-scatter.png") # 绘制预测效果图
self.model.plot_components(forecast).savefig(f"img/{self.name}-trend.png") # 绘制成分趋势图
mape_score = np.abs(1 - forecast['yhat'].iloc[:self.data.shape[0]] / self.data['y'].values)
return np.quantile(mape_score, 0.8)
@property
def get_predict_df(self):
future = self.model.make_future_dataframe(freq=self.freq,
periods=self.predict_freq_num) # 建立数据预测框架,数据粒度为天,预测步长为一年
forecast = self.model.predict(future)
return forecast
def grid_search(self, use_cv=True, save_result=True):
"""
结合cv进行网格寻参,cv方式网格寻参很慢,一般建议先使用非网格方式,待参数调整完毕再使用cv验证。
:param save_result:
:return:
"""
changepoint_range = [i / 10 for i in range(3, 10)]
seasonality_mode = ['additive', 'multiplicative']
seasonality_prior_scale = [0.05, 0.1, 0.5, 1, 5, 10, 15]
holidays_prior_scale = [0.05, 0.1, 0.5, 1, 5, 10, 15]
for sm in seasonality_mode:
for cp in changepoint_range:
for sp in seasonality_prior_scale:
for hp in holidays_prior_scale:
params = {
"seasonality_mode": sm,
"changepoint_range": cp,
"seasonality_prior_scale": sp,
"holidays_prior_scale": hp,
"holidays": holidays
}
score = self._cv_run() if use_cv else self.run()
if self.mape > score:
self.mape = score
self.params = params
if save_result:
future = self.model.make_future_dataframe(freq=self.freq,periods=self.predict_freq_num)
forecast = self.model.predict(future)
forecast[['ds', 'yhat_lower', 'yhat_upper', 'yhat']].iloc[-self.predict_freq_num:].to_csv(
f'csv/{self.name}.csv', index=False)
self.model.plot(forecast).savefig(f"img/{self.name}-scatter.png") # 绘制预测效果图
self.model.plot_components(forecast).savefig(f"img/{self.name}-trend.png") # 绘制成分趋势图
self.save_model()
print(f'score:{self.mape}\nparams:{self.params}')
return self
def save_model(self):
with open(f'model/{self.name}.pkl', 'wb') as fp:
pickle.dump(self, fp)
@staticmethod
def load_model(name):
with open(f'model/{name}.pkl', 'rb') as fp:
return pickle.load(fp)
在这里主要给大家介绍2点:
-
网格寻参很耗CPU,对于CPU性能不好的同学福布湿只能给你一个大大的拥抱。(当然如果使用2分法一组组参数调,麻烦是麻烦了点,但是速度肯定快不少)。
-
网格寻参的参数可以是所有的参数,不仅仅是福布湿给出的这几个
changepoint_range = [i / 10 for i in range(3, 10)]
seasonality_mode = ['additive', 'multiplicative']
seasonality_prior_scale = [0.05, 0.1, 0.5, 1, 5, 10, 15]
holidays_prior_scale = [0.05, 0.1, 0.5, 1, 5, 10, 15]
而这些参数的取值范围则需要同学们根据每个参数固有的取值范围和时间序列的特点自己研究决定。
- Prophet自带的交叉验证(cross_validation)函数
def cross_validation(model, horizon, period=None, initial=None):
model: model是已经训练的Prophet模型
horizon: horizon是每次预测所使用的数据的时间长度,比如‘30d’(30天)
period:period是触发预测动作的时间周期。如果设置为‘7d’,01-07、01-14、01-21等等,而这些预测的数据为前面定义的horizon。这个值的默认值为horizon*0.5
Initial:整个交叉验证的数据范围,结束点是昨天的点,开始点是(昨天-initial),initial的默认值是3*horizon。当然同学们也可根据实际情况手动设置,比如“110d”。
语言总是苍白的,那么福布湿就直接上图了。
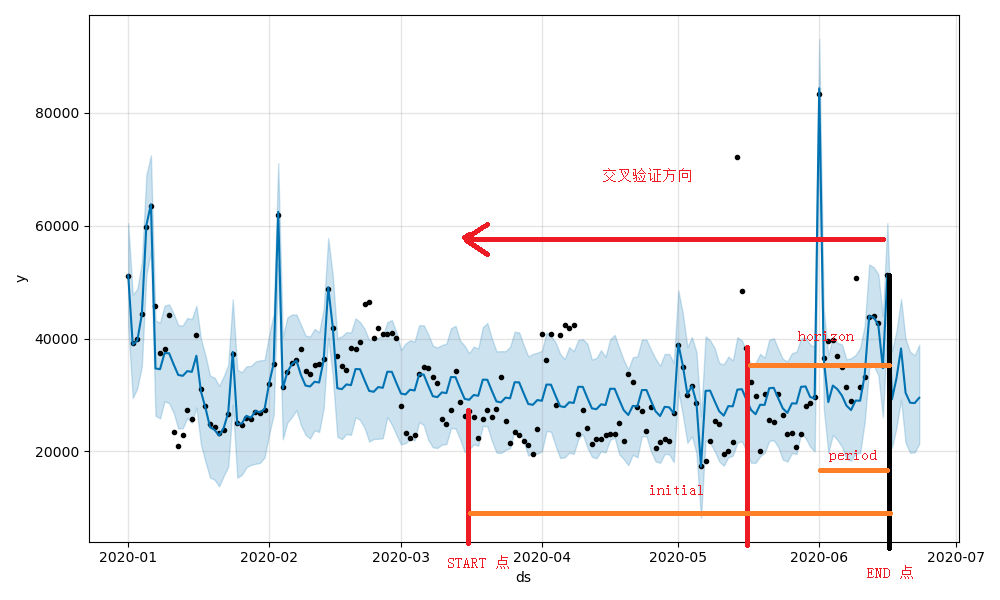 |
|---|
| 图1-5 |
图中的horizon为‘30d’,其他的均为默认值(period=‘15d’,initial=‘90d’)。
三 结尾
任何一种算法不可能适合所有情况,所有大家要做的是理解算法原理,针对实际情况优化算法。比如福布湿在研究双十一这个节假日的时候发现实际的分布并不是对称的,而正态分布是一个对称的分布,明显不符合实际情况,因此福布湿将这个先验分布改为了F分布,就这一个小小的改动就让模型的准确率上升了大约5%左右。因此如果想训练出一个好的模型,数据和调参很重要,但更重要的对算法原理的充分理解并根据实际情况改进算法,从而让模型效果达到一个新的台阶。
参考文献:
【1】Prophet官方文档:https://facebook.github.io/prophet/
【2】Prophet论文:https://peerj.com/preprints/3190/
【3】Prophet-github:https://github.com/facebook/prophet

 浙公网安备 33010602011771号
浙公网安备 33010602011771号