

统一数据管理中心是SPA复杂数据流的管理形式。
Context
注:这里统一指16.3版本以后的新context API,16.3以前的context API存在SCU问题。
类组件中的Context
context可以嵌套使用,也可以多个split使用
// index.js
// 顶层Context
export const TopContext = React.createContext({
data:"",
dispatch:()=>{}
});
class App extends React.Component {
constructor(props) {
super(props);
this.state = {data: "TopContext"};
}
dispatch = (value)=>{
this.setState({data:value});
}
render() {
return (
<TopContext.Provider value={{data:this.state.data, dispatch}}>
<ModuleA></ModuleA>
</TopContext.Provider>
);
}
}
// moduleA.js
// 模块级别Context
export const ModuleAContext = React.createContext({
moduleAData: "",
dispatchA: ()=>{}
});
class ModuleA extends React.Component {
constructor(props) {
super(props);
this.state = {moduleAData: "ModuleAContext"};
}
dispatchA = (value)=>{
this.setState({moduleAData:value});
}
render() {
return (
<ModuleAContext.Provider value={{moduleAData:this.state.moduleAData, dispatchA}}>
<PageOne></PageOne>
</ModuleAContext.Provider>
);
}
}
// pageOne.js
import {TopContext} from 'index.js';
import {ModuleAContext} from 'moduleA.js';
class PageOne extends React.Component {
render() {
return (
<TopContext.Consumer>
{
({data,dispatch})=>{
return <Button onClick={()=>{dispatch("pageOne-TopContext-Click")}}>{data}</Button>
}
}
<ModuleAContext.Consumer>
{
({moduleAData,dispatchA})=>{
return <Button onClick={()=>{dispatchA("pageOne-ModuleAContext-Click")}}>{moduleAData}</Button>
}
}
</ModuleAContext.Consumer>
</TopContext.Consumer>
);
}
}
在使用类组件的场景下,即使使用新的Context API,同样存在shouldComponentUpdate的问题,pureComponent也是一样的问题。
SCU问题是在context传递过程中,如果有中间组件做了shouldComponentUpdate比较但是这个组件未使用context,那么即使子组件使用了Context,该子组件也不会触发更新。
Hooks场景中的Context
// index.js
// 顶层Context
export const TopContext = React.createContext({});
const reducer = (state, action) => {
switch (action.type) {
case "A":
return { ...state, ...action.payload };
case "B":
return { ...state, ...action.payload };
default:
return state;
}
};
const initialState = {text:"TopContext"};
const App = (props) => {
const [state, dispatch] = useReducer(reducer, initialState);
return (
<TopContext.Provider
value={{
data: state,
dispatch: dispatch
}}
>
<ModuleA></ModuleA>
</TopContext.Provider>
);
}
// moduleA.js
// 模块级别Context
export const ModuleAContext = React.createContext({});
const reducer = (state, action) => {
...
};
const initialState = {text:"ModuleAContext"};
const ModuleA = () => {
const [state, dispatch] = useReducer(reducer, initialState);
return (
<ModuleAContext.Provider
value={{
dataA: state,
dispatchA: dispatch
}}
>
<PageOne></PageOne>
</ModuleAContext.Provider>
);
}
// pageOne.js
import {TopContext} from 'index.js';
import {ModuleAContext} from 'moduleA.js';
const PageOne = () => {
const { dispatch, data } = useContext(TopContext);
const { dispatchA, dataA } = useContext(ModuleAContext);
return (
<div>
<Button onClick={()=>{dispatch("pageOne-TopContext-Click")}}>{data.text}</Button>
<Button onClick={()=>{dispatchA("pageOne-ModuleAContext-Click")}}>{dataA.text}</Button>
</div>
);
}
但是在Hooks的场景下,由于底层机制的更改,不会存在SCU的问题。
思考
Context作为React自带的数据中心,在少量数据/数据流不复杂的场景下,其实完全满足作为统一数据中心的需求,即使需要考虑树形多级数据中心的场景下,也能满足需求。
关于更新context造成全局重新渲染的性能问题,可以结合useMemo或者React.memo机制来减少对应的问题。
当然,Context的缺陷是store的变更依赖于下沉到子组件中的dispatch来完成,对于一些全局状态的管理并不太容易抽离到单独的模块中实现。
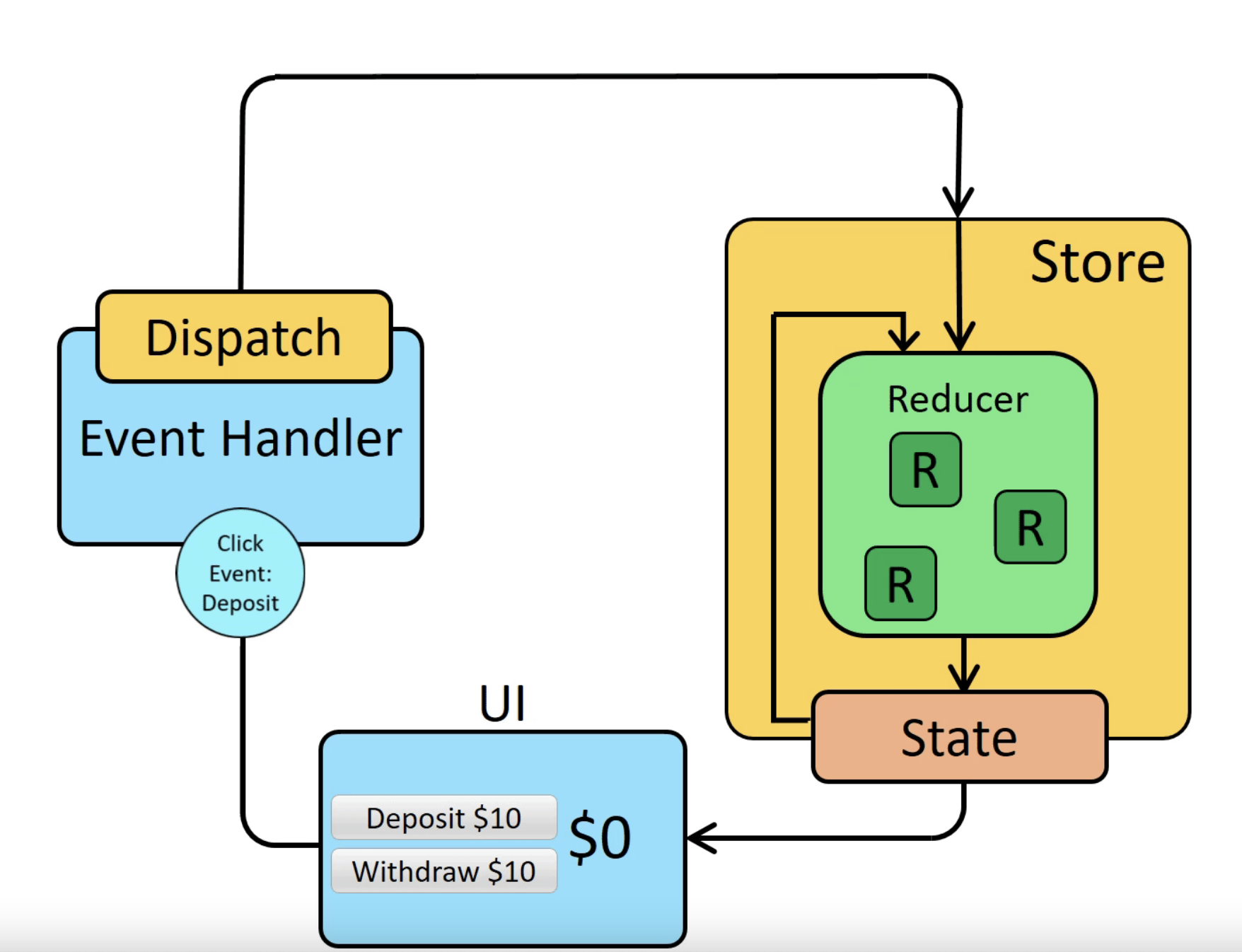
Redux
先上一张官网的图看下Redux的数据流。
// store.js
function reducerA(state = { valueA: "a" }, action) {
switch (action.type) {
case "ActionA":
return { ...state, valueA: action.payload }
default:
return state
}
}
function reducerB(state = { valueB: { b1: 1, b2: 2 } }, action) {
switch (action.type) {
case "ActionB":
return { ...state, valueB: action.payload }
default:
return state
}
}
export const OverallReducer = combineReducers({
storeA: reducerA, storeB: reducerB, storeC: reducerC
})
export const centralStore = createStore(OverallReducer, applyMiddleware(thunk));
//index.js
ReactDOM.render((
<Provider store={centralStore}>
<App/>
</Provider>
), document.getElementById('root'));
// app.js
export const App = () => {
return (
<div>
<ModuleA></ModuleA>
<ModuleB></ModuleB>
</div>
);
}
// AsyncActions.js
export const asyncDispatchA = (dispatch) => {
setTimeout(() => {
dispatch({ type: 'ActionA', payload: "AsyncDispatchA" })
}, 3000);
}
// moduleA.js
export const App = () => {
const dispatch = useDispatch();
const actionAText = useSelector((state) => {
return state.actionA;
})
const actionBObject = useSelector((state) => state.actionB);
const handleButtonAClick = () => dispatch({ type: 'todos/allCompleted' });
const handleButtonBClick = () => dispatch({ type: 'todos/completedCleared' });
const handleButtonCClick = () => dispatch(asyncDispatchA);
return (
<div className="main">
<div className="actions">
<button className="buttonA" onClick={handleButtonAClick}>
ActionA
</button>
<div>{actionAText}</div>
<button className="buttonB" onClick={handleButtonBClick}>
ActionB
</button>
<div>{JSON.stringify(actionBObject)}</div>
<button className="buttonC" onClick={handleButtonCClick}>
asyncA
</button>
</div>
</div>
)
}
// moduleB.js
export function ModuleB() {
const valueB = useSelector(store => { return { B: store.storeB.valueB } }, shallowEqual);
console.log("render-moduleB")
return (
<div>
{JSON.stringify(valueB)}
</div>
);
}
关于useSelector
useSelector是一个hook,当store被更新触发重新渲染时,他的第一个参数方法将被调用,如果该方法返回的值被改变,那么
使用该hook的组件就会被re-render。
这里需要注意的是:返回的值是否改变使用的对比方法,默认是===操作符
带来的问题是:如果返回的值是一个对象,那么每次重新计算时必然都不一样,这种情况下需要使用useSelector的第2个参数自己来对比object是否改变或者使用shallowEqual。
关于异步中间件
首先,异步请求不一定要通过thunk或者middleware,完全可以在组件的CDU或者useEffect里直接发一个异步请求,然后再把返回的数据dispatch一下,存到store里。thunk其实只是对于一种业务模式的抽象,把多个模块需要共用的一种业务抽离出来放到单独模块。所以说,如果是组件内维护状态,redux 只是解决共享问题,那就可以不在 redux 里处理异步;如果是 redux 集中业务逻辑,那通常是提倡异步逻辑单独抽离开的。
关于计算缓存
跟异步中间件一样,是否使用如reselect等的第三方计算缓存库主要取决于状态维护是否由组件内部自己维护,还是集中式业务逻辑。
const componentA = ()=>{
const valueA = useSelector((state) => state.valueA);
const valueB = useSelector((state) => state.valueB);
const calcValue = useMemo(()=>{return valueA + valueB},[valueA,valueB]);
return (<div>{calcValue}</div>)
}
const calcSelector = createSelector(
[(state) => state.storeA.valueA,
(state) => state.storeB.valueB],
(valueA, valueB) => valueA + valueB
)
const componentB = ()=>{
const calcResult = useSelector(calcSelector)
return (<div>{calcResult}</div>)
}
以上代码的区别在于缓存由谁负责,当使用createSelector时,该计算结果可以在多个组件中共用。
思考
首先Redux也是支持树形多级数据中心的。与context相比,reducer支持按业务拆分后进行combine,dispatch可以通过中间件支持异步action。当然,redux和context一样,也有模板代码和重复代码过多的问题,所以使用Redux还是context并没有本质上的区别,还是要取决于团队的背景。至于现存项目,则完全没有必要去折腾替换的问题,保持原状最好。
Mobx
mobx的思想是响应式编程,其逻辑拆分如下
- 定义状态并使其可观察
- 视图层使用状态并响应状态变化
- 更改状态

虽然Mobx支持在单组件内用来进行数据管理,但这并不是一个常见场景。
通常来说Mobx按业务模块将应用状态进行划分,存储在多个独立的store中管理,store的定义如下:
//myStore.js
class MyStore {
title = "StoreA";
price = 10;
amount = 2;
get total() {
return this.price * this.amount;
}
constructor() {
makeAutoObservable(this)
}
}
export const storeA = new MyStore();
const autorunA = autorun(
() => console.log("StoreA autorun:", storeA.title + 'get' + storeA.total)
)
在多组件间共享状态数据有几种方法:
- 使用props
- 使用全局变量
- 使用context provider
//ViewOne.js
import storeA from 'myStore.js'
const ViewA = observer(({ storeA }) => <span>Current Price: storeA.price}</span>)
const ViewB = observer(({ storeA }) => <span>Current Amount: storeA.amount}</span>)
//ViewTwo.js
import storeA from 'myStore.js'
const ViewA = observer(() => <span>Current Price: storeA.price}</span>)
const ViewB = observer(() => <span>Current Amount: storeA.amount}</span>)
//ViewThree.js
import storeA from 'myStore.js'
const ViewRoot = ()=>{
return (<Provider store={storeA}>
<ViewA></ViewA>
</Provider>)
}
const ViewA = (props) => <span>Current Price: props.storeA.price}</span>
const ViewAInject = inject(store => {
return {
storeA: store
};
})(observer(ViewA));
const ViewB = (props) => <span>Current Price: props.storeA.amount}</span>
const ViewBInject = inject(store => {
return {
storeA: store
};
})(observer(ViewB));
使用Mobx管理数据状态会非常灵活,但是过度灵活也是一个问题,在团队协作时需要花更多的时间去了解数据的依赖和流转。
思考
Mobx的学习成本非常少,基础知识很简单,属于响应式编程,对于大部分刚上手的人来说感觉非常容易。
Mobx具有很高的灵活性,但同时过度的灵活会给多人协作项目和团队带来一定的困扰,如果在Code Review和代码结构风格(非书写风格)不严格的团队中使用的话,长期迭代会带来数据流程混乱,规范化的问题。
另外还有诸如依赖收集逃逸(需要对子组件进行类型判断导致无法进行observe包裹),调试困难(打印结果为proxy对象,无法直接调试)等问题。
个人观点Mobx灵活简单,适用于中小型或者会被快速迭代掉的项目,对大型项目或toB业务场景的长生命周期项目,多人协作和迭代开发后期难免带来不可维护性的问题。
状态的immutable
immutable概念这里不展开,immutablejs和Immerjs都使用数据节点共享来提高效率,在此基础上衍生出时间旅行、复制粘贴等功能。
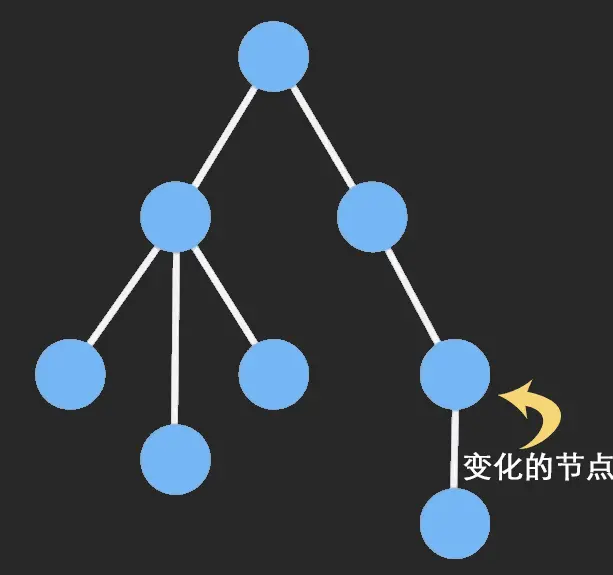
immutablejs有很高的上手成本,并且由于immutablejs使用内置对象转化作为底层的技术实现,因此在操作数据和调试等带来很大的不便。虽然支持编译为 ES3 代码在所有 JS 环境环境,但相较于Immerjs,果断抛弃。
Immerjs学习没有太多成本,因为它的 API 很少,无非就是把我们之前的操作放置到 produce 函数的第二参数函数中去执行。看一下官方示例:
const baseState = [
{
title: "Learn TypeScript",
done: true
},
{
title: "Try Immer",
done: false
}
]
//Without Immer
const nextState = baseState.slice()
nextState[1] = {
...nextState[1],
done: true
}
nextState.push({title: "Tweet about it"})
//With Immer
const nextState = produce(baseState, draft => {
draft[1].done = true
draft.push({title: "Tweet about it"})
})
immer 的核心原理Proxy,做法就是维护一份 state 在内部,劫持所有操作,内部来判断是否有变化从而最终决定如何返回。
const ComponentImmer = ()=>{
const [valueImmer, setValueImmer] = useState([{ a: 1 }, { a: 2 }]);
const handleImmerClick = () => setValueImmer(produce(valueImmer, (draft) => {
draft.forEach(item => item.a += 1)
}));
return (
<div>
<button className="Immer" onClick={handleImmerClick}>
ImmerClick
</button>
<div>{valueImmer.map(item => item.a + "-")}</div>
</div>
);
}
与immutablejs 最大的不同,immer是使用原生数据结构的 API 而不是像 immutable-js 那样转化为内置对象之后使用内置的 API,因此使用和上手上面会简单很多。
尤其是对于不熟悉React的state机制的人或新人,使用immerjs会大大降低上手难度和各种由于未使用新的object更新state造成的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号