JAVA中的集合(Collection和Map)
1、Java 集合框架概述
/**
* 一、集合的框架
*
* 1.集合、数组都是对多个数据进行存储操作的结构,简称Java容器。
* 说明;此时的存储,主要是指能存层面的存储,不涉及到持久化的存储(.txt,.jpg,.avi,数据库中)
*
* 2.1数组在存储多个数据封面的特点:
* 》一旦初始化以后,它的长度就确定了。
* 》数组一旦定义好,它的数据类型也就确定了。我们就只能操作指定类型的数据了。
* 比如:String[] arr;int[] str;
* 2.2数组在存储多个数据方面的特点:
* 》一旦初始化以后,其长度就不可修改。
* 》数组中提供的方法非常有限,对于添加、删除、插入数据等操作,非常不便,同时效率不高。
* 》获取数组中实际元素的个数的需求,数组没有现成的属性或方法可用
* 》数组存储数据的特点:有序、可重复。对于无序、不可重复的需求,不能满足。
*
*/
2、集合框架涉及的API
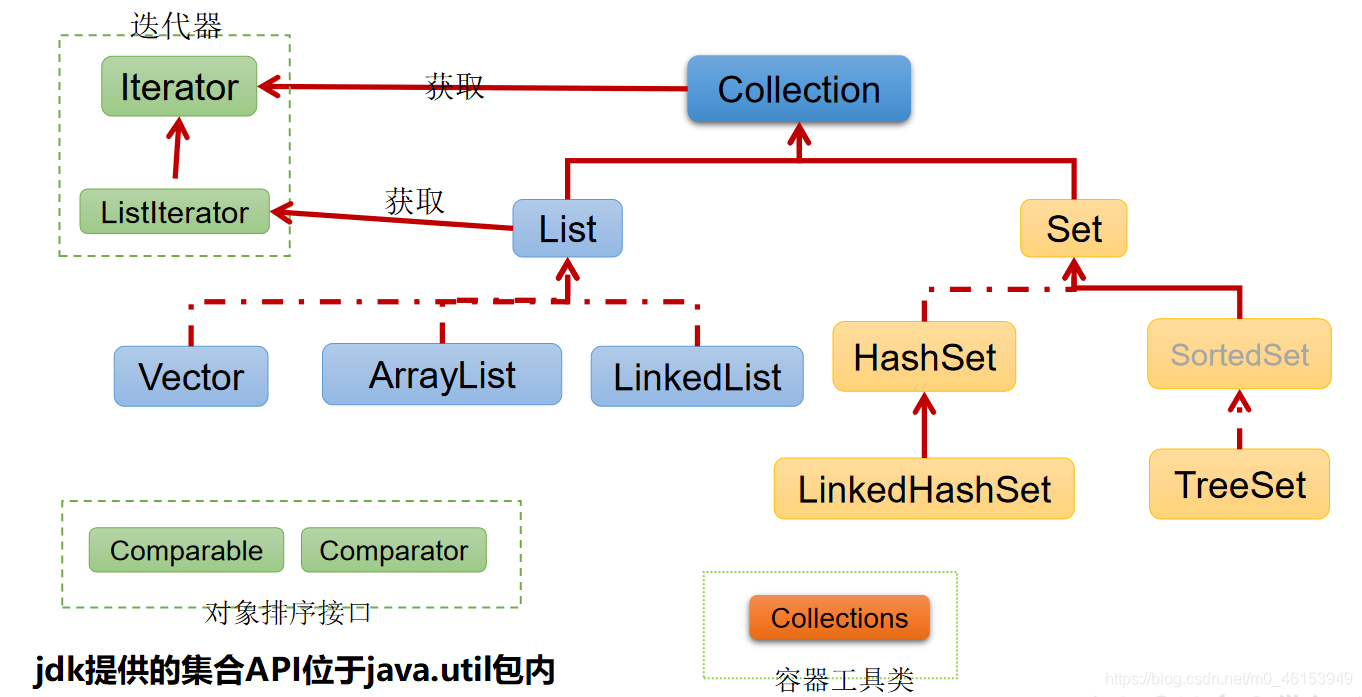
1、Collection接口继承树
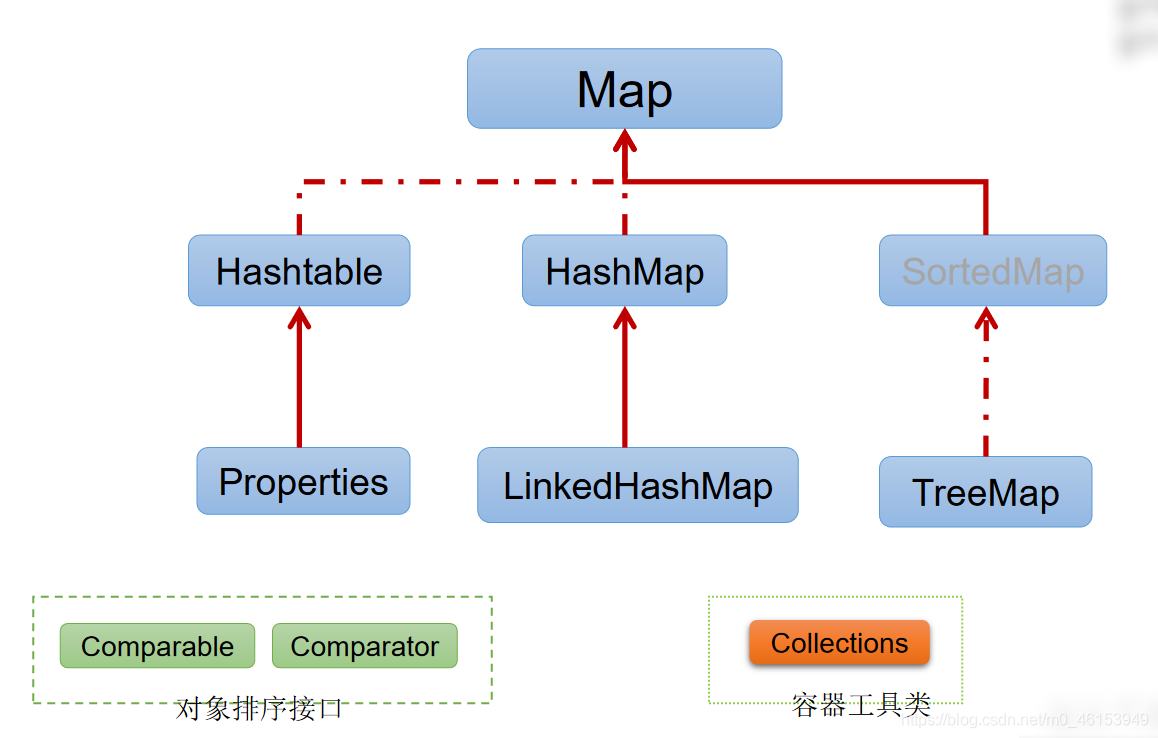
2、Map接口继承树
* 集合框架:
* &---Collection接口:单列集合,用来存储一个一个的对象
* &---List接口:存储有序的、可重复的数据。 -->“动态”数组
* &---ArrayList、LinkedList、Vector
*
* &---Set接口:存储无序的、不可重复的数据 -->高中讲的“集合”
* &---HashSet、LinkedHashSet、TreeSet
*
* &---Map接口:双列集合,用来存储一对(key - value)一对的数据 -->高中函数:y = f(x)
* &---HashMap、LinkedHashMap、TreeMap、Hashtable、Properties
2.1 Collection子接口之一:List接口
/**
* List接口框架
* |----Collection接口:单列集合,用来存储一个一个的对象
* |----List接口:存储有序的、可重复的数据。 -->“动态”数组,替换原有的数组
* |----ArrayList:作为List接口的主要实现类;线程不安全的,效率高;底层使用Object[] elementData存储
* |----LinkedList:对于频繁的插入、删除操作,使用此类效率比ArrayList高;底层使用双向链表存储
* |----Vector:作为List接口的古老实现类;线程安全的,效率低;底层使用Object[] elementData存储
*
*
* 面试题:比较ArrayList、LinkedList、Vector三者的异同?
* 同:三个类都是实现了List接口,存储数据的特点相同:存储有序的、可重复的数据
* 不同:见上
*
*/
2.2 Collection子接口之二:Set接口
/**
* Set接口的框架:
* |----Collection接口:单列集合,用来存储一个一个的对象
* |----Set接口:存储无序的、不可重复的数据 -->高中讲的“集合”
* |----HashSet:作为Set接口的主要实现类;线程不安全的;可以存储null值
* |----LinkedHashSet:作为HashSet的子类;遍历其内部数据时,可以按照添加的顺序遍历
* 对于频繁的遍历操作,LinkedHashSet效率高于HashSet.
* |----TreeSet:可以按照添加对象的指定属性,进行排序。
*/
2.3 Map接口
* 一、Map的实现类的结构:
* |----Map:双列数据,存储key-value对的数据 ---类似于高中的函数:y = f(x)
* |----HashMap:作为Map的主要实现类;线程不安全的,效率高;存储null的key和value
* |----LinkedHashMap:保证在遍历map元素时,可以按照添加的顺序实现遍历。
* 原因:在原有的HashMap底层结构基础上,添加了一对指针,指向前一个和后一个元素。
* 对于频繁的遍历操作,此类执行效率高于HashMap。
* |----TreeMap:保证按照添加的key-value对进行排序,实现排序遍历。此时考虑key的自然排序或定制排序
* 底层使用红黑树
* |----Hashtable:作为古老的实现类;线程安全的,效率低;不能存储null的key和value
* |----Properties:常用来处理配置文件。key和value都是String类型
*
*
* HashMap的底层:数组+链表 (jdk7及之前)
* 数组+链表+红黑树 (jdk 8)
*
* 二、Map结构的理解:
* Map中的key:无序的、不可重复的,使用Set存储所有的key ---> key所在的类要重写equals()和hashCode() (以HashMap为例)
* Map中的value:无序的、可重复的,使用Collection存储所有的value --->value所在的类要重写equals()
* 一个键值对:key-value构成了一个Entry对象。
* Map中的entry:无序的、不可重复的,使用Set存储所有的entry
*
*
* 面试题:
* 1. HashMap的底层实现原理?
* 2. HashMap 和 Hashtable的异同?
* 3. CurrentHashMap 与 Hashtable的异同?(暂时不讲)
*/
HashMap的底层实现原理
JDK 7及以前版本:HashMap是数组+链表结构(即为链地址法)
JDK 8版本发布以后:HashMap是数组+链表+红黑树实现。
原文链接:https://blog.csdn.net/PorkBird/article/details/113727330

