STA扩展
1. Tool是怎么计算Cell dealy & Net delay的?
Cell delay:根据 cell 的输入 transition 和输出 load 通过查表从 library 中得到 cell delay 和输出 transition,在 library 的表头有四个 attribute,这四个 attribute 决定了 cell delay 是如何衡量的,通常这四个值都是 50%,所表诉的意思是:从输入信号电压上升 / 下降到工作电压的 50% 到对应的输出信号电压翻转为工作电压的 50% 之间的时间为 cell delay。进一步追溯,cell delay 的计算分为三部分:library 的生成、输入 transition 的计算、输出 load 的计算。
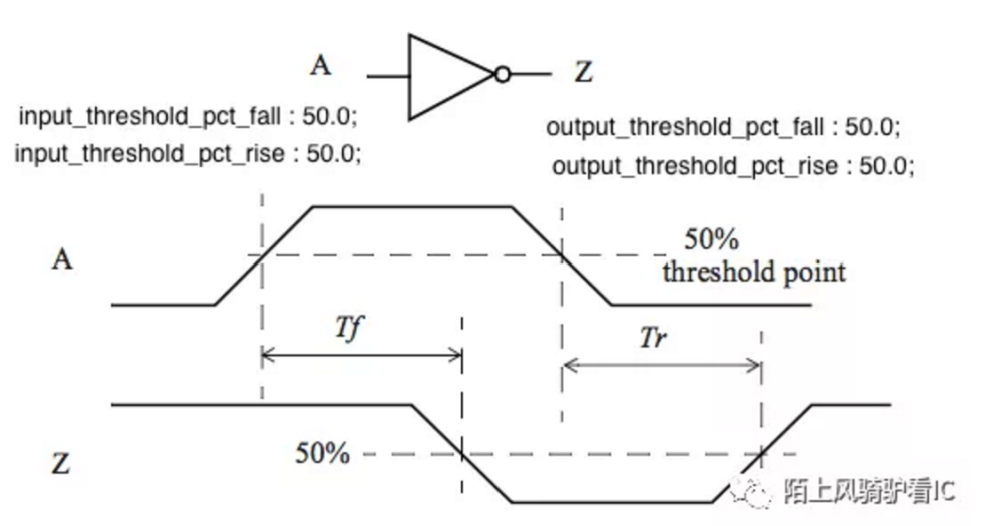
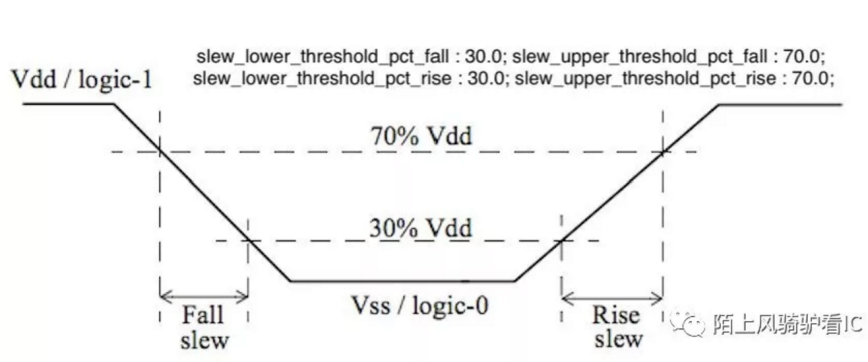
而Transition 的计算是逐级递进的,port 的 transition 由硅农在 SDC 中指定,如 set_driving_cell,第一级 Port 的 transition 来自 driving cell 的 output transition,经由 net 的 RC 网络到达下一级 cell 的 input pin,再从 library 中查得该级 cell 的 output transition 依次类推。同样在 library 的表头有四个变量,用以标示如何衡量 rise/fall transition time。如从工作电压的 30% 上升到工作电压的 70% 为 rise transtion time,从工作电压的 70% 下降到工作电压的 30% 为 fall transition time。
Net delay:线延迟的计算可以有多种方式,但是不同方式有其各自的特征,分别介绍如下,
方式1.根据线负载模型进行估算,优势就是快,但是不准确,偏差较大,常用于综合阶段,crosstalk/noise的影响无法评估;
方式2.直接读取反标的SDF文件,优势是快,但是需要生成该文件;
方式3.根据提取的寄生参数文件进行计算,优势就是更加精准,crosstalk/noise的影响同样可以计算,但是速度比较慢,需要后端工具提取寄生参数文件,比如starRC。
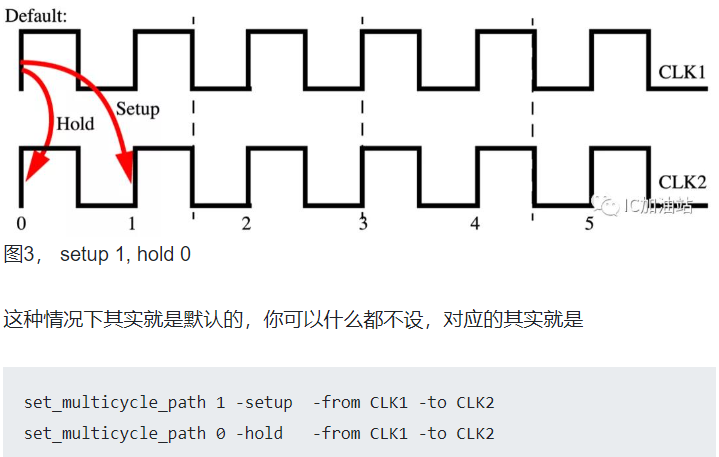
2. 多周期路径设置
默认:DC默认对setup的检查是-end;对hold的检查是-start
移动方向规律:
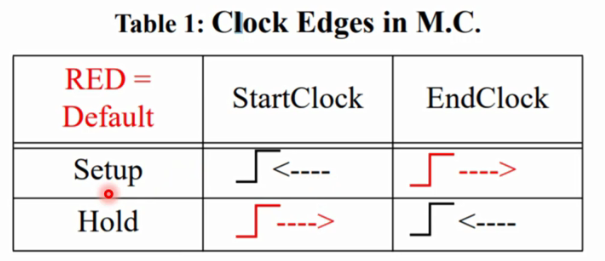
- 对setup而言,设置-start,则向左移是正,设置-end,则向右移是正
- 对hold而言,设置-start,则向右移是正,设置-end,则向坐移是正
同频:
假设组合逻辑需要5个周期完成:
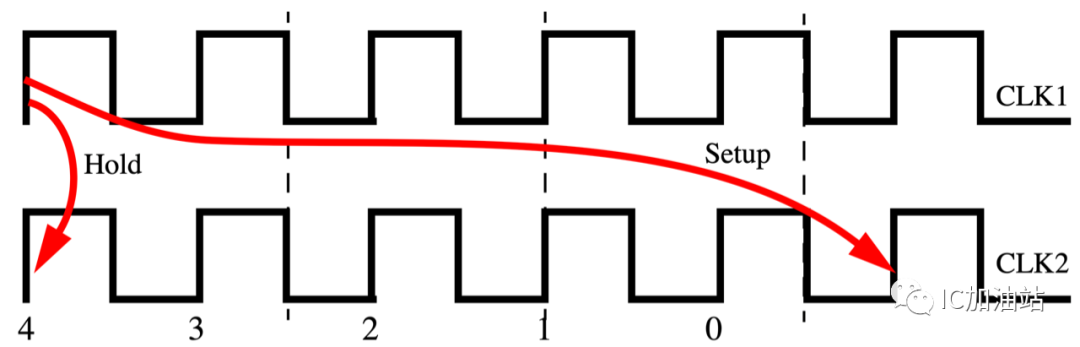
set_multicycle_path 5 -setup -from CLK1 -to CLK2
set_multicycle_path 4 -hold -from CLK1 -to CLK2
注意,如果你不设置-hold,那么会自动调整为setup的沿的前一个沿。hold的cycle是相对于setup path的沿往前算的,也就是说CLK2的setup capture edge为1,前一个沿为0,也就是默认的值,而如果你要继续往前面的沿来设就要调整multiplier的值。
慢到快:多周期是针对快时钟(-end;-end)
希望设置2周期路径

如果仍然仍然设置setup 2;hold 1,则变成:
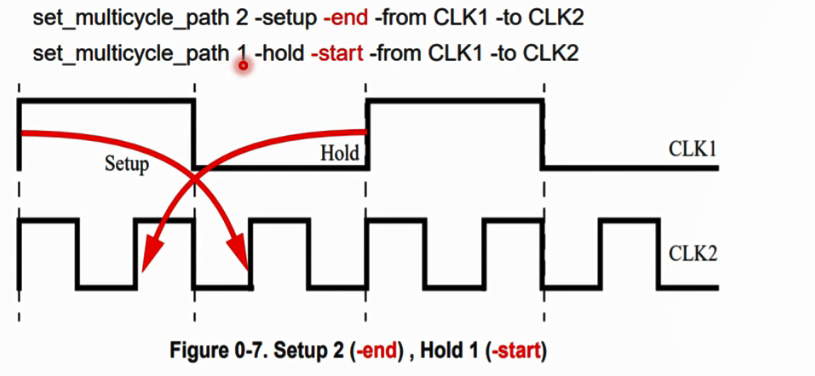
因为hold默认-start,也就是将start沿往后移1,但是end沿不变,就变成了上图的情况
那么要怎么正确设置呢,这个时候我们要调整的是hold,要依据CLK2的周期来调整,要加-end选项。
set_multicycle_path 2 -setup -end -from CLK1 -to CLK2
set_multicycle_path 1 -hold -end -from CLK1 -to CLK2
hold end端(在clk2上)往前移1
快到慢:多周期是针对快时钟(-start;-start)
默认的check:
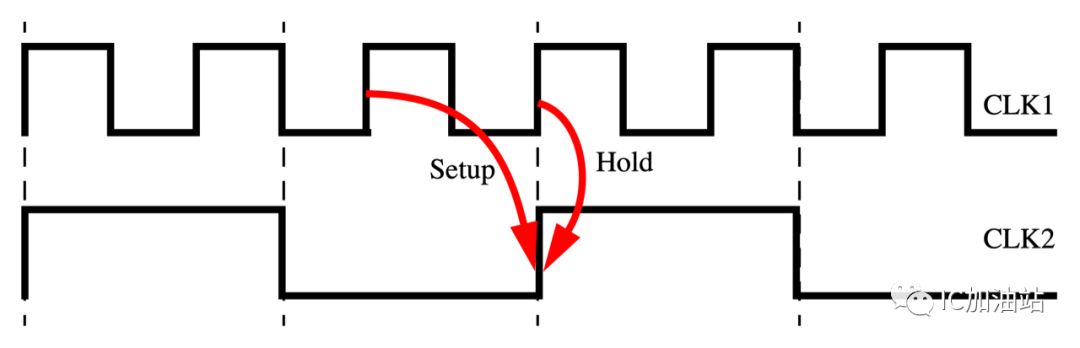
由于多周期是针对快时钟,此时setup需要设置的是-start时钟
set_multicycle_path 2 -setup -start -from CLK1 -to CLK2
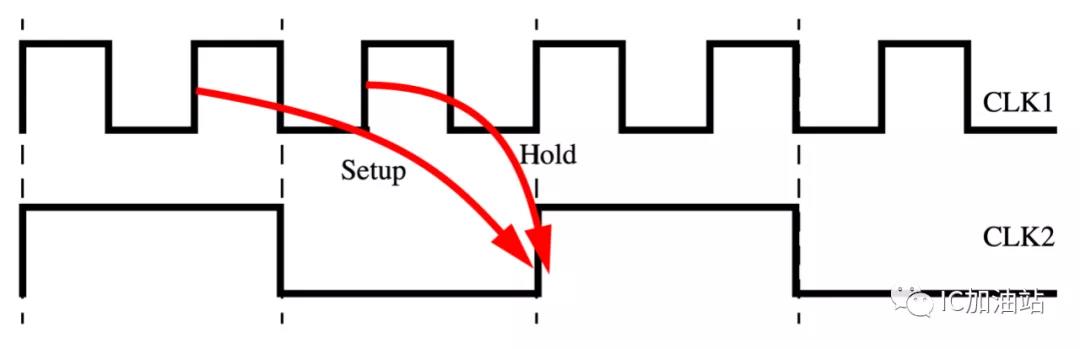
要想把hold的沿对齐,那就要用下面的约束

3. SDC常用命令:
3.1 描述芯片的工作速度,即时钟的频率,包括create_clock, create_generated_clock等

create_clock和create_generated_clock有什么区别?
一般我们把时钟的源头会定义成create_clock,而分频时钟则会定义为create_generated_clock. 两者的主要区别在于CTS步骤,generated clock并不会产生新的clock domain, 会继承source clock的latency。
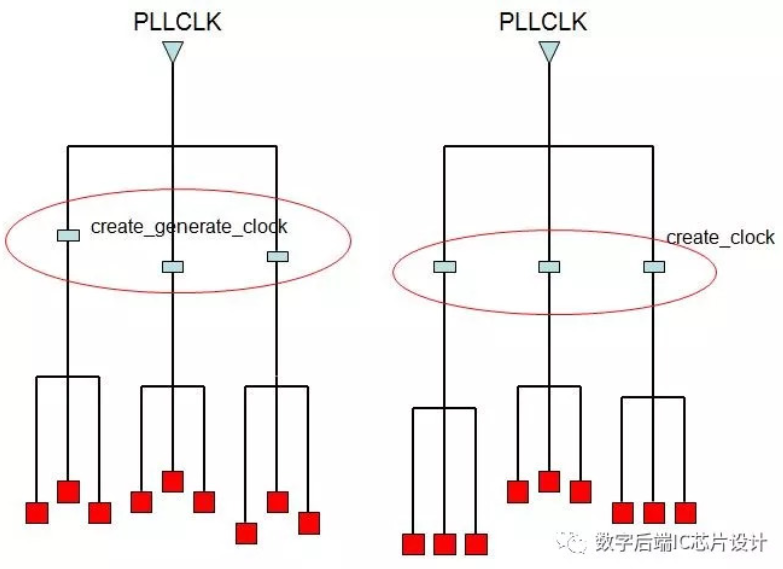
上图中描述,如果我们给PLLCLK出来的三个分频点定义为generate clock,则在trace clock tree时,工具会穿过这三个点,并不会产生新的clock,对工具来说,它会balance所有clock sink。这种情况下,clock tree通常会做得比较长一些。
相反,如果我们给这三个分频点定义为create_clock,则在trace clock tree时,这三个点会生成各自新的clock tree,属于他们自己的sink会分别做balance,但是相互之间会不做balance。而且它本身的input clock pin也会被当成PLLCLK的sink进行balance。
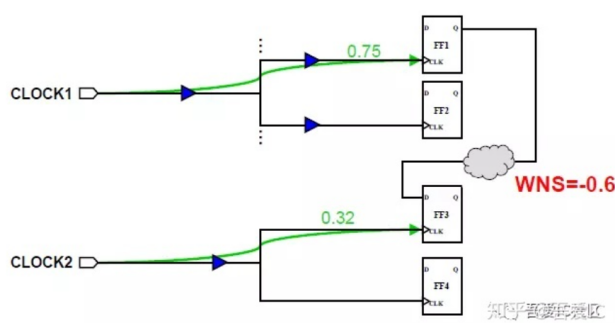
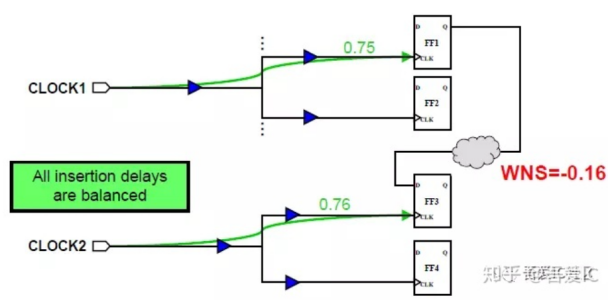
下图是未做balance和做了balance的对比:
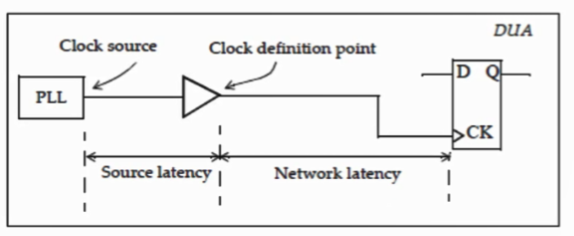
3.2 clk latency:
包括Source latency和Network latency,当然,有时候source端并不一定在pll,可以认为设置。
3.3 clk uncertainty 包括skew/jitter
3.4 描述芯片的边界约束,包括set_input_delay, set_output_delay等
3.5 描述组合逻辑延迟: set_max_delay, set_min_delay
3.6 描述设计中一些特殊的路径,包括set_false_path, set_multicycle_path等
3.7 描述设计中一些需要禁止的timing arc,例如set_disable_timing
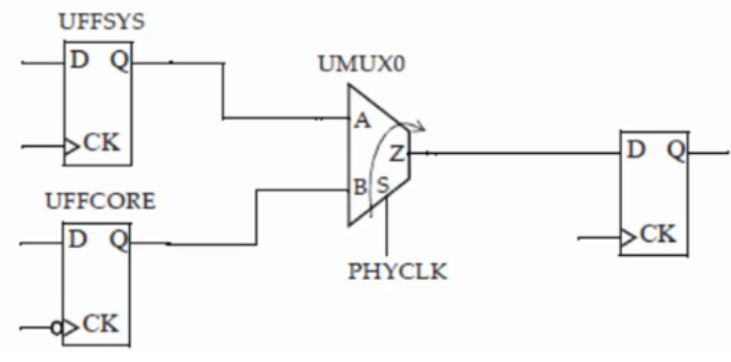
4. STA OCV:
library中的cell delay是在某个固定的PVT(operating condition)下仿真得出的,也就是下图中的Nominal delay,而实际上在芯片内部由于工艺偏差、电压降、温度变化,cell的delay并不是一个固定值,
而是一个随机值,遵循高斯分布。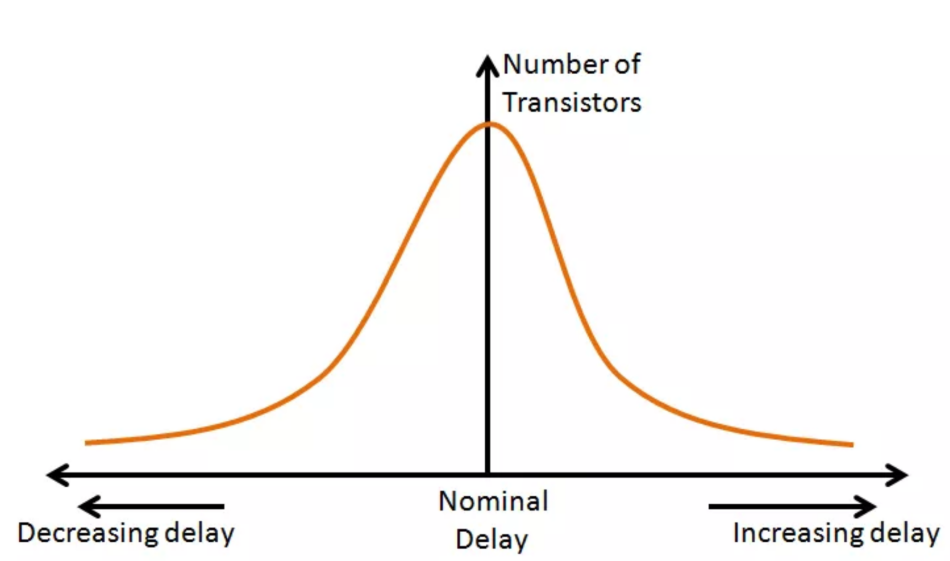
在STA中用OCV来模拟这一『特征』,OCV全称on chip variation,用于描述不同管子间由于PVT引起的delay变化,也用于描述工艺偏差引起的net厚度宽度的变化从而导致net的电容电阻变化。概括为不同芯片在相同PVT下的性能表现不同。
在timing sign-off时,为什么要在Nominal delay上加OCV?因为Nominal delay是在固定PVT下仿真得出的delay,而实际上由于OCV的影响,管子的delay是呈高斯分布或门特卡洛分布,要想保证收益,就必须在timing sign-off时将OCV考虑在内,以保证大部分管子都可以满足时序要求。
OCV的计算?
对每一代工艺,foundry都会做大量测试,针对每个corner找到一组适合的OCV值,这组值可以保证足够高的yield,而如果进一步加紧这个值,并不会更有效的提高yield。
Timing derate: 这个值就是告诉工具,OCV影响有多大。比如在Worst case(WC)下,delay就会多一点,在BC下,就会少一点
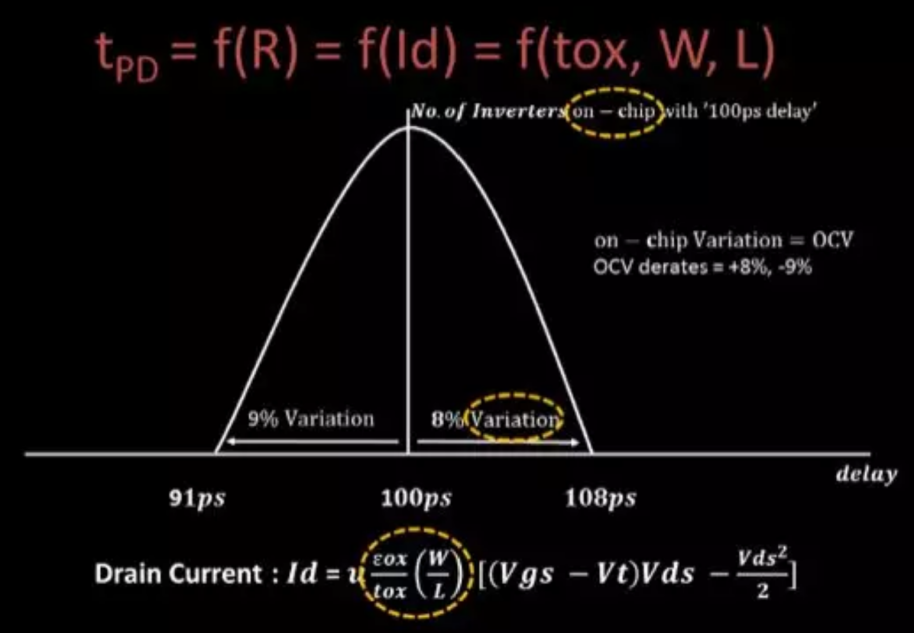
5. STA分析方式
在不同温度工艺电压下,把时延相关信息分为三档:best, typical, worst
STA分析方式主要有三种:single,worst_best,OCV
- Single:在单一情况下进行分析,即在做setup/hold分析时用同一种PVT模式下的时延信息
- Worst_best:在分析时同时读入worst和best情况下的延迟信息,用worst下的延迟信息计算Setup constraints,用best下的PVT模式计算hold time constraints
- OCV:在分析时同时读入worst情况下的PVT,在进行setup计算 时,clock skew采用考虑到加工工艺的不确定性对时延的影响,用PVT中best(shortest)情况下计算,data delay用PVT中worst(longest)情况进行计算。计算Hold时相反。这种分析方式对芯片的timing非常严格。
6. CPPR:
CPPR(CRPR)。全称Clock Path Pessimism Removal(Clock Reconvergence Pessimism Removal),中文名“共同路径悲观去除”。它的作用是去除clock path上的相同路径上的悲观计算量。如下图所示:
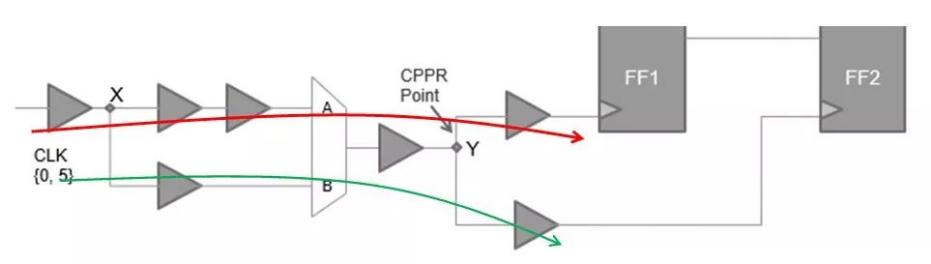
由于STA是穷举型的分析路径,在分析setup timing时,clock launch path会选择红色的路径,clock capture path则会选择绿色的路径,这本身就是不合理的情况,一个mux不可能同时存在两条经过的路径,所以我们需要去除这个计算的悲观量。再比如:
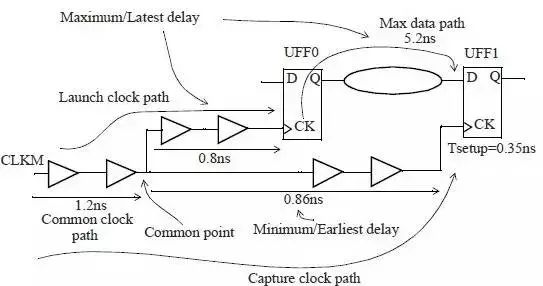
大家肯定发现了对于path最前端那1.2ns的延迟,在setup分析时,launch clock path中没有被derate, 而在capture clock path中被time derate 1.2*0.9 =1.08. 显然这是相互矛盾的。对于上诉设计,考虑CPPR之后,我们必须减去一个CPP因子=1.2-1.08=0.12

 浙公网安备 33010602011771号
浙公网安备 33010602011771号