
9.MySQL单表,多表
==========================================
order by 排序
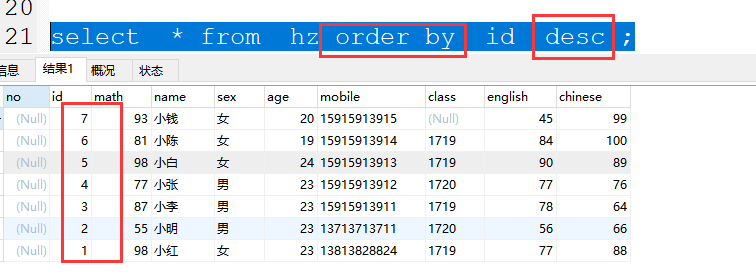
(1)降序 (大到小)
order by desc
案例:select * from hz order by id desc ;
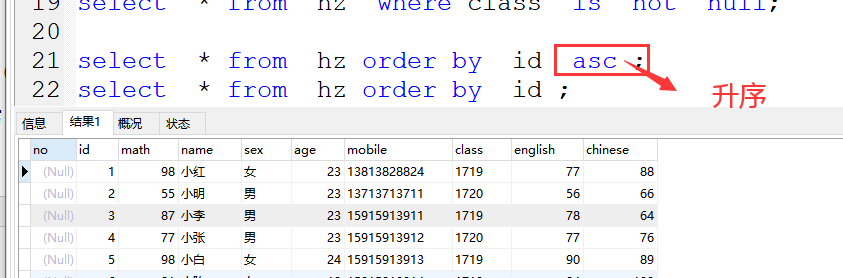
(2)升序(小到大)
asc 或不写
案例:
select * from hz order by id asc ;
select * from hz order by id ;
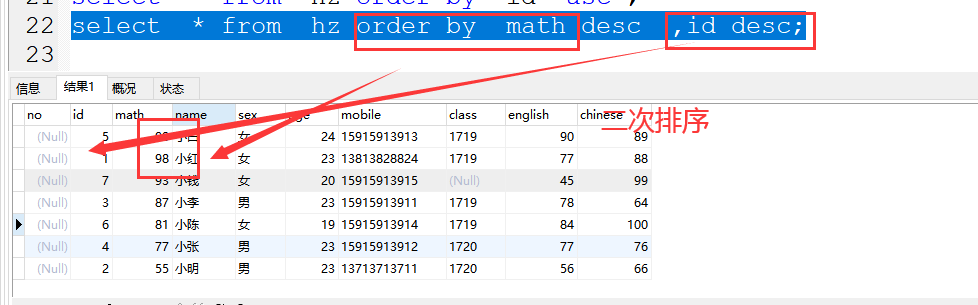
(3)二次排序
案例:select * from hz order by math desc ,id desc;
=====================
like 模糊匹配查询
%:表示匹配1个字符或多个字符
_ : 下滑线表示一个字符
案例1:匹配xx开头的数据
select * from hz where math like "7%"; # 匹配7开头的数据
案例2:匹配xx结尾数据
select * from hz where math like "%7"; #匹配7结尾的数据
案例3:匹配含有xx数据
select * from hz where math like "%7%"; #匹配含有7的数据
案例4:匹配指定位数的数据
select * from hz where math like "7_"; #匹配具体位数的数据
=====================
limit (索引位,步长) 显示指定的数据,限制;
根据索引位置来取值,从0开始,一个表第一行的索引就是0,第二行就是1
select * from hz limit 2; #表示取两行数据, 2 表示步长
select * from hz limit 1,2#表示从索引1开始第二行,2表示步长2行
select * from hz limit 4,3 ;# 表示从索引4开始取值,第五行开始,取三行,
=====================
sql 聚合函数
max 最大数
案例1:select max(math) from hz ;
min最小数
案例2:select min(math) from hz ;
avg 平均值
案例3:
select avg(math) from hz ;
sum 求和
案例4:
select sum(math) from hz ;
count 统计
案例5:select count(math) from hz ;
distinct 去重
案例6:
select DISTINCT(math) from hz ;
==================
group by ....... having
group by 是分组,一般不会单独使用,通常和聚合函数组合使用
案例1:分组
select sum(math),class from hz GROUP BY class ;
案例2:分组 在条件 having
(1)select sum(math) s,class from hz GROUP BY class having s>200 ;
(2)select sum(math) s,class from hz GROUP BY class having sum(math)>200 ;
注意:having 一般接在group by 后面
==================
改:
update ......set......
格式:update 表名 set 字段名=新值 where条件;
案例:update hz set id=1 where id=9;
==================
删除:
(1)delete
格式:DELETE from 表名 where 条件;
DELETE from hz where id=1;
(2) truncate 快速删除数据
格式:
truncate 表名 ;
案例:
truncate ff ;
(3)drop 删除
格式:drop table 表名
案例:drop table emp ;
drop >truncate> delete
==================
单行注释:ctrl +/
取消注释:shift+ctrl+/
多行注释:选中多行 ,ctrl +/
取消注释:选中多行 shift+ctrl+/
===============================
备份:
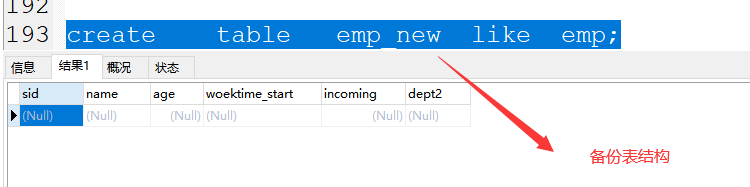
(1)备份表结构:
格式:create table 新表名 like 旧表名;
create table emp_new like emp;
(2)备份表数据
格式:
INSERT into 新表结构 select * from 旧表有数据 ;
案例:
INSERT into emp_new select * from emp ;

(3)备份部分数据
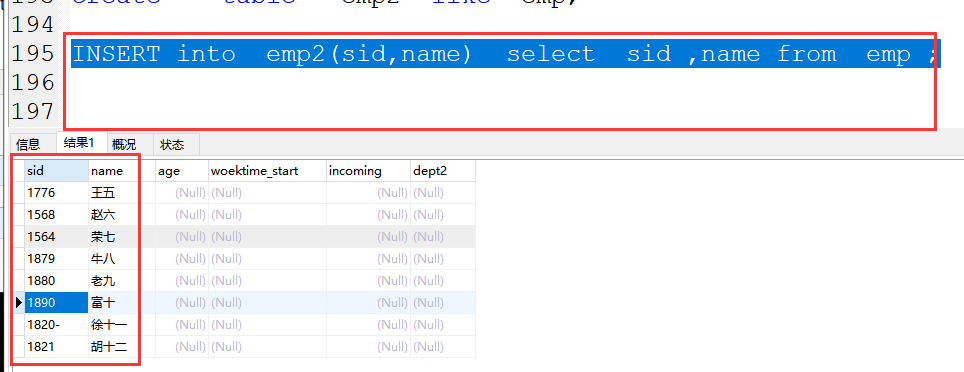
格式:INSERT into 表名(字段1,字段2) select 字段1,字段2 from 旧表 ;
案例:INSERT into emp2(sid,name) select sid ,name from emp ;
(4)备份表结构和数据
格式:
create table 新表 as (select * from 原表);
案例:create table hh as (select * from emp);

=========================================================================
在linux 中:
备份:
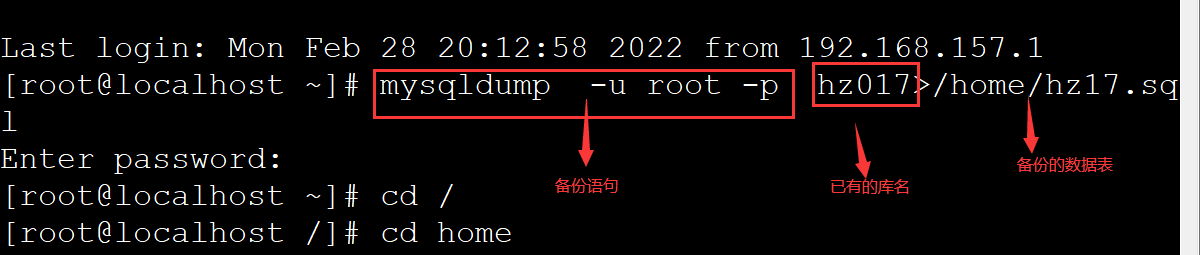
格式:mysqldump -u root -p 原库>新sql脚本名
案例:mysqldump -u root -p hz017>/home/hz17.sql
还原:

还原:
格式:mysql -u root -p 新库<备份好的脚本
案例:mysql -u root -p new</home/hz17.sql
===================================
一、多表查询
1、什么是多表关联查询
从2个表或者更多的表中查询我们需要的数据
2、多表连接的关系?
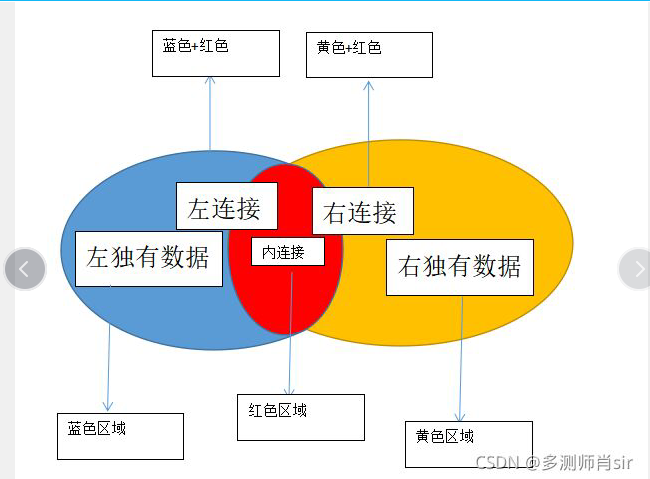
(1)内连接
(2)左连接
(3)右连接
(4)左独有数据
(5)右独有数据
(6)全外连接
比如: a 表:1,2,3 b 表:1,2,4
内连接:显示左边12和右边12关联 12
左连接:显示左边1,2,3,右 边12 关联 123 4不显示
右连接: 显示右边1,2,4全部显示,左 边12关联 124, 3不显示
左独有数据:显示3
右独有数据:显示4
全外连接:显示1,2,3,4
===================================
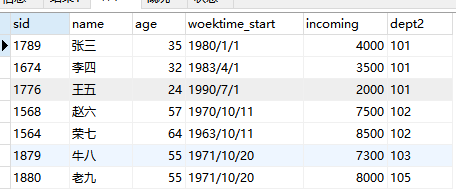
部门表:部门编号 ,部门名称

员工表:
员工编号,姓名,年龄、工作时间、工资、部门编号
====================================================
三、内连接
1、内连接(普通内连接,隐藏内连接两者结果相同,只是格式不同)
定义:查询两个表共有的关联的数据
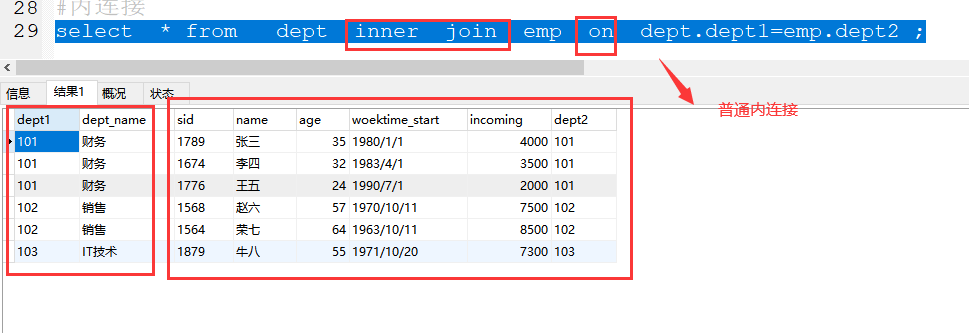
(1)普通内连接:
格式:select * from 表1 inner join 表2 on 表1.关联字段1=表2.关联字段2 ;
案例:select * from dept inner join emp on dept.dept1=emp.dept2 ;
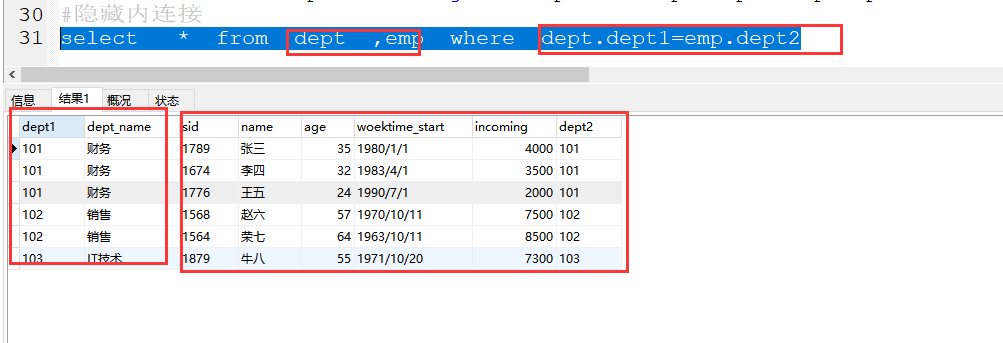
(2)隐藏内连接
格式:select * from 表1 , 表2 where 表1.关联字段1=表2.关联字段2 ;
案例:select * from dept ,emp where dept.dept1=emp.dept2
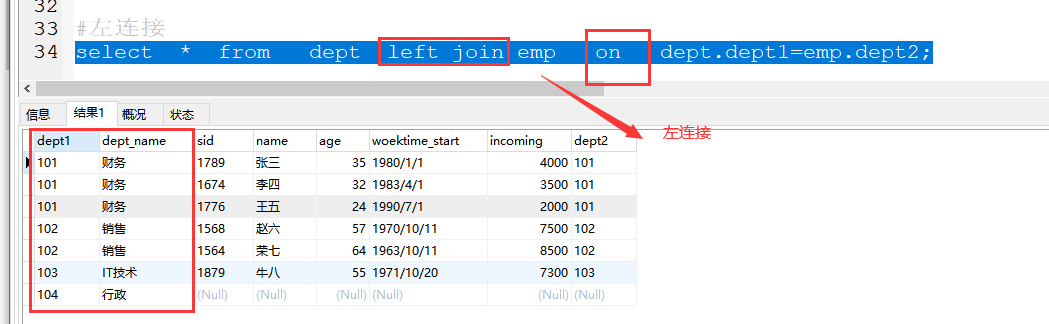
2、左连接(左边全部显示,右边只显示与左边相同部分)
格式:select * from 表1 left join 表2 on 表1.关联字段1=表2.关联字段2 ;
案例:select * from dept left join emp on dept.dept1=emp.dept2;
3.右连接(右边全显示,左边只显示与右边相同部分)
格式:select * from 表1 right join 表2 on 表1.关联字段1=表2.关联字段2 ;
案例:select * from dept right join emp on dept.dept1=emp.dept2;

4、左独有数据(只显示左边独有数据)
格式:select * from 表1 left join 表2 on 表1.关联字段1=表2.关联字段2 where 右表字段 is null ;
案例:select * from dept left join emp on dept.dept1=emp.dept2 wehre name is null;

五、右独有数据(只显示右边独有数据)
格式:select * from 表1 right join 表2 on 表1.关联字段1=表2.关联字段2 where 左表字段 is null ;
案例:select * from dept right join emp on dept.dept1=emp.dept2 wehre dept1 is null;

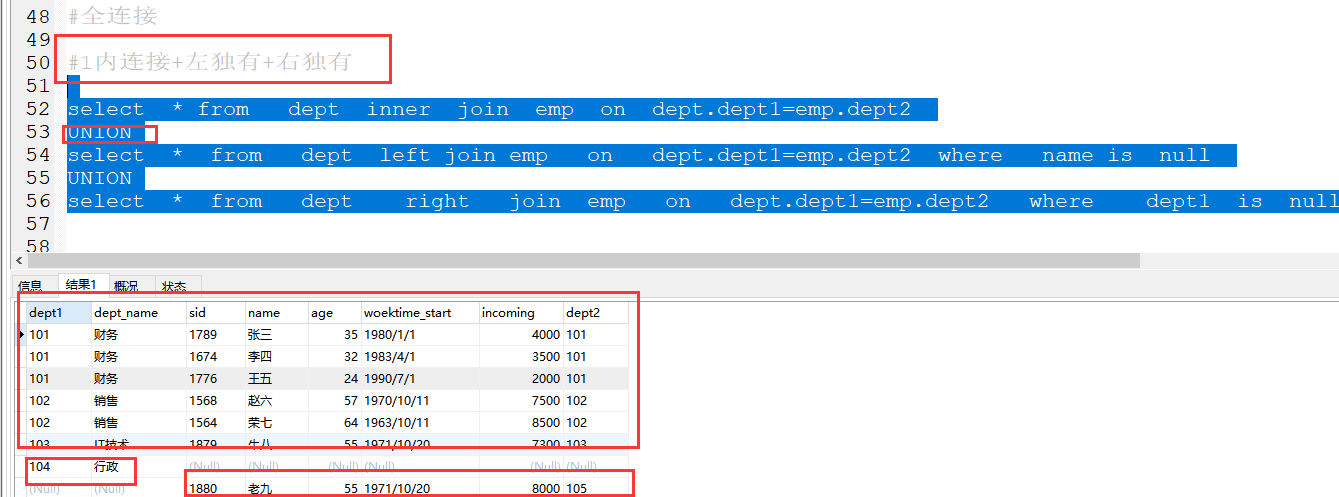
六、全外连接 (union)
1内连接+左独有+右独有
select * from dept inner join emp on dept.dept1=emp.dept2
UNION
select * from dept left join emp on dept.dept1=emp.dept2 where name is null
UNION
select * from dept right join emp on dept.dept1=emp.dept2 where dept1 is null;
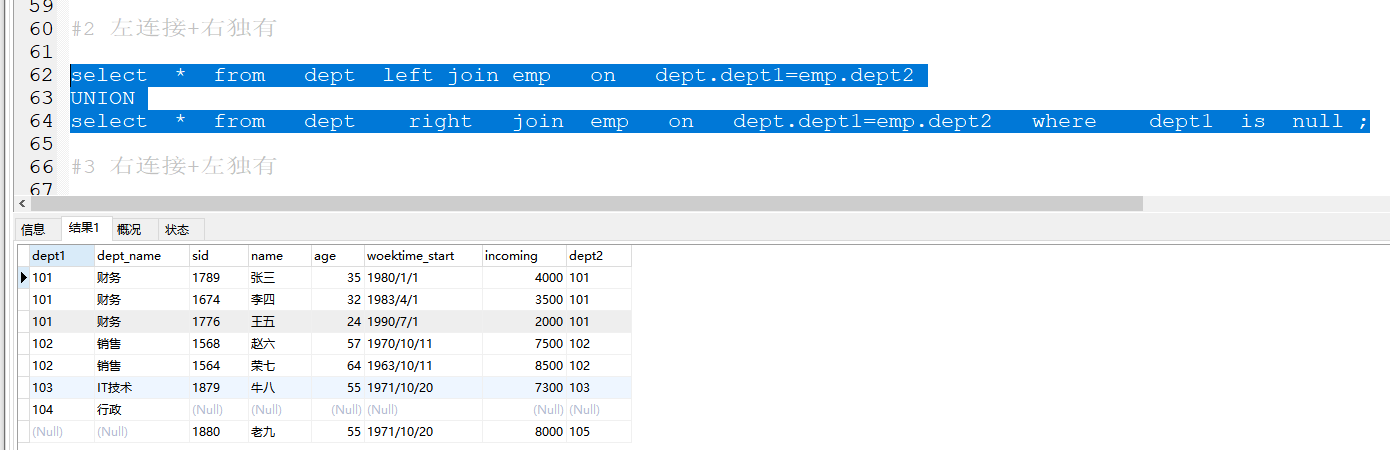
2 左连接+右独有
select * from dept left join emp on dept.dept1=emp.dept2
UNION
select * from dept right join emp on dept.dept1=emp.dept2 where dept1 is null ;
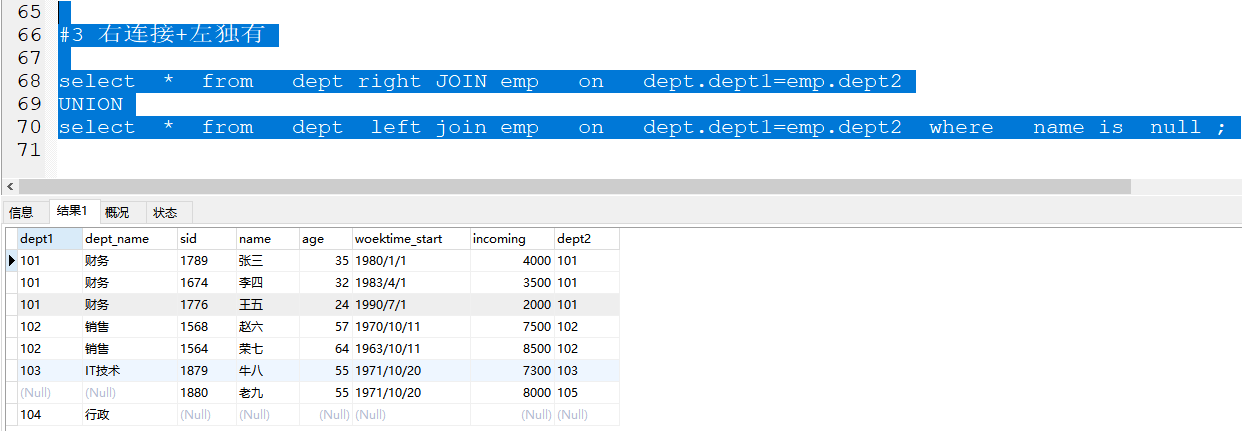
3 右连接+左独有
select * from dept right JOIN emp on dept.dept1=emp.dept2
UNION
select * from dept left join emp on dept.dept1=emp.dept2 where name is null ;
==============================================
总结:
多表:
普通内连接:select * from 表1 inner join 表2 on 表 1.关联字段=表2.关联字段
隐藏内连接:select * from 表1,表2 where 表 1.关联字段=表2.关联字段
左连接:select * from 表1 left join 表2 on 表 1.关联字段=表2.关联字段
右连接 :select * from 表1 right join 表2 on 表 1.关联字段=表2.关联字段
左独有数据:select * from 表1 left join 表2 on 表 1.关联字段=表2.关联字段 where 表2中的字段 is null
右独有数据:select * from 表1 right join 表2 on 表 1.关联字段=表2.关联字段 where 表1 中的字段 isnull
全外连接:union
(1)左独有+右独有+内连接
(2)左连接+右独有
(3)右连接+左独有
===================================================
1.列出每个部门的平均收入及部门名称;
结果:部门名称(dept_name),avg(incong)
条件:
group by dept_name
方法
select avg(incoming) ,dept_name from dept left join emp on dept.dept1=emp.dept2 group by dept_name ;
2.财务部门的收入总和;
emp: sum(incoming)
dept: dept_name="财务"
方法1:select sum(incoming) from dept INNER JOIN emp on dept.dept1=emp.dept2 where dept_name="财务" ;
方法2:
select a.dept_name,sum(incoming) from dept a join emp b on a.dept1=b.dept2 group by dept_name HAVING dept_name='销售';
3.It技术部入职员工的员工号
方法1:select sid from dept inner join emp on dept.dept1=emp.dept2 where dept_name="IT技术"

