
作业 20180925-3 效能分析
此作业的要求参见:https://edu.cnblogs.com/campus/nenu/2018fall/homework/2145
该作业git地址为:https://git.coding.net/fuj905/wf.git
作业:对上周作业中的功能4 (仅由文件重定向读入,不由控制台读入) 做效能分析
要求0: 以 战争与和平 作为输入文件,重读向由文件系统读入。连续三次运行,给出每次消耗时间、CPU参数。
使用命令行进入程序所在文件夹,输入如下命令:
ptime wf -s < war_and_peace.txt
2018.10.5 16:52时连续测试三次运行时间截图为:

消耗时间汇总:
| 第一次运行时间 | 0.952s |
| 第二次运行时间 | 1.099s |
| 第三次运行时间 | 0.966s |
| 平均运行时间 | 1.006s |
CPU参数: Intel(R) Core(TM) i7-4770K CPU @ 3.50GHz 3.50GHz
要求1 给出你猜测程序的瓶颈。你认为优化会有最佳效果,或者在上周在此处做过优化
一、 上周做过优化的地方
最初版本
text = text.replace('\r',' ').replace(' ',' ').replace('.',' ').replace(',',' ').replace('"',' ')
修改版本
for ch in '\r .,"':
text = text.replace(ch,' ')
此处是删除文档中的冗余字符(非单词部分),将冗余字符替换为空格可以使用replace()方法,但是反复replace()会比较浪费时间,修改版本则是将所有的冗余字符封装在一个字符串里,进行一个for循环,降低时间复杂度。
二、 猜测的瓶颈
1. 处理字符时遍历整个文档耗时较长
字符处理代码:
def dispose_words(string):
string = string.replace('\n',' ').replace(',',' ')
s1 = list(string)
num = len(s1)
s1.append(' ')
for i in range(num): # 遍历整个文档
if s1[i] in '."?\')-(;#$%&*!':
if str(s1[i-1].isalnum())=='True' and (str(s1[i+1].isalnum())== 'True'):
pass
else:
s1[i]=' '
for i in range(num):
if s1[i] in ':':
if s1[i+1]=='/':
pass
else:
s1[i]=' '
s = ''.join(s1)
return s
此处为去除冗余字符及保留特殊字符(例如网址)共有两次使用for循环遍历整个文档,对于大文件而言,比较耗时。考虑到上述工作在词频统计任务中是必须的,因此可以设置一个for循环,预计会节省时间。
2. 将所有单词分离并小写化时遍历整个文档耗时较长
分离、小写化所有单词代码:
def countWordsFrequency(text,flag):
text = dispose_words(text)
list1 = text.replace('\n',' ').lower().split()# list1保存小写化后的原始数据
此处考虑到句首的单词首字母会大写,为了统计相同的单词所以需要将所有单词分离并均转化为小写,故需要进行一个全文遍历后转为小写。lower()函数与split()函数需要进行一个全文遍历。但考虑到功能性,此处的遍历是必不可少的。
要求2 通过profile 找出程序的瓶颈。给出程序运行中最花费时间的3个函数或代码片段。
由于本程序作业使用Python语言,故在查阅资料之后使用cProfile进行效能分析。
效能分析步骤:
0. 使用命令行进入程序所在目录后输入以下命令:
python -m cProfile wf.py war_and_peace.txt
1.因为上述命令行得出的结果不够直观,故采用下述命令行进行分析:
python -m cProfile -s time wf.py -s < war_and_peace.txt
2. 得到分析结果如下:

其中:
ncalls:表示函数调用的次数;
tottime:表示指定函数的总的运行时间,除掉函数中调用子函数的运行时间;
percall:(第一个percall)等于 tottime/ncalls;
cumtime:表示该函数及其所有子函数的调用运行的时间,即函数开始调用到返回的时间;
percall:(第二个percall)即函数运行一次的平均时间,等于 cumtime/ncalls;
filename:lineno(function):每个函数调用的具体信息;
由测试结果可知:我的程序最耗时的函数为“dispose_words”(去除冗余字符),“countWordsFrequency”(统计词频)以及main函数,最耗时的代码段为“dispose_words”函数中的“split()”、“join()”方法。
其中耗时前三为:
1. “dispose_words”函数:调用1次,运行时间为0.442s。
2. “countWordsFrequency”函数:调用1次,运行时间为0.765s。
3. “split()”方法:调用1次,运行时间为0.047s。
代码如下:
1. “dispose_words”函数
#功能0:去除冗余字符
def dispose_words(string):
string = string.replace('\n',' ').replace(',',' ')
s1 = list(string)
num = len(s1)
s1.append(' ')
for i in range(num):
if s1[i] in '."?\')-(;#$%&*!':
if str(s1[i-1].isalnum())=='True' and (str(s1[i+1].isalnum())== 'True'):
pass
else:
s1[i]=' '
if s1[i] in ':':
if s1[i+1]=='/':
pass
else:
s1[i]=' '
s = ''.join(s1)
return s
2. “countWordsFrequency”函数
# 功能1:统计词频。
def countWordsFrequency(text,flag):
text = dispose_words(text)
list1 = text.replace('\n',' ').lower().split()# 保存原始数据
list2 = list(set(list1) ) # 去重之后的数据
if(flag == 0):
print("total " + str(len(list2)))# 小文本统计词汇量(功能1不输出words)
else:
print("total " + str(len(list2))+ " words")# 统计词汇量
print("\n")
dir1 = {} #计算频数
for str1 in list1:
if str1 != ' ':
if str1 in dir1.keys():
dir1[str1] = dir1[str1] + 1
else:
dir1[str1] = 1
dir2 = sorted((dir1).items(),key = lambda x:x[1],reverse = True) # 按照频数排序
if (len(dir2) > 30):
count = 10
else:
count = len(dir2)
for x in range(0,count):
print('%-10s %-10s' % (dir2[x][0],dir2[x][1])) #美化输出频数
3. “split()”方法
def countWordsFrequency(text,flag):
text = dispose_words(text)
list1 = text.replace('\n',' ').lower().split()# 保存原始数据
要求3 根据瓶颈,“尽力而为”地优化程序性能。
由cProfile分析结果可知:程序耗时最久的为“dispose_words”函数中的“split()”方法、“join()”方法、“lower()”方法、“replace()”方法、“isalnum()”方法,以及“countWordsFrequency”函数中的“keys()”方法。
考虑到上述功能在整个词频统计功能实现中无法避免的要进行遍历,结合要求1中的猜测,可以将“dispose_words”函数中的“isalnum()”方法与针对“/”的for循环放在一起,即只进行一次遍历。
修改代码如下:
for i in range(num): if s1[i] in '."?\')-(;#$%&*!': if str(s1[i-1].isalnum())=='True' and (str(s1[i+1].isalnum())== 'True'): pass else: s1[i]=' ' elif s1[i] in ':': if s1[i+1]=='/': pass else: s1[i]=' ' s = ''.join(s1)
要求4 再次profile,给出在要求1 中的最花费时间的3个函数此时的花费。
修改之后再次cProfile,测试结果见下图:
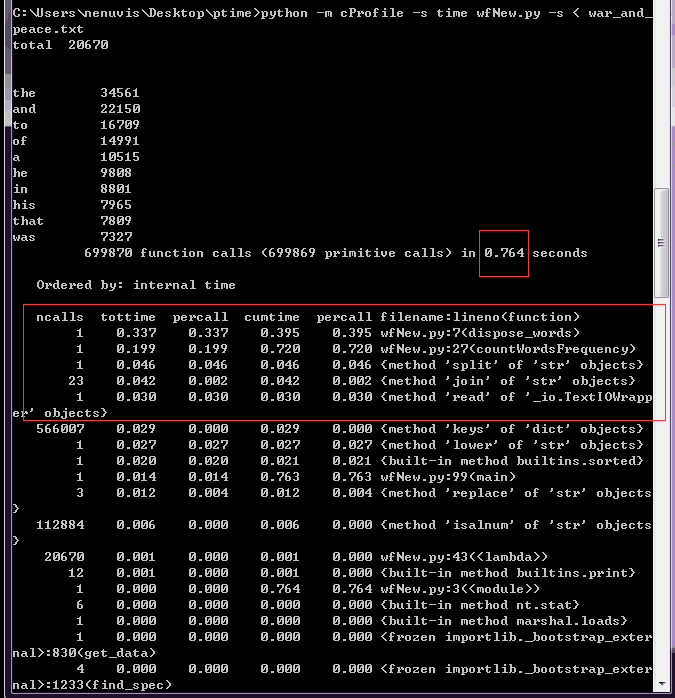
对比优化之前可知:
(1) “dispose_words”函数:依旧调用1次,运行时间由0.442s下降为0.395s。
(2) “countWordsFrequency”函数:依旧调用1次,运行时间由0.765s下降为0.720s。(此处虽未直接修改 “countWordsFrequency”函数,但其执行时会先调用 “dispose_words”函数,故运行时间会有所下降)
(3) “split()”方法:依旧调用1次,运行时间由0.047s下降为0.046s。
再次profile,2018.10.05 21:08连续测试三次运行时间(对应于要求0)结果见下图:


消耗时间汇总:
| 第一次运行时间 | 0.902s |
| 第二次运行时间 | 0.893s |
| 第三次运行时间 | 0.890s |
| 平均运行时间 | 0.895s |
CPU参数: Intel(R) Core(TM) i7-4770K CPU @ 3.50GHz 3.50GHz
对比可知:平均运行时间由1.006s下降为0.895s
要求5 程序运行时间。
等待教师的测评。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号