作业 20180918-1 词频统计
本作业的要求参见https://edu.cnblogs.com/campus/nenu/2018fall/homework/2126.
写在博客最前:
(1) 本项目使用Python语言。
(2) 本项目代码地址为:https://git.coding.net/fuj905/count_words.git
功能1 小文件输入。
重点/难点
(1) Python文件打包为.exe文件:
附上个人编写教程:http://www.cnblogs.com/fuj905/p/9696193.html
(2) 命令行参数:判断用户输入的参数是否含有含有"-s",若是,则执行功能1。
(3) 读取文件:使用Python语言的open函数,进行只读操作。
(4) 词频统计:重难点在于英文字符的去重与删除冗余字符。由于Word中严格按照空格来区分单词,因此将字符等替换为空格即可。去重则利用Python的字典对文章单词进行遍历,存储单词及频数。
重要代码展示
命令行参数:
if sys.argv[1]=="-s": countFileWords(sys.argv[2])
读取文件:
# 功能2:打开文件并计算词频 def countFileWords(filename): try: with open(filename,'r',encoding='UTF-8') as f_obj: content = f_obj.read() countWordsFrequency(content) except FileNotFoundError: #抛出异常 msg = "sorry,the file " + filename + " does not exist." print(msg)
删除冗余字符与计算词频:
def countWordsFrequency(text):
for ch in '\r .,"':
text = text.replace(ch,' ')
list1 = text.replace('\n',' ').lower().split()# 保存原始数据
list2 = list(set(list1) ) # 去重之后的数据
print("total " + str(len(list2)))# 统计词汇量
dir1 = {} #计算频数
for str1 in list1:
if str1 != ' ':
if str1 in dir1.keys():
dir1[str1] = dir1[str1] + 1
else:
dir1[str1] = 1
dir2 = sorted((dir1).items(),key = lambda x:x[1],reverse = True) # 按照频数排序
if (len(dir2) > 30):
count = 10
else:
count = len(dir2)
for x in range(0,count):
print(dir2[x][0]+" " + str(dir2[x][1]))
执行效果截图
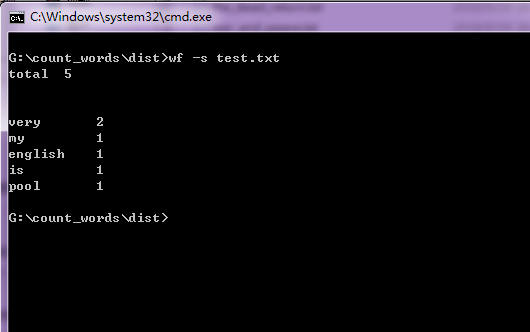
得意、突破、困难的地方
删除冗余的字符:按照杨老师提供的测试样例,确定了删除冗余字符的算法,即替换 \r .,"(软空格、空格、点、逗号、双引号)为空格。在删除时对字符进行遍历,看是否属于以上冗余字符,若是,则替换。避免了反复执行replace()方法,实现了代码的简洁。
去重方法:在功能1实现之前,反复纠结于如何去重,因为计算所得total始终与Word中不一致,后来经过微信群中其他同学与老师的沟通得知,只需计算不同字符的数目,故只需将文章内容存储在list之后取set即可(set不包含重复元素)。同时对于Word计数问题,我也曾多次与同学沟通或在微信群与教师交流,最终终于明白计数方法,因此“沟通要在正式投入工作之前”也算是这个功能的一个收获。
功能2 支持命令行输入英文作品的文件名。
重点/难点
(1) 命令行参数:判断用户输入的参数,当它不是"-s",且不是文件夹时,执行功能2。
(2) 读取不包含后缀的文件:读入用户输入的用户名,在用户名后加上".txt"的后缀。此时新的文件名(含后缀)即相当于功能1中要求的文件名。
重要代码展示
命令行参数:
inputfile=sys.argv[1]+'.txt' countFileWords(inputfile)
执行效果截图
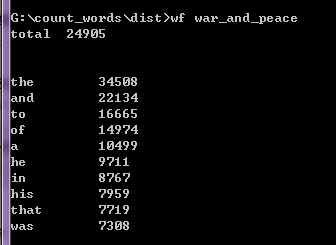
得意、突破、困难的地方 :
在用户给定参数之后,补全用户名则进入执行功能1的函数之中,简化代码。
功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。
重点/难点
(1) 命令行参数:首先判断用户当前输入是否为文件夹,由于Python语言可以直接判断当前文件是否含有子文件(即是否为文件夹),故在此处可进行一个判断。判断过后遍历该文件夹下所有后缀为txt的文件,并将其文件名存储在列表之中。
重要代码展示
命令行参数:
elif str(os.path.exists(sys.argv[1]))=='True': getFileName(sys.argv[1])
展示文件夹下所有txt文件:
#打开当前程序所在目录下的文件夹
def getFileName(folderName):
path = os.listdir(os.getcwd())#获取当前目录下所有文件
folderList = []
for p in path:
if os.path.isdir(p):#找到所有文件夹
#print(p)#打印文件夹名字
folderList.append(p)
textFolder = folderName
fileNameList = []
for folder in folderList:
#print("all folders " + folder)
if textFolder == folder:
path1= os.listdir(folder)#该文件夹下所有文件建成列表
#print(path1)#打印文件夹下所有文件名字
for i in path1:
if os.path.splitext(i)[1] == '.txt':
print(os.path.splitext(i)[0])
fileNameList.append(os.path.splitext(i)[0])
对于已存在的文件名进行字频统计:
for filenames in fileNameList: filename = input() #if filename == filenames: countFileWords(filename + ".txt")
执行效果截图
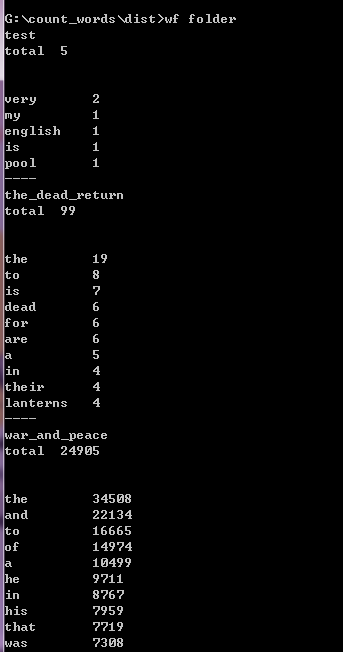
得意、突破、困难的地方
分离文件名与后缀:
if os.path.splitext(i)[1] == '.txt': print(os.path.splitext(i)[0])
使用splitext()函数分离,若后缀为txt,则保存文件名至列表。
功能4 重定向 (暂未实现)
重点/难点
(1) 对于重定向的理解:通过各种方法将各种网络请求重新定个方向转到其它位置。对于本题目而言,用户输入文件名或者文本内容,利用Python语言的input()函数即可捕获,类似于C语言的scanf()。
重要代码展示
执行效果截图
得意、突破、困难的地方
PSP:功能实现及测试PSP
| PSP阶段 | 预计花费时间(min) | 实际花费时间(min) | 分析时间差原因 |
| 功能一实现 | 60 | 168 | 功能一花费的大部分时间在于思考如何去除冗余的字符,筛选非单词,例如it's中的单引号不可去除,浪费时间过久。但最后实践证明,积极地与老师进行沟通才是解决问题一个行之有效的方法。这也给我以后的作业提了个醒,主动沟通。 |
| 功能一测试 | 15 | 36 | 测试的时间主要在于一开始不会使用控制台输入参数,加上Python语言学习时间不久,因此浪费了大量的时间。很多的函数仗在依靠老师是靠脚本测试的准确性上,并没有捕获异常。这也给测试工作带来了无穷多的浪费时间。 |
| 功能二实现 | 120 | 203 | 功能二本身的实现并不难,主要是自己一开始不理解type参数的意思,以为功能一是输入一个字符串并计算词频,因此没有利用代码复用将功能一、二结合起来。所以花费了大量的时间。 |
| 功能二测试 | 30 | 85 | 同功能一测试。 |
| 功能三实现 | 120 | 176 | 功能三的主要难点在于文件夹操作。Python语言的文件夹操作从未接触过,因此算是边做边学,边学边做,所以也浪费了比较多的时间。 |
| 功能三测试 | 30 | 57 | 同功能一测试。 |
| 功能四实现 | 120 | 24 | 功能四只是投入一点时间了解了重定向,对于代码和功能的实现一直没有思路,因此功能四也未能实现。 |
| 功能四测试 | 30 | 0 | 功能四未测试。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号