SqlServer 多叉树字典表设计最佳实践探索
多叉树
在字典表设计中,常常需要存储树形结构的数据。
比如:国家、省、市、区县,公司部门信息等。
每一个节点下面的子节点数量是不确定的,这类的树我们称之为多叉树(N-ary Tree)
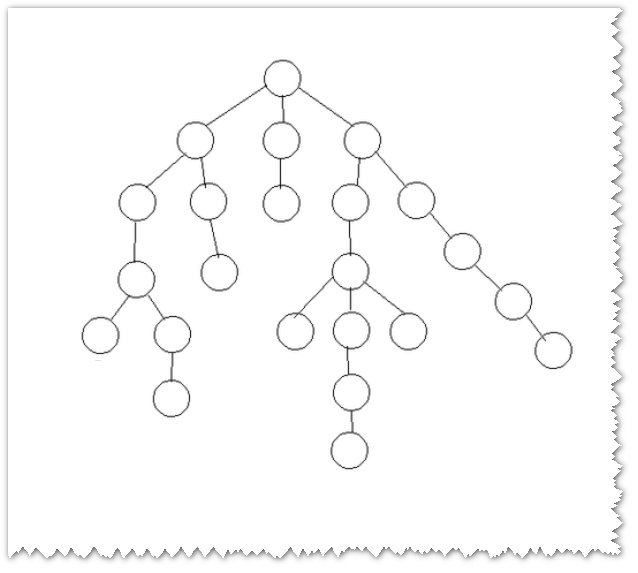
本文将以如何在字典表中存储省、市、区县数据为目标,探讨多叉树字典表设计最佳设计方案。
设计需求
我们设计的字典表需要满足以下需求:
a、支持查询任意层级的所有子级
b、支持查询任意层级的所有上级
c、支持分布式存储
d、数据安全,防止碰撞攻击
e、支持增、删、改、查
f、支持同级节点排序
设计思路
程序员们首先想到的是在字典表中增加ParantId列,指向该节点父级的Id。这种设计方式我们称之为“邻接表”。
但这样的设计有个弊端:满足a、b两个需求较为复杂,因为我们必须利用代码或者Sql语句实现递归。网上其他文章中还提到了路径枚举、嵌套集、闭包表等设计方案。接下来本文提供两种相对优秀的设计方案供参考。
方案一、范式设计(双表方案)
字典表+闭包表+ParantId+路径枚举
适用范围
这种设计是一种比较标准的、符合范式的设计方案。
它的适用范围是在无法确定某个节点下有多少个子节点。
如果我们无法评估整个字典表下所有节点究竟可能出现多少个子节点,这种情况下比较适用。
优点
a、支持查询任意层级的所有子级
b、支持查询任意层级的所有上级
c、支持分布式存储
d、数据安全,防止枚举攻击
e、支持增、删、改、查
f、支持同级节点排序
g、支持无限节点层级存储、节点数量没有限制
缺点
a、对程序员水平要求更高,维护字典表和闭包表代码有难度且不能有错
b、多了一张闭包表,维护闭包表数据有额外工作量和数据库开销
c、查询相对复杂,需要联表
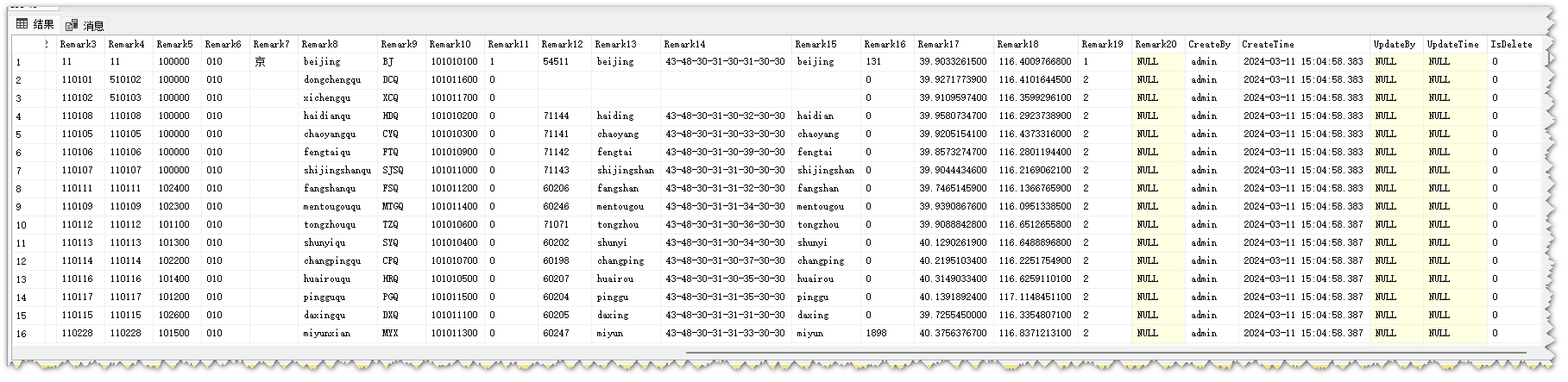
D_Dictionary_FirstPlan字典表设计图
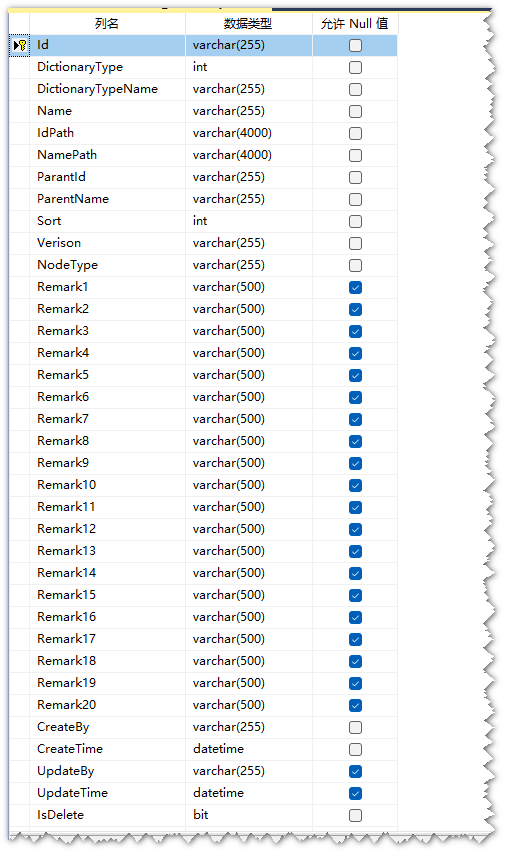
D_Dictionary_FirstPlan字典表模型图
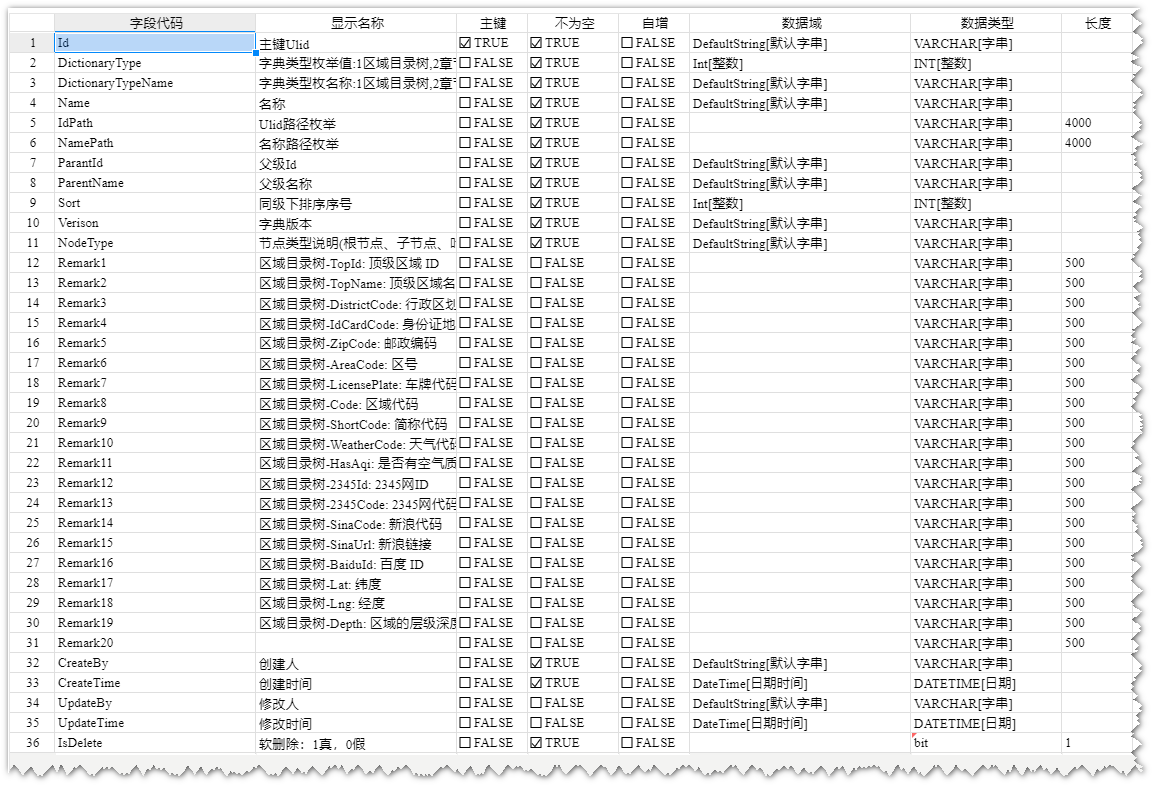
D_Dictionary_FirstPlan字典表数据展示
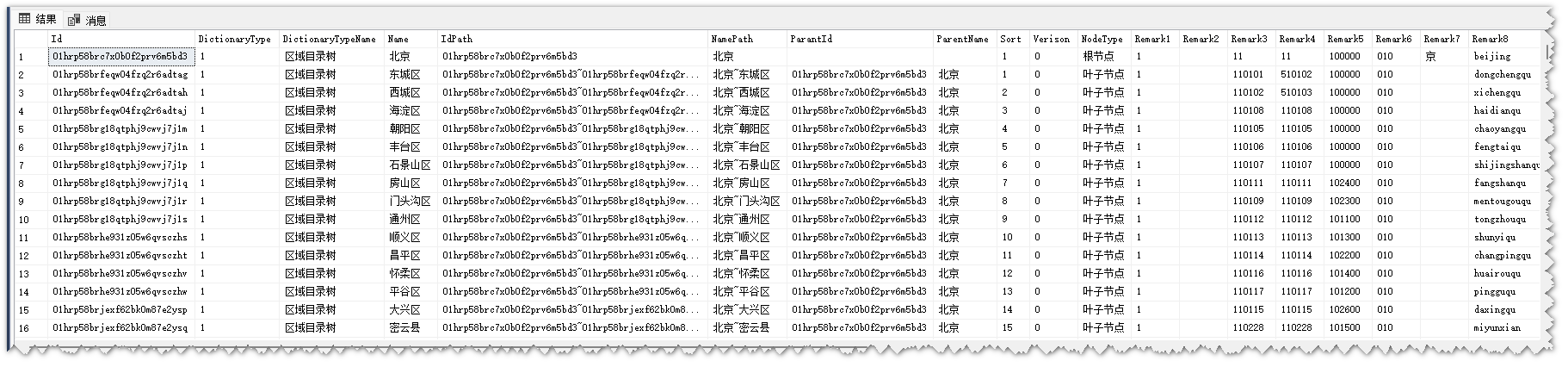
D_Dictionary_FirstPlan_Closure闭包表设计图
D_Dictionary_FirstPlan_Closure闭包表模型图

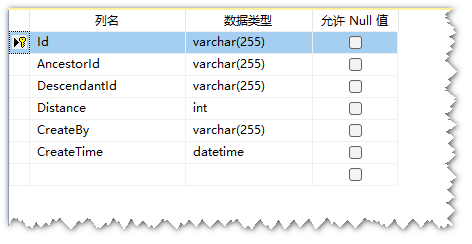
D_Dictionary_FirstPlan_Closure闭包表介绍
闭包表存储的是D_Dictionary字典表所有上下节点之间的关系,是所有祖先节点和子节点的关系。比如父节点-子节点,祖先节点-孙子节点....
D_Dictionary_FirstPlan_Closure闭包表数据展示
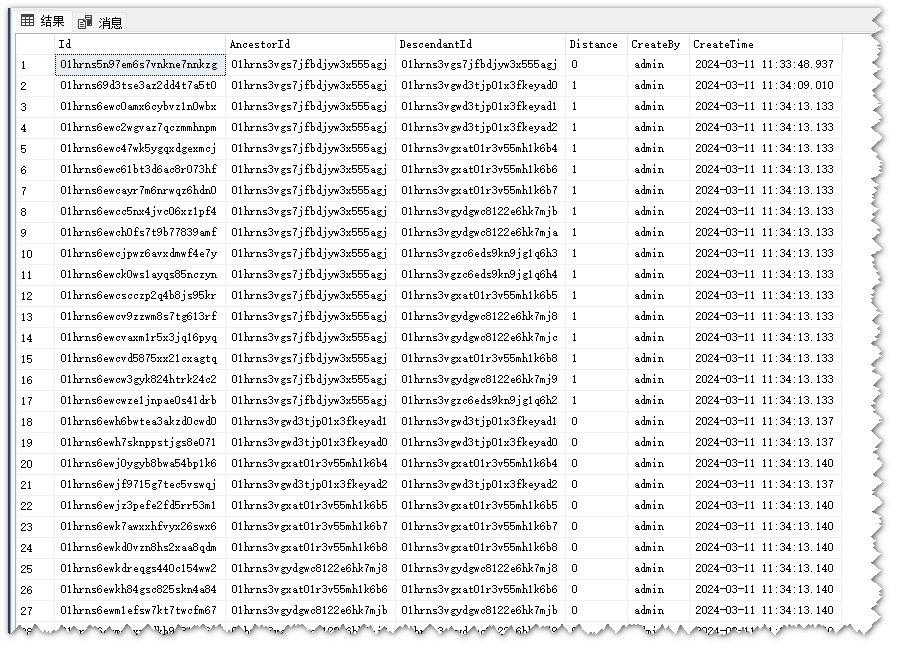
查询演示
查询所有安徽省的下级
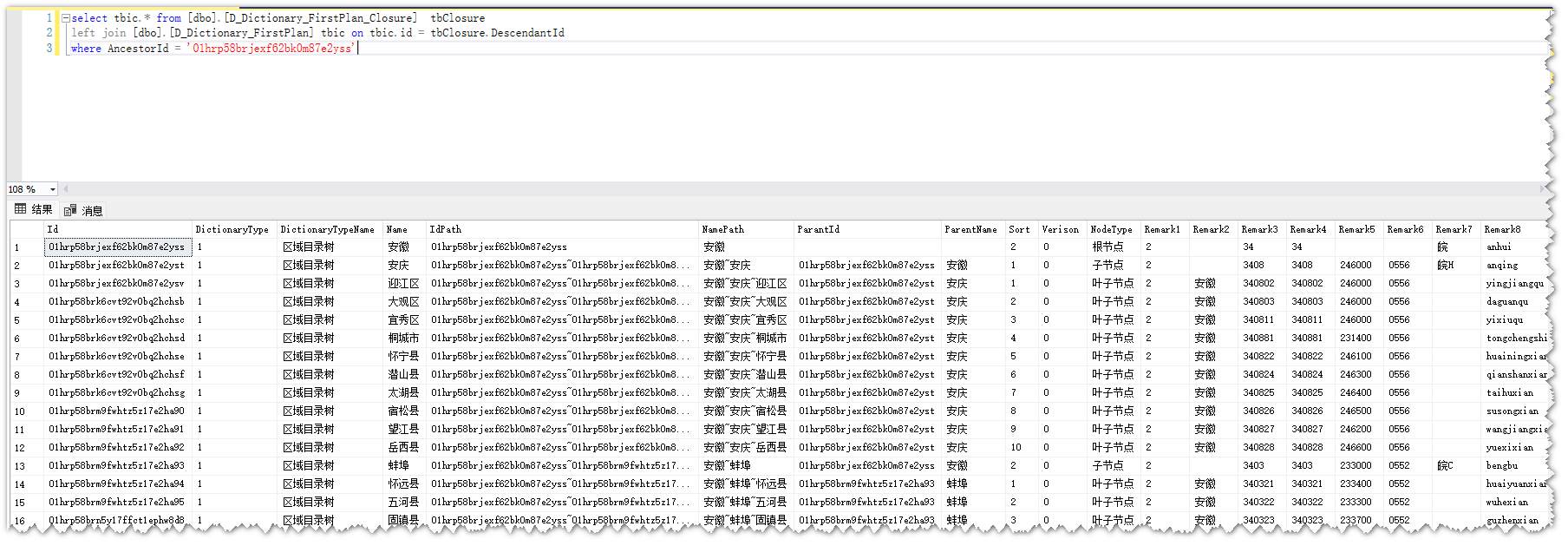
查询怀远县所有上级

方案二、反范式设计(单表方案)
字典表+Code编码+ParantId+路径枚举
适用范围
这种设计是一种极大提高查询速度和减少查询复杂度的方案。
但是这种设计有一定的前提条件,设计者必须确定字典表最多子节点数量。
如果我们明确知道整个字典表下所有节点都不超过8999个子节点,则方案二比较适用。
优点
a、支持查询任意层级的所有子级,高效,查询简单
b、支持查询任意层级的所有上级,高效,查询简单
c、支持分布式存储
d、数据安全,防止碰撞攻击
e、支持增、删、改、查
f、支持同级节点排序
g、支持无限节点层级存储、节点数量没有限制
缺点
a、每个节点最多支持8999个字节点(但可以通过拓展Code范围解决)
D_Dictionary字典表设计图

D_Dictionary字典表模型图
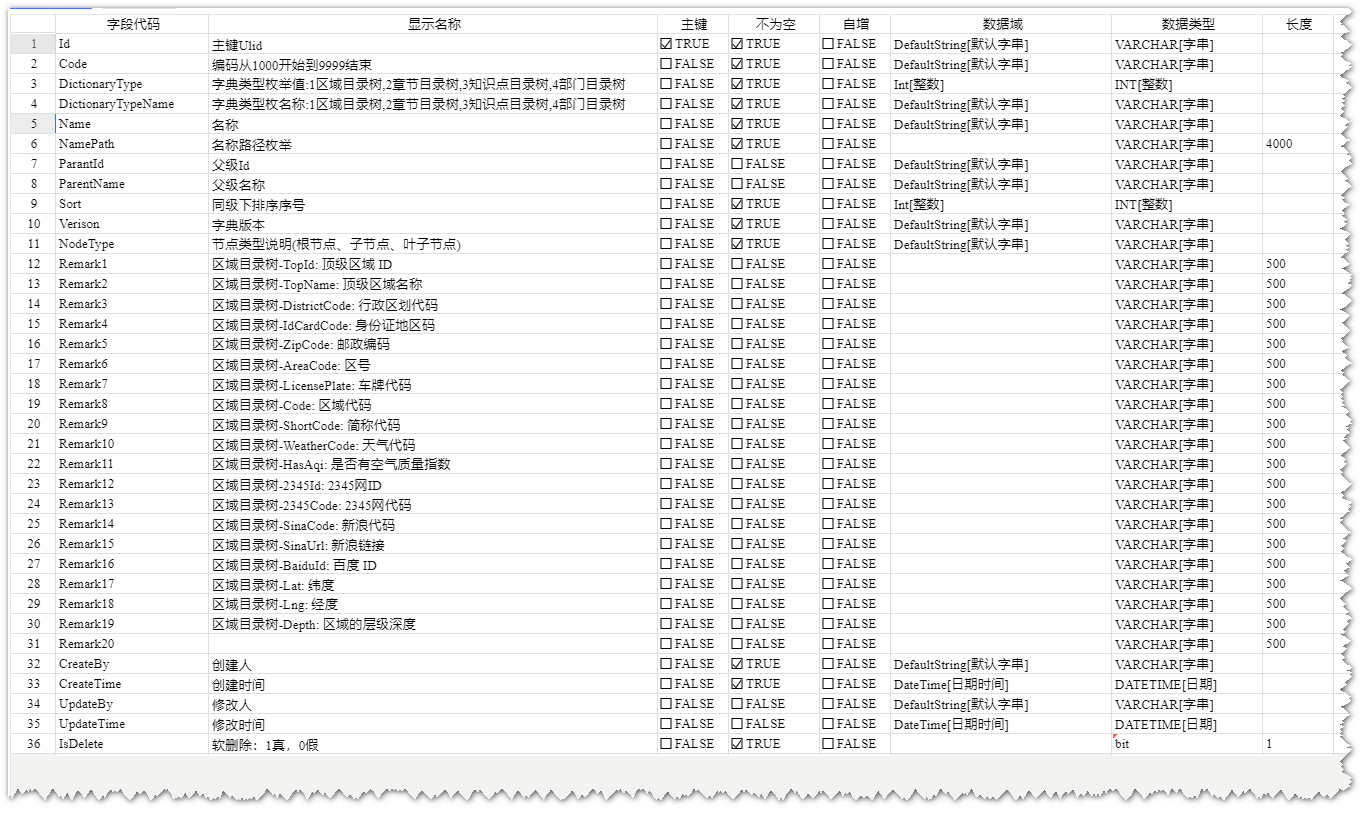
D_Dictionary字典表数据展示
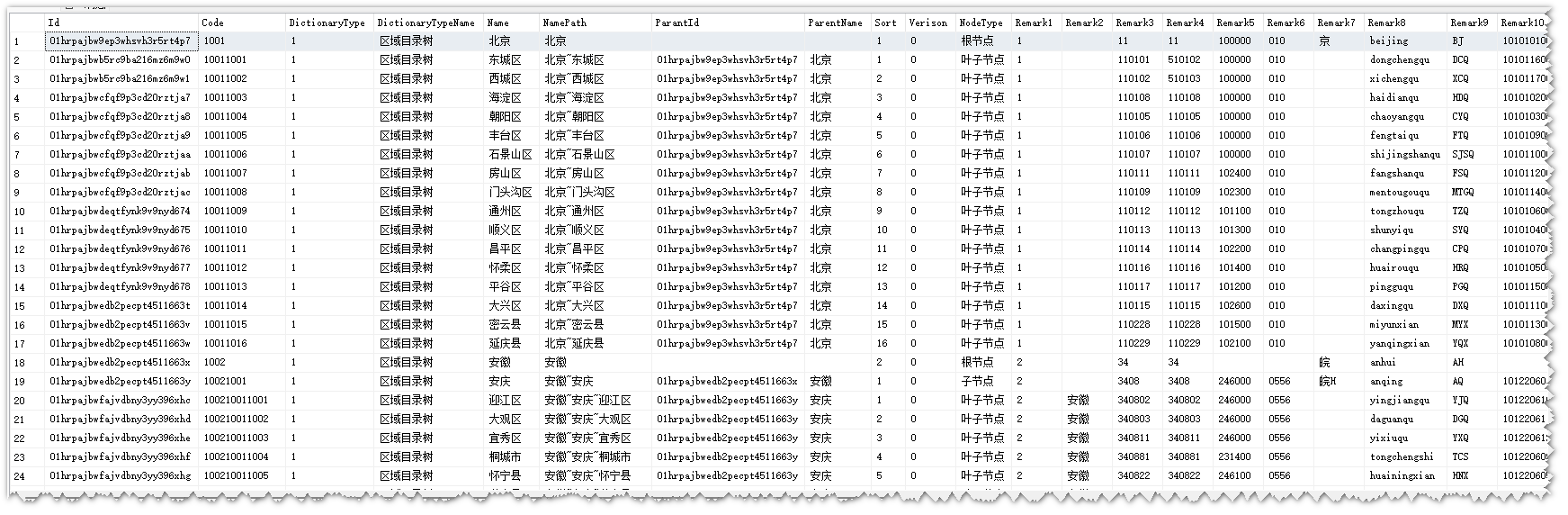
D_Dictionary字典表Code介绍
Code从1001开始编码,最多支持到9999。
例:安徽:1002 安徽~安庆:10021001 安徽安庆迎江区:100210011001
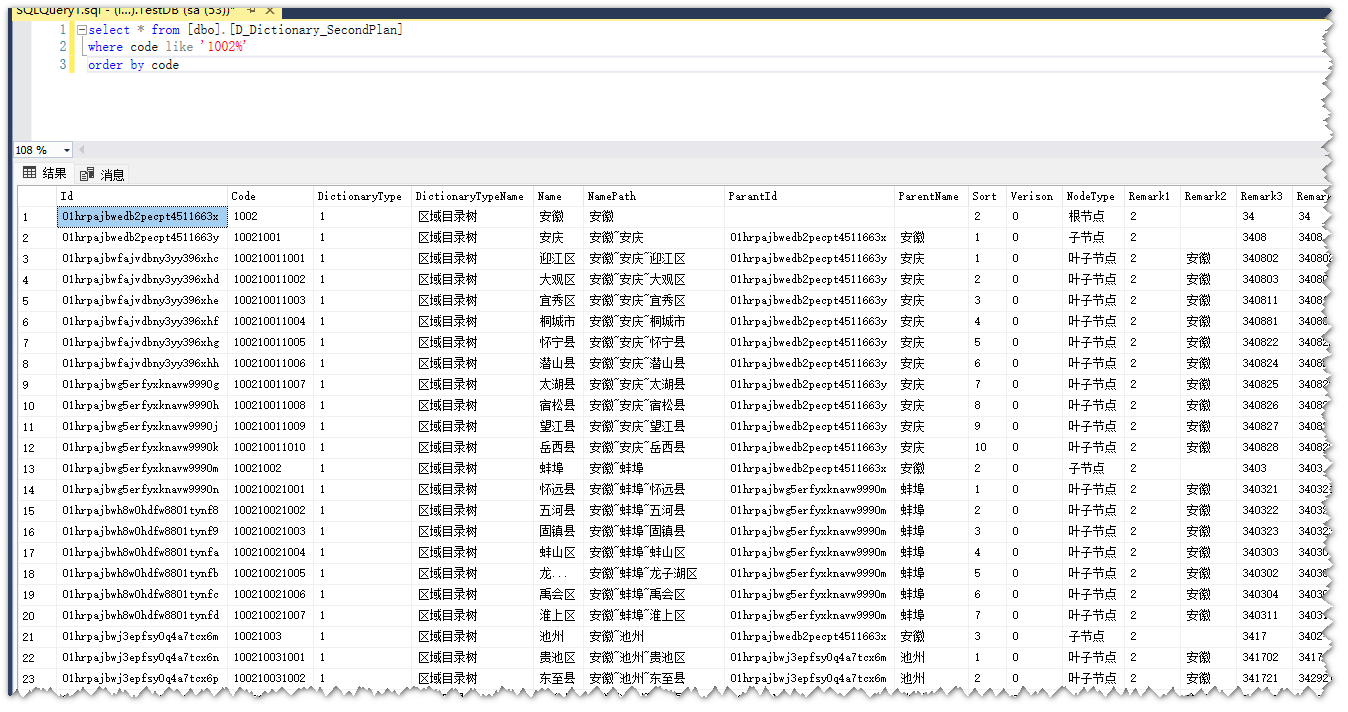
查询演示
查询所有安徽省的下级
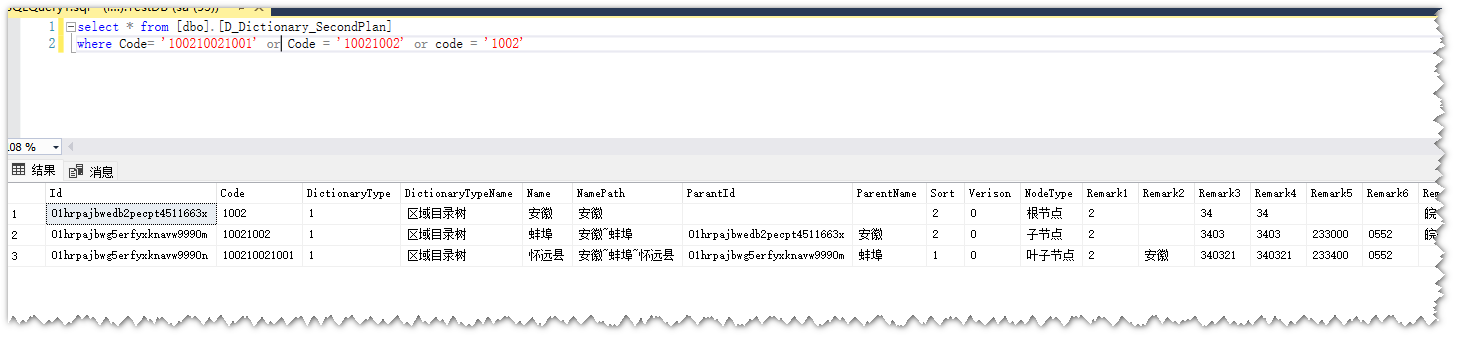
查询怀远县所有上级
生成Ulid的库:
https://github.com/Cysharp/Ulid
https://github.com/RobThree/NUlid
推荐:https://github.com/RobThree/NUlid
//参考代码
var rng = new MonotonicUlidRng();
Ulid.NewUlid(rng).ToString().ToLower();
Ulid作为主键遗留问题
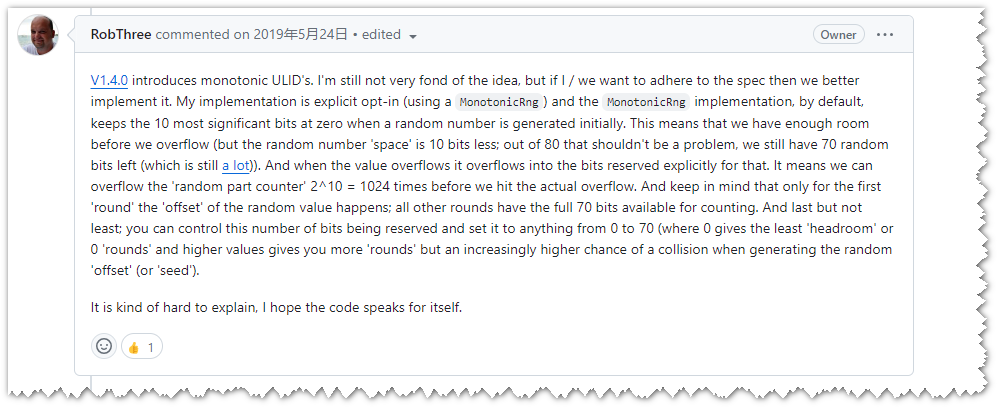
NUlid库:
支持单机单位毫秒自增,(分布式、多线程、时间回退情况下尚未测试)
https://github.com/ulid/spec/issues/11

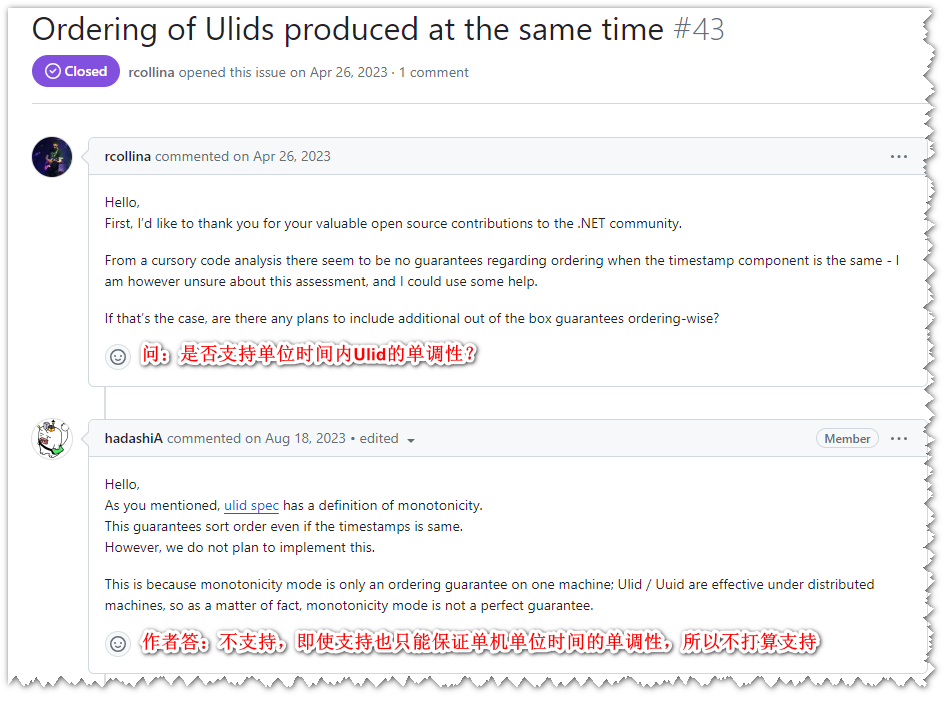
Ulid库:
单机和分布式都不支持单位毫秒内自增

 浙公网安备 33010602011771号
浙公网安备 33010602011771号