
图1
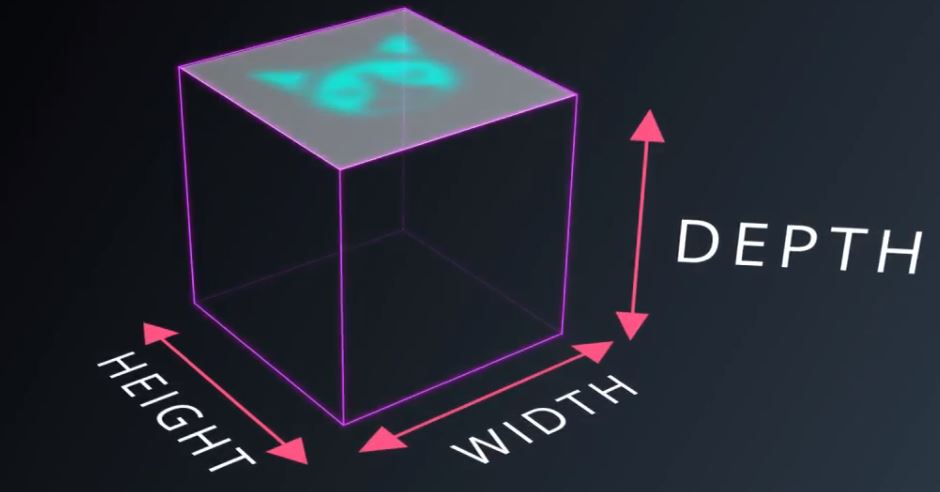
一张图片有宽和高图1,且通常一幅图像是由红绿蓝三色通道,所以它还有深度信息图2。

图2 深度为3
现在假设拿出图片的一小块,运行一个具有K个输出的小神经网络,像图3一样把输出表示为垂直的一小列
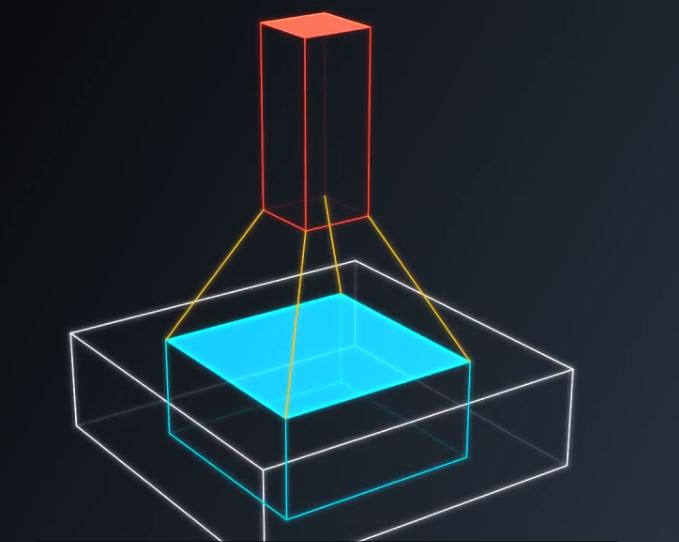
图3
在不改变权重的情况下,把这个小神经网络滑过整个图片,就像我们拿个涮子一样水平垂直地滑动。图4,5,6
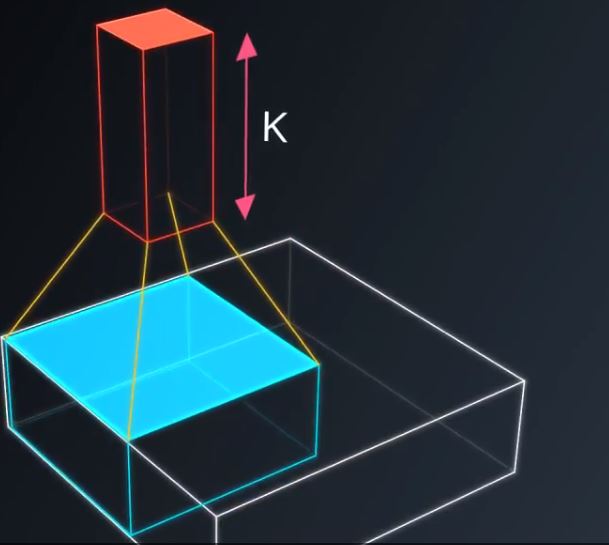
图4
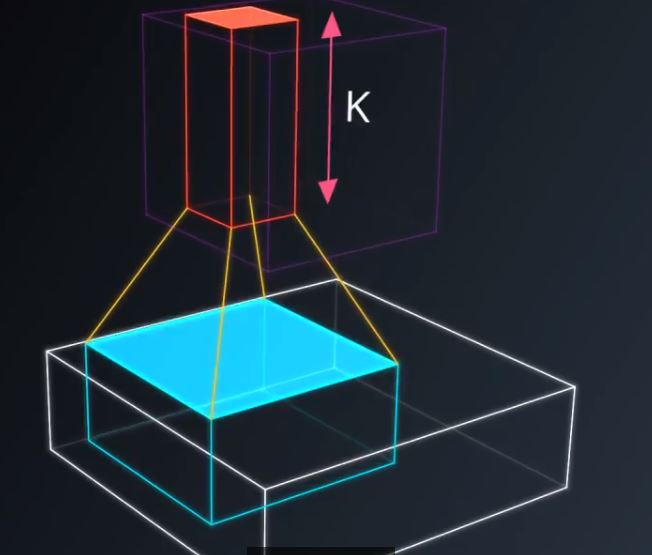
图5
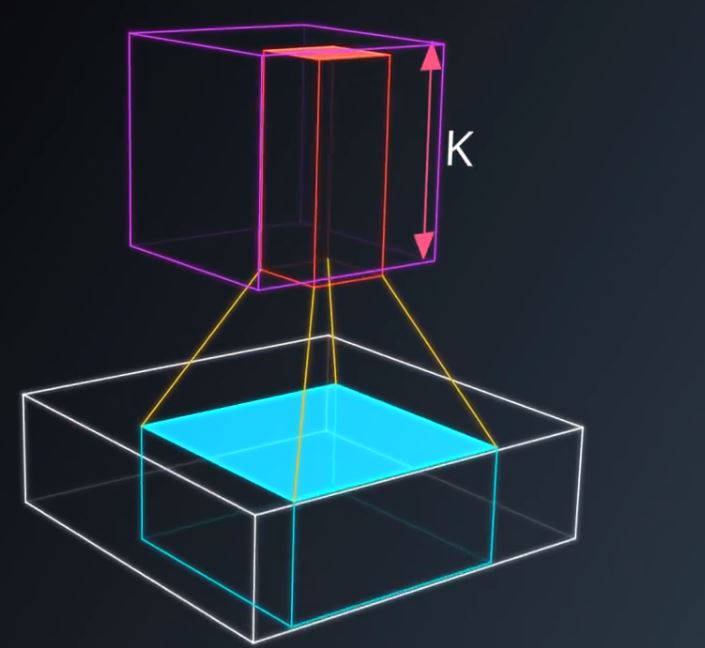
图6
在输出端我们得到一幅新的图片,它的宽度和高度与输入不同,更重要的是他的深度和之前不同,而是得到了k个颜色通道图7。这种操作叫做卷积。
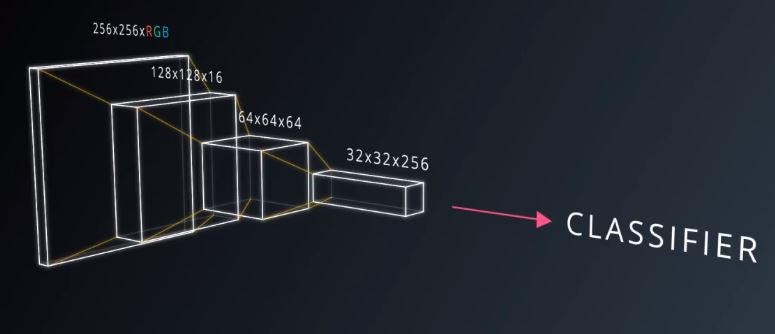
卷积网络基本上是一个深度网络,但我们用共享权重的“卷积层”替代了“全连接层” 。总的想法是让它们形成金字塔形状。图8
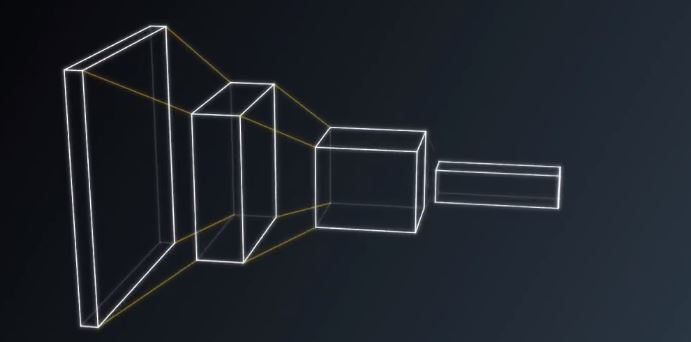
图8
金字塔底部是一个非常大而浅的图片,仅包含红绿蓝三通道。通过卷积操作逐渐挤压空间的纬度。
同时不断增加深度,使深度信息大体上可以表示出复杂的语意。图9

在金字塔的顶端,你可以放一个分类器。所有的信息被压缩成一个表示仅映射到图片,内容的参数被保留。图10
块(PATCH)的概念和深度(DEPTH)的概念.块有时也叫做核 图11
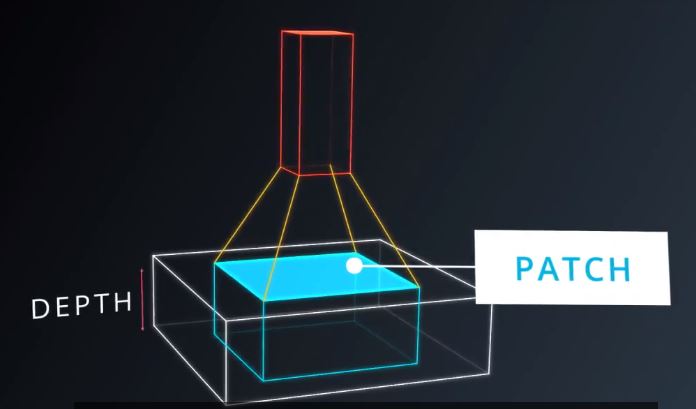
图11
堆栈中每一个薄饼叫做特征图,图12
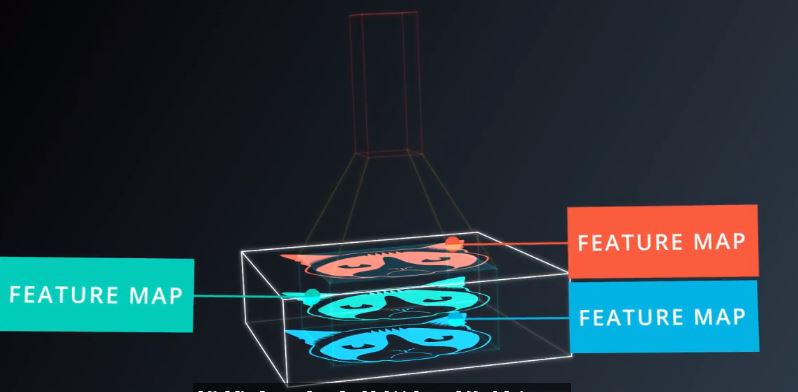
图12
这里你将三个特征图映射到K个特征图。图13
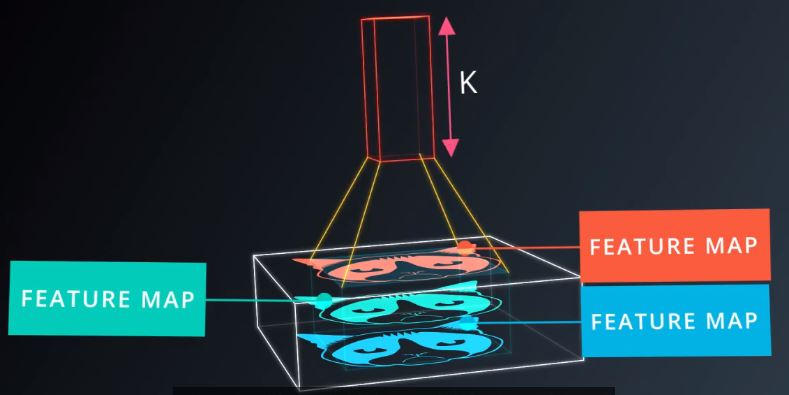
图13
还需要知道一个术语叫 “步幅”(stride),他是你移动过滤器时平移的像素数量。步幅为1时,输出的尺寸和输入大体相同。图14
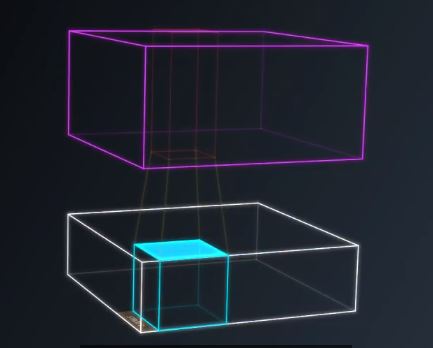
图14
步幅为2时,尺寸为原来的一半。图15
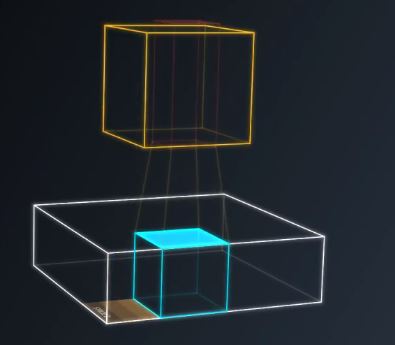
图15
大体是因为输出的尺寸取决于你在图像边界上咋样处理。要么你从不超过边界,它通常称为有效填充。(valid padiding)图16
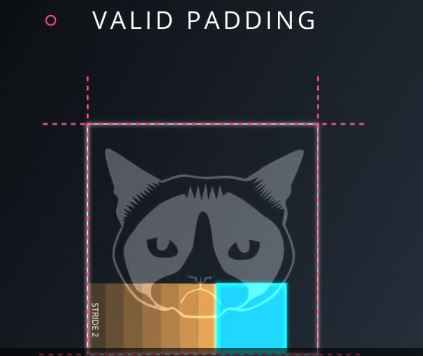
图16
要么你在边界外使用0填充,这样你会得到和输入图相同大小的输出图。称为相同填充,(same padding)图17
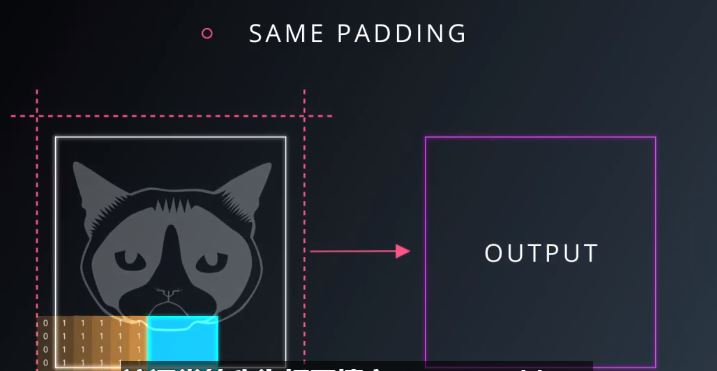
图17

 浙公网安备 33010602011771号
浙公网安备 33010602011771号