白天和夜晚分类
你正在努力建立分类器!你知道如何分析给定图像中的颜色和亮度,而这种技能本身可以帮助你区分不同的交通标志。
现在,我要给你一个分类挑战。如果我要求你分类两种类型的图像,在白天或晚上太阳落山的时候拍摄的,我希望你把这些图像分成两类:白天或夜晚。

同一场景的白天和夜晚的例子
这实际上是无人驾驶车的重要分类挑战。这些车辆需要知道它们正在什么样的环境条件下驾驶,以便能够在任何时间安全地驾驶,并且仍然可以识别其他车辆和周围的物体,无论外面是夜晚还是白天!
我们将一起分析每个分类步骤,但你认为创建白天和夜晚图像分类模型的第一步是什么?
在分类任何一组图像之前,你必须看看它们! 可视化你正在处理的图像数据,是识别图像数据中的任何图案,并能够预测数据的第一步!
标签
标签是附加到特定图像上的标记,它能向你提供这张图像的相关信息。在本节课中,我们将为每张图像添加标签。这些标签将图像数据分为不同类,而这些类就像一般类别。
对于我们的日/夜图像,我们有两个标签:“日”和“夜”。
我们为什么需要标签?
你 可以分辨图像是夜晚还是白天,但电脑不能,除非我们用标签来明确告诉它!
当我们测试分类模型的准确性时,这变得尤为重要。
一个分类器接受一个图像作为输入,并应输出一个predict_label,告诉我们该图像的预测类。 现在,当我们加载数据时,就像你所看到的那样,我们加载所谓的 true_labels,它们是图像的 correct 标签。
为了检查分类模型的准确性,我们比较了预测标签和真实标签。如果真实和预测的标签匹配,那么我们已经正确地分类图像!有时标签不匹配,这意味着我们错误地分类了图像。

一个错误的图像的例子。 true_label 是 “day”,而 predict_label 是 “night”。
精确性
在查看许多图像之后,分类器的准确度被定义为正确分类的图像的数量(predicted_label 匹配真实标签的数量)除以图像的总数量。这也就是说,假设我们试图分类 100 张图像,并正确分类了 81张。我们的准确性为 0.81 或 81%!
只有当拥有这些预测和真实标签来进行比较时,我们才能让计算机检查分类器的准确性。我们也可以从分类器所犯的任何错误中学习,这一点我们将在本节课的后面学习。
数字标签
与使用字符串或分类标签相比,使用数字标签是很好的做法,因为它们更容易跟踪和比较。所以,对于这个日/夜图片二进制类的例子,我们不采用“日”和“夜”的标签,而是使用数字标签:0 为夜晚,1 为白天。
你已经熟悉了日/夜图片的数据,并且知道了标签是什么,以及为什么使用它们。现在你准备好接下来的工作了,我们将建立一个完整的分类流程!
先思考一下,我们将采取什么步骤来分类这些图像。
有区别和可衡量的特征
当你接受分类挑战时,你可能会问自己:我怎样才能把这些图像分开来呢?这些图像有什么特点可以区分,我如何编写代码来识别它们的差异。除此之外,我怎么才能忽略这些图像中不相关或者过于相似的部分呢?
你可能已经想到了许多显着特征:一般来说,白天图像比夜晚图像要亮得多。夜晚图像也有这些非常明亮的小点,所以整个图像的亮度变化比白天图像大很多。白天图像中有更多的灰色/蓝色调色板。
有很多可衡量的特征可以区分这些图像,而这些可衡量的特征被称为特征。
在理想情况下,特征,也即图像或对象可测量的组成部分在不同条件下是独特和可识别的,比如在不同的光线或摄像机角度下。接下来我们会了解更多关于特征的信息。
标准化和预处理
但是我们正在超越自我!要提取图像的特征,我们必须进行预处理和标准化!
因此,在提取特征之前,我们先学习标准化的步骤。
数值与分类
让我们多了解一些标签。在可视化图像数据之后,你会看到每个图像都有一个附加的标签:“日”或“夜”,这些被称为分类值。
分类值通常是表示关于图像各种特征的文本值。几个例子是:
- 某个“动物”变量,其值为“猫”、“老虎”、“河马”和“狗”。
- 某个“颜色”变量,其值为“红色”、“绿色”和“蓝色”。
每个值代表不同的类别,大多数收集的数据都以这种方式标记!
这些标签对于我们来说是描述性的,但对于分类任务可能是低效的。许多机器学习算法没有;他们要求所有的输出都是数字的。数字很容易比较和存储在内存中,为此,我们经常需要将分类值转换为数字标签。你会遇到两种主要的方法:
- 整数编码
- 独热编码
整数编码
整数编码意味着为每个类别赋值一个整数值。所以,day = 1 和 night = 0。这是分离二进制数据的好方法,并且是我们为昼夜影像所做的。
独热编码
当有两个以上的值分开时,经常使用独热编码。一个热门标签是一个一维列表,是类的数量的长度。假设我们正在看动物变量,其值为“猫”、“老虎”、“河马”和“狗”。这个类别有四个类,所以我们的一个独热编码将是一个长度为四的列表。该列表将全部为 0 和 1;1 表示某个图像是哪一类。
例如,由于我们有四个类(猫、老虎、河马和狗),我们可以按照这个顺序给出一个列表:[猫值、老虎值、河马值、狗值]。一般来说,顺序无关紧要。
如果我们有一张图像,它的独热编码是[0, 1, 0, 0],这是什么意思?
按照[猫值、老虎值、河马值、狗值]的顺序,这个标签表明这是一头老虎的形象!再举一个例子,标签[0, 0, 0, 1]呢?
日夜图像分类器
日夜图像数据集由200个RGB彩色图像组成,分为两类:白天图像和夜晚图像。每个例子都有相同的数字:100个日图像和100个夜图像。
我们希望建立一个分类器,可以把这些图像准确地标记为白天或黑夜。要完成这个任务,我们需要找出这两种图像之间的显著性特征!
注:所有图像都来自 AMOS 数据集 (众多户外场景档案)。
导入资源
在开始使用项目代码之前,请导入你需要的库和资源。
import cv2 # computer vision library import helpers import numpy as np import matplotlib.pyplot as plt import matplotlib.image as mpimg %matplotlib inline
训练并测试数据
200张日/夜的图像被分成训练和测试数据集。
- 这些图像中的60%是训练图像,供你在创建分类器时使用。
- 另外40%是测试图像,将用于测试分类器的准确度。
首先,我们设置一些变量来跟踪图像的存储位置:
image_dir_training: the directory where our training image data is stored image_dir_test: the directory where our test image data is stored
# Image data directories image_dir_training = "day_night_images/training/" image_dir_test = "day_night_images/test/"
加载数据集
前几行代码将加载训练日/夜图像,并将它们全部存储在变量IMAGE_LIST中。 该列表包含图像及其相关标签(“日”或“夜”)。
例如, IMAGE_LIST 中的第一个图像标签对可以通过索引
# Using the load_dataset function in helpers.py # Load training data IMAGE_LIST = helpers.load_dataset(image_dir_training)
1. 可视化输入图像
# Print out 1. The shape of the image and 2. The image's label # Select an image and its label by list index image_index = 0 selected_image = IMAGE_LIST[image_index][0] selected_label = IMAGE_LIST[image_index][1] # Display image and data about it plt.imshow(selected_image) print("Shape: "+str(selected_image.shape)) print("Label: " + str(selected_label))

2. 预处理数据
在每张图像中进行加载之后,你需要可视化输入和输出!
输入
请使你的图像尺寸保持一致,以便传输至相同的分类步骤!每一张输入图像应拥有相同的格式、尺寸,等等。
TODO: 标准化输入图像
- 重新将每张图像调整为要求尺寸: 600x1100px (hxw).
# This function should take in an RGB image and return a new, standardized version def standardize_input(image): ## TODO: Resize image so that all "standard" images are the same size 600x1100 (hxw) #standard_im = [] ima=cv2.resize(image,(1100,600)) #print(ima.shape) #standard_im.append(ima) return ima
TODO: 标准化输出
对于每一张加载的图像,你还需要确定预期输出。针对这一点,请使用二进制数值,0/1=夜/日。
# Examples: # encode("day") should return: 1 # encode("night") should return: 0 def encode(label): numerical_val = 0 ## TODO: complete the code to produce a numerical label if label=='day': numerical_val=1 else: numerical_val=0 return numerical_val
构建输入图像和输出标签的STANDARDIZED_LIST 函数
该函数将输入一个图像标签对列表,并输出一个包含调整过的图像和数字标签的标准列表。
此处使用你在上方定义的函数来标准化输入和输出,因此,你必须完成那些函数来使这里的标准化顺利进行。
def standardize(image_list): # Empty image data array standard_list = [] # Iterate through all the image-label pairs for item in image_list: image = item[0] label = item[1] # Standardize the image standardized_im = standardize_input(image) # Create a numerical label binary_label = encode(label) # Append the image, and it's one hot encoded label to the full, processed list of image data standard_list.append((standardized_im, binary_label)) return standard_list # Standardize all training images STANDARDIZED_LIST = standardize(IMAGE_LIST) print(len(STANDARDIZED_LIST))
将标准化数据可视化
显示一个来自STANDARDIZED_LIST的标准化图片。
# Display a standardized image and its label # Select an image by index image_num = 0 selected_image = STANDARDIZED_LIST[image_num][0] selected_label = STANDARDIZED_LIST[image_num][1] print(selected_image.shape) print(selected_image) print(selected_label) # Display image and data about it ## TODO: Make sure the images have numerical labels and are of the same size plt.imshow(selected_image) print("Shape: "+str(selected_image.shape)) print("Label [1 = day, 0 = night]: " + str(selected_label))

平均亮度
以下是我们提取图像平均亮度的步骤。
- 将图像转换为 HSV 颜色空间(Value 通道是亮度的近似值);
- 总结 Value 通道中像素的所有值。 将亮度总和除以图像的面积,即宽度乘以高度。
这给我们提供了一个值: 这张图像的平均 Value 的平均亮度。
在下一个 notebook 中,请确保查看各种昼夜图像,看看是否可以考虑将图像分开的平均亮度值(类似于在沙中画线)!
下一步将把这些数据提供给一个分类器。分类器可能像条件语句一样简单,核实平均亮度是否高于某个阈值,则此图像标记为1(白天);如果不是,则标记为 0(夜晚)。
特征提取
创建一个表示图像亮度的特征。我们将使用HSV颜色空间提取平均亮度。具体来说,我们将使用V通道(亮度测量),将V通道中的像素值相加,然后将该总和除以图像的面积,从而获得该图像的平均值。
从 RGB 转换为 HSV
在下方,一张测试图片被从 RGB 转换为 HSV 颜色空间,其中每个元素都用一张图片显示。
# Convert and image to HSV colorspace # Visualize the individual color channels image_num = 0 test_im = STANDARDIZED_LIST[image_num][0] test_label = STANDARDIZED_LIST[image_num][1] # Convert to HSV hsv = cv2.cvtColor(test_im, cv2.COLOR_RGB2HSV) # Print image label print('Label: ' + str(test_label)) # HSV channels h = hsv[:,:,0] s = hsv[:,:,1] v = hsv[:,:,2] # Plot the original image and the three channels f, (ax1, ax2, ax3, ax4) = plt.subplots(1, 4, figsize=(20,10)) ax1.set_title('Standardized image') ax1.imshow(test_im) ax2.set_title('H channel') ax2.imshow(h, cmap='gray') ax3.set_title('S channel') ax3.imshow(s, cmap='gray') ax4.set_title('V channel') ax4.imshow(v, cmap='gray')

使用V通道查找平均亮度
该函数会输入标准化的RGB图像并返回一个代表图像亮度平均水平的特征(单个值)。我们将使用此值将图像分类为白天或夜晚。
# Find the average Value or brightness of an image def avg_brightness(rgb_image): # Convert image to HSV hsv = cv2.cvtColor(rgb_image, cv2.COLOR_RGB2HSV) # Add up all the pixel values in the V channel sum_brightness = np.sum(hsv[:,:,2]) ## TODO: Calculate the average brightness using the area of the image # and the sum calculated above avg = sum_brightness/(600*1100) return avg
in[11]

什么是特征?
特征可以被简单定义为某个东西的“归纳”。因此图像的特征在本质上只是图像数据的简要归纳。此外,就像图像实际上只是阵列中的数字集合一样,特征也是阵列中的另一个数字集合,但这个集合往往比图像的集合小得多。
那么这是什么意思?简单来说,撇开图像,我们以人类为例。一个人有很多特征面,我们很难全面地描述一个人。
然而,我们可以从一个人身上提取哪些简要特征?之所以选择“简要”这个词,是因为我们想用这些特征来描述这个人的某些方面,同时这个描述应该是某些相关信息的概括。
例如,如果我们想把拳击手放到他们的体重类中,我们可能想要对每个拳击手进行特征提取。我们将提取一个二维特征:身高和体重(两者都用来确定一个体重类。)
从这个意义上说,这些是“特征”,因为它们很好地忽略了不相关;它们描述了一个人的体重和身高,这些特征对于将拳击手安置在适当的体重类中是有用的,它们也忽略了诸如肤色或者说头发长度等特征。所以从这个意义上来说, 特征提取是提取相关信息的一种方式,同时也巧妙地忽略了不相关的信息。一个很好的特征是非常简洁。
特征是图像中独特和可衡量的信息。我们将具体通过几个示例,来谈谈特征以及如何检测它们。计算机视觉方面的突破之一来自于能够自动提取好的特征。但是,你也可以自己手动执行此操作。
打个比方,如果我们想把拳击手按体重分类,我们可能会提取每个拳击手的特征。在这里我们将提取一个二维特征:身高和体重(这两者都用来确定体重分类。)
这些数据之所以是“特征”,是因为它们很好地忽略了无关信息。它们描述了一个人的体重和身高,这些特征能有效将拳击手归纳到正确的体重组中。同时它们也忽略了诸如肤色或头发长度等无关特征。所以从这个方面来说, 特征提取是一种提取相关信息、同时巧妙地忽略无关信息的方法。好的特征非常简明。
特征是图像中独特、可测量的信息片段。我们将探究几个示例,并学习如何检测它们。计算机视觉的一个重要突破实际上就来自于自动计算好的特征。不过你也可以自己手动计算。
特征类型
我们已经将图像描述为可衡量的数据片段,以帮助区分不同类的图像。
有两种主要类型的特征:
- 基于颜色
- 基于形状
这两个特征在单独出现时很有用,连在一起时更重要。例如,假设我想分类停车标志。停车标志应该在颜色和形状方面鲜明突出!一个停车标志是一个八角形(它有 8 个平坦的侧面),颜色很红。它的红色往往足以区分这个停车标志,但标志却会被树木或其他事物遮蔽,因此形状也变得重要。
再举另外一个例子,假设我想避免撞上一辆车(一个非常重要的避免案例!)。我想把对象分类为汽车,或者至少要识别汽车的边界,这是由形状决定的。具体来说,我想要识别车辆的边缘,以便我可以跟踪车辆,并避免它。在这种情况下,颜色并不是很有用,但形状却很重要。
随着学习的进行,请记住,选择正确的特征是一项重要的计算机视觉任务。
过滤器
我们刚刚已经看到了如何使用颜色来隔离图像的一部分,或是协助进行图像分类。
除了颜色信息之外,图像中的灰阶强度图案也十分有用。光的强度与亮度类似,用于测量光暗。它可以用来探测其他区域或我们感兴趣的对象。 例如,我们往往可以通过查看强度的突然变化来识别对象的边缘,这种变化指图像由暗转亮。
要检测这些变化,你将使用并创建特定的图像滤波器来查看像素组,并探测图像中饱和度的大范围变化。这些滤波器的输出会显示这些边缘。
所以,让我们深入学习这些滤波器,看看它们在图像处理和识别感兴趣的特征中的作用。
高通滤波器
高通滤波器检测小范围内的强度大变化,并且在灰度图像中可以最好地看到强度图案。

灰度汽车
我将要讨论的过滤器是以矩阵的形式出现的,通常称为卷积内核,它们只是修改图像的数字网格。如果你想看到更多的运行中的内核类型,这里有链接资源。 下面是一个边缘检测的高通内核的例子。这是一个 3x3 内核,其元素总和为零。
对于边缘检测来说,所有元素总和为 0 很重要,因为边缘滤波器计算相邻像素之间的差异或变化;它们是空间上图像导数的近似值。

高通内核
卷积
在核卷积过程中,3x3 内核是原始灰度图像中每个像素的滑块。内核中的权重在中心像素周围成对地相乘,然后相加。该总和成为新的过滤处理过的输出图像中的像素的值。
该操作处于卷积神经网络的中心,该神经网络使用多个内核来提取基于形状的特征,并识别可准确分类图像集合的图案。这些神经网络在大量的标记数据上训练,他们学习最有效的、有助于正确表征每幅图像的内核权重。

在执行卷积的同时计算一个输出像素值(175)。
为了处理过滤器不能完全重叠的图像边缘,需要使用各种技术。最常见的一种方法是将图像的边缘像素值向外扩展一个,然后用它来执行卷积。另一种方法是用零填充图像,尽管这样会在滤波的图像中产生较深的边界。
下面的四个内核中,哪一个最适合在图像中查找和增强图像中的水平边缘和线条?

创建滤波器,边缘检测
导入资源并显示图像

将原图像转换为灰度图
import matplotlib.pyplot as plt import matplotlib.image as mpimg import cv2 import numpy as np %matplotlib inline # Read in the image image = mpimg.imread('images/curved_lane.jpg') plt.imshow(image)

TODO: 创建一个自定义内核
下面给出了一种常见的边缘检测滤波器:索贝尔算子。
索贝尔滤波器常用于边缘检测以及在图像中查找强度图谱。将索贝尔滤波器应用于图像是分别在x或y方向上 对图像的导数进行(近似)处理的一种方式。该算子看起来如下所示。

你可以创建一个索贝尔 x运算子并将其应用于给定的图像。
如果想挑战自己,你可以看看是否能够通过一系列滤波器来放置图像:首先使一张图像模糊化(需要平均像素),然后检测其边缘。
# Create a custom kernel # 3x3 array for edge detection sobel_y = np.array([[ -1, -2, -1], [ 0, 0, 0], [ 1, 2, 1]]) ## TODO: Create and apply a Sobel x operator sobel_x=np.array([[-1,0,1], [-2,0,2], [-1,0,1]]) # Filter the image using filter2D, which has inputs: (grayscale image, bit-depth, kernel) filtered_image = cv2.filter2D(gray, -1, sobel_y) plt.imshow(filtered_image, cmap='gray')
Out[12]:

测试其他滤波器!
我们鼓励你创建其他类型的滤波器并应用它们,观察会发生什么情况!作为可选练习, 请尝试以下操作:
- 创建一个具有十进制值权重的滤波器。
- 创建一个5x5滤波器。
- 将你的滤波器应用到
images目录中的其他图像。
图像的频率
我们对声音的频率都有所了解。高频率是一种高音调噪音,像鸟鸣或小提琴声。而低频声音则是低音调,就像低沉的声音或低音鼓。对于声音来说,频率实际上是指声波振荡时的速度,振幅往往使用 cycles/s 来衡量(Hz),声波更快,音调也就更高。下方是高频音和低频音声波的图片。y 轴表示振幅,衡量感受到的声音音量的声压,x轴表示时间。
高低频率
类似地,图像的频率是一种变化率。但图像的变化究竟是什么?其实图像在空间中发生变化,高频图像指的是强度变化很大的图像,而亮度级别也在像素之间快速变化。低频图像也许指亮度相对均匀或是变化缓慢的图像。这一点可以用一个例子来简单表示。

高频和低频图像模式。
大多数图像都同时具有高频和低频元素。在上面的图片中,围巾和条纹衬衫上有高频图案。在这一部分,亮度变化十分迅速。而在这张图片的上方,我们可以看到天空和背景部分的变化非常缓慢,这是一种平滑的低频图案。
高频元素往往也与图像中的物体边缘对应,这可以帮助我们对这些物体进行分类。具体参考:http://homepages.inf.ed.ac.uk/rbf/HIPR2/roberts.htm
颜色直方图
让我们回到我们的分类任务:将图像分类为白天图像或夜晚图像。 通过之前的学习,你已经知道如何使用原始像素值构造亮度特征,现在我们将尝试把像素强度直方图(颜色直方图)作为 特征向量。
特征可以是有用值的数组。 即使你创建的过滤图像也被视为特征提取图像。特征向量是值的一维数组(或列表),当单个值不足以对图像进行分类时可以使用它们。
在这个 notebook 中,你将看到如何创建一种常见类型的特征向量:直方图。 直方图是显示不同高度条的数据的一种图形显示方式。 每个柱会将数据(在这个案例中为像素值)分组为不同的范围,每个柱的高度表示数据落入该范围的次数。 所以,如果一个柱的高度更高,则表示有更多的数据落在了该特定范围内。
让我们来看看HSV颜色直方图的样子。
导入资源¶
import cv2 # computer vision library import numpy as np import matplotlib.pyplot as plt import matplotlib.image as mpimg %matplotlib inline
读入日/夜图像并将其标准化
我们将要分析两种图像:训练数据集中的一天一夜图像;同一场景的图像。 但是这些图像还没有被标准化,所以它们需要被调整为相同的。
# Read in a day and a night image # These are directly extracted by name -- do not change day_image = mpimg.imread("day_night_images/training/day/20151102_074952.jpg") night_image = mpimg.imread("day_night_images/training/night/20151102_175445.jpg") # Make these images the same size width = 1100 height = 600 night_image = cv2.resize(night_image, (width, height)) day_image = cv2.resize(day_image, (width, height)) # Visualize both images f, (ax1, ax2) = plt.subplots(1, 2, figsize=(20,10)) ax1.set_title('night') ax1.imshow(night_image) ax2.set_title('day') ax2.imshow(day_image)

创建HSV直方图
首先,将这些图像转换为HSV颜色空间。 然后使用numpy的 直方图函数 将颜色值组合到范围中。 其中,Bin指的是数值范围,如暗度值为0-15,亮度值为200-255。
使用np.histogram(),你不必指定bin数量或范围,但在这里我已任意选择了个bin并指定其范围=(0,256),这样便于获得有序的bin尺寸。np.histogram()返回两个数组的元组。例如,在这种情况下,h_hist [0]包含每个bin的计数,而h_hist [1]包含bin边(因此它比h_hist [0]长一个元素)。
为了将这些结果绘制成图,我们可以从bin边缘计算bin中心。 在这个示例例中,每个直方图都有相同的bin,所以我只使用rhist bin边缘就可以了:你可以定义bin的数量。
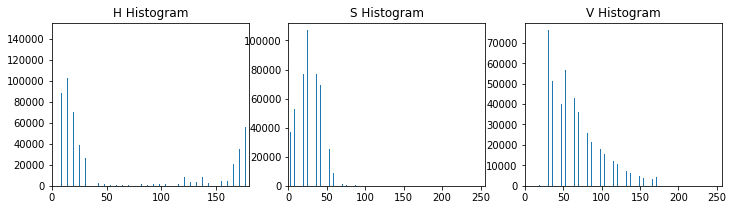
def hsv_histograms(rgb_image): # Convert to HSV hsv = cv2.cvtColor(rgb_image, cv2.COLOR_RGB2HSV) # Create color channel histograms h_hist = np.histogram(hsv[:,:,0], bins=32, range=(0, 180)) s_hist = np.histogram(hsv[:,:,1], bins=32, range=(0, 256)) v_hist = np.histogram(hsv[:,:,2], bins=32, range=(0, 256)) # Generating bin centers bin_edges = h_hist[1] bin_centers = (bin_edges[1:] + bin_edges[0:len(bin_edges)-1])/2 # Plot a figure with all three histograms fig = plt.figure(figsize=(12,3)) plt.subplot(131) plt.bar(bin_centers, h_hist[0]) plt.xlim(0, 180) plt.title('H Histogram') plt.subplot(132) plt.bar(bin_centers, s_hist[0]) plt.xlim(0, 256) plt.title('S Histogram') plt.subplot(133) plt.bar(bin_centers, v_hist[0]) plt.xlim(0, 256) plt.title('V Histogram') return h_hist, s_hist, v_hist
night_h_hist, night_s_hist, night_v_hist =hsv_histograms(night_image)
day_h_hist, day_s_hist, day_v_hist = hsv_histograms(day_image)
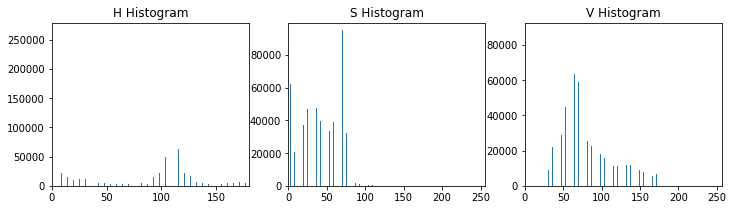
观察差异
# Which bin do most V values fall in? # Does the Hue channel look helpful? # What patterns can you see that might distinguish these two images? # Out of 32 bins, if the most common bin is in the middle or high up, then it's likely day fullest_vbin_day = np.argmax(day_v_hist[0]) fullest_vbin_night = np.argmax(night_v_hist[0]) print('Fullest Value bin for day: ', fullest_vbin_day) print('Fullest Value bin for night: ', fullest_vbin_night)
Fullest Value bin for day: 10 Fullest Value bin for night: 5
## TODO: Create and look at RGB histograms # Practice what you've learned and look at RGB color histograms of these same images
求和并创建特征向量
为了保持空间信息,对沿图像的列或行的像素值进行求和也是一种有用的方法,这样可以让你在空间中看到各种颜色值的尖峰。
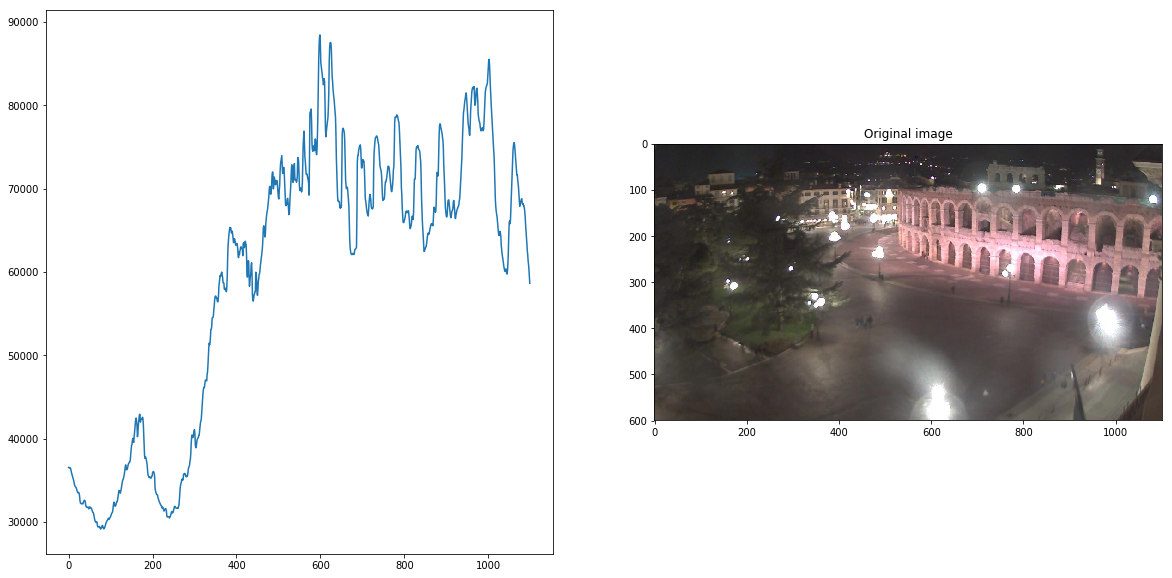
我们以夜间图像为例, 这些图像大多是黑暗的,但有很多来自人造灯光的小亮点。 我将查看图像中的Value组件,使用np.sum()将各列中的像素值相加,然后将该总和绘制成图。
TODO:将白天图像的V分量进行求和,并与夜晚图像进行对比
# Convert the night image to HSV colorspace hsv_night = cv2.cvtColor(night_image, cv2.COLOR_RGB2HSV) # Isolate the V component v = hsv_night[:,:,2] # Sum the V component over all columns (axis = 0) v_sum = np.sum(v[:,:], axis=0) f, (ax1, ax2) = plt.subplots(1, 2, figsize=(20,10)) ax2.set_title('Value sum over columns') ax1.plot(v_sum) ax2.set_title('Original image') ax2.imshow(night_image, cmap='gray')
分类任务
我们回去完成昼夜分类器。在提取平均亮度值之后,我们希望将此函数转换为对图像进行分类的predicted_label。 请记住,我们要生成一个数字标签。而且,由于我们有一个二进制数据集,我将创建一个标签。如果图像预测为白天,则标签为 1;如果预测为夜晚,则标签为 0。
我可以通过编写一个函数,来创建一个完整的分类器。该函数可以提取图像和亮度特征,然后检查平均亮度是否高于某个阈值 x。
如果是,这个分类器返回 1(白天)。否则,这个分类器返回 0(夜晚)!
分类和可视化误差
在本节中,我们将把我们的平均亮度特征转换为一个分类器,该分类器输入一个标准化图像并返回该图像的一个predicted_label。这个 estimate_label 函数应该返回一个值:0或1(分别代表夜晚或白天)。
TODO: 建立一个完整的分类器
请设置一个根据平均亮度区分日/夜图像的阈值。
# This function should take in RGB image input def estimate_label(rgb_image): ## TODO: extract average brightness feature from an RGB image # Use the avg brightness feature to predict a label (0, 1) predicted_label = 0 avg=avg_brightness(rgb_image) threshold=100 if avg>= threshold: predicted_label=1 else: predicted_label=0 ## TODO: set the value of a threshold that will separate day and night images ## TODO: Return the predicted_label (0 or 1) based on whether the avg is # above or below the threshold return predicted_label
# Test out your code by calling the above function and seeing # how some of your training data is classified day=0 night=0 #print(STANDARDIZED_LIST[0].shape) for i in range(len(STANDARDIZED_LIST)): print if estimate_label(STANDARDIZED_LIST[i][0])==1: day+=1 else: night+=1 print(day) print(night)
准确性
分类模型的准确性是通过比较预测标签和真实标签来实现的。对于任何给定的图像,如果predicted_label匹配true_label,那么这是一个正确分类的图像;否则,这就是错误分类。
准确度由正确分类的图像的数量除以图像的总数量得到。我们将在新图像上测试这个分类模型,这被称为测试数据集。
测试数据
测试数据是以前看不见的图像数据。你已经看到的数据,以及你用来帮助构建分类器的数据称为训练数据,我们之前提过。创建这些数据集的想法是,创建一个能够正确分类所有这些训练图像的分类器,以及了解分类器如何在真实世界的一般情况下工作。你可以想象正在浏览训练集的图像,并创建一个能够正确分类所有这些训练图像的分类器。但是,实际上,你会创建一个分类器,能够识别数据的一般模式。所以当它面对现实世界的情景时,它仍然会工作! 因此,我们使用新的测试数据集,来查看分类模型在现实世界中的工作方式,并确定模型的准确性。
错误分类的图像
在这个和大多数分类的例子中,测试集中有一些错误分类的图像。要看如何改进,了解这些错误分类的图像很有用。看看哪些地方被错误标记,以及这种模型在哪些地方有问题。这将取决于你看这些图像,并考虑如何改进分类模型!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号