一旦我们的聚类算法确定了聚类和原型轨迹,在这种情况下,每个具有三个原型轨迹的三个群集,
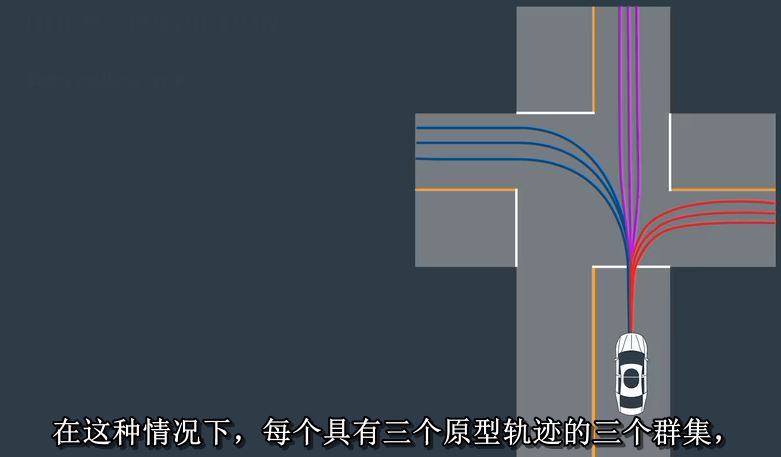
我们可以开始对在路上遇到的车辆进行在线预测。首先,我们观察了车辆的部分轨迹。接下来我们比较一下
每个集群原型轨迹的相应部分。这个比较是使用完成的这是我们之前用来执行聚类的相同度量。
每个群集的信念基于更新,部分轨迹与原型轨迹的相似程度如何。
最后,我们计算每个群集的预测轨迹。例如,通过采取最相似的原型轨迹。
让我们通过跟随这款车前进来更清楚地说明这一点
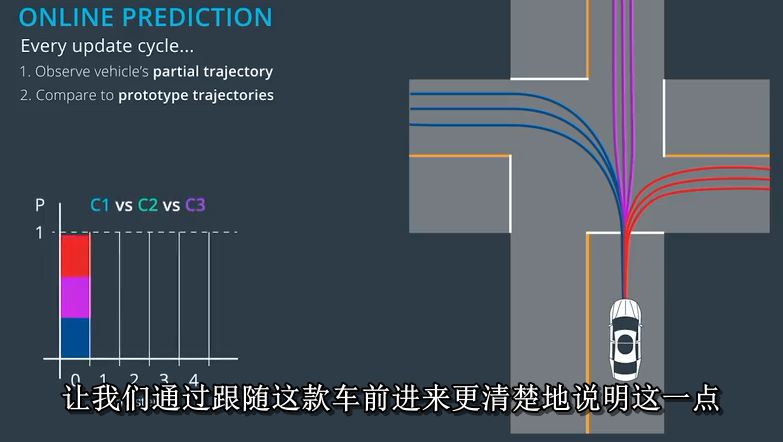
从T等于零到T等于1。我们来看看这些步骤。
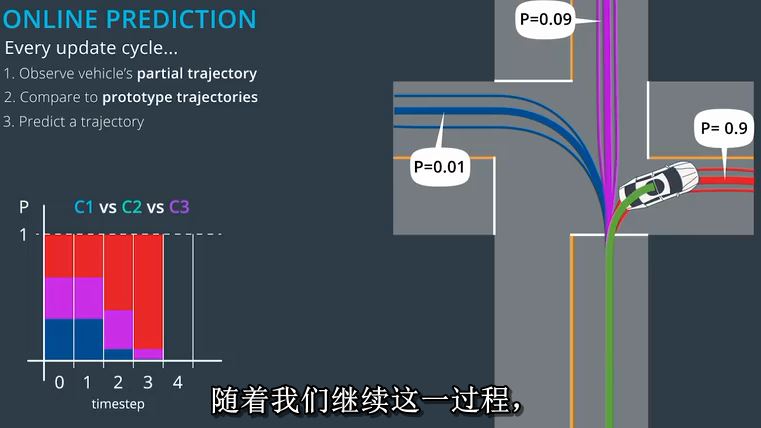
一,我们观察时间零和一之间的部分轨迹。这是车后的绿线。
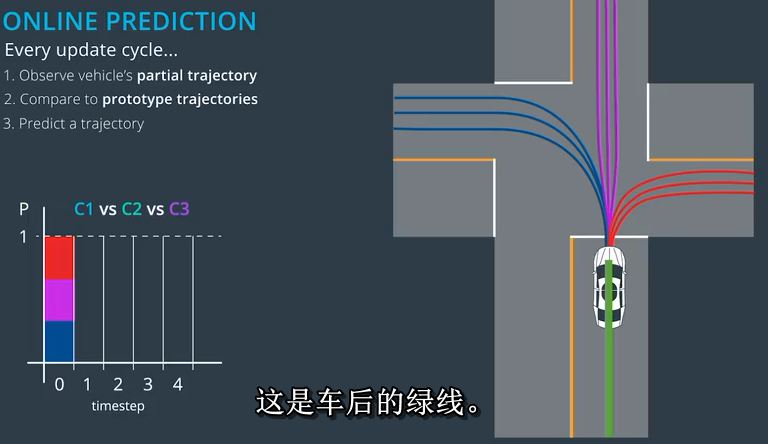
二,因为所有的原型轨迹重叠到这一点,轨迹比较步骤将为每个群集产生相同的概率。
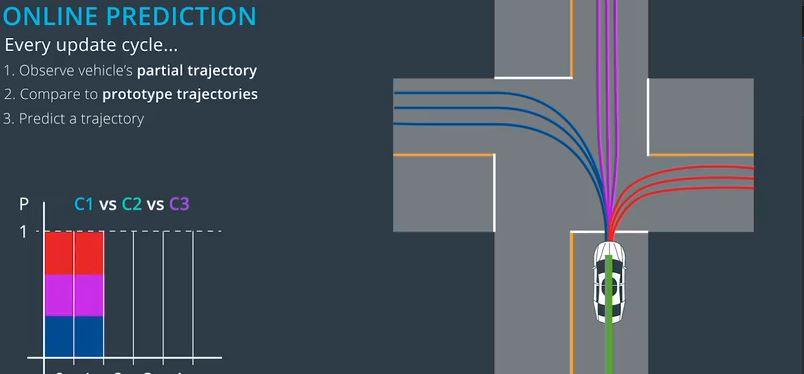
三,即使在每个集群中没有明确的赢家,我们仍然必须选择一个原型轨迹来表示每个集群和我们广播这三个轨迹及其相关概率。
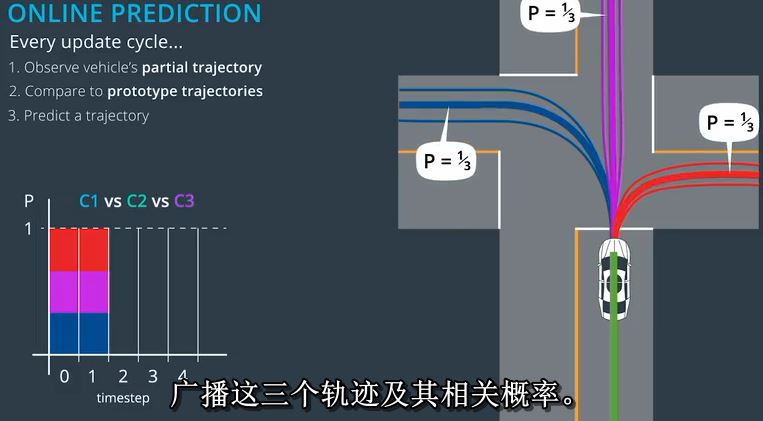
接下来,T等于两件事情会变得更有趣。
首先,让我们摆脱汽车,让我们可以更清楚地看到轨迹。
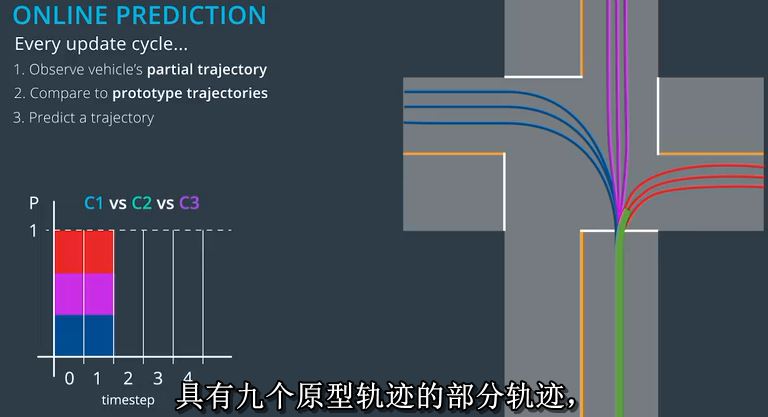
现在,当你进行比较时具有九个原型轨迹的部分轨迹,我们发现车辆的部分轨迹似乎比紫色或蓝色更类似于红色。
当我们更新相关的概率时,我们可能会得到类似的结果。请注意,红色增长的概率和蓝色和紫色都缩小,
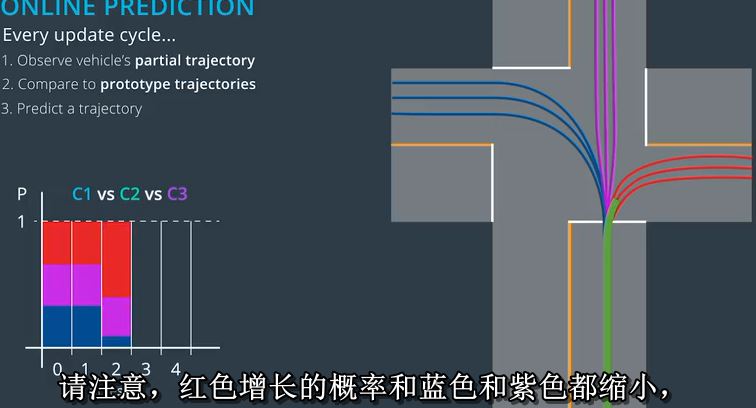
但蓝色比紫色收缩更多,因为部分轨迹对蓝色来说是更糟糕的匹配。然后,我们选择最佳的原型轨迹
每个集群并用它们来表示汽车未来的轨迹。
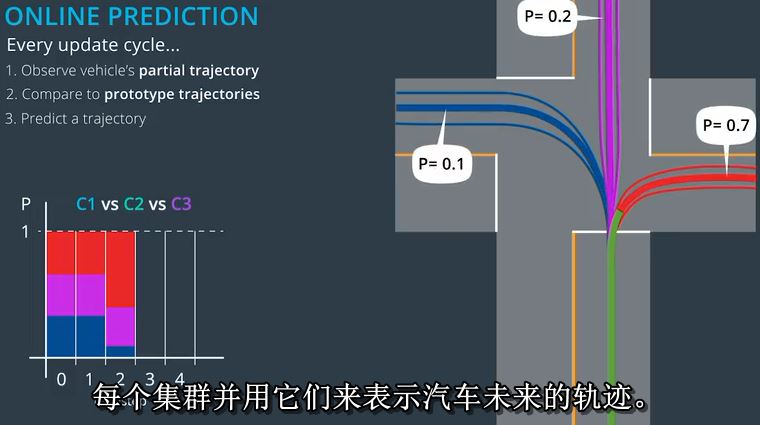
随着我们继续这一过程,我们看到红色星团快速接近一个的可能性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号