数据采集融合与应用综合实践
福州大学多模态网络舆情分析与可视化系统
| 序号 | 信息类别 | 内容描述 |
|---|---|---|
| 1 | 这个项目属于哪个课程 | 数据采集与融合综合实践 |
| 2 | 组名、项目简介 | 组名:福小兵,项目需求:实时舆情监控系统,项目目标:为福州大学提供舆情监控与决策辅助工具,技术路线:使用 Flask 后端、Memfire(PostgreSQL)数据库和 Vue 前端技术栈,建立从数据采集到情感分析再到可视化的完整系统 |
| 3 | 团队成员学号 | 102202141黄昕怡, 102202112刘莹,102202145谢含, 102202101马鑫,102202106王强,102202126陈家凯,102202153来再提·叶鲁别克,102202124 阿依娜孜·赛日克 |
| 4 | 这个项目的目标 | 设计并实现一个多源异构数据采集系统,通过情感分析和大数据技术总结和展示舆情,增强学校管理者对校园舆情的理解和控制力度。 |
| 5 | 其他参考文献 | [1] Kumar, A., et al. "Real-Time Sentiment Analysis of Twitter Data." Journal of Big Data. 2021. [2]马茜, 谷峪, 张天成, & 于戈. (2013). 一种基于数据质量的异构多源多模态感知数据获取方法. 计算机学报, 36(10), 12. [3]司俊勇, & 付永华. (2024). 多模态数据融合的在线学习情感计算研究. 图书与情报(3), 69-80. [4]何炎祥, 孙松涛, 牛菲菲, & 李飞. (2017). 用于微博情感分析的一种情感语义增强的深度学习模型. 计算机学报, 40(4), 18. |
项目github代码
一、项目概述![]
随着互联网和社交媒体的飞速发展,高校舆情已成为影响学校形象与声誉的重要因素。本项目面向福州大学,聚焦其在微博、贴吧、知乎等平台的多模态网络舆情数据,以 Flask 后端、Memfire(PostgreSQL) 数据库和 Vue 前端 为主要技术栈,搭建一个从数据采集到情感分析再到可视化展示的完整系统,为学校舆情监控与管理提供支持和决策辅助。
项目主要目标:
多源异构数据采集:整合文本、图片等多模态信息,建立统一的数据存储和管理方案。
情感分析与大模型总结:基于零样本分类模型进行细粒度情感识别,并调用大语言模型生成舆情报告和情感分析走向。
可视化与交互:通过前端页面实现搜索、分析结果图表展示、舆情总结文本等交互功能。
二、系统总体结构
1. 数据采集层
- 通过爬虫或官方 API,从微博、贴吧、知乎等平台获取与福州大学相关的多模态内容(文本、图片、视频链接等)。
- 数据存储到 Memfire 提供的云端 PostgreSQL 数据库中,便于后续查询与分析。
2. 后端层(Flask)
- 提供 RESTful API,对外暴露功能接口包括:
- 关键词搜索:在数据库中检索相关内容;
- 情感分析:基于深度学习模型,对文本做多类别情感识别;
- 舆情整合:关键词提取、高频话题检测、情感分析统计,AI 总结。
- 整合大语言模型接口,用于对检索和情感分析结果进行二次生成与深入总结。
3. 前端层(Vue + HTML/CSS)
- 前端一包括用户自爬取数据和报告式分析使用 Vue 搭建前端页面,包含搜索输入框、情感分析可视化、AI 总结输出等界面。
- 前端二包括用户聊天式舆论分析和全数据库整合
整体数据分析整合表格分页、柱状/饼图、词云翻页、音乐播放器、日历打卡彩蛋、AI 聊天窗口等交互; - 对接后端 Flask API,利用 Axios 发起请求,将搜索与分析结果进行可视化呈现(Chart.js 等图表库)。
三、核心功能与流程
1. 数据采集和整体数据展示
- 多平台文本数据抓取(微博、贴吧、知乎等),并整理出舆情数据库结构(如表
main_content字段:展示内容,发布时间等)。 - 采集图片和评论(如校园图片、评论配图),丰富多模态分析维度。
-整体数据分析整合表格分页、柱状/饼图、词云翻页、音乐播放器、日历打卡彩蛋、

2. 自动爬取存取数据库与自动检索
- 借助 Memfire 提供的 PostgreSQL 实例存储海量舆情数据;
- 通过手动模拟用户cookie进行自动关键词爬取存取进入数据库
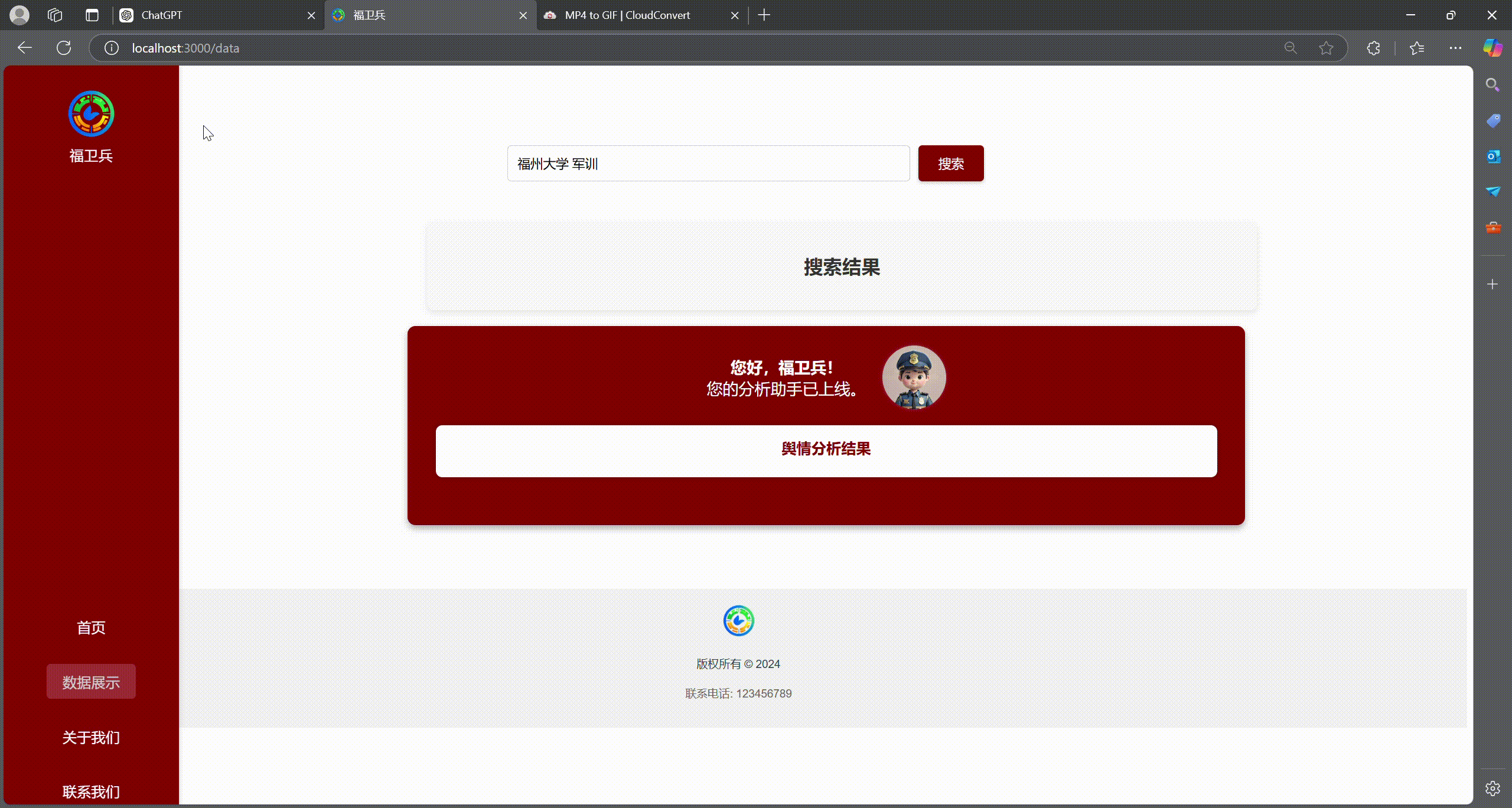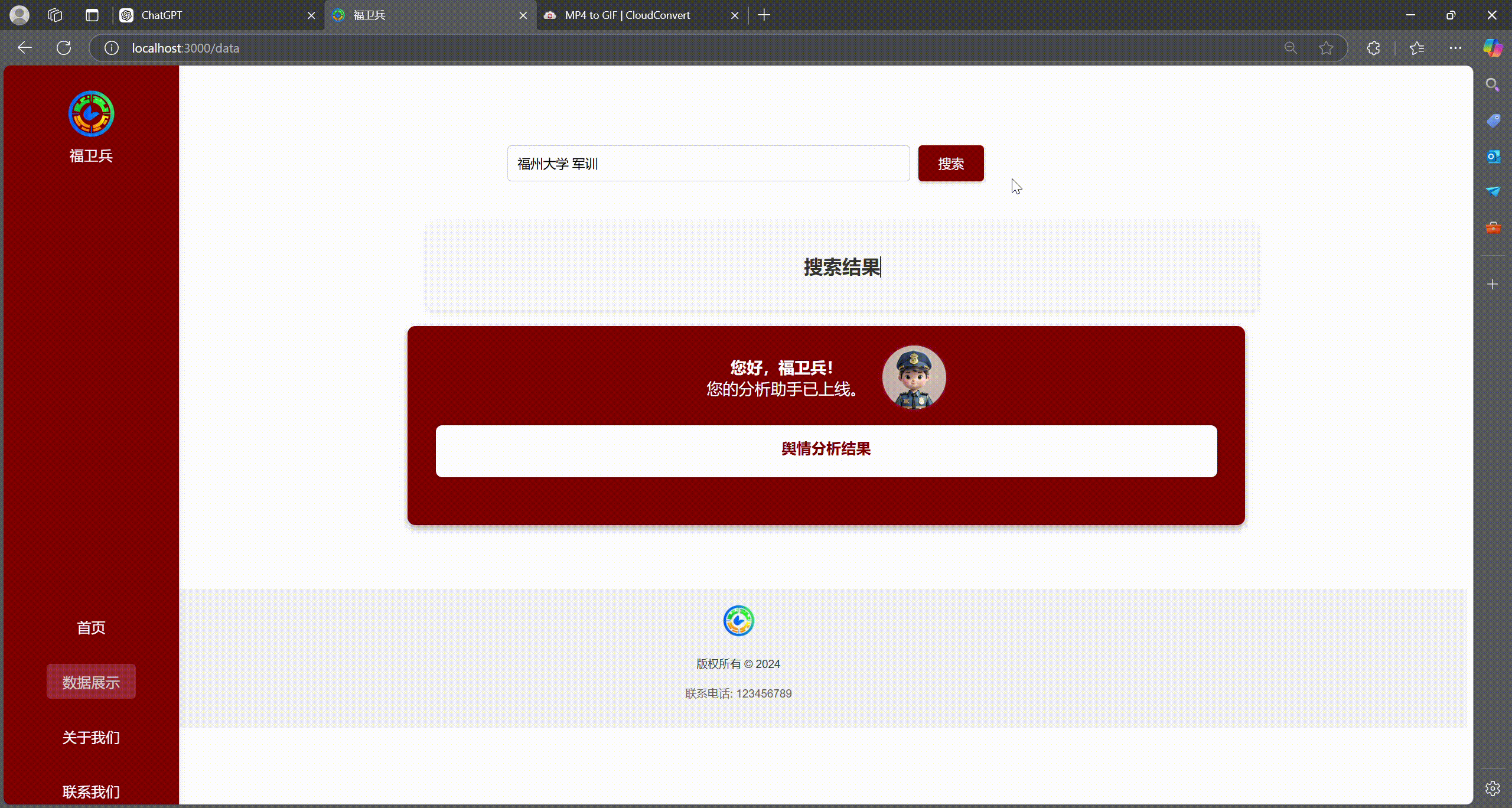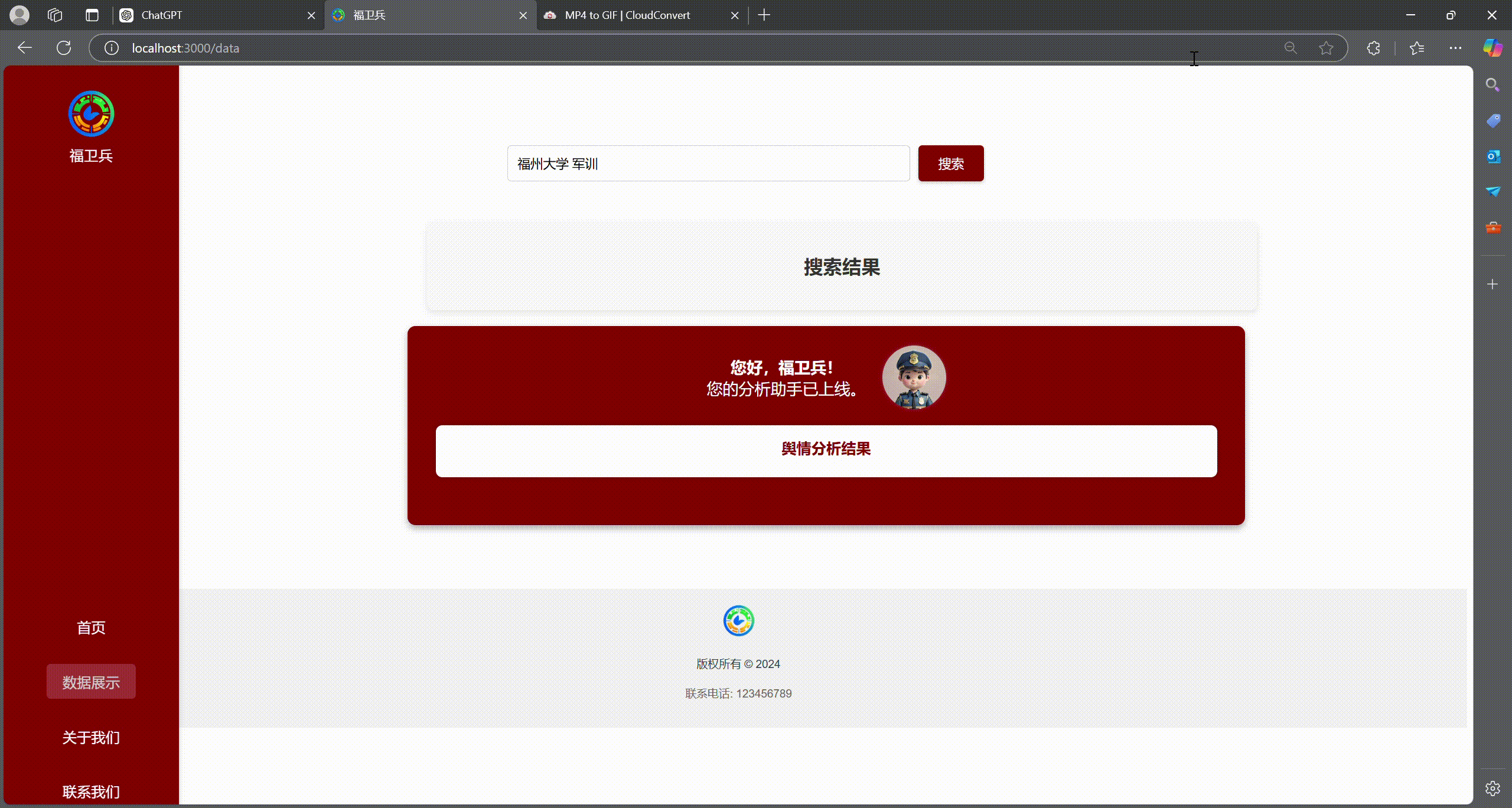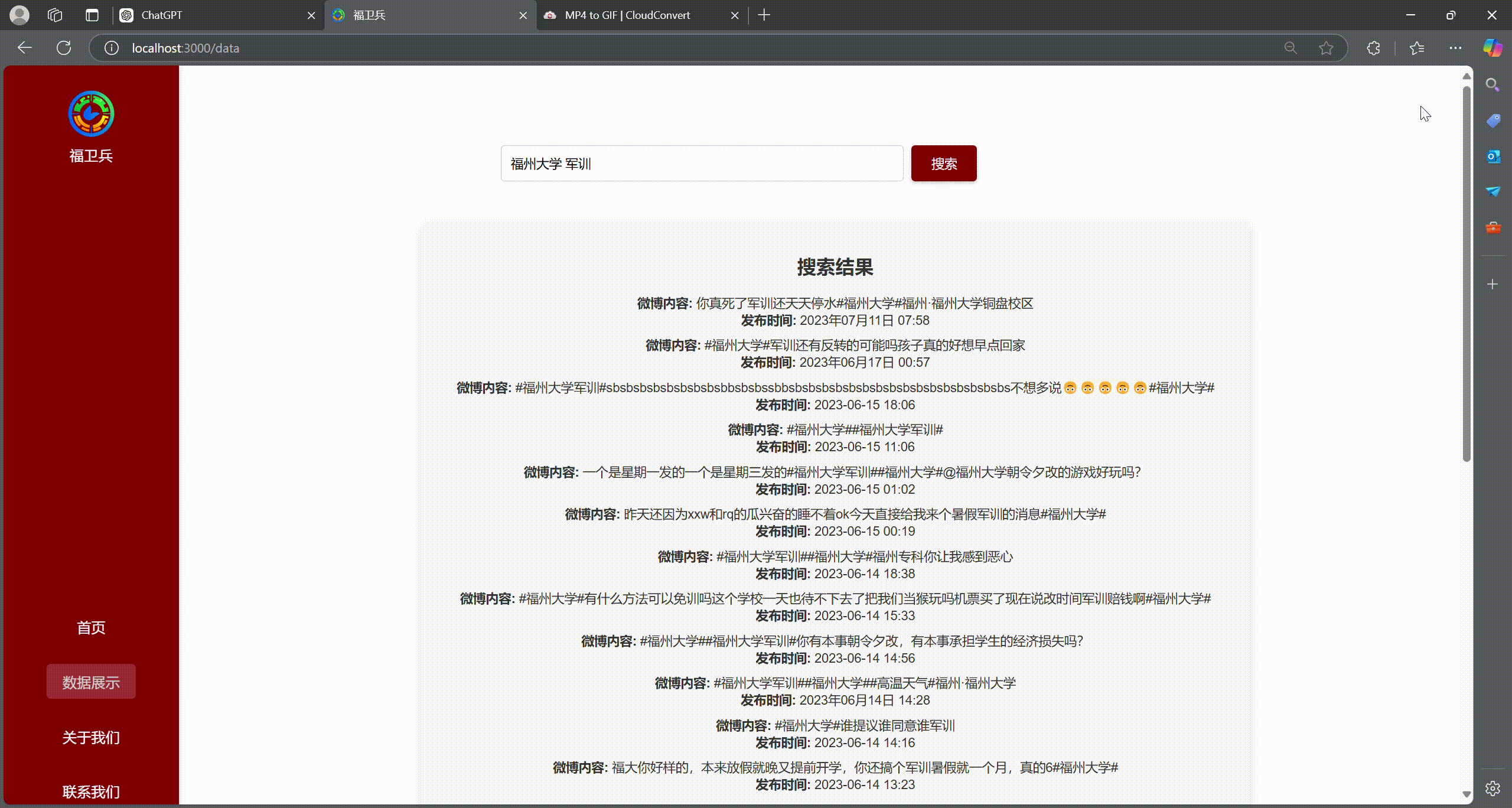

3. 用户自情感分析
- 可以将自爬取的数据单独拎出来分析,输入让ai单独分析,和另一个前端的整体数据架构进行区分,做一个稍微special的功能
- 使用
transformers中的零样本分类(Zero-Shot Classification)模型,对文本进行“喜悦、愤怒、悲伤、恐惧、惊讶、厌恶、中性”等多类别情感打分; - 进一步统计各情感类别占比,为舆情概况提供可视化支撑。
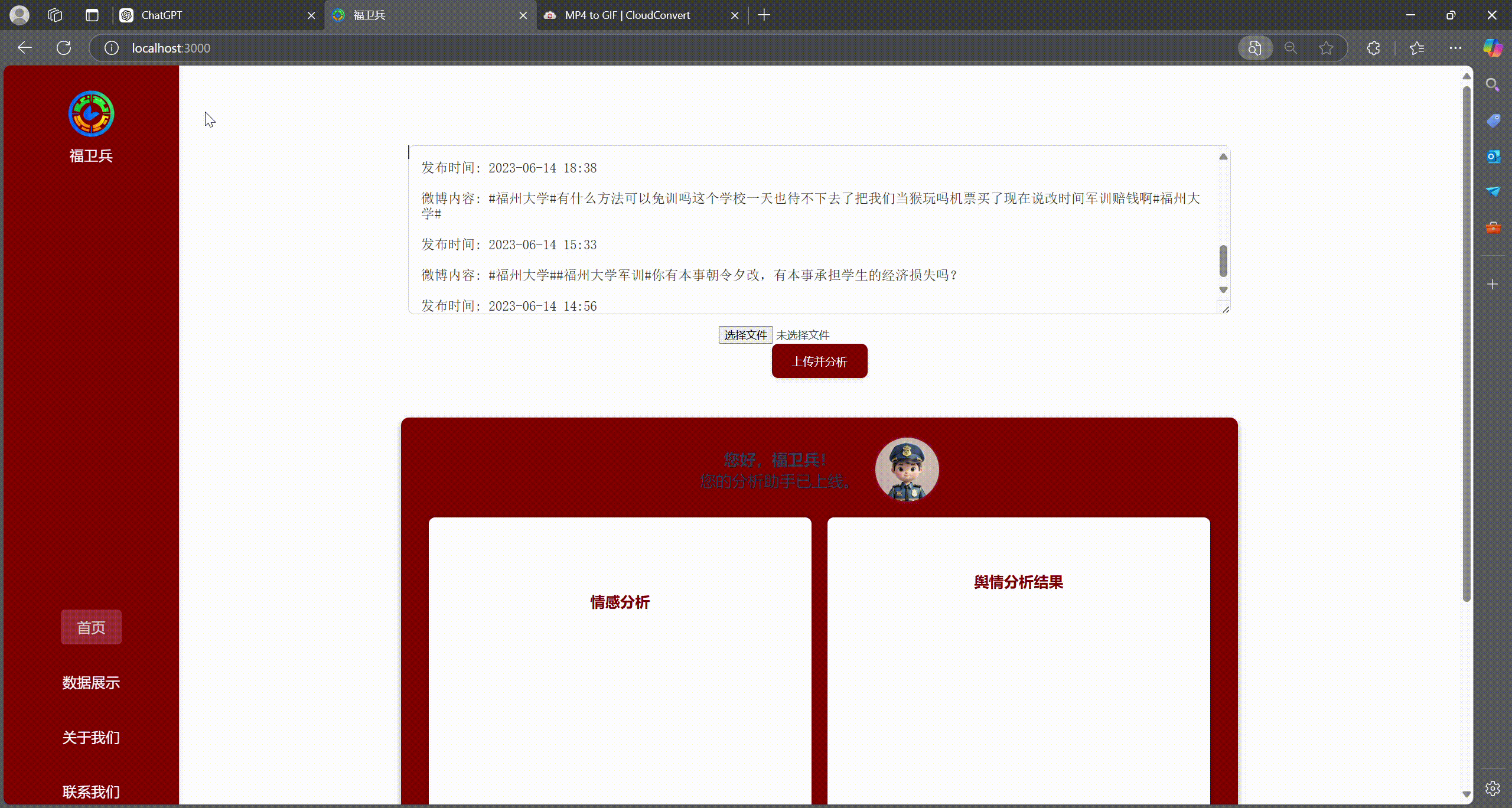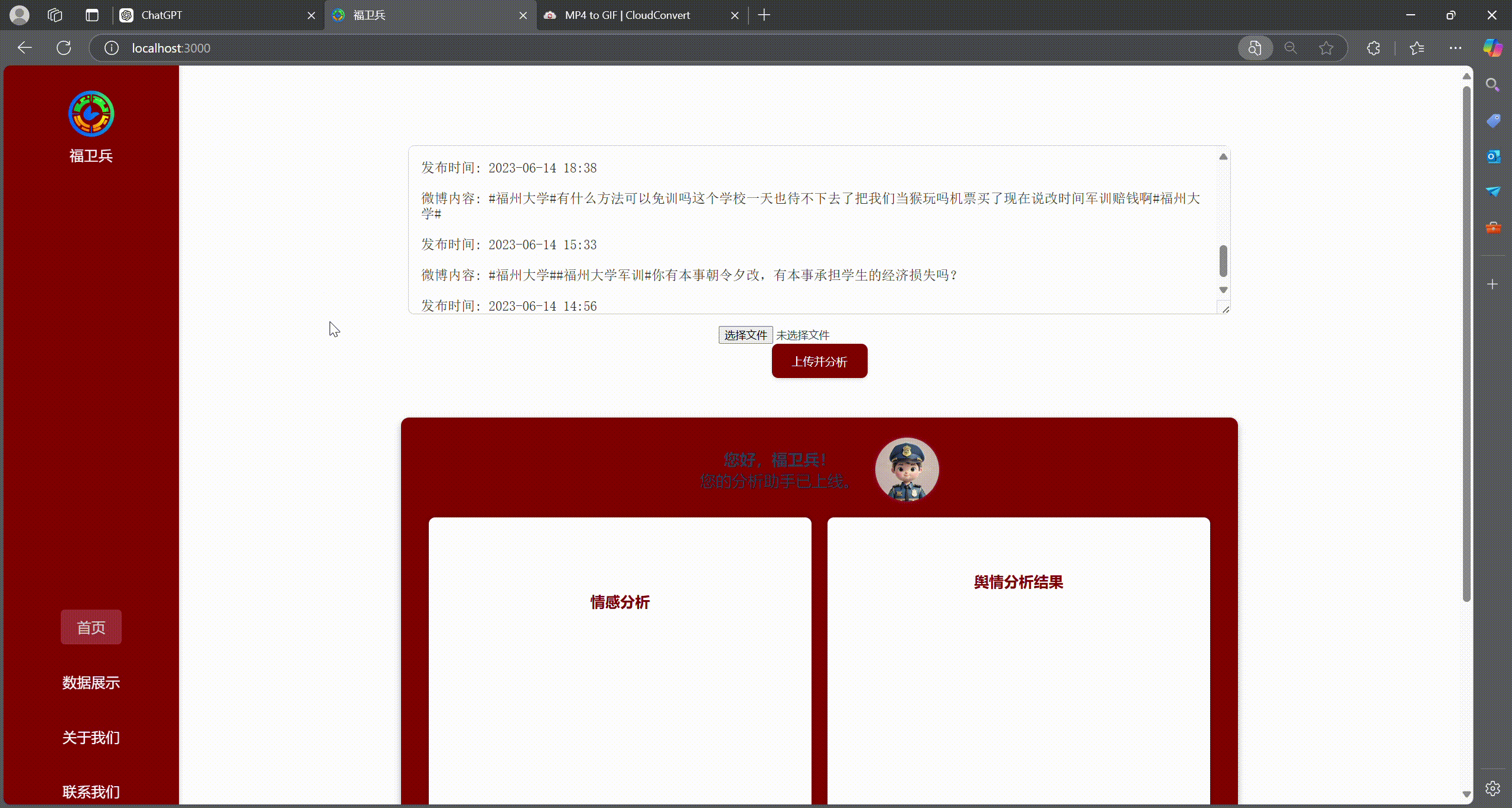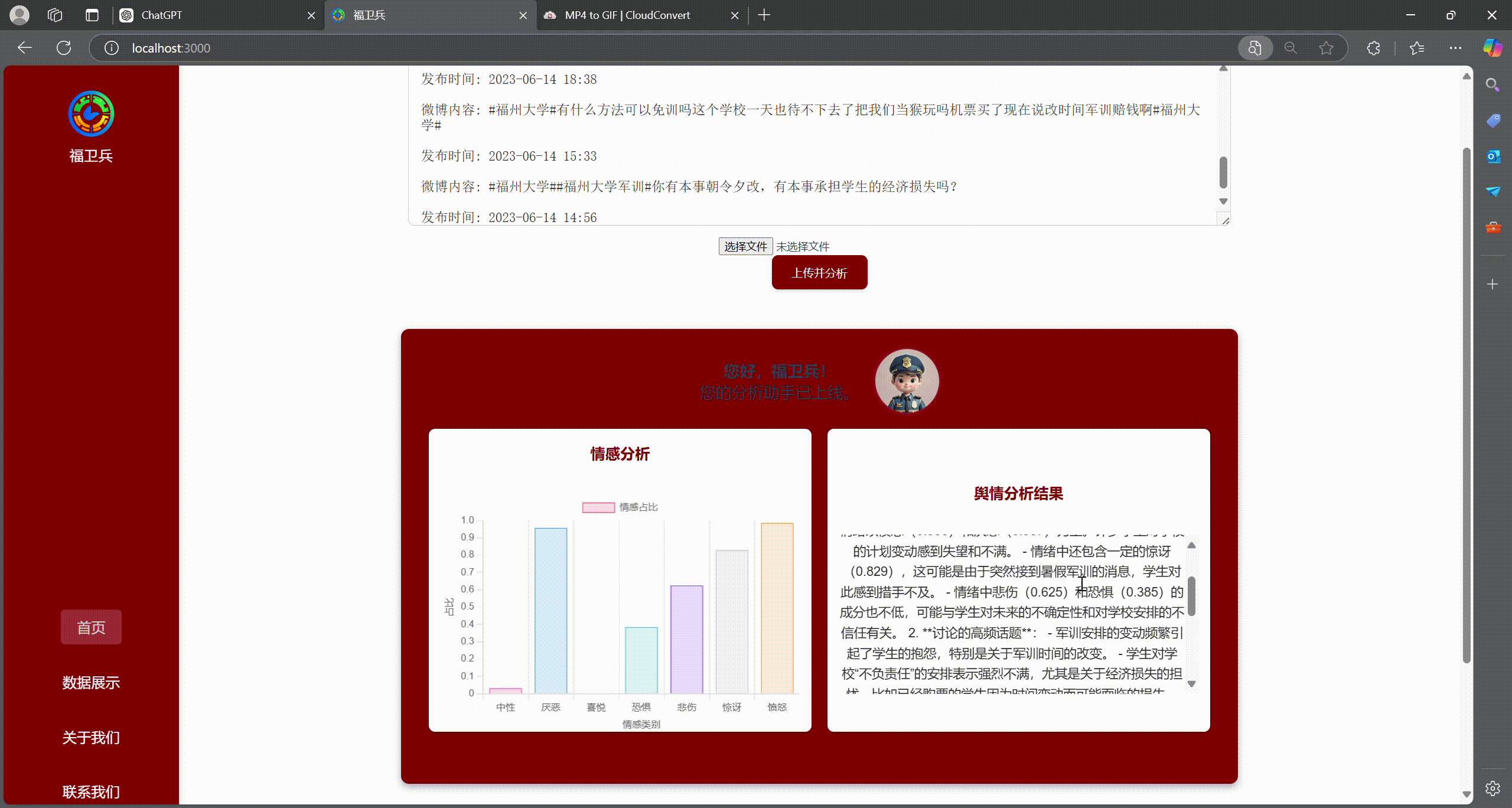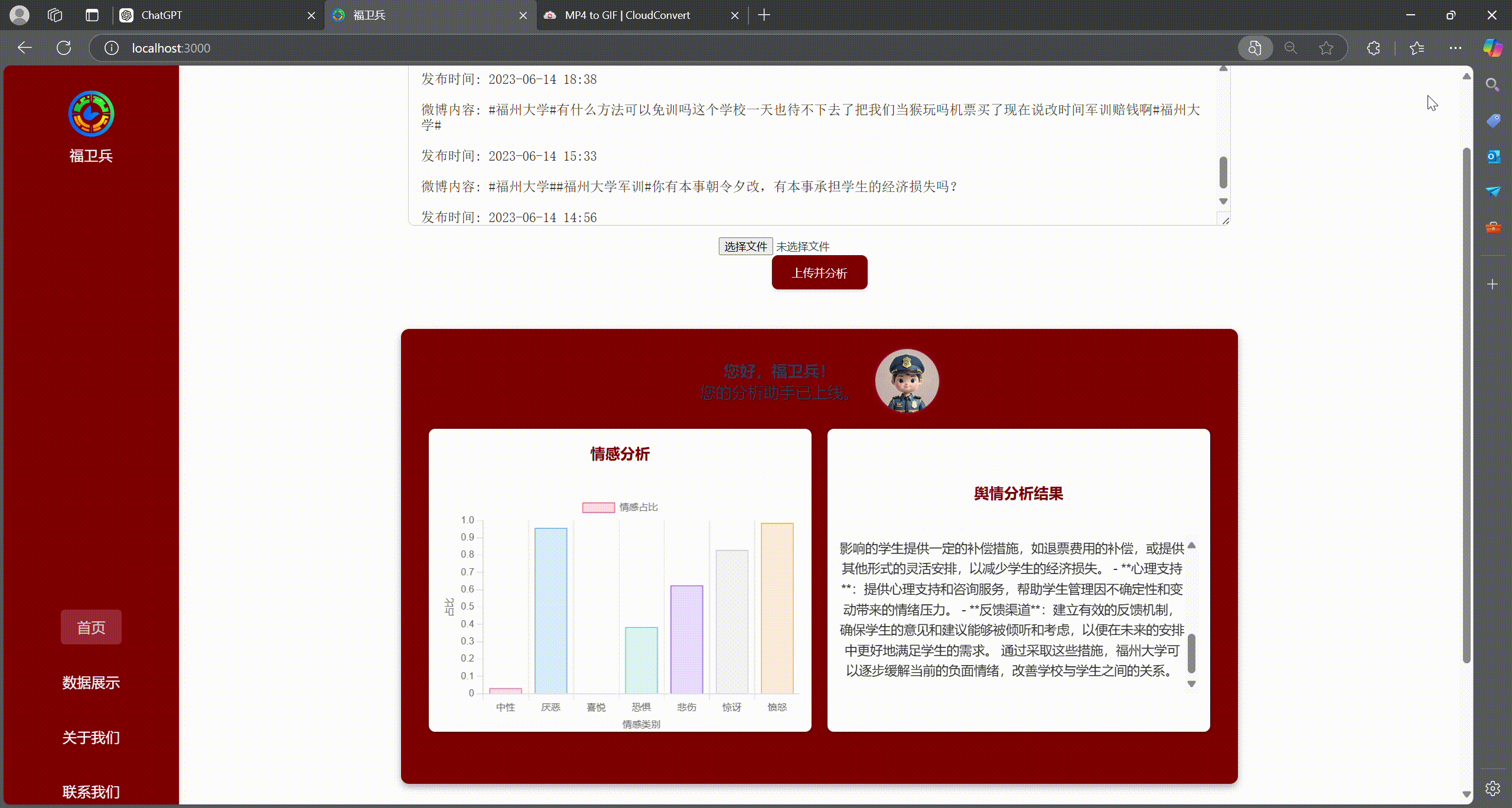
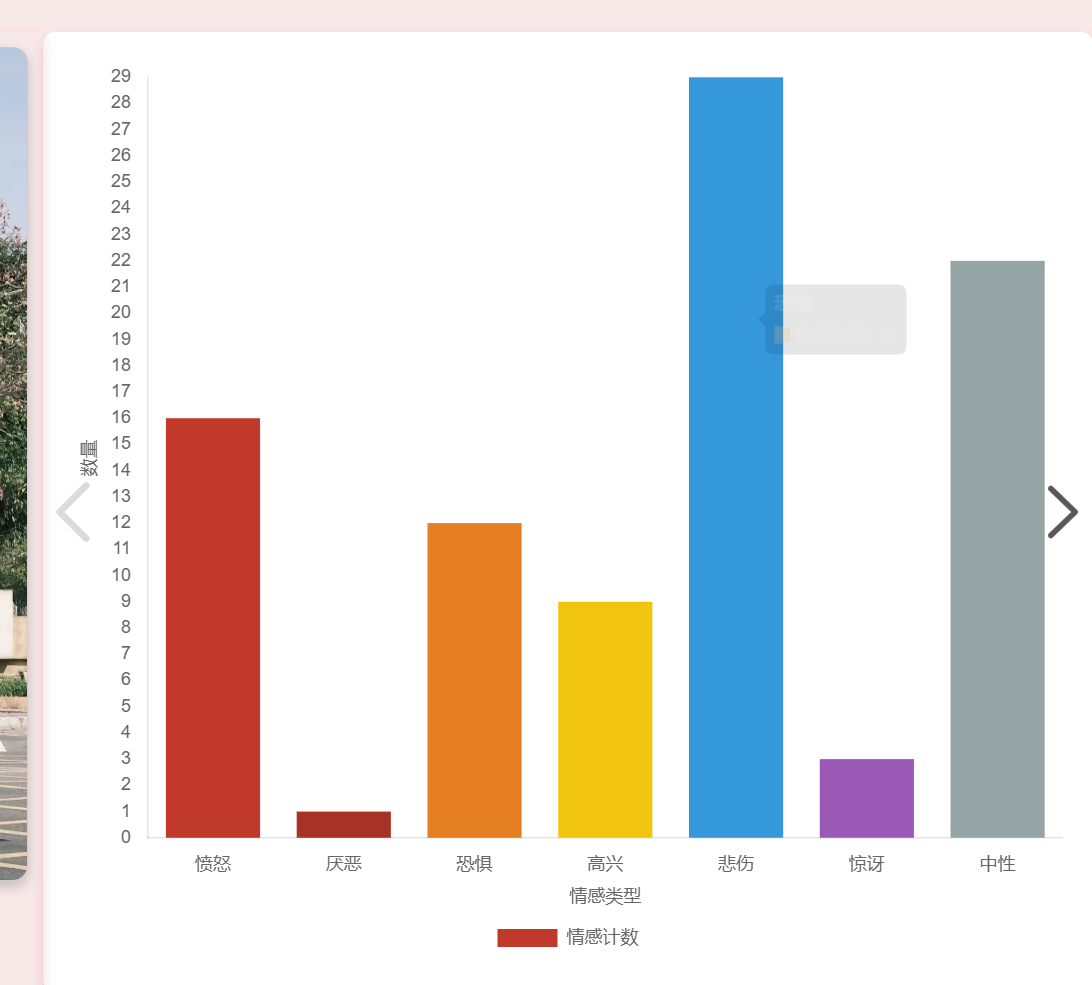
4. 舆情总结(大语言模型)
- 将搜索结果与情感分析占比等信息整合,调用 GPT-4 或其他大模型 API 生成简报;
- 分析福州大学在当前时间段舆论场所关注的焦点话题,给出相应建议和判断。
- 设计了直接ai自动调取数据库数据进行分析和聊天式智能舆情分析助手,能够根据需求自己调整
/api/chat路由基于 GPT-4,结合“高频话题统计”、“情感分布”信息自动生成舆情对话式总结;- 帮助使用者更快速地全局掌握舆情核心与情绪分布,提供实时决策建议。


5. 前端可视化
- 使用 Vue + Chart.js 实现情感分析可视化(柱状图或词云等);
- 实时展示 AI 的舆情总结文本,便于校方了解全局舆论走势。
-这些上面都能看见
四、项目亮点
1. 多模态融合:在文本情感分析基础上,可结合图片等识别结果进一步扩展舆情监控维度。
2. 大模型赋能:零样本分类与大语言模型相结合,实现复杂场景下的快速情感识别与深度总结。
3. 前后端分离:Flask 提供灵活可维护的后端接口,Vue 实现前端交互与可视化,部署与维护相对简单。
4. 可视化与易用性:图表、关键词统计、自动化报告帮助学校及时掌握网络舆论走向,推进科学决策。
五、系统部署与扩展
1. 部署
- 后端 Flask 部署在服务器(可选 Docker 容器方式),Memfire 云端 PostgreSQL 存储数据。
- 前端 Vue 项目可通过 Nginx / Node.js 等方式发布并与后端保持联通。
2. 扩展与优化
- 多模态:若需处理更多类型的图片/视频,可在后端添加 OCR 模块或视频分析流程;
- 性能:可对爬虫与数据库结构进行优化,实现对大规模数据的实时监控;
- 交互:可在前端增设权限管理、多语言支持及更多可视化大屏组件。
六、成果与展望
通过本项目可实现对福州大学在社交媒体平台的热点话题与情感倾向的自动化检测与可视化分析,为校方舆情管理与宣传策略提供辅助决策。后续可进一步研究舆情事件的溯源与传播路径,或深度对接更多大模型能力(如多语言自动生成舆情报告等),构建更完善的高校舆情监测体系。
七.个人贡献
本人主要负责项目功能的设计,需求的构建和想法的构造,进度的跟进,功能技术栈的沟通,关键技术的实现,整体进度的把控,还有presentation。
以下是本人在项目中主要个人负责或实现的功能模块:
1.自动检索功能的强化和重构
- 编写多平台爬虫脚本(微博、贴吧等),实现批量数据采集和入库;
- 实现对文本和图片的初步清洗与整理,提高后续分析的准确度。
问题是如何对关键词进行存取,会对每个关键词构造 展示内容 LIKE %XXX% AND 展示内容 LIKE %YYY% ... 的动态查询,实现同时包含所有关键词的搜索逻辑,不造成顺序前后的影响,尽可能地爬取相关信息
def extract_multiple_keywords(text, top_n=10):
"""
从文本中提取多个高频词,并返回用空格隔开的字符串。
这里可以根据需要换成jieba分词或更复杂的NLP方法。
"""
from collections import Counter
import re
# 用正则提取“单词/词语”
words = re.findall(r'\b\w+\b', text.lower())
# 可以添加更多停用词
stop_words = set(['的', '和', '是', '在', '了', '有', '我', '也', '不', '就',
'你', '我们', '他们', '她们', '没有', '这个', '那个', '什么'])
# 过滤停用词及长度过短的词
filtered_words = [word for word in words if word not in stop_words and len(word) > 1]
word_counts = Counter(filtered_words)
high_freq = [word for word, count in word_counts.most_common(top_n)]
# 将关键词用空格连起来
return " ".join(high_freq)
@app.route('/api/search-and-analyze', methods=['GET'])
def search_and_analyze():
"""
1. 根据关键字在数据库中搜索
2. 将搜索到的数据整合后,对文本做进一步关键词提取
3. 将提取的关键词和文本摘要发给 AI 做进一步的热点分析和总结
4. 返回给前端搜索结果 + AI分析结果
"""
keyword_str = request.args.get('keyword') # 获取前端传来的关键词字符串
if not keyword_str:
return jsonify({"message": "缺少关键词参数"}), 400
# 将用户输入的 keyword_str 用空格进行拆分,得到多个关键词
# 例如 "福州大学 军训" -> ["福州大学", "军训"]
split_keywords = keyword_str.split()
# 如果你希望去除空字符串或者前后空白,可以再做一次过滤
split_keywords = [kw.strip() for kw in split_keywords if kw.strip()]
if not split_keywords:
return jsonify({"message": "关键词为空"}), 400
conn = connect_db()
if not conn:
return jsonify({"message": "数据库连接失败"}), 500
cursor = conn.cursor(cursor_factory=extras.RealDictCursor)
try:
# 动态构建 WHERE 子句,让所有关键词都通过 LIKE 匹配(AND 连接)
# SELECT * FROM main_content WHERE 展示内容 LIKE %keyword1% AND 展示内容 LIKE %keyword2% ...
where_clauses = []
params = []
for kw in split_keywords:
where_clauses.append("展示内容 LIKE %s")
params.append(f"%{kw}%")
# 将各个条件用 AND 拼接
where_condition = " AND ".join(where_clauses)
query = f"SELECT * FROM main_content WHERE {where_condition}"
cursor.execute(query, params)
results = cursor.fetchall()
except Error as e:
print(f"数据库查询出现错误: {e}")
cursor.close()
conn.close()
return jsonify({"message": "数据库查询出现错误", "error_detail": str(e)}), 500
cursor.close()
conn.close()
# 如果没有搜索到数据,直接返回空结果
if not results:
return jsonify({
"results": [],
"analysis": "没有找到相关数据,无法进行AI分析。"
})
# 2. 整合所有搜索结果中的文本
# 假设展示内容字段叫做 "展示内容"
all_text = " ".join([row['展示内容'] for row in results if row.get('展示内容')])
# 3. 提取关键词(可换成更复杂的NLP方法)
extracted_keywords_str = extract_multiple_keywords(all_text, top_n=10)
# 4. 构建给AI的提示
ai_prompt = (
f"以下是根据关键词 '{keyword_str}' 搜索得到的内容集合:\n\n"
f"{all_text}\n\n"
f"系统自动提取的多个关键词:{extracted_keywords_str}\n\n"
"请基于以上内容,对这些话题进行简要分析,并给出热点话题的概括。"
)
public_opinion = chat_with_ai1(user_message=ai_prompt)
# 5. 返回给前端
response = {
"results": results, # 原始数据库搜索结果
"analysis": public_opinion, # AI分析结果
"extractedKeywords": extracted_keywords_str
}
return jsonify(response)
2.情绪分析模型构造
- 选型并部署零样本分类模型(Zero-Shot Classification),对文本进行多类别情感识别,让图片生成文字;
- 优化超参数配置与中文适配,提升在高校舆情场景下的分类效果。
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import json # 引入json模块
import os
import hashlib
import random
import time
from playwright.sync_api import sync_playwright
from transformers import BlipProcessor, BlipForConditionalGeneration
from PIL import Image
# Set up a rotating User-Agent list to avoid getting blocked
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Safari/605.1.15",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:89.0) Gecko/20100101 Firefox/89.0",
"Mozilla/5.0 (iPhone; CPU iPhone OS 14_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0 Mobile/15E148 Safari/604.1"
]
# Pre-load the BLIP model and processor from local directory to avoid downloading
try:
blip_model = BlipForConditionalGeneration.from_pretrained("./blip/")
blip_processor = BlipProcessor.from_pretrained("./blip/")
except Exception as e:
print(f"Failed to load BLIP model. Error: {e}")
blip_model = None
blip_processor = None
# Fetch posts from Tieba using Playwright
def fetch_tieba_posts(keyword, page_limit=1):
base_url = f"https://tieba.baidu.com/f?kw={keyword}&ie=utf-8"
posts = []
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
context = browser.new_context(
user_agent=random.choice(USER_AGENTS),
viewport={"width": 1280, "height": 800}
)
page = context.new_page()
for page_number in range(page_limit):
page_url = f"{base_url}&pn={page_number * 50}"
try:
page.goto(page_url)
time.sleep(random.uniform(2, 5)) # Random delay to avoid getting blocked
threads = page.locator('div.threadlist_title a.j_th_tit')
for i in range(threads.count()):
title = threads.nth(i).text_content().strip()
link = urljoin("https://tieba.baidu.com", threads.nth(i).get_attribute('href'))
posts.append({
'title': title,
'link': link
})
except Exception as e:
print(f"Failed to retrieve page {page_number + 1}. Error: {e}")
continue
browser.close()
return posts
# Fetch images from a specific post using Requests
def fetch_post_images(post_url):
headers = {"User-Agent": random.choice(USER_AGENTS)}
try:
response = requests.get(post_url, headers=headers)
response.raise_for_status()
except requests.RequestException as e:
print(f"Failed to retrieve post {post_url}. Error: {e}")
time.sleep(random.uniform(1, 3)) # Random delay to avoid getting blocked
return []
soup = BeautifulSoup(response.text, 'html.parser')
images = soup.find_all('img', {'class': 'BDE_Image'})
image_urls = [img['src'] for img in images if img.get('src')]
return image_urls
# Download an image from a URL and save it to a folder
def download_image(image_url, folder_path):
headers = {"User-Agent": random.choice(USER_AGENTS)}
try:
response = requests.get(image_url, headers=headers, stream=True)
response.raise_for_status()
except requests.RequestException as e:
print(f"Failed to download image {image_url}. Error: {e}")
return None
# Use hash to generate a unique filename
hash_object = hashlib.md5(image_url.encode())
file_extension = os.path.splitext(image_url)[1].split('?')[0] # Get file extension
filename = f"{hash_object.hexdigest()}{file_extension}"
file_path = os.path.join(folder_path, filename)
try:
with open(file_path, 'wb') as f:
for chunk in response.iter_content(1024):
f.write(chunk)
return file_path
except IOError as e:
print(f"Failed to save image {file_path}. Error: {e}")
return None
# Generate image description using BLIP
def generate_image_description(image_path):
if blip_model is None or blip_processor is None:
print("BLIP model is not loaded. Skipping description generation.")
return None
try:
image = Image.open(image_path)
inputs = blip_processor(images=image, return_tensors="pt")
out = blip_model.generate(**inputs)
description = blip_processor.decode(out[0], skip_special_tokens=True)
return description
except Exception as e:
print(f"Failed to generate description for image {image_path}. Error: {e}")
return None
# Generate descriptions for all images in the images folder and update JSON data
def generate_descriptions_in_folder(folder_path, data):
if not os.path.exists(folder_path):
print(f"Folder {folder_path} does not exist.")
return
image_files = [f for f in os.listdir(folder_path) if os.path.isfile(os.path.join(folder_path, f))]
for post in data:
for image_path in post['images']:
image_file = os.path.basename(image_path)
if image_file in image_files:
# Generate image description using BLIP
description_result = generate_image_description(os.path.join(folder_path, image_file))
if description_result:
print(f"Image: {image_file} - Description: {description_result}")
post.setdefault('descriptions', []).append({image_file: description_result})
# Main function to scrape posts, download images, and generate descriptions
def main():
keyword = "福州大学"
page_limit = 1 # Adjust the number of pages to scrape
posts = fetch_tieba_posts(keyword, page_limit)
# Create images folder if it doesn't exist
images_folder = 'images'
if not os.path.exists(images_folder):
os.makedirs(images_folder)
print(f"Created folder: {images_folder}")
# Prepare JSON data
data = []
if posts:
for post in posts:
print(f"Title: {post['title']}\nLink: {post['link']}\n")
image_urls = fetch_post_images(post['link'])
if image_urls:
print("Images:")
downloaded_images = []
for img_url in image_urls:
print(img_url)
local_path = download_image(img_url, images_folder)
if local_path:
downloaded_images.append(local_path)
post['images'] = downloaded_images # Add local image paths to post
else:
print("No images found.\n")
post['images'] = []
data.append(post)
else:
print("No posts found. Loading images from folder.")
# If no posts are found, load existing images from the images folder
if os.path.exists(images_folder):
image_files = [f for f in os.listdir(images_folder) if os.path.isfile(os.path.join(images_folder, f))]
data.append({'title': 'Local Images', 'link': 'N/A', 'images': [os.path.join(images_folder, img) for img in image_files]})
# Generate descriptions in the images folder and update JSON data
generate_descriptions_in_folder(images_folder, data)
# Write updated data to JSON file
with open('images_to_text.json', 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
print("Data has been written to images_to_text.json")
if __name__ == "__main__":
main()
3. AI 接口调用与功能设计和实现
- 整合 GPT-4 API,编写
/api/chat路由; - 将“高频话题统计”和“情感分布”和“高频词汇分析”“构造prompt"一起提交给大模型,生成对福州大学舆情的深层次分析与总结;
- 在前端实现对话式 AI 界面(文本输入、滚动历史记录),提高可交互性。
def get_high_frequency_topics():
try:
conn = get_db_connection()
if conn is None:
return []
cursor = conn.cursor()
# 从 analyzed_demo_one 和 comment_analyse 表中获取文本
query1 = 'SELECT content FROM analyzed_demo_one'
cursor.execute(query1)
rows1 = cursor.fetchall()
query2 = 'SELECT text FROM comment_analyse'
cursor.execute(query2)
rows2 = cursor.fetchall()
cursor.close()
conn.close()
# 合并所有文本
all_text = ' '.join([row[0] for row in rows1] + [row[0] for row in rows2])
# 分词
tokens = word_tokenize(all_text)
# 转为小写
tokens = [word.lower() for word in tokens]
# 去除标点符号和数字
tokens = [word for word in tokens if word.isalpha()]
# 去除停用词
stop_words = set(stopwords.words('chinese') + stopwords.words('english'))
filtered_tokens = [word for word in tokens if word not in stop_words]
# 统计词频
word_counts = Counter(filtered_tokens)
# 获取前10个高频词
high_freq = [word for word, count in word_counts.most_common(10)]
return high_freq
except Exception as e:
print(f"高频话题统计错误: {e}")
return []
def chat_with_ai(user_message, high_freq_topics, sentiment_summary):
api_url = 'https://api.gptsapi.net/v1/chat/completions' # 确认这个 URL 是否正确
api_key = 'sk-mvOc5002d4fec6492dda97092933450e3daea29ad09eYKtV' # 从环境变量中获取 API 密钥
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}' # 假设 API 使用 Bearer Token 认证
}
# 构建提示内容,包含词频和情感摘要
analysis_context = (
f"以下是福州大学当前的舆情数据分析:\n"
f"高频话题: {', '.join(high_freq_topics)}\n"
f"情感分析:\n"
)
for emotion, count in sentiment_summary.items():
analysis_context += f"- {emotion}: {count}\n"
# 完整的用户提示
full_user_message = (
f"{analysis_context}\n"
f"基于以上数据,请对福州大学的当前舆情进行详细分析,并提供相关建议。"
)
payload = {
"model": "gpt-4",
"messages": [
{"role": "system", "content": "你是一个帮助分析福州大学舆情的助手。请你尽可能地分析和猜测福州大学的舆论和学生情绪,大家目前关心什么话题"},
{"role": "user", "content": full_user_message}
],
"max_tokens": 500,
"temperature": 0.7
}
try:
response = requests.post(api_url, headers=headers, json=payload, timeout=60)
response.raise_for_status() # 如果响应状态码不是 2xx,会抛出异常
data = response.json()
print(f"API Response: {json.dumps(data, ensure_ascii=False, indent=2)}") # 调试输出
# 提取 AI 的回复
ai_reply = data['choices'][0]['message']['content'].strip()
return ai_reply
except requests.exceptions.HTTPError as http_err:
print(f"HTTP 错误发生: {http_err}") # HTTP 错误
return '抱歉,分析时出现了问题。请稍后再试。'
except requests.exceptions.Timeout:
print("请求超时") # 超时
return '抱歉,服务器响应超时。请稍后再试。'
except requests.exceptions.RequestException as err:
print(f"请求错误: {err}") # 其他请求错误
return '抱歉,出现了一个错误。请稍后再试。'
except KeyError:
print("响应结构异常")
return '抱歉,收到的回复格式不正确。'
@app.route('/api/chat', methods=['POST'])
def chat():
try:
data = request.get_json()
print(f"Received data: {data}, type: {type(data)}") # 调试输出
if not isinstance(data, dict):
raise ValueError("Invalid JSON data received")
user_message = data.get('message', '').strip()
if not user_message:
return jsonify({'reply': '请输入您的消息。'}), 400
# 获取高频话题
high_freq_topics = get_high_frequency_topics()
# 获取情感摘要
sentiment_summary = get_sentiment_summary()
# 调用 AI 进行分析
ai_reply = chat_with_ai(user_message, high_freq_topics, sentiment_summary)
return jsonify({'reply': ai_reply})
except Exception as e:
print(f"AI 聊天错误: {e}")
return jsonify({'reply': '抱歉,分析时出现了问题。请稍后再试。'}), 500
def chat_with_ai(user_message, high_freq_topics, sentiment_summary):
api_url = 'https://api.gptsapi.net/v1/chat/completions' # 确认这个 URL 是否正确
api_key = 'sk-mvOc5002d4fec6492dda97092933450e3daea29ad09eYKtV' # 从环境变量中获取 API 密钥
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}' # 假设 API 使用 Bearer Token 认证
}
# 构建提示内容,包含词频和情感摘要
analysis_context = (
f"以下是福州大学当前的舆情数据分析:\n"
f"用户输入的文本: {user_message}\n"
f"高频话题: {', '.join(high_freq_topics)}\n"
f"情感分析:\n"
)
for emotion, count in sentiment_summary.items():
analysis_context += f"- {emotion}: {count}\n"
# 完整的用户提示
full_user_message = (
f"{analysis_context}\n"
f"基于以上数据,请对福州大学的当前舆情进行详细分析,并提供相关建议。"
)
payload = {
"model": "gpt-4o",
"messages": [
{"role": "system", "content": "你是一个帮助分析福州大学舆情的助手。请你尽可能地分析和猜测福州大学的舆论和学生情绪,大家目前关心什么话题"},
{"role": "user", "content": full_user_message}
],
"max_tokens": 500,
"temperature": 0.7
}
try:
response = requests.post(api_url, headers=headers, json=payload, timeout=60)
response.raise_for_status() # 如果响应状态码不是 2xx,会抛出异常
data = response.json()
print(f"API Response: {json.dumps(data, ensure_ascii=False, indent=2)}") # 调试输出
# 提取 AI 的回复
ai_reply = data['choices'][0]['message']['content'].strip()
return ai_reply
except requests.exceptions.HTTPError as http_err:
print(f"HTTP 错误发生: {http_err}") # HTTP 错误
return '抱歉,分析时出现了问题。请稍后再试。'
except requests.exceptions.Timeout:
print("请求超时") # 超时
return '抱歉,服务器响应超时。请稍后再试。'
except requests.exceptions.RequestException as err:
print(f"请求错误: {err}") # 其他请求错误
return '抱歉,出现了一个错误。请稍后再试。'
except KeyError:
print("响应结构异常")
return '抱歉,收到的回复格式不正确。'
def chat_with_ai1(user_message):
api_url = 'https://api.gptsapi.net/v1/chat/completions' # 确认这个 URL 是否正确
api_key = 'sk-mvOc5002d4fec6492dda97092933450e3daea29ad09eYKtV' # 从环境变量中获取 API 密钥
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}' # 假设 API 使用 Bearer Token 认证
}
# 构建提示内容,包含词频和情感摘要
analysis_context = (
f"以下是福州大学当前的舆情数据分析:\n"
f"用户搜索到的关键词和数据: {user_message}\n"
)
# 完整的用户提示
full_user_message = (
f"{analysis_context}\n"
f"基于以上数据,请对福州大学的当前舆情进行详细分析,并提供相关建议。"
)
payload = {
"model": "gpt-4o",
"messages": [
{"role": "system", "content": "你是一个帮助分析福州大学舆情的助手。请你尽可能地分析和猜测福州大学的舆论和学生情绪,大家目前关心什么话题"},
{"role": "user", "content": full_user_message}
],
"max_tokens": 500,
"temperature": 0.7
}
try:
response = requests.post(api_url, headers=headers, json=payload, timeout=60)
response.raise_for_status() # 如果响应状态码不是 2xx,会抛出异常
data = response.json()
print(f"API Response: {json.dumps(data, ensure_ascii=False, indent=2)}") # 调试输出
# 提取 AI 的回复
ai_reply = data['choices'][0]['message']['content'].strip()
return ai_reply
except requests.exceptions.HTTPError as http_err:
print(f"HTTP 错误发生: {http_err}") # HTTP 错误
return '抱歉,分析时出现了问题。请稍后再试。'
except requests.exceptions.Timeout:
print("请求超时") # 超时
return '抱歉,服务器响应超时。请稍后再试。'
except requests.exceptions.RequestException as err:
print(f"请求错误: {err}") # 其他请求错误
return '抱歉,出现了一个错误。请稍后再试。'
except KeyError:
print("响应结构异常")
return '抱歉,收到的回复格式不正确。'
4. 整体技术架构与协同
- 负责后端接口与数据库交互逻辑,完成 Flask 路由的编写;
- 与前端配合设计可视化图表、分页展示、日历印章彩蛋等,增强项目功能与用户体验。
- 整体进度的跟进和把控,帮助别人收尾debug
通过上述团队协作,本项目已经基本实现对福州大学多模态网络舆情的采集、分析和可视化闭环,为高校舆情监控提供一体化解决方案。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号