数据采集与融合实践四
| 这个作业属于哪个课程 | 2024数据采集与融合班级 |
|---|---|
| 本次作业的码云 | fufubuff_python爬虫实践作业4 |
| 这次作业的链接 | 数据采集与融合第四次作业 |
| 学号姓名 | 102202141黄昕怡 |
作业一

作业目的
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。使用Selenium框架结合MySQL数据库存储技术路线,爬取“沪深A股”、“上证A股”、“深证A股”三个板块的股票数据信息。
候选网站:
东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息:
将数据存储到MySQL数据库中,表头采用英文命名,例如:序号id,股票代码bCode,等。
实现步骤
本项目使用Selenium框架结合MySQL数据库,爬取“沪深A股”、“上证A股”、“深证A股”三个板块的股票数据信息。具体实现步骤如下:
-
环境搭建
- 安装Python及相关依赖库(Selenium、PyMySQL等)。
- 配置Chrome浏览器及对应的WebDriver。
- 搭建MySQL数据库,并创建相应的数据表。
-
编写爬虫代码
- 使用Selenium模拟浏览器行为,访问东方财富网的股票列表页面。
- 通过XPath定位并提取所需的股票信息。
- 处理分页,确保抓取所有页面的数据。
-
数据存储
- 将抓取到的数据通过PyMySQL存入MySQL数据库。
- 设计合理的数据库表结构,确保数据的完整性和可查询性。
-
运行与调试
- 执行爬虫脚本,监控抓取过程,处理可能出现的异常。
- 验证数据库中的数据是否完整、准确。
核心代码
创造Mysql的数据库
CREATE DATABASE fufubuff CHARACTER SET utf8 COLLATE utf8_general_ci;
USE fufubuff;
-- 创建股票信息表
CREATE TABLE stocks1 (
id INT PRIMARY KEY,
bCode VARCHAR(20),
bName VARCHAR(50),
bLatestPrice DECIMAL(10, 2),
bUpDownRange DECIMAL(10, 2),
bUpDownPrice DECIMAL(10, 2),
bTurnover DECIMAL(20, 2),
bTurnoverNum VARCHAR(50),
bAmplitude DECIMAL(10, 2),
bHighest DECIMAL(10, 2),
bLowest DECIMAL(10, 2),
bToday DECIMAL(10, 2),
bYesterday DECIMAL(10, 2)
);
stock_spider.py
# stock_spider.py
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
import pymysql
from selenium.webdriver.common.by import By
class getStocks:
headers = {
"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US;rv:1.9pre)"
"Gecko/2008072421 Minefield/3.0.2pre"
}
num = 1
def startUp(self, url):
# 建立浏览器对象
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(options=chrome_options)
try:
# 与MySQL建立连接
self.con = pymysql.connect(
host="localhost",
port=3306,
user="root",
passwd="hhxxyy120",
db="fufubuff",
charset="utf8"
)
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("DELETE FROM stocks1")
except Exception as err:
print(err)
self.driver.get(url)
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err)
def insertDB(self, id, bCode, bName, bLatestPrice, bUpDownRange, bUpDownPrice, bTurnover, bTurnoverNum, bAmplitude, bHighest, bLowest, bToday, bYesterday):
try:
print(id, bCode, bName, bLatestPrice, bUpDownRange, bUpDownPrice, bTurnover, bTurnoverNum, bAmplitude, bHighest, bLowest, bToday, bYesterday)
self.cursor.execute(
"INSERT INTO stocks1 (id, bCode, bName, bLatestPrice, bUpDownRange, bUpDownPrice, bTurnover, "
"bTurnoverNum, bAmplitude, bHighest, bLowest, bToday, bYesterday) VALUES "
"(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)",
(id, bCode, bName, bLatestPrice, bUpDownRange, bUpDownPrice, bTurnover, bTurnoverNum, bAmplitude, bHighest, bLowest, bToday, bYesterday)
)
except Exception as err:
print(err)
def processSpider(self):
try:
time.sleep(1)
# 输出当前URL
print(self.driver.current_url)
trs = self.driver.find_elements(By.XPATH, "//div[@class='listview full']/table[@id='table_wrapper-table']/tbody/tr")
for tr in trs:
# 使用XPath获取信息
id = tr.find_element(By.XPATH, "./td[position()=1]").text
bCode = tr.find_element(By.XPATH, "./td[position()=2]/a").text
bName = tr.find_element(By.XPATH, "./td[position()=3]/a").text
bLatestPrice = tr.find_element(By.XPATH, "./td[position()=5]/span").text
bUpDownRange = tr.find_element(By.XPATH, "./td[position()=6]/span").text
bUpDownPrice = tr.find_element(By.XPATH, "./td[position()=7]/span").text
bTurnover = tr.find_element(By.XPATH, "./td[position()=8]").text
bTurnoverNum = tr.find_element(By.XPATH, "./td[position()=9]").text
bAmplitude = tr.find_element(By.XPATH, "./td[position()=10]").text
bHighest = tr.find_element(By.XPATH, "./td[position()=11]/span").text
bLowest = tr.find_element(By.XPATH, "./td[position()=12]/span").text
bToday = tr.find_element(By.XPATH, "./td[position()=13]/span").text
bYesterday = tr.find_element(By.XPATH, "./td[position()=14]").text
self.insertDB(id, bCode, bName, bLatestPrice, bUpDownRange, bUpDownPrice, bTurnover, bTurnoverNum, bAmplitude, bHighest, bLowest, bToday, bYesterday)
# 翻页操作
try:
self.driver.find_element(By.XPATH, "//div[@class='dataTables_wrapper']//div[@class='dataTables_paginate paging_input']//a[@class='next paginate_button disabled']")
except:
nextPage = self.driver.find_element(By.XPATH, "//div[@class='dataTables_wrapper']//div[@class='dataTables_paginate paging_input']//a[@class='next paginate_button']")
time.sleep(10)
self.num += 1
if self.num < 4:
nextPage.click()
self.processSpider()
except Exception as err:
print(err)
def executeSpider(self, url):
print("Spider starting......")
self.startUp(url)
print("Spider processing......")
# 分别爬取三种股票
print("沪深A股")
self.processSpider()
self.num = 1
url = "http://quote.eastmoney.com/center/gridlist.html#sh_a_board"
self.driver.get(url)
print("上证A股")
self.processSpider()
self.num = 1
url = "http://quote.eastmoney.com/center/gridlist.html#sz_a_board"
self.driver.get(url)
print("深证A股")
self.processSpider()
print("Spider closing......")
self.closeUp()
if __name__ == "__main__":
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
spider = getStocks()
spider.executeSpider(url)
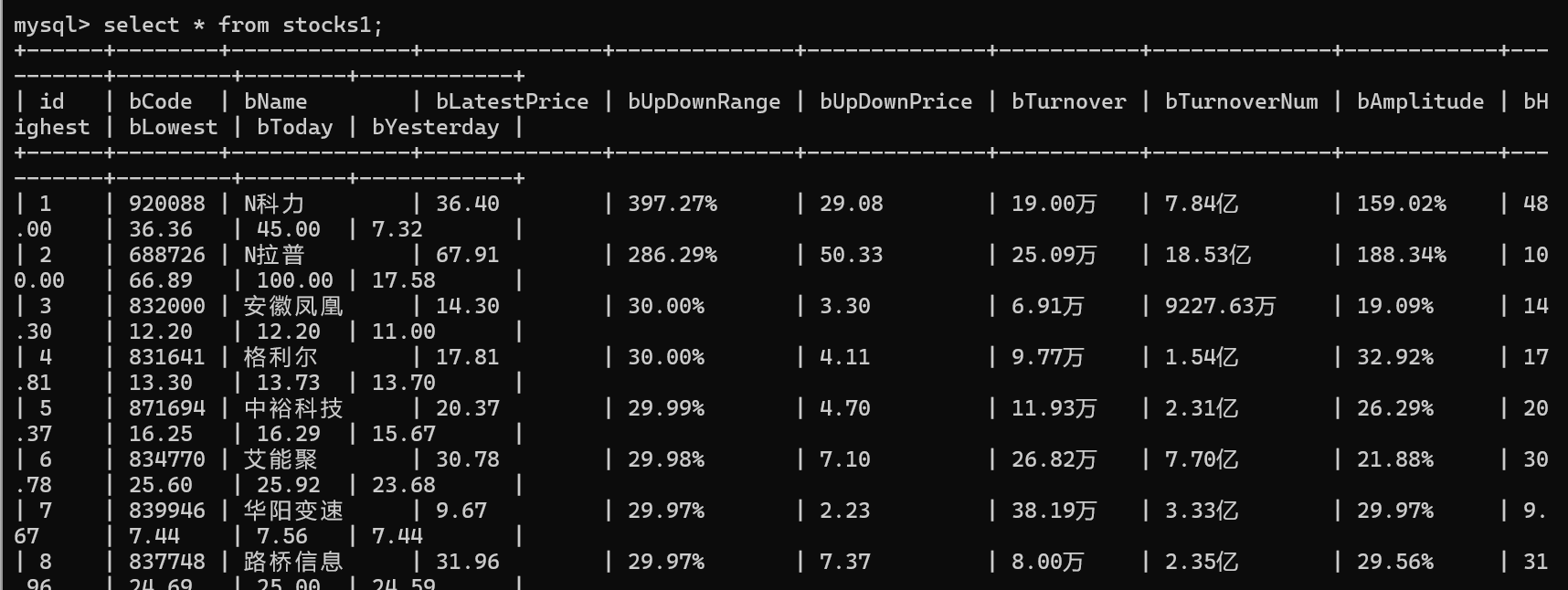
实验结果
通过运行上述爬虫脚本,成功抓取了“沪深A股”、“上证A股”、“深证A股”三个板块的股票数据信息,并将数据存储在MySQL数据库的stocks1表中。数据包括股票代码、名称、最新价格、涨跌幅、涨跌价、成交量、成交金额、振幅、最高价、最低价、今开价、昨收价等信息。以下在mysql终端检索的部分抓取的数据示例:
遇到的困难及解决方案
困难 1:数据库连接问题和数据导出问题
问题描述:
在初次连接MySQL数据库时,常常遇到连接失败或数据插入错误的问题,尤其是在处理大量数据时,可能导致数据导出不完整。
解决方案:
- 检查数据库配置: 确保数据库主机、端口、用户名、密码和数据库名配置正确。
- 使用异常处理: 在代码中添加异常捕捉,及时捕获并输出错误信息,方便排查问题。
- 优化数据插入: 使用事务处理,减少单次插入的开销,提高效率和稳定性。
困难 2:分页处理
问题描述:
东方财富网的股票列表页面采用分页加载,如何有效处理分页,确保所有页面的数据都被抓取,是一个挑战。
解决方案:
- XPath定位分页按钮: 通过XPath准确定位“下一页”按钮,模拟点击行为进行翻页。
- 控制翻页次数: 设置翻页的最大次数(如3页),防止无限翻页导致程序崩溃。
- 等待页面加载: 在翻页后,适当等待页面内容加载完成(如
time.sleep(10)),确保数据提取的准确性。
心得体会
面对动态网页的数据抓取
在处理动态网页时,传统的静态抓取方法难以应对JavaScript渲染的内容。通过使用Selenium模拟浏览器行为,可以有效地处理动态加载的数据,获取完整的信息。我们需要要合理控制等待时间和翻页逻辑,确保抓取过程的稳定性和效率。
深入理解数据库操作
本项目加深了对MySQL数据库操作的理解。从建立连接、创建表结构、编写插入语句到处理事务,每一个环节都需要细致入微的掌握。通过实践,学会了如何设计合理的表结构,如何优化数据插入,提高数据库操作的效率和可靠性。此外,异常处理和错误排查也是保障数据完整性的重要手段。
作业二
作业要求
熟练掌握以下内容:
- 使用Selenium查找HTML元素
- 实现用户模拟登录
- 爬取Ajax网页数据
- 等待HTML元素加载
技术路线:
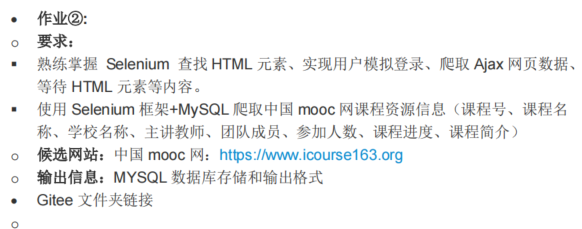
使用Selenium框架结合MySQL数据库,爬取中国mooc网的课程资源信息,包括课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度及课程简介。
候选网站:
中国mooc网:https://www.icourse163.org
输出信息:
将爬取的数据存储到MySQL数据库中,表头采用英文命名,例如:cCourse(课程名称)、cCollege(学校名称)、cTeacher(主讲教师)等。
实现步骤
本项目使用Selenium框架结合MySQL数据库,爬取中国mooc网的课程资源信息。具体实现步骤如下:
-
环境搭建
- 安装Python及相关依赖库(Selenium、PyMySQL、BeautifulSoup等)。
- 配置Chrome浏览器及对应的WebDriver。
- 搭建MySQL数据库,并创建相应的数据表。
-
编写爬虫代码
- 使用Selenium模拟浏览器行为,访问中国mooc网。
- 实现用户模拟登录,输入手机号和密码进行登录。
- 使用Selenium查找HTML元素,模拟搜索课程。
- 爬取Ajax加载的网页数据,提取课程信息。
- 处理分页,确保抓取所有页面的数据。
-
数据存储
- 将抓取到的数据通过PyMySQL存入MySQL数据库。
- 设计合理的数据库表结构,确保数据的完整性和可查询性。
-
运行与调试
- 执行爬虫脚本,监控抓取过程,处理可能出现的异常。
- 验证数据库中的数据是否完整、准确。
核心代码
在mysql上的搭建
MYSQL中需要创建的表的内容:
create database mydb;
use fufubuff;
CREATE TABLE mooc (
id INT AUTO_INCREMENT PRIMARY KEY,
course TEXT,
college TEXT,
teacher TEXT,
team TEXT,
count INT,
process TEXT,
brief TEXT
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
course_spider.py
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
import random
import pymysql
from selenium.common.exceptions import NoSuchElementException
# 连接数据库
conn = pymysql.connect(
host="127.0.0.1",
user="root",
password="hhxxyy120",
database="fufubuff",
charset="utf8mb4",
cursorclass=pymysql.cursors.DictCursor
)
cursor = conn.cursor()
# 创建表格
cursor.execute('''CREATE TABLE IF NOT EXISTS mooc (
id INTEGER PRIMARY KEY,
course TEXT,
college TEXT,
teacher TEXT,
team TEXT,
count INTEGER,
process TEXT,
brief TEXT
)''')
# 初始化浏览器
driver = webdriver.Chrome()
# 打开网页
driver.maximize_window()
driver.get("https://www.icourse163.org/")
# 登录
login_button = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div')))
login_button.click()
# 切换到登录框的iframe
driver.switch_to.default_content()
driver.switch_to.frame(driver.find_elements(By.TAG_NAME, 'iframe')[0])
# 输入用户名和密码
username = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input')))
username.clear()
username.send_keys("13859087027")
password = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]')
password.send_keys("Hhxxyy120")
# 点击登录按钮
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.ID, "submitBtn"))).click()
# 切换回主页面
driver.switch_to.default_content()
# 等待搜索框出现
search_box = WebDriverWait(driver, 20).until(EC.presence_of_element_located((By.CSS_SELECTOR, 'input.ant-input[type="text"]')))
search_box.clear()
# 在搜索框输入关键词
search_box.send_keys("高数", Keys.RETURN)
# 开始爬取数据的函数
def start_spider():
# 等待课程列表加载完成
WebDriverWait(driver, 10).until(EC.presence_of_all_elements_located((By.XPATH, '//div[@class="m-course-list"]/div/div')))
# 模拟滚动到页面底部
driver.execute_script('document.documentElement.scrollTop=10000')
# 等待加载新的课程列表
WebDriverWait(driver, random.randint(3, 6)).until(EC.presence_of_element_located((By.XPATH, '//div[@class="m-course-list"]/div/div')))
# 滚动到页面顶部
driver.execute_script('document.documentElement.scrollTop=0')
num = 0
for link in driver.find_elements(By.XPATH, '//div[@class="m-course-list"]/div/div'):
num += 1
course_name = link.find_element(By.XPATH, './/span[@class=" u-course-name f-thide"]').text
try:
school_name = link.find_element(By.XPATH, './/a[@class="t21 f-fc9"]').text
except NoSuchElementException:
school_name = ''
try:
teacher_element = link.find_element(By.XPATH, ".//div[@class='t2 f-fc3 f-nowrp f-f0']//a[@class='f-fc9']")
teacher = teacher_element.text
except NoSuchElementException:
teacher = ''
try:
teachers_element = link.find_element(By.XPATH,
".//div[@class='t2 f-fc3 f-nowrp f-f0']//span[@class='f-fc9']")
teachers = teachers_element.text
team_member = teachers + teacher
except NoSuchElementException:
team_member = ''
try:
join = link.find_element(By.XPATH, './/span[@class="hot"]').text.replace('参加', '')
except NoSuchElementException:
join = ''
try:
process = link.find_element(By.XPATH, './/span[@class="txt"]').text
except NoSuchElementException:
process = ''
try:
introduction = link.find_element(By.XPATH, './/span[@class="p5 brief f-ib f-f0 f-cb"]').text
except NoSuchElementException:
introduction = ''
try:
join_number = ''.join(filter(str.isdigit, join))
count_value = int(join_number)
# 插入数据库
cursor.execute(
"INSERT INTO mooc (id, course, college, teacher, team, count, process, brief) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)",
(num, str(course_name), str(school_name), str(teacher), str(team_member), count_value, str(process),
str(introduction)))
except Exception as err:
print("出现错误:", err)
conn.commit()
print("爬取成功")
# 主函数
def main():
start_spider()
if __name__ == '__main__':
main()
driver.quit()
conn.close()
实验结果
运行代码显示爬取成功
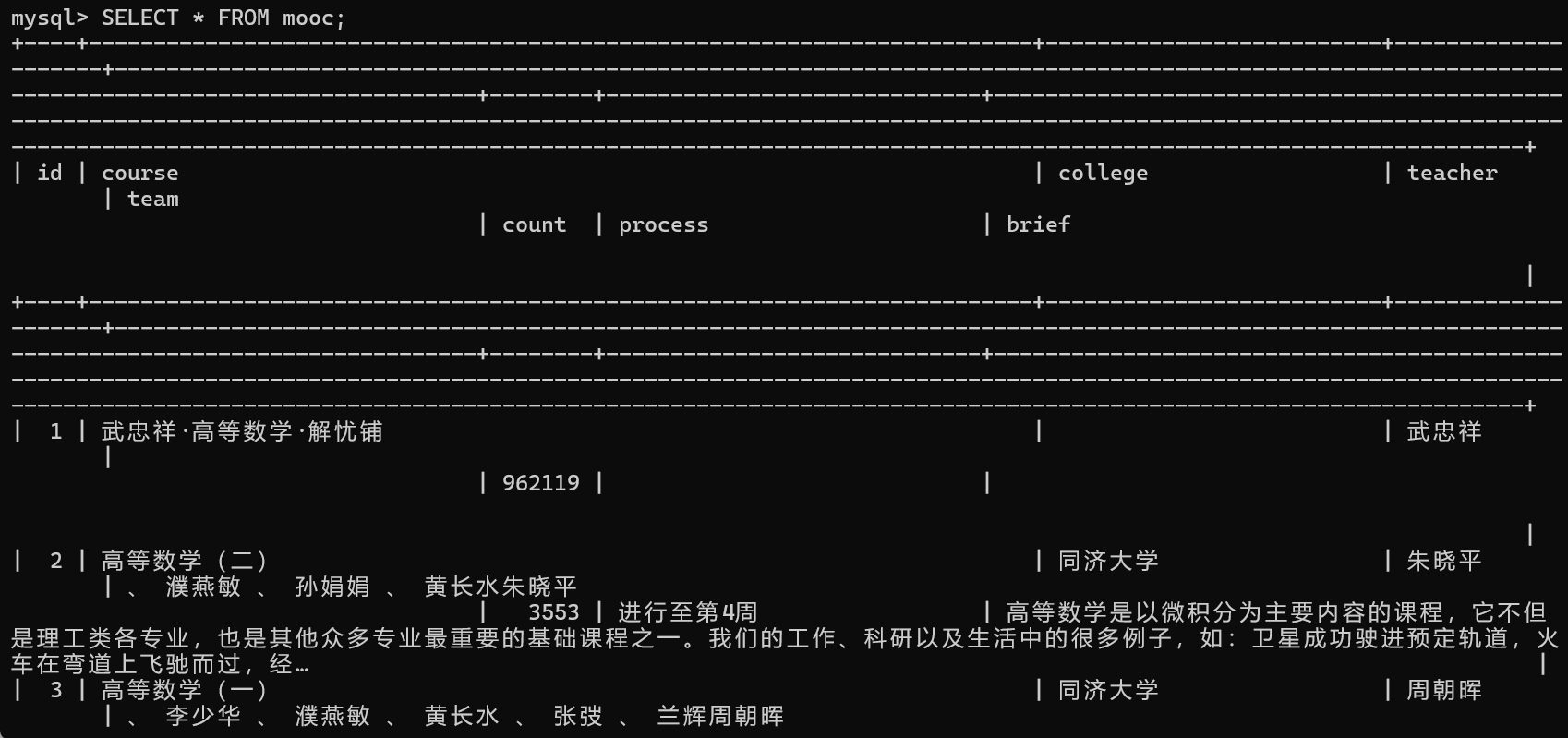
在mysql上查看

遇到的困难和解决方案
困难1. 导航到下一页时找不到元素的错误
问题描述:
在尝试点击“下一页”按钮时,Selenium 无法找到该元素,导致程序报错。
解决方案:
添加了 WebDriverWait,确保在尝试点击之前,元素是可点击的。这可以等待元素加载完成,避免因页面未完全加载而找不到元素的问题。
next_page = WebDriverWait(driver, 20).until(
EC.element_to_be_clickable((By.XPATH, '//a[contains(@class, "next-page-selector")]'))
)
next_page.click()
困难2. 页面上的元素可能并不总是存在
**问题描述: **
某些页面元素在特定情况下可能不存在,直接访问会导致程序崩溃。
**解决方案: **
将元素的交互操作包装在 try-except 块中,处理元素缺失的情况,避免程序因找不到元素而中断。
try:
teacher = link.find_element(By.XPATH, ".//div[contains(@class, 't2')]/a[contains(@class, 'f-fc9')]").text
except NoSuchElementException:
teacher = ''
困难3. 搜索框位置找不到
问题描述:
网页中搜索框的位置和属性发生变化,原有的绝对 XPath 无法准确定位。
解决方案:
使用搜索框的 placeholder 属性或 class 和 type 属性进行相对定位,避免依赖绝对路径,提高脚本的稳定性。
search_box = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'input.ant-input[type="text"]'))
)
心得体会
面对网页元素定位的困难
在本项目中,网页元素的定位成为了一大挑战。中国MOOC网的页面结构复杂且经常更新,使得我在使用Selenium定位特定元素时屡屡遇到困难。每当网站的HTML结构发生变化,原本有效的XPath或CSS选择器便失效,导致脚本无法正常工作。这种不确定性不仅增加了调试的难度,也让我深刻体会到在动态网页环境中进行自动化操作的复杂性。通过不断尝试和调整,我逐渐掌握了如何灵活运用各种定位方法,并学会了耐心与细致,这对提升我的编程能力和解决问题的能力起到了积极的促进作用。
确保翻页的心得和总结
在数据爬取过程中,确保能够顺利翻页是另一个重要的挑战。由于MOOC网站采用了动态加载内容的方式,翻页按钮的状态和位置时常变化,使得脚本在自动化点击“下一页”时频频失效。这不仅影响了数据的完整性,也让我意识到在处理分页逻辑时需要更加严谨和细致。每当遇到翻页失败的情况,我都需要仔细分析页面的变化,调整脚本的逻辑,确保能够准确识别和操作翻页按钮。这一过程不仅锻炼了我的逻辑思维能力,也让我更加深入地理解了网页结构与自动化脚本之间的互动关系。
作业3

环境搭建
任务一:开通MapReduce服务
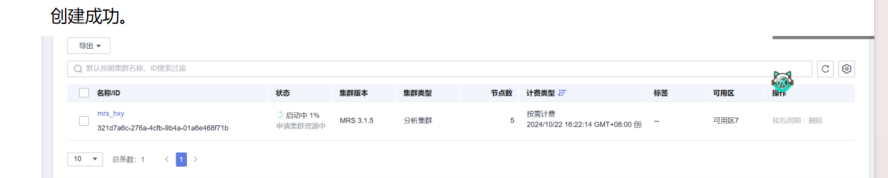
实现步骤
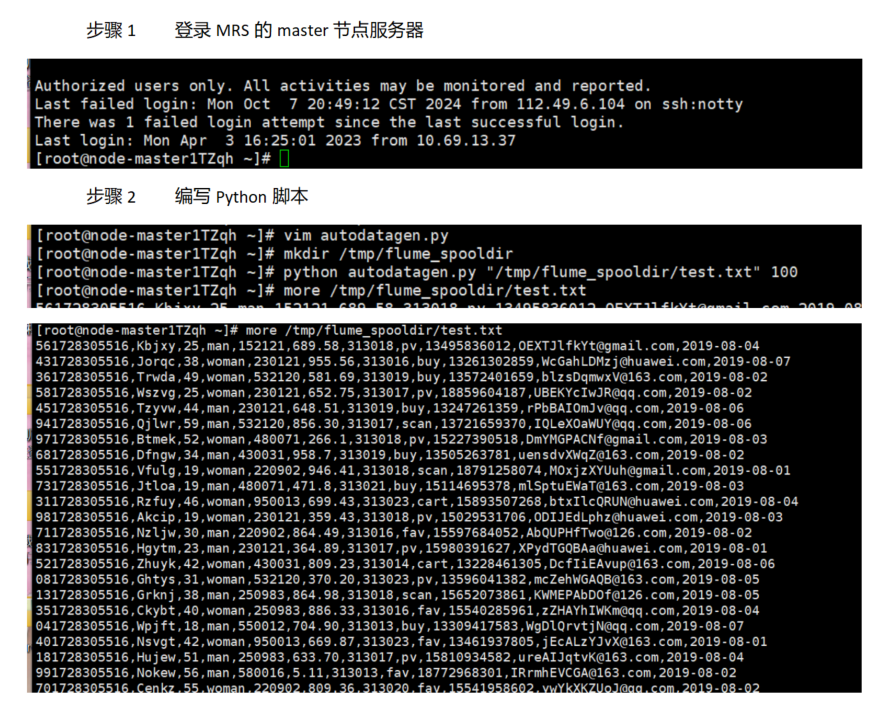
任务一:python脚本生成测试数据
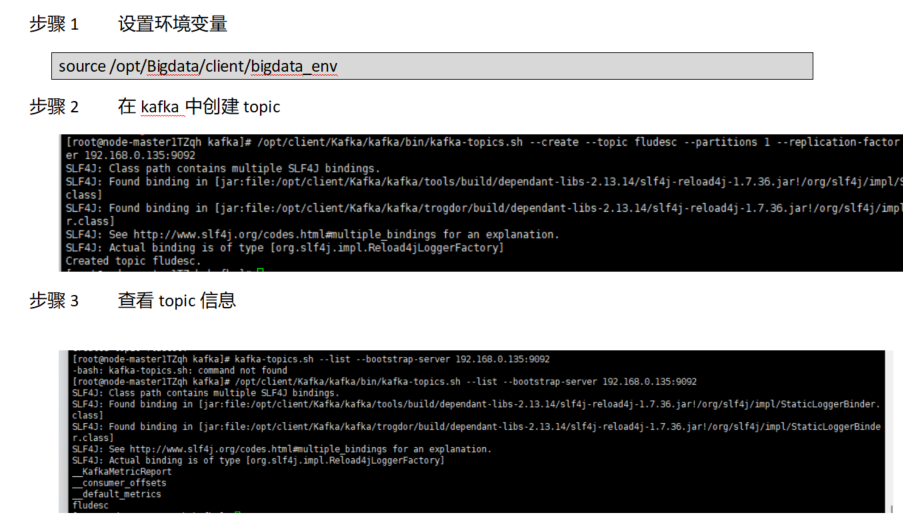
任务二:配置Kafka
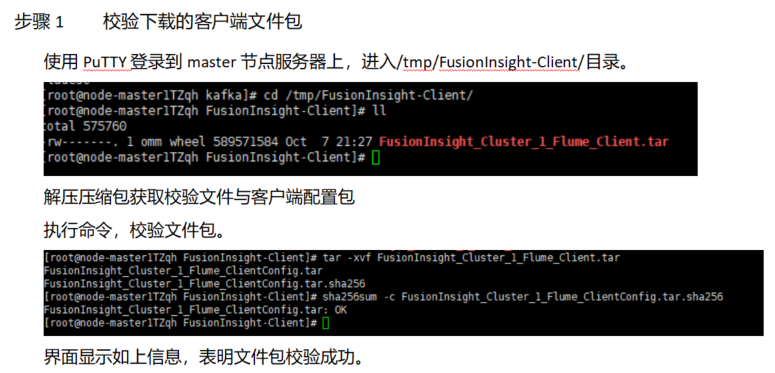
任务三:安装Flume客户端
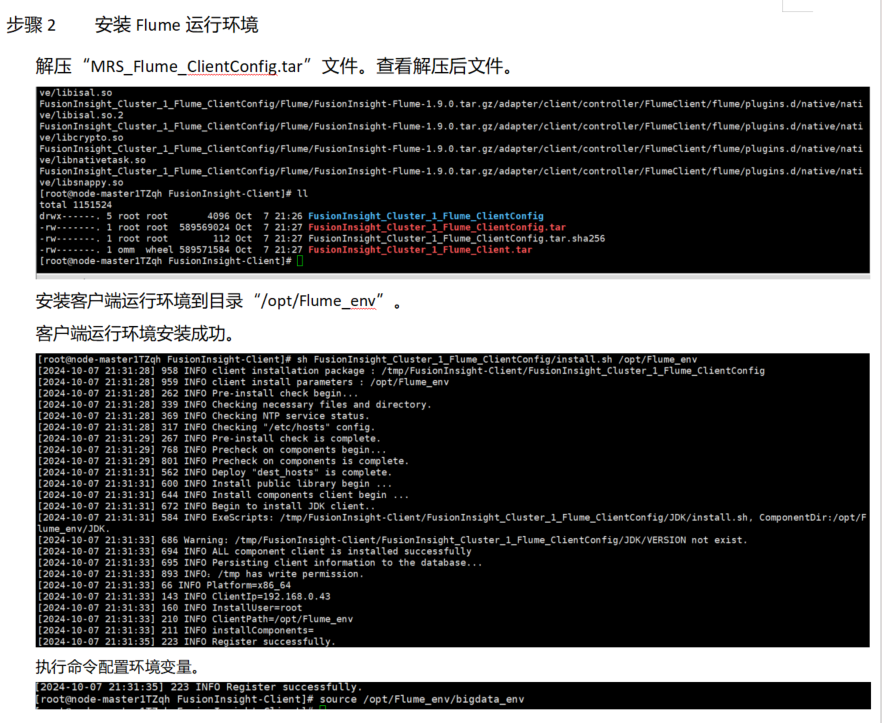
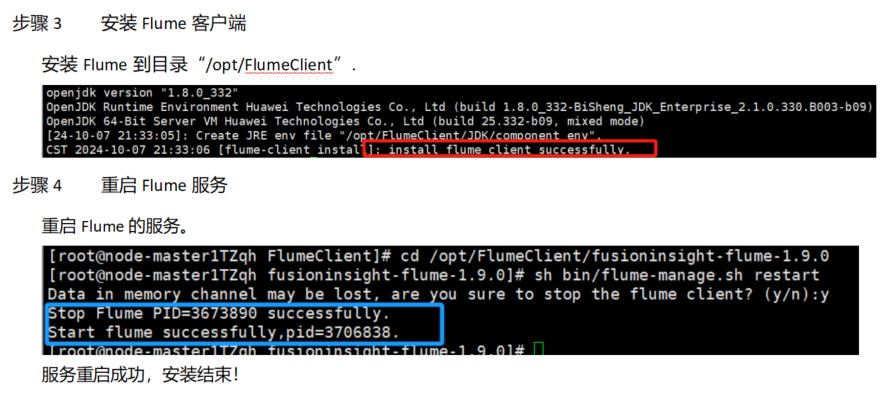
任务四:配置Flume采集数据
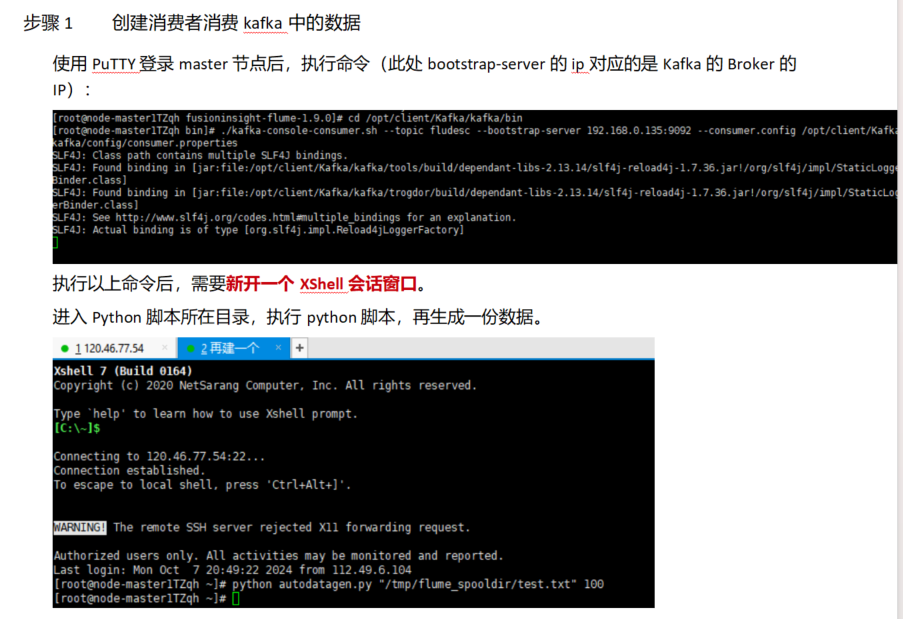
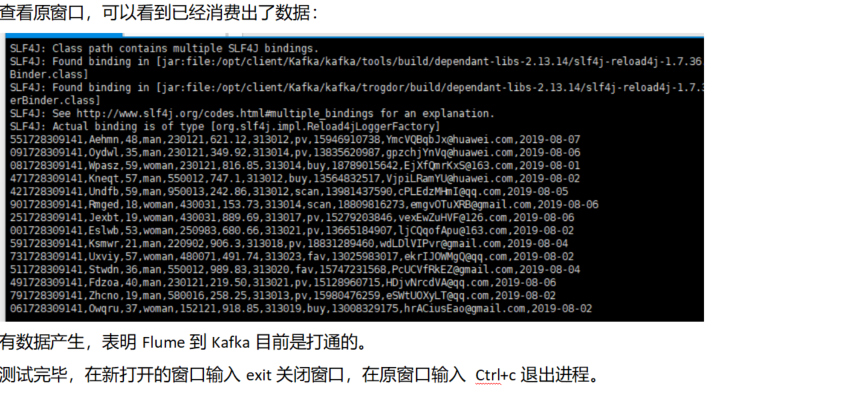
遇到的困难以及心得体会
遇到的困难
心得
整个实验过程虽然遇到了一些小问题,但通过不断查阅文档和排查,问题逐步得以解决。特别是在配置 Kafka 和 Flume 时,正确的环境设置和配置文件非常关键,稍有疏漏就会影响整个系统的运行。这个过程让我更加熟悉了 Kafka 和 Flume 的配置细节,以及如何调试和排查问题。
此外,实验中的每一个环节都离不开对细节的关注,无论是端口配置、文件路径,还是安全组设置,都需要逐一确认。通过这次实验,我对大数据处理的工具链有了更深入的了解,特别是如何将数据流从生成到采集再到处理,整个过程中的每个环节都是紧密相连的。
总结来说,虽然遇到了一些配置和环境方面的困难,但通过一步步排查和解决,最终完成了实验,也提升了我对大数据系统的配置和调试能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号