数据采集与融合实践第三次作业
| 这个作业属于哪个课程 | 2024数据采集与融合班级 |
|---|---|
| 本次作业的码云 | fufubuff_python爬虫实践作业3 |
| 这次作业的链接 | 数据采集与融合第二次作业 |
| 学号姓名 | 102202141黄昕怡 |
作业内容概况
作业一
作业要求

开发环境
- 编程语言:Python 3.8
- 爬虫框架:Scrapy 2.5
- 开发工具:PyCharm 2021.1
- 操作系统:Windows 10
实现步骤
步骤一:环境准备
首先,确保已安装 Python 和 Scrapy。可以通过以下命令安装 Scrapy:
pip install scrapy
步骤创建 Scrapy 项目
使用 Scrapy 的命令行工具创建一个新的项目:
scrapy startproject weather_scraper
cd weather_scraper
步骤三:定义 Item
编辑 weather_scraper/items.py 文件,定义一个 WeatherItem 用于存储图片的 URL:
import scrapy
class WeatherItem(scrapy.Item):
img_url = scrapy.Field()
pass
步骤四:编写爬虫
在 weather_scraper/spiders 目录下创建 scrapy_weather.py,编写爬虫逻辑:
# scrapy_weather.py
import scrapy
from urllib.parse import urljoin
from weather_scraper.items import WeatherItem
class ScrapyWeatherSpider(scrapy.Spider):
name = "scrapy_weather"
allowed_domains = ["weather.com.cn"]
start_urls = ["http://www.weather.com.cn"]
def parse(self, response):
# Extract all image src attributes
imgs = response.css('img::attr(src)').getall()
for img_src in imgs:
# Ensure the image URL is absolute
img_url = response.urljoin(img_src)
# Validate the URL
if img_url.startswith('http'):
item = WeatherItem()
item['img_url'] = img_url
yield item
else:
self.logger.warning(f'Invalid image URL skipped: {img_url}')
步骤五:配置图片管道
在 weather_scraper/pipelines.py 中配置图片管道,以便下载并保存图片:
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class WeatherImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
img_url = item.get('img_url')
if img_url:
yield scrapy.Request(url=img_url)
else:
self.logger.warning(f'Missing img_url in item: {item}')
def file_path(self, request, response=None, info=None, *, item=None):
image_name = request.url.split('/')[-1]
return image_name
在 settings.py 中进行以下配置:
`BOT_NAME = 'weather_scraper'
SPIDER_MODULES = ['weather_scraper.spiders']
NEWSPIDER_MODULE = 'weather_scraper.spiders'
# 用户代理
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'
# 是否遵守robots.txt规则
ROBOTSTXT_OBEY = False
# 并发请求
CONCURRENT_REQUESTS = 32
# 图片管道激活
ITEM_PIPELINES = {
'weather_scraper.pipelines.WeatherImagesPipeline': 300,
}
# 媒体允许重定向
MEDIA_ALLOW_REDIRECTS = True
# 图片存储路径
IMAGES_STORE = './images'
DOWNLOAD_DELAY = 1
LOG_LEVEL = 'DEBUG'
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
步骤六:运行爬虫
在项目根目录下运行爬虫,开始抓取图片:
scrapy crawl scrapy_weather
实验结果
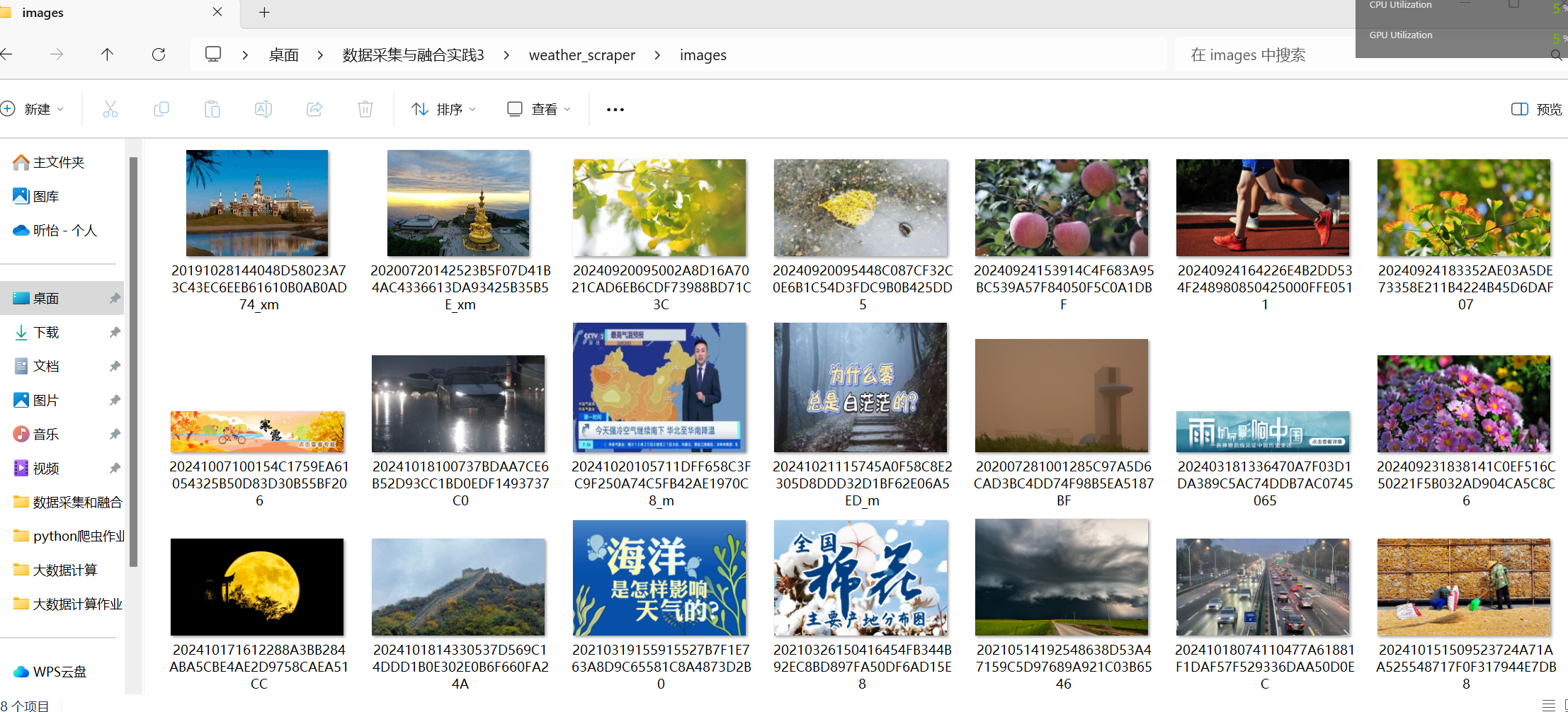
遇到的困难和解决方案
在本次作业中,我遇到了以下困难,并通过分析和调整代码成功解决。
1. ValueError: Missing scheme in request url
错误详情:
在运行爬虫时,控制台出现以下错误信息:
ValueError: Missing scheme in request url: h
原因分析:
- 该错误提示请求的 URL 缺少协议部分(如
http://或https://)。 - 这是由于在爬虫中提取的图片链接为相对路径,未转换为绝对 URL,导致
scrapy.Request无法识别。
解决方案:
- 使用
response.urljoin()方法: 该方法可以将相对路径转换为包含协议和域名的完整绝对路径。 - 更新爬虫代码:
# scrapy_weather.py
import scrapy
from weather_scraper.items import WeatherItem
class ScrapyWeatherSpider(scrapy.Spider):
name = "scrapy_weather"
allowed_domains = ["weather.com.cn"]
start_urls = ["http://www.weather.com.cn"]
def parse(self, response):
# 提取所有图片的 src 属性
imgs = response.css('img::attr(src)').getall()
for img_src in imgs:
# 将相对路径转换为绝对 URL
img_url = response.urljoin(img_src)
# 检查 URL 的有效性
if img_url.startswith('http'):
item = WeatherItem()
item['img_url'] = img_url
yield item
else:
self.logger.warning(f'Invalid image URL skipped: {img_url}')
效果验证: 修改后,错误消失,图片 URL 能够正确解析并下载。
2. KeyError: 'WeatherItem does not support field: img_url'
错误详情:
在运行爬虫时,出现以下错误信息:
KeyError: 'WeatherItem does not support field: img_url'
原因分析:
该错误是由于在 WeatherItem 类中未定义 img_url 字段,但在爬虫和管道中使用了 item['img_url'],导致字段不存在的错误。
解决方案:
在 items.py 中添加 img_url 字段:
import scrapy
class WeatherItem(scrapy.Item):
img_url = scrapy.Field()
确保字段名称一致: 检查爬虫和管道代码,确认使用的字段名称与 items.py 中定义的一致。
效果验证: 修改后,KeyError 错误消失,爬虫能够正常运行并处理图片链接。
心得体会
通过本次作业,我深入学习了 Scrapy 框架的基本使用方法,包括如何创建项目、定义 Item、编写爬虫和配置管道。实践过程中,我更加熟悉了爬虫的配置和优化,尤其是如何处理和保存网络上的图片资源。
在编写爬虫时,我注意到需要处理图片 URL 的完整性,使用 response.urljoin() 可以确保获取到完整的图片链接。此外,配置图片管道时,需要正确设置 IMAGES_STORE 路径,以确保图片能够正确保存。
这次实践加深了我对 Web 爬虫技术的理解,为未来的数据采集和分析工作打下了坚实的基础。
我深刻体会到代码细节和一致性的重要性。主要有以下收获:
1.字段命名的一致性: 在 Scrapy 中,Item、Spider 和 Pipeline 之间的数据传递依赖于字段名称的一致性。字段命名不一致会导致数据无法正确传递和处理。
2.URL 的完整性: 在处理网页爬取时,提取的链接可能是相对路径,需要转换为绝对路径才能正确访问。使用 response.urljoin() 可以方便地完成这一转换。
3.错误调试的方法: 当遇到错误时,通过仔细阅读错误信息,定位到具体的代码行,然后结合 Scrapy 的文档和日志,可以有效地找到问题的根源。
4.日志的重要性: 合理地使用日志功能,可以在调试时提供有价值的信息,帮助快速定位和解决问题。
通过本次作业,我成功实现了一个功能完整的 Scrapy 爬虫,不仅掌握了 Scrapy 的核心技术,还增强了对 Python 编程的应用能力。未来,我计划进一步探索 Scrapy 的高级特性,如中间件的使用、动态内容的处理等。
作业二
作业要求
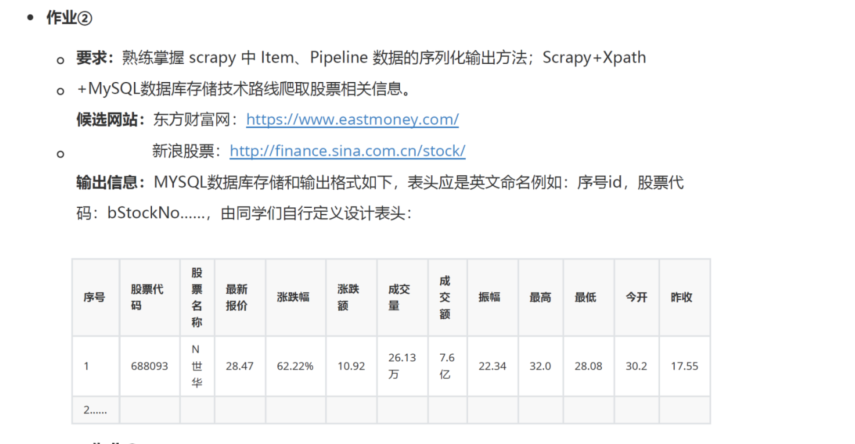
实现步骤
项目结构
stock_scraper/
│
├── spiders/
│ └── stock_spider.py # 爬虫逻辑实现
│
├── items.py # 定义抓取数据的结构
├── pipelines.py # 数据处理和保存逻辑
└── settings.py # 配置文件
核心代码
items.py
import scrapy
class StockItem(scrapy.Item):
id = scrapy.Field()
code = scrapy.Field()
name = scrapy.Field()
latest_price = scrapy.Field()
change_degree = scrapy.Field()
change_amount = scrapy.Field()
count = scrapy.Field()
money = scrapy.Field()
zfcount = scrapy.Field()
highest = scrapy.Field()
lowest = scrapy.Field()
today = scrapy.Field()
yestoday = scrapy.Field()
stock_spider.py
import scrapy
import json
from stock_scraper.items import StockItem
class StockSpider(scrapy.Spider):
name = 'stock_spider'
allowed_domains = ['eastmoney.com']
start_urls = ["http://38.push2.eastmoney.com/api/qt/clist/get?cb=..."]
def parse(self, response):
data = json.loads(response.text[response.text.find('{'):response.rfind('}') + 1])
for stock in data['data']['diff']:
item = StockItem()
item['code'] = stock['f12']
...
yield item
在mysql终端上创建
Enter password: *********
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 10
Server version: 8.0.40 MySQL Community Server - GPL
Copyright (c) 2000, 2024, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> CREATE DATABASE IF NOT EXISTS fufubuff;
Query OK, 1 row affected (0.00 sec)
mysql> USE fufubuff;
Database changed
mysql>
mysql> CREATE TABLE IF NOT EXISTS stocks (
-> id INT AUTO_INCREMENT PRIMARY KEY,
-> code VARCHAR(255),
-> name VARCHAR(255),
-> latest_price FLOAT,
-> change_degree FLOAT,
-> change_amount FLOAT,
-> count BIGINT,
-> money FLOAT,
-> zfcount FLOAT,
-> highest FLOAT,
-> lowest FLOAT,
-> today FLOAT,
-> yestoday FLOAT
-> );
Query OK, 0 rows affected (0.01 sec)
mysql> GRANT ALL PRIVILEGES ON fufubuff.* TO 'root'@'localhost' IDENTIFIED BY 'hhxxyy120'; FLUSH PRIVILEGES;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'IDENTIFIED BY 'hhxxyy120'' at line 1
Query OK, 0 rows affected (0.01 sec)BOT_NAME = 'stock_scraper'
SPIDER_MODULES = ['stock_scraper.spiders']
pipelines.py
import pymysql
from pymysql import OperationalError, MySQLError
class StockPipeline:
def open_spider(self, spider):
try:
self.conn = pymysql.connect(
host=spider.settings.get('MYSQL_HOST'),
port=spider.settings.get('MYSQL_PORT'),
user=spider.settings.get('MYSQL_USER'),
password=spider.settings.get('MYSQL_PASSWORD'),
db=spider.settings.get('MYSQL_DB'),
charset=spider.settings.get('MYSQL_CHARSET'),
cursorclass=pymysql.cursors.DictCursor
)
self.cursor = self.conn.cursor()
except OperationalError as e:
spider.logger.error(f"Could not connect to MySQL: {e}")
raise
def process_item(self, item, spider):
try:
sql = """
INSERT INTO stocks (code, name, latest_price, change_degree, change_amount, count, money, zfcount, highest, lowest, today, yestoday)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
self.cursor.execute(sql, (
item['code'], item['name'], item['latest_price'], item['change_degree'],
item['change_amount'], item['count'], item['money'], item['zfcount'],
item['highest'], item['lowest'], item['today'], item['yestoday']
))
self.conn.commit()
except MySQLError as e:
spider.logger.error(f"Failed to insert item: {e}")
self.conn.rollback()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
settings.py
# Database settings
MYSQL_HOST = 'localhost'
MYSQL_PORT = 3306
MYSQL_USER = 'fufu'
MYSQL_PASSWORD = 'hhxxyy120'
MYSQL_DB = 'fufubuff'
MYSQL_CHARSET = 'utf8mb4'
# Scrapy settings
BOT_NAME = 'stock_scraper'
SPIDER_MODULES = ['stock_scraper.spiders']
NEWSPIDER_MODULE = 'stock_scraper.spiders'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'stock_scraper.pipelines.StockPipeline': 300,
}
CONCURRENT_REQUESTS = 32
FEED_EXPORT_ENCODING = 'utf-8'
实验结果
在mysql终端上查看
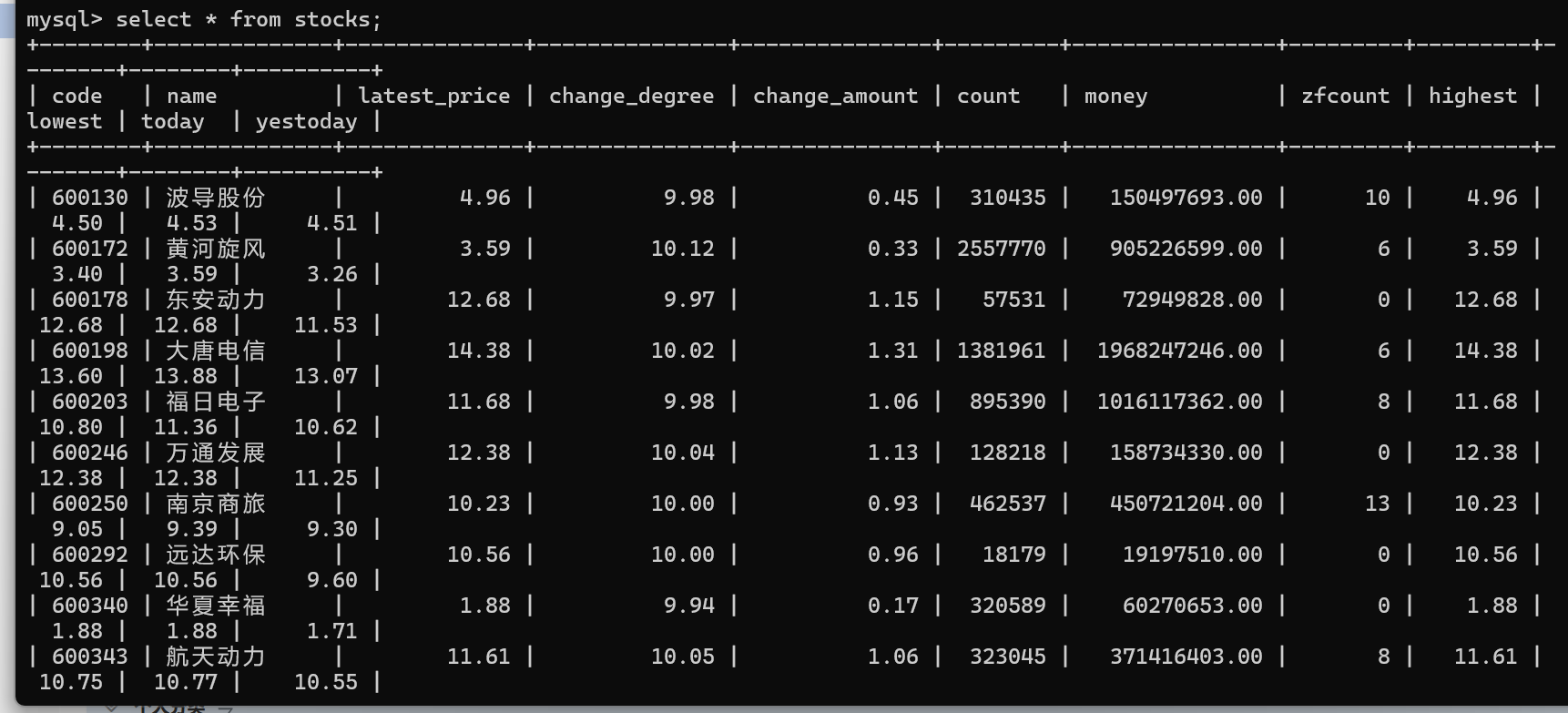
导出成csv文件

在导出的路径查看
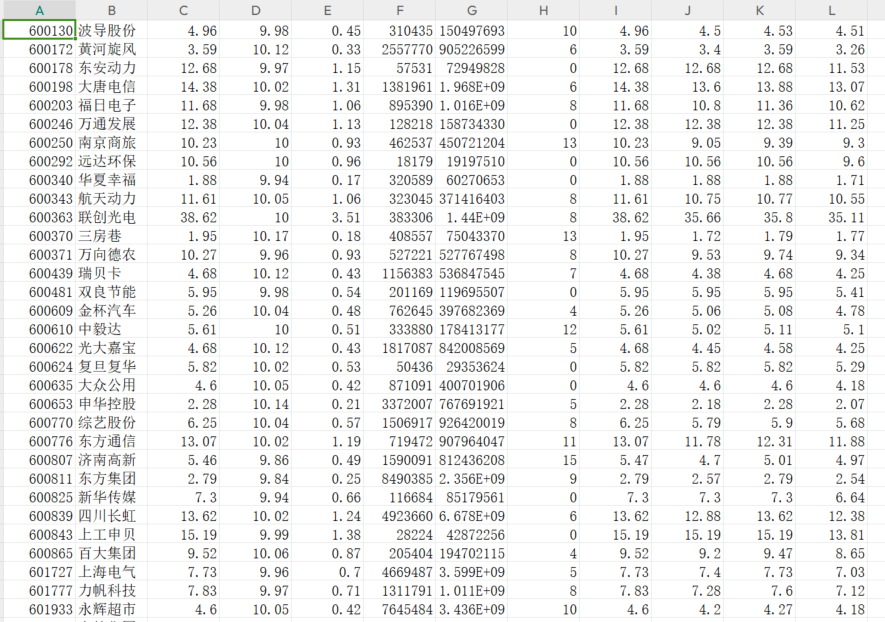
遇到的困难及解决方案
困难 1. 数据库连接问题和数据导出问题
我遇到了无法连接到 MySQL 数据库的问题。错误信息表明用户名和密码被拒绝。通过检查和修改 settings.py 中的数据库配置,并确保数据库用户具有适当的访问权限,我解决了这个问题。
在尝试使用 INTO OUTFILE 将数据导出时,由于 MySQL 的 secure_file_priv 配置,我无法将文件导出到预期路径。通过查询允许的目录并调整输出文件的路径,我解决了这个问题。
困难 2: 分页处理
问题描述: 需要处理数据分页以抓取更多数据。
解决方案: 实现自动翻页逻辑,在 parse 方法中检查是否存在下一页,并递归调用解析方法。
心得体会
面对动态网页的数据抓取
动态数据抓取的挑战:本次在作业中中的一个主要挑战来自于东方财富网的动态网页。在最初尝试爬取数据时,我注意到通过常规的 HTTP 请求无法获取到页面上显示的实时数据。这是因为网页内容是通过 JavaScript 动态生成的,而这些数据在初次页面加载时并不包含在 HTML 中。
解决方法的探索:为了解决这个问题,我采用了几种不同的策略:
抓包分析:我使用了浏览器的开发者工具对网络请求进行了深入的抓包分析。通过仔细查看网络请求的预览信息,并使用 Ctrl+F 搜索具体的股票数据,我最终找到了包含所需数据的 AJAX 请求。这个过程需要耐心和细致,因为数据隐藏在了响应内容的末尾,一开始很容易被忽略。
Scrapy 结合 Selenium:考虑到网站的数据动态加载问题,我也了解并尝试使用了 Selenium 来直接从浏览器中获取完整渲染后的页面数据。这种方法虽然处理起来较为繁琐,但能有效解决 JavaScript 动态渲染的问题。
技术的深化理解:通过这次项目,我不仅学习了如何使用 Scrapy 框架抓取静态和动态网页数据,还对如何结合 Selenium 处理复杂的网页渲染有了更深的理解和实践。此外,抓包技术对于理解 Web 应用的数据交互流程也是非常宝贵的学习经验。
深入理解数据库操作:
通过这次实验,我不仅学会了如何在 MySQL 中创建用户和数据库,还学会了如何设置和修改用户权限,这些都是实际工作中非常实用的技能。特别是在处理 secure_file_priv 的问题时,我了解到了 MySQL 安全设置的重要性及其配置方式,这在未来的数据库管理工作中将非常有帮助。
在项目过程中,我遇到了多个挑战,如数据库连接错误、权限配置问题等。每解决一个问题,我都感到自己的问题解决能力在提升。我学会了如何分析错误日志,如何查找和利用在线资源(如官方文档和技术论坛)来解决问题。在解决数据导出的问题中,我更加明白了数据安全配置的重要性。了解到不恰当的权限设置可能会导致数据泄露或被恶意访问,这让我在未来的工作中会更加注重数据的安全和保护。
作业三
作业要求

实现步骤
项目结构
forex_scraper/
│
├── spiders/
│ └── boc_forex_spider.py # 爬虫逻辑实现
│
├── items.py # 定义抓取数据的结构
├── pipelines.py # 数据处理和保存逻辑
└── settings.py # 配置文件
核心代码
items.py
import scrapy
class ForexRateItem(scrapy.Item):
currency = scrapy.Field()
tbp = scrapy.Field()
cbp = scrapy.Field()
tsp = scrapy.Field()
csp = scrapy.Field()
time = scrapy.Field()
pipelines.py
import pymysql
from pymysql import OperationalError, MySQLError
class MySQLPipeline(object):
def open_spider(self, spider):
try:
self.conn = pymysql.connect(
host=spider.settings.get('MYSQL_HOST'),
port=spider.settings.get('MYSQL_PORT'),
user=spider.settings.get('MYSQL_USER'),
password=spider.settings.get('MYSQL_PASSWORD'),
db=spider.settings.get('MYSQL_DB'),
charset=spider.settings.get('MYSQL_CHARSET'),
cursorclass=pymysql.cursors.DictCursor
)
self.cursor = self.conn.cursor()
except OperationalError as e:
spider.logger.error(f"无法连接到 MySQL: {e}")
raise
def process_item(self, item, spider):
try:
sql = """
INSERT INTO forex_rates (currency, tbp, cbp, tsp, csp, time)
VALUES (%s, %s, %s, %s, %s, %s)
"""
self.cursor.execute(sql, (
item['currency'], item['tbp'], item['cbp'], item['tsp'], item['csp'], item['time']
))
self.conn.commit()
except MySQLError as e:
spider.logger.error(f"插入数据失败: {e}")
self.conn.rollback()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
settings.py
# Database settings
MYSQL_HOST = 'localhost'
MYSQL_PORT = 3306
MYSQL_USER = 'fufu'
MYSQL_PASSWORD = 'hhxxyy120'
MYSQL_DB = 'fufubuff'
MYSQL_CHARSET = 'utf8mb4'
# Scrapy settings
BOT_NAME = 'forex_scraper'
SPIDER_MODULES = ['forex_scraper.spiders']
NEWSPIDER_MODULE = 'forex_scraper.spiders'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'forex_scraper.pipelines.MySQLPipeline': 300,
}
CONCURRENT_REQUESTS = 32
FEED_EXPORT_ENCODING = 'utf-8'
boc_forex_spider.py
import scrapy
from forex_scraper.items import ForexRateItem
class BocForexSpider(scrapy.Spider):
name = 'boc_forex'
allowed_domains = ['boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
rows = response.xpath('//div[@class="BOC_main"]/div[1]/div[2]/table//tr')[1:] # 跳过表头
for row in rows:
item = ForexRateItem()
item['currency'] = row.xpath('./td[1]/text()').get()
item['tbp'] = row.xpath('./td[2]/text()').get()
item['cbp'] = row.xpath('./td[3]/text()').get()
item['tsp'] = row.xpath('./td[4]/text()').get()
item['csp'] = row.xpath('./td[5]/text()').get()
item['time'] = row.xpath('./td[last()]/text()').get()
yield item
在 MySQL 终端上创建数据库和表
Enter password: *********
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 11
Server version: 8.0.40 MySQL Community Server - GPL
...
mysql> CREATE DATABASE IF NOT EXISTS fufubuff;
Query OK, 1 row affected (0.00 sec)
mysql> USE fufubuff;
Database changed
mysql> CREATE TABLE IF NOT EXISTS forex_rates (
-> id INT AUTO_INCREMENT PRIMARY KEY,
-> currency VARCHAR(255),
-> tbp FLOAT,
-> cbp FLOAT,
-> tsp FLOAT,
-> csp FLOAT,
-> time VARCHAR(255)
-> );
Query OK, 0 rows affected (0.01 sec)
mysql> GRANT ALL PRIVILEGES ON fufubuff.* TO 'fufu'@'localhost' IDENTIFIED BY 'hhxxyy120'; FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
mysql>
运行结果
在mysql上查看

导出结果成为csv


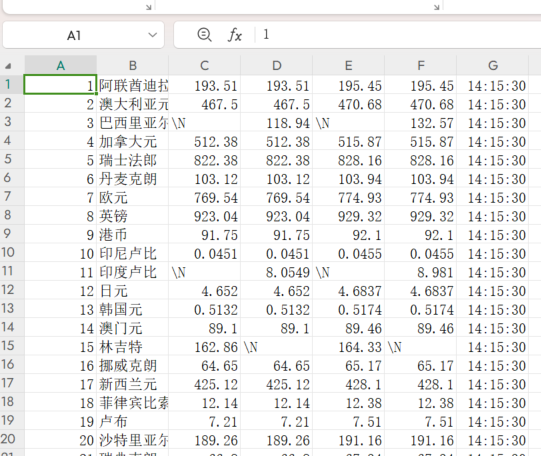
遇到的困难和解决方案
困难一:Scrapy 爬虫未提取任何数据
问题描述:可能是由于网页结构变化导致 XPath 或 CSS 选择器不再准确,或是页面内容通过 JavaScript 动态加载。
解决方案:更新和调整选择器以匹配当前网页的结构。对于动态加载的内容,考虑使用 Scrapy-Splash 或 Selenium 集成来处理 JavaScript。
困难二:数据库连接与权限配置
问题描述:在最初配置 MySQL 数据库时,尝试使用 GRANT ALL PRIVILEGES 语句时出现语法错误,导致无法正确设置用户权限,进而无法将数据插入数据库。
解决方案:仔细检查 MySQL 的权限语法,确保使用正确的 SQL 语句格式。最终使用以下语句成功创建用户并授予权限:
GRANT ALL PRIVILEGES ON fufubuff.* TO 'fufu'@'localhost' IDENTIFIED BY 'hhxxyy120'; FLUSH
困难三:数据格式转换
问题描述:部分汇率数据以字符串形式存在,需要将其转换为浮点数以便在数据库中进行数值分析。
解决方案:在 pipelines.py 中,对抓取到的数据进行类型转换,确保数值字段被正确解析为浮点数。如果数据中存在异常字符或格式,增加数据清洗步骤,过滤或修正不符合预期的数据格式。
心得体会
通过本次作业,我深入理解了 Scrapy 框架中 Item 和 Pipeline 的作用与实现方式。Item 用于定义抓取数据的结构,确保数据的一致性和规范性;Pipeline 则负责对抓取到的数据进行处理、清洗,并最终将其保存到指定的存储介质中,如 MySQL 数据库。本项目中,结合 XPath 精确提取所需数据,并通过 Pipeline 将数据高效地存储到数据库中,极大地提升了数据处理的自动化和可靠性。
在项目实施过程中,我综合运用了 Scrapy 框架、XPath 解析技术和 MySQL 数据库存储,形成了一条完整的数据抓取与存储技术路线。具体步骤如下:
数据抓取:使用 Scrapy 爬虫从中国银行网的外汇汇率页面抓取数据,通过 XPath 精确定位和提取表格中的汇率信息。
数据处理:在 Pipeline 中对抓取到的数据进行必要的清洗和格式转换,确保数据的准确性和一致性。
数据存储:将处理后的数据通过 PyMySQL 库插入到预先创建的 MySQL 数据库表中,实现数据的持久化存储。
本次作业不仅巩固了我对 Scrapy 框架的使用,还加深了我对 XPath 解析技术和 MySQL 数据库操作的理解。在实际项目中,难免会遇到各种问题和挑战,通过查阅资料、调试代码和不断优化,最终成功实现了从中国银行网抓取外汇汇率数据并存储到 MySQL 数据库中的目标。这不仅提升了我的技术能力,也增强了我的问题解决能力和项目实践经验。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号