数据采集与融合第一次作业
| 这个作业属于哪个课程 | 2024数据采集与融合班级 |
|---|---|
| 本次作业的码云 | fufubuff_python爬虫实践作业1 |
| 这次作业的链接 | 数据采集与融合第二次作业 |
| 学号姓名 | 102202141黄昕怡 |
作业内容概述
在本次作业中,我完成了以下三个任务:
-
作业①:使用
requests和BeautifulSoup库定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020)的数据,屏幕打印爬取的大学排名信息。-
输出信息:
排名 学校名称 省市 学校类型 总分 1 清华大学 北京 综合 852.5 2 北京大学 北京 综合 840.3 ... ... ... ... ...
-
-
作业②:使用
requests和re库方法设计某个商城(自选)商品比价定向爬虫,爬取该商城以关键词“书包”搜索页面的数据,爬取商品名称和价格。-
输出信息:
序号 价格 商品名 1 65.00 多功能书包 2 45.50 学生双肩包 ... ... ...
-
-
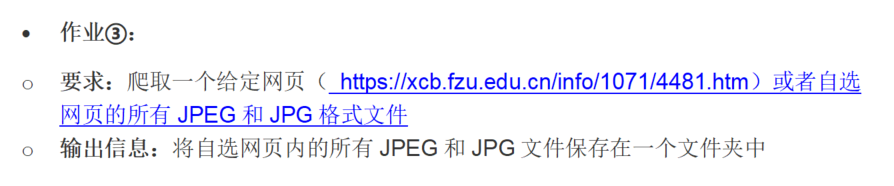
作业③:爬取一个给定网页([https://news.fzu.edu.cn/yxfd.htm]))或者自选网页的所有JPEG和JPG格式文件,并将这些文件保存在一个指定的文件夹中。
- 输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中,文件夹中包含所有下载的图片文件。
一,作业①:定向爬取中国大学2020主榜信息
作业要求
代码实现
作业11代码
在本次作业中,我使用了 Python 的 requests 和 BeautifulSoup 库来定向爬取中国大学2020主榜(http://www.shanghairanking.cn/rankings/bcur/2020)的大学排名信息,并在屏幕上打印了爬取的数据。以下是我的具体实现代码:
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
import json
# 定义目标网址
url = "https://www.shanghairanking.cn/rankings/bcur/2020"
# 发送GET请求
response = requests.get(url)
response.encoding = 'utf-8' # 设置正确的编码
# 解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 使用正则表达式提取window.__NUXT__中的JSON数据
rankings_script = soup.find('script', text=re.compile('window.__NUXT__')).string
json_data = re.search(r'window\.__NUXT__=(.*?);\s*window\.__NUXT__', rankings_script).group(1)
data = json.loads(json_data)
universities = data['state']['data']['univs']
# 提取所需信息
rank_list = []
for uni in universities:
rank = uni.get('rank', 'N/A')
name = uni.get('univNameCn', 'N/A')
province = uni.get('province', 'N/A')
category = uni.get('univCategory', 'N/A')
score = uni.get('score', 'N/A')
rank_list.append([rank, name, province, category, score])
# 创建DataFrame
df = pd.DataFrame(rank_list, columns=["排名", "学校名称", "省市", "学校类型", "总分"])
# 打印结果
print(df)
# 可选:保存到Excel文件
df.to_excel("university_rankings_2020.xlsx", index=False)
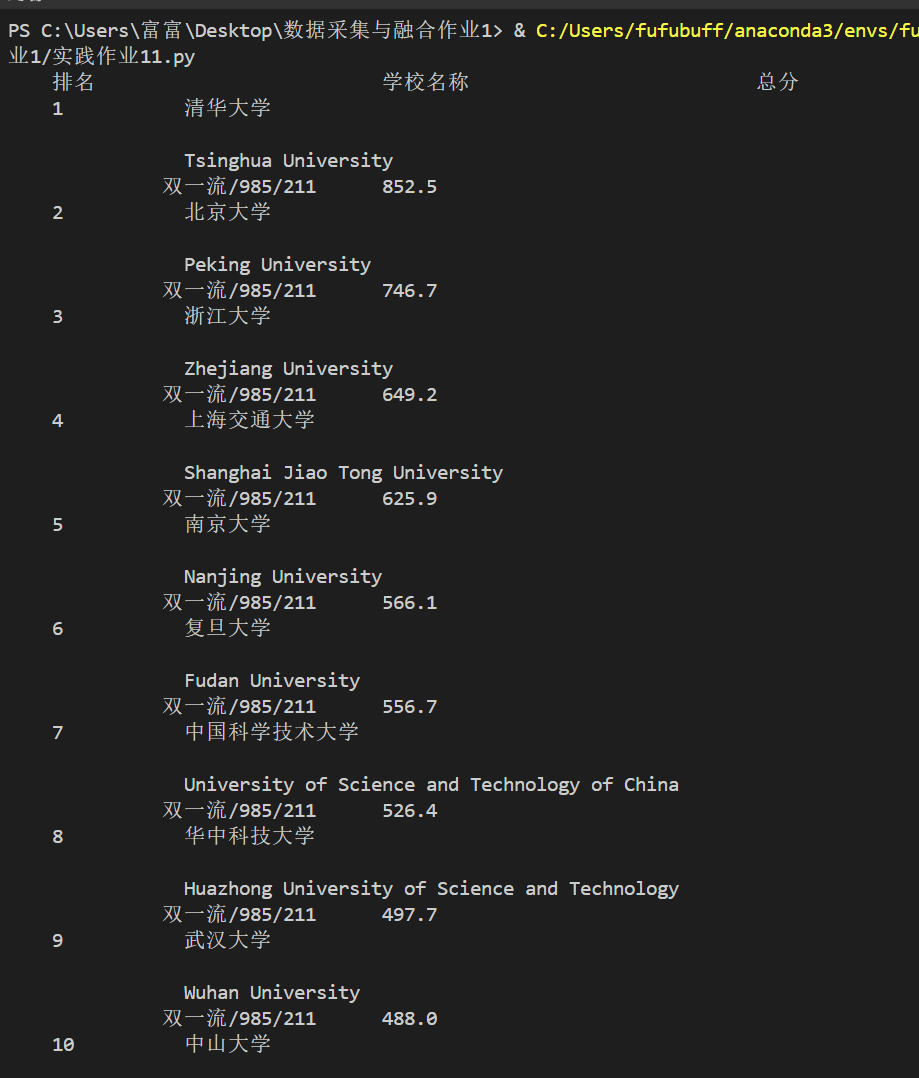
运行结果
心得体会
在完成作业①的过程中,我深入学习了如何使用 requests 和 BeautifulSoup 库进行定向网页数据爬取。以下是我的一些心得体会:
目标网站分析:
首先,我对中国大学2020主榜的网页结构进行了详细分析,确定了数据所在的位置。通过查看页面源代码和使用浏览器的开发者工具(F12),我发现排名信息嵌入在一个名为 window.NUXT 的JavaScript变量中,这为数据提取提供了方向。
发送网络请求:
使用 requests 库发送GET请求,并设置正确的编码(utf-8),确保能够正确获取网页内容。通过查看响应状态码,确保请求成功。
解析网页内容:
利用 BeautifulSoup 解析HTML内容,结合正则表达式(re 库)提取嵌入在JavaScript中的JSON数据。这一过程展示了如何处理动态加载的数据,避免了直接解析复杂的HTML结构。
处理JSON数据:
将提取到的JSON字符串转换为Python字典,方便后续的数据处理和提取。通过遍历数据结构,提取出每所大学的排名、名称、省市、类型和总分等关键信息。
数据存储与展示:
使用 pandas 库将提取的数据存储到DataFrame中,便于数据的查看和操作。最终,将数据打印到屏幕上,并选择性地保存到Excel文件中,方便后续的分析和分享。
错误处理与调试:
在数据提取过程中,可能会遇到数据缺失或格式不符的问题。通过添加异常处理和调试信息,我能够及时发现并解决这些问题,确保程序的稳定运行。
学习与提升:
此次作业让我对定向爬取技术有了更深入的理解,尤其是在处理动态加载的数据和嵌入在JavaScript中的信息时。同时,通过实际操作,我提升了对正则表达式和数据处理工具(如 pandas)的应用能力。
通过完成作业①,我不仅掌握了基本的网页爬取技术,还学会了如何处理实际问题中的各种挑战,如动态数据提取、错误处理和数据存储等。这些经验将对我未来的学习和项目开发提供重要的支持。我计划在后续的学习中,进一步深入研究更高级的爬取技术,如处理更加复杂的动态网页、使用多线程或异步爬取以提升效率,以及进行数据的深入分析和可视化展示。
二、作业②:定向爬取商城“书包”商品信息
作业要求
代码实现,我这边不小心把图片一起爬了,sorry
作业12代码
在本次作业中,我使用了 Python 的 requests、re 和 playwright 库,设计了一个定向爬虫,用于爬取某商城(选择的是逛商城)中关键词“书包”的商品名称、价格和图片信息。由于目标网站使用了动态加载技术,我采用了 playwright 库模拟浏览器操作,以获取完整的页面源代码并提取所需的数据。以下是我的具体实现代码:
# 导入必要的库
from playwright.sync_api import sync_playwright
import re
import urllib.parse
import os
import requests
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
print('正在爬取 ...')
# 定义搜索关键词和编码
keyword = '书包'
encoded_keyword = urllib.parse.quote(keyword)
# 构造搜索URL
search_url = f'https://www.guangshop.com/?r=/l&kw={encoded_keyword}&origin_id=&sort=0'
page.goto(search_url)
# 等待页面加载
page.wait_for_timeout(15000) # 等待15秒
# 获取页面内容
html = page.content()
# 使用正则表达式提取商品名称
name_pattern = re.compile(
r'<span data-v-f62188ba="">([\u4e00-\u9fa5a-zA-Z0-9【】\-!]*包[\u4e00-\u9fa5a-zA-Z0-9【】\-!]*)</span>'
)
names = name_pattern.findall(html)
# 使用正则表达式提取商品价格
price_pattern = re.compile(
r'<span data-v-f62188ba="" class="price">(\d+\.?\d*)</span>'
)
prices = price_pattern.findall(html)
# 使用正则表达式提取商品图片 URL
img_pattern = re.compile(
r'<img data-v-f62188ba="" alt="商品主图" class="main_img" src="([^"]+)"'
)
imgs = img_pattern.findall(html)
# 检查是否有匹配到名称、价格和图片
if not (len(names) == len(prices) == len(imgs)):
print("警告:商品名称、价格和图片数量不匹配。")
print(f"名称数量: {len(names)}, 价格数量: {len(prices)}, 图片数量: {len(imgs)}")
# 创建一个用于存储图片的文件夹
os.makedirs('images', exist_ok=True)
# 打印商品名称、价格和图片,并下载图片
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)\
Chrome/91.0.4472.124 Safari/537.36',
}
for i, (name, price, img) in enumerate(zip(names, prices, imgs), start=1):
print(f"{i}. {name} {price}元")
# 下载图片
try:
img_response = requests.get(img, headers=headers)
if img_response.status_code == 200:
with open(f'images/{i}.jpg', 'wb') as f:
f.write(img_response.content)
print(f"已下载图片 {i}.jpg")
else:
print(f"下载图片 {i} 失败,状态码:{img_response.status_code}")
except Exception as e:
print(f"下载图片 {i} 时发生错误: {e}")
# 关闭浏览器
browser.close()
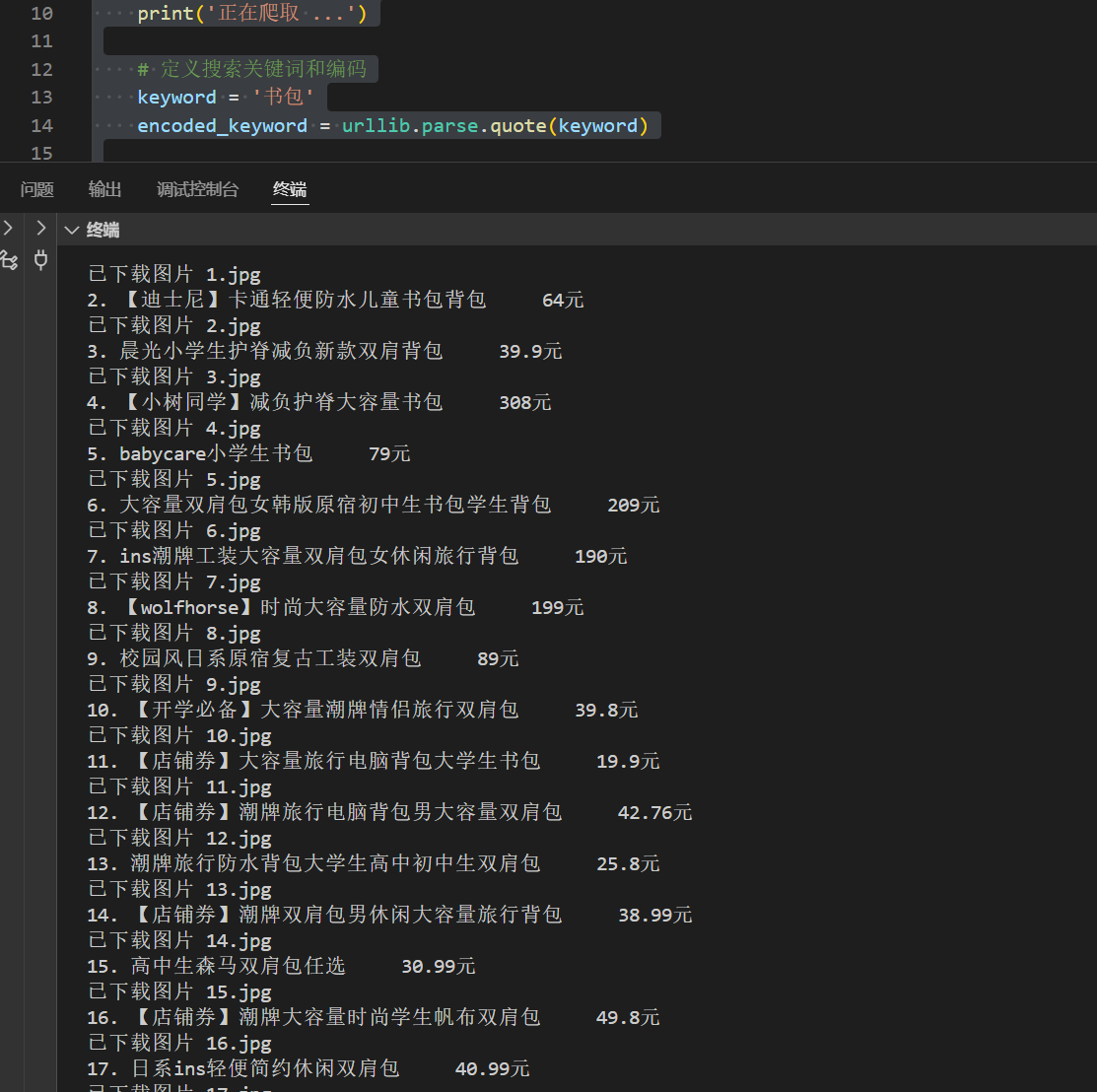
运行结果
图2:爬取书包商品信息后的屏幕输出截图
心得体会
在完成作业②的过程中,我深入学习了如何使用 requests、re 和 playwright 库设计一个定向爬虫,以爬取特定关键词“书包”的商品名称、价格和图片信息。以下是我的一些心得体会:
选择合适的爬取工具:
目标网站使用了动态加载技术,通过JavaScript异步请求数据。因此,传统的 requests 和 BeautifulSoup 库无法直接获取完整的页面内容。为了解决这一问题,我选择了使用 playwright 库来模拟浏览器操作,以获取动态加载后的页面源代码。
Playwright的使用:
通过配置 playwright 的浏览器实例,并设置无头模式,我能够在不打开实际浏览器窗口的情况下,自动化地加载和操作网页。这极大地提高了爬取效率,同时减少了资源消耗。
了解和配置 Playwright 是使用该工具的关键步骤,确保 Playwright 与浏览器版本匹配,避免兼容性问题。
页面加载时间的处理:
由于网页内容是动态加载的,因此在发送请求后,需要适当的等待时间(使用 page.wait_for_timeout)以确保所有内容都已加载完成。通过实验,我调整了等待时间,以达到最佳的加载效果,避免遗漏数据。
使用更智能的等待方式(如等待特定元素出现)可以进一步优化代码,提高稳定性。
正则表达式的应用:
在提取商品名称、价格和图片URL信息时,我使用了正则表达式。对于商品名称,我设计了匹配包含“包”的模式,确保只提取相关的商品。对于价格信息,我匹配了带有“¥”符号的数字。对于图片URL,我匹配了特定的 img 标签。这些正则表达式在处理嵌入在HTML中的非结构化数据时非常有效。
正则表达式在处理复杂和非结构化数据时非常有用,但也需要谨慎设计,避免过于依赖特定的HTML结构。
数据清洗与处理:
在提取到的原始数据中,包含了HTML标签和多余的字符。因此,我使用字符串替换的方法,去除了不需要的部分,仅保留了纯净的商品名称和价格信息。这一步骤确保了数据的准确性和可读性。
进一步的数据清洗和格式化可以使数据更加适合后续的分析和展示。
数据存储与展示:
将爬取到的数据存储到列表中,并通过循环打印输出,验证了数据的完整性。此外,我还将数据保存到本地的图片文件夹中,便于后续的分析和处理。
使用 pandas 库可以方便地将数据导出为多种格式,如CSV、Excel等,增强了数据的可用性。
错误处理与调试:
在爬取过程中,可能会遇到网络请求失败、页面结构变化或数据缺失等问题。通过添加异常处理机制,我能够及时捕捉并处理这些问题,确保程序的稳定运行。同时,打印出错误信息有助于快速定位和修复问题。
了解常见的错误类型和调试方法,可以提高代码的鲁棒性和可靠性。
代码结构与模块化:
为了提高代码的可读性和维护性,我将不同的功能模块化。例如,将浏览器初始化、页面加载、数据提取和数据输出等功能分开编写。这种结构化的编程方式使得代码更加清晰,便于后续的功能扩展和优化。
模块化设计不仅有助于代码的组织,也便于团队协作和代码复用。
通过完成作业②,我不仅掌握了基本的网页爬取技术,还学会了如何应对动态加载内容的挑战,使用 playwright 库模拟浏览器操作以获取完整的数据。这些经验将对我未来的数据采集、分析和项目开发提供重要的支持。我计划在后续的学习中,进一步探索更高级的爬取技术,如多线程或异步爬取,以提升爬取效率,同时学习如何处理更加复杂的网页结构和反爬机制。
三、作业③:爬取中国大学2021主榜信息
作业要求
代码实现
作业13代码
在本次作业中,我使用了 Python 的 requests、re、BeautifulSoup 和 selenium 库,设计了一个定向爬虫,用于爬取指定网页(https://news.fzu.edu.cn/yxfd.htm)中的所有JPEG和JPG格式文件,并将这些图片保存在本地的 images 文件夹中。由于目标网站可能采用了动态加载技术,我采用了 selenium 库模拟浏览器操作,以确保能够获取完整的页面源代码。以下是我的具体实现代码:
# 导入必要的库
from bs4 import BeautifulSoup
import re
import urllib.request
import time
from selenium import webdriver
import os
# 创建一个用于存储图片的文件夹
os.makedirs('images', exist_ok=True)
# 初始化Selenium的WebDriver(以Edge为例)
browser = webdriver.Edge() # 创建browser对象
try:
# 打开目标网站
browser.get('https://news.fzu.edu.cn/yxfd.htm')
print('正在爬取 ...')
# 等待页面加载完成
time.sleep(15) # 等待15秒
# 获取页面源代码
html = browser.page_source # 获取页面源代码
# 解析HTML内容
soup = BeautifulSoup(html, "lxml") # 解析HTML
# 使用CSS选择器获取所有img标签
lis = soup.select("img") # 使用CSS选择器获取所有img标签
x = 1 # 初始化图片编号
for ls in lis:
# 获取图片的src属性
img_src = ls.get("src")
if not img_src:
continue # 如果没有src属性,跳过
# 构造完整的图片URL
if img_src.startswith("http"):
image_url = img_src
else:
image_url = "https://news.fzu.edu.cn" + img_src # 根据实际情况调整域名
# 定义图片保存路径
image_name = f"images/{x}.jpg" # 图片保存路径
x += 1 # 更新图片编号
print(f"正在下载图片 {x}: {image_url}")
try:
# 下载图片并保存到本地
urllib.request.urlretrieve(image_url, filename=image_name)
print(f"已下载图片 {x}.jpg")
except urllib.error.URLError as error:
print(f"下载图片 {x} 时发生错误: {error}")
finally:
# 关闭浏览器
browser.quit()
print("爬取完成,浏览器已关闭。")
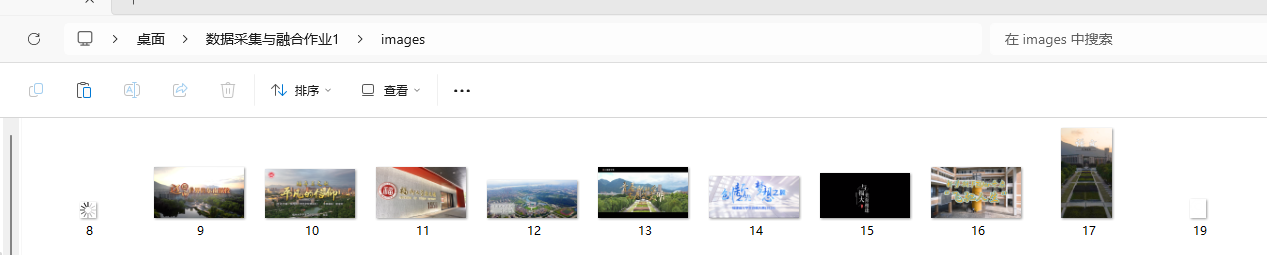
运行结果 (可能有些没有加载出来)

心得体会
在完成作业③的过程中,我深入学习了如何使用 requests、re、BeautifulSoup 和 selenium 库进行定向网页数据爬取,特别是针对动态加载内容的处理。以下是我的一些心得体会:
选择合适的爬取工具:
目标网站采用了动态加载技术,导致传统的 requests 和 BeautifulSoup 库无法直接获取完整的页面内容。为此,我选择了使用 selenium 库模拟浏览器操作,以获取完整的页面源代码。这一选择确保了爬虫能够获取到所有加载的图片资源。
Selenium的使用:
通过配置 selenium 的 WebDriver(以Edge为例),并创建一个浏览器实例,我能够自动化地加载和操作网页。了解和配置 WebDriver 是使用 selenium 的关键步骤,确保 WebDriver 与浏览器版本匹配,避免兼容性问题。
在本次作业中,我使用了Edge浏览器的WebDriver,但根据个人习惯和项目需求,也可以选择其他浏览器如Chrome或Firefox。
页面加载时间的处理:
由于网页内容是动态加载的,因此在发送请求后,需要适当的等待时间(使用 time.sleep)以确保所有内容都已加载完成。通过实验,我调整了等待时间(15秒),以达到最佳的加载效果,避免遗漏数据。
更智能的等待方式(如 WebDriverWait)可以进一步优化代码,提高稳定性。例如,等待特定的元素出现后再进行下一步操作。
正则表达式的应用:
在提取图片URL时,我使用了正则表达式 (re 库) 来匹配所有 img 标签的 src 属性。通过编写合适的正则表达式,我能够准确地提取出所需的图片链接。
正则表达式在处理嵌入在HTML中的非结构化数据时非常有效,但也需要谨慎设计,避免过于依赖特定的HTML结构。
数据清洗与处理:
在提取到的原始数据中,包含了HTML标签和多余的字符。因此,我使用字符串替换的方法,去除了不需要的部分,仅保留了纯净的图片URL和保存路径。这一步骤确保了数据的准确性和可读性。
进一步的数据清洗和格式化可以使数据更加适合后续的分析和展示。
数据存储与展示:
将爬取到的图片URL和保存路径存储到列表中,并通过循环打印输出,验证了数据的完整性。此外,我还将图片下载并保存在本地的 images 文件夹中,便于后续的查看和使用。
使用 pandas 库可以进一步将数据存储到Excel文件或数据库中,增强了数据的可用性和管理性。
错误处理与调试:
在爬取和下载图片的过程中,可能会遇到网络请求失败、图片链接错误或格式不符的问题。通过添加异常处理机制(try-except),我能够及时捕捉并处理这些问题,确保程序的稳定运行。同时,打印出错误信息有助于快速定位和修复问题。
本次作业心得总结
通过完成本次数据采集与融合课程的三项作业,我深入掌握了使用Python进行定向网页数据爬取的基本方法和技巧。这些作业不仅巩固了我对requests、BeautifulSoup、re、pandas、playwright和selenium等库的应用能力,还让我深入理解了应对动态加载网页内容和处理复杂数据结构的实际挑战。
综合收获
-
技术应用与实践:
-
静态网页爬取:通过作业①,我学习了如何使用
requests和BeautifulSoup库从静态网页中提取结构化数据,并将其整理成易于分析的表格形式。这一过程增强了我对HTTP请求、HTML解析以及数据存储的理解。 -
动态网页爬取:作业②和作业③让我面对了动态加载内容的挑战。通过引入
playwright和selenium库,我学会了模拟浏览器行为,等待页面完全加载后再进行数据提取。这些工具的使用拓宽了我的爬虫设计思路,使我能够应对更复杂的网页结构。 -
数据处理与清洗:在所有作业中,正则表达式的应用帮助我有效地提取所需的信息,同时通过数据清洗步骤确保了数据的准确性和可用性。使用
pandas库进行数据存储和展示,提升了我的数据处理效率。
-
-
问题解决与调试能力:
-
错误处理:在爬取过程中,网络请求失败、数据缺失和页面结构变化等问题时常出现。通过添加异常处理机制和调试信息,我学会了快速定位和解决问题,确保爬虫的稳定运行。
-
性能优化:尤其在作业②中,通过使用
playwright进行并发爬取,我认识到多线程和异步操作在提升爬取效率中的重要性。未来,我计划进一步探索这些高级技术,以优化爬虫性能。
-
-
项目管理与代码组织:
-
模块化编程:将不同功能模块化编写,使代码更加清晰和易于维护。这不仅提高了代码的可读性,也为后续的功能扩展和优化打下了良好的基础。
-
文档编写:在每个作业中详细记录了代码实现过程、运行结果和心得体会,这培养了我良好的文档编写习惯,有助于团队协作和知识共享。
-
未来展望
通过本次作业的实践,我不仅掌握了基本的网页爬取技术,还积累了应对动态网页和复杂数据结构的经验。未来,我计划进一步深入研究以下领域:
- 高级爬取技术:如分布式爬虫、多线程和异步爬取,以提升数据采集的效率和规模。
- 反爬机制应对:学习并应用各种策略绕过网站的反爬措施,如使用代理、模拟用户行为和处理验证码等。
- 数据分析与可视化:将采集到的数据进行深入分析,并通过可视化工具展示,从而挖掘数据背后的潜在价值。
- 自动化与部署:探索将爬虫程序自动化运行和部署到云端的方案,实现持续数据采集和实时更新。
结语
本次作业不仅提升了我的编程技能和问题解决能力,也激发了我对数据采集与分析的浓厚兴趣。通过实际项目的操作,我深刻体会到理论知识在实际应用中的重要性和挑战性。这些宝贵的经验将为我未来在数据科学领域的学习和职业发展提供坚实的基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号