[吴恩达团队自然语言处理第3课_2]LSTM NER SiameseNetwork
[吴恩达团队自然语言处理第3课_2]LSTM NER SiameseNetwork
LSTM
Outline
- RNNs and vanishing/exploding gradients
- Solutions
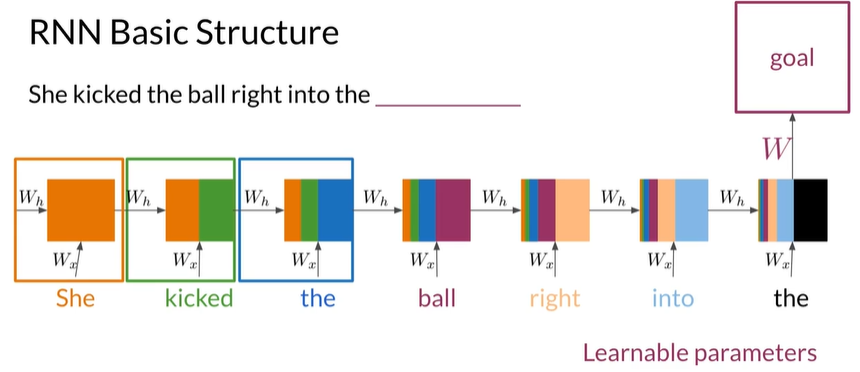
RNNs
-
Advantages
- Captures dependencies within a short range
- Takes up less RAM than other n-gram models
-
Disadvantages
-
Struggles with longer sequences
-
Prone to vanishing or exploding gradients
-
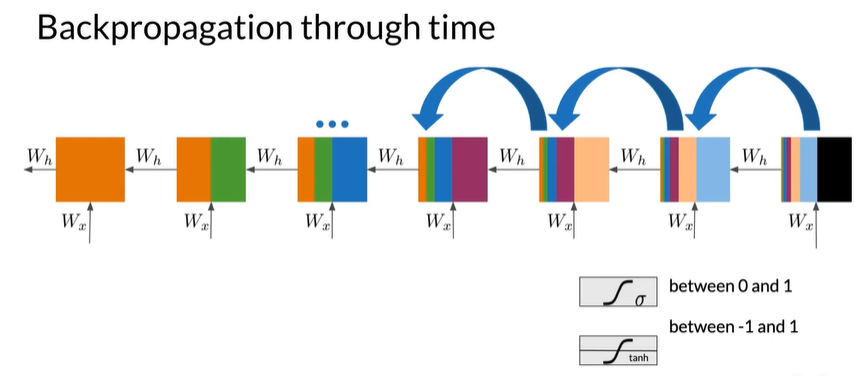
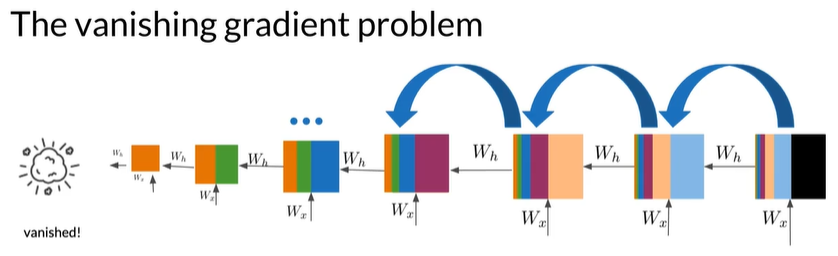
Solving for vanishing or exploding gradients
-
Identity RNN with ReLU activation ,-1->0 将负值替换为0,使其更接近单位矩阵
\[\begin{bmatrix} 1 & 0 & 0 & 0\\ 0 & 1 & 0 & 0\\ 0 & 0 & 1 & 0\\ 0 & 0 & 0 & 1\\ \end{bmatrix} \] -
Gradient clipping 32->25 将>25的值剪裁到25,限制梯度的大小
-
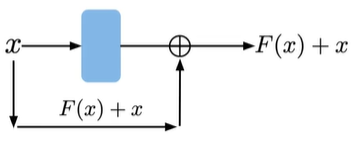
Skip connections
Introduction
Outline
- Meet the Long short-term memory unit!
- LSTM architecture
- Applications
LSTMs:a memorable solution
-
Learns when to remember and when to forget
-
Basic anatomy:
- A cell state
- A hidden state with three gates
- Loops back again at the end of each time step
-
Gates allow gradients to flow unchanged
LSTMs: Based on previous understanding
Cell state=before conversation
接到朋友电话之前,想的是无关朋友的内容
Forget gate=beginning of conversation
接电话时,把无关的想法放在一边,保留我想要的任何内容Input gate=thinking of a response
在通话进行时,获得来自朋友的新信息,同时想接下来可能会谈什么
Output gate=responding
当你决定下一步要说什么
Updated cell state=after conversation
重复直到挂电话,记忆更新了几次
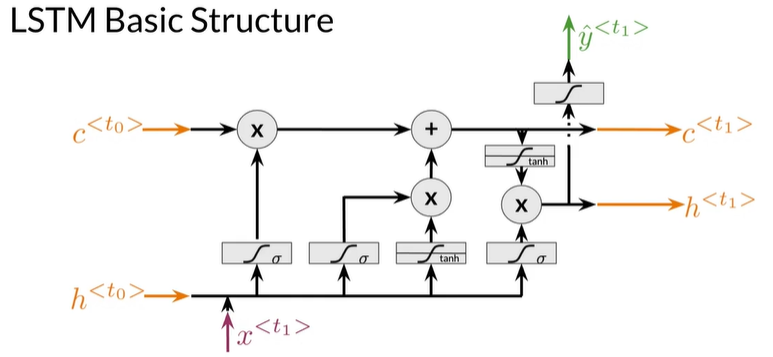
LSTM Basic Structure
applications of LSTMs
Summary
- LSTMs offer a solution to vanishing gradients
- Typical LSTMs have a cell and three gates:
- Forget gate
- Input gate
- Output gate
LSTM architecture
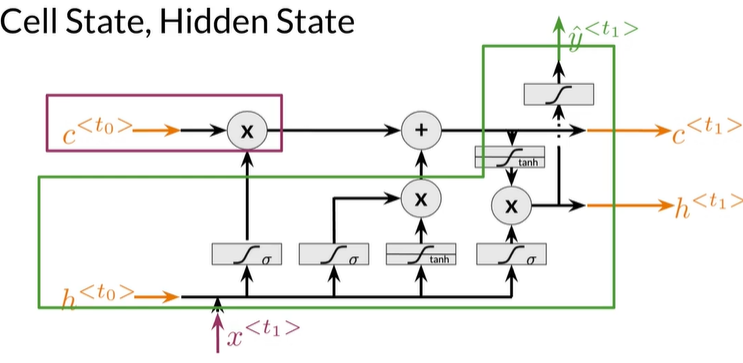
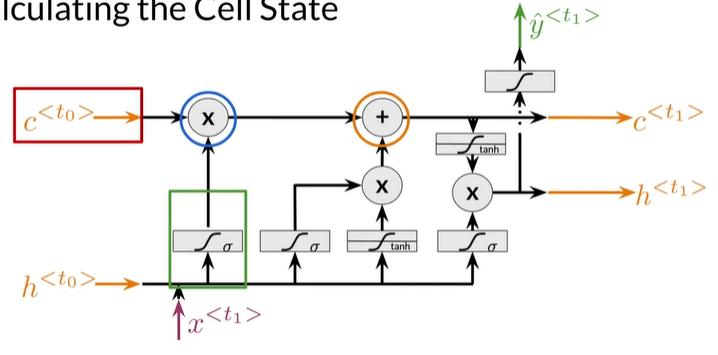
Cell State, Hidden State
- Cell State 充当memory
- Hidden State 是做出预测的原因
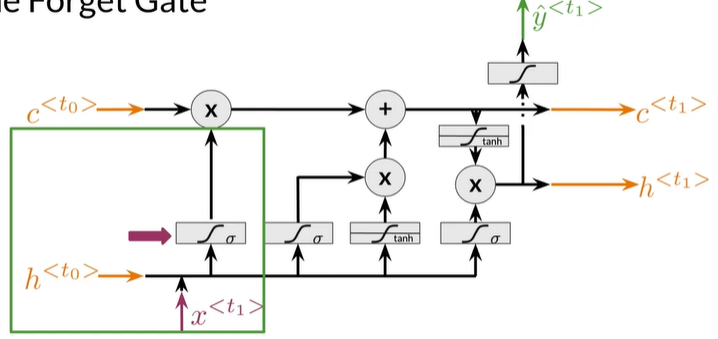
The Forget Gate
指出什么要保留,什么要丢弃,通过sigmod函数,值被压缩到 0-1 之间,越靠近0越应该被丢掉,接近1 被保留
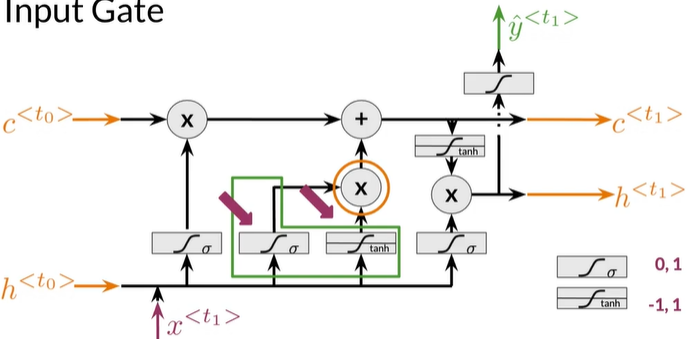
The Input Gate
更新状态,有两层,sigmod层和tanh层
sigmod:采用先前隐藏状态、当前输入,选择要更新的值,值压缩到 0-1,越接近1重要性越高
tanh:也是采用先前隐藏状态、当前输入,值压缩到 -1 到 1,有助于调节网络中的信息流
最后两个相乘得输出
Calculating the Cell State
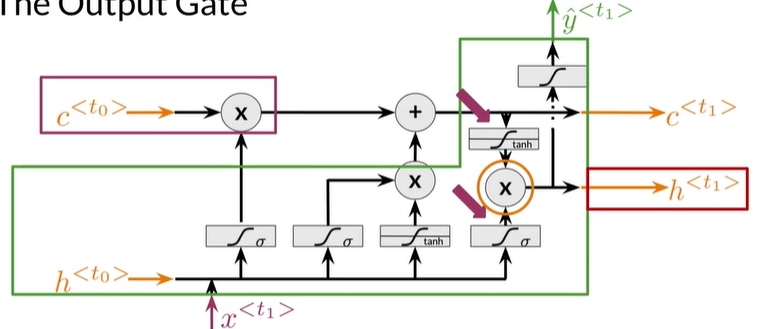
The Output Gate
决定下一个隐藏状态是什么
采用先前的隐藏状态、当前输入,通过sigmod层
最近更新的 cell state 通过 tanh层
接下来两个相乘得 h
Summary
-
LSTMs use a series of gates to decide which information to keep:
-
Forget gate decides what to keep
-
Input gate decides what to add
-
Output gate decides what the next hidden state will be
-
-
One time step is completed after updating the states
Named Entity Recognition (NER)
Introduction
What is Named Entity Recognition
- Locates and extracts predefined entities from text
- Places,organizations,names,time and dates
Types of Entities


Example of a labeled sentence
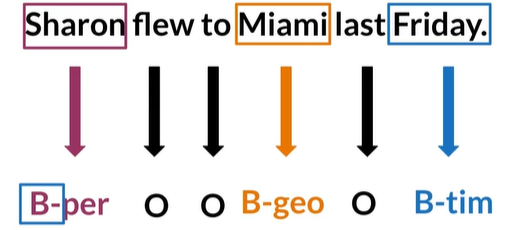
Application of NER systems
- Search engine efficiency
- Recommendation engines
- Customer service
- Automatic trading
Training NERs process
Data Processing
Outline
- Convert words and entity classes into arrays
- Token padding
- Create a data generator
Processing data for NERs
-
Assign each class a number 为每个实体类分配唯一数字
-
Assign each word a number 为每个单词分别其实体类的数字

Token padding
For LSTMs, all sequences need to be the same size.
- Set sequence length to a certain number
- Use the <PAD>token to fill empty spaces
Training the NER
- Create a tensor for each input and its corresponding number
- Put them in a batch ---->64,128,256,512..
- Feed it into an LSTM unit
- Run the output through a dense layer
- Predict using a log softmax over K classes
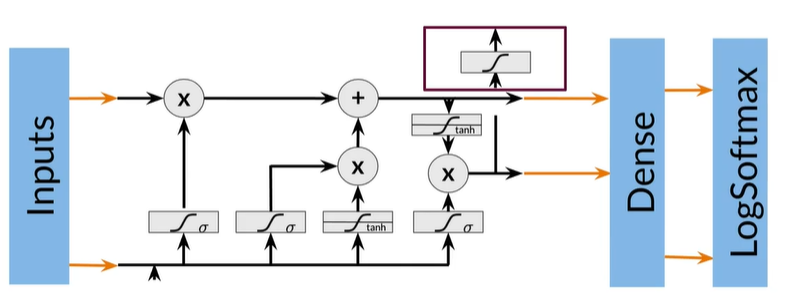
Layers in Trax
model = t1.Serial(
t1.Embedding(),
t1.LSTM(),
t1.Dense()
t1.LogSoftmax()
)
Summary
- Convert words and entities into same-length numerical arrays
- Train in batches for faster processing
- Run the output through a final layer and activation
Computing Accuracy
Evaluating the model
- Pass test set through the model
- Get arg max across the prediction array
- Mask padded tokens
- .Compare outputs against test labels

Summary
- If padding tokens,remember to mask them when computing accuracy
- Coding assignment!
Siamese Networks
Introduction
两个相同的神经网络组成的神经网络,最后合并
Question Duplicates
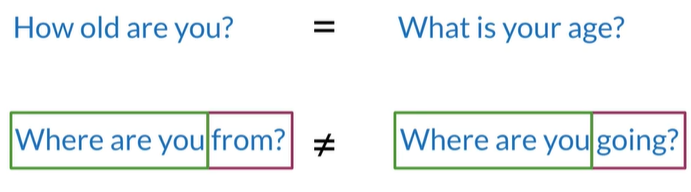 比比较单词序列的含义
比比较单词序列的含义
What do Siamese Networks learn?

Siamese Networks in NLP

Architecture
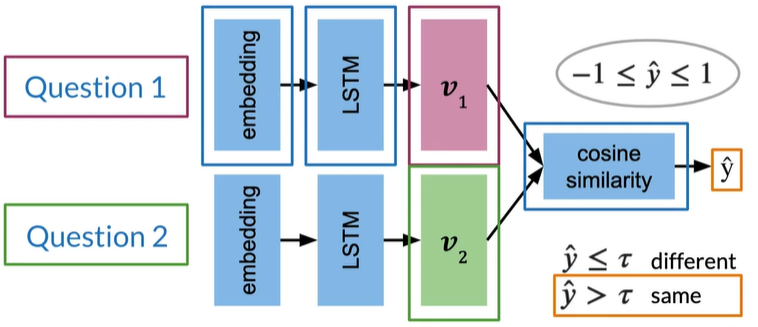
Cost function
Loss function
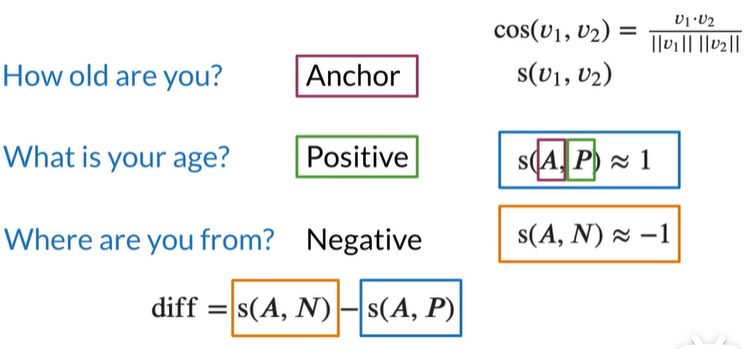
将问题How old are you 作为anchor锚点,用于比较其他的问题
与锚点有相似的意义则为positive question,没有则negative question
相似的问题,相似度会接近1,反之接近 -1
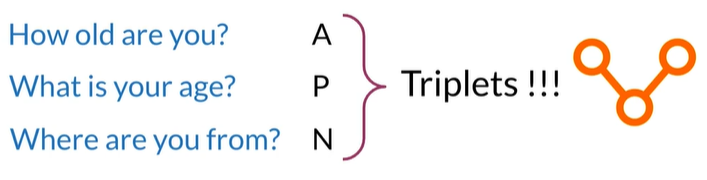
Triplets
Triplets
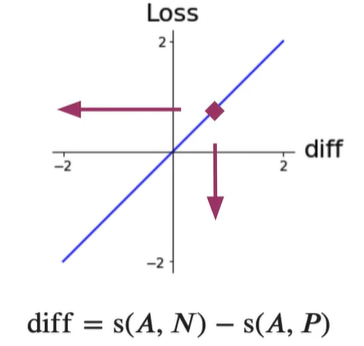
如果给模型正损失值,模型将一次来更新权重得到改进;
如果给模型一个负损失值,就像告诉模型做的好,加大权重,所以不要给负值,如果损失值<0就得0
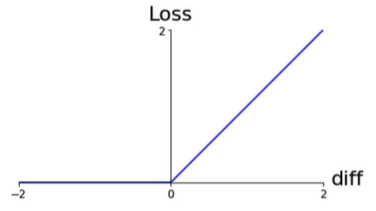
Simple loss:
Non linearity:
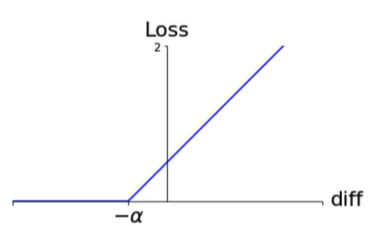
Triplet Loss
将函数左移,如选取alpha=0.2,
如果相似度之间的差距很小,如-0.1,在加入了alpha之后结果>0,让模型可以从中学习
Alpha margin:
Triplet Selection
当模型正确预测(A,P)比(A,N)更相似时,Loss=0
此时已不能从 Triplets 学到更多,可以选择更有效的训练,选择让模型出错的triplets而不是随机的,叫hard triplets,是(A,N)十分接近但是仍然小于(A,P)的相似性

Compute the cost
Introduction
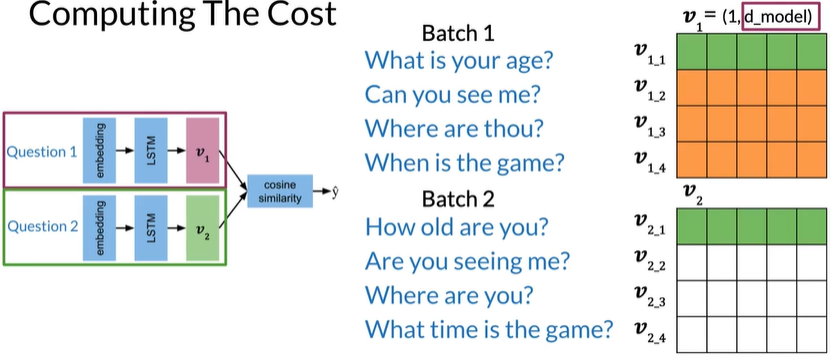
d_model是embedding的维度,同时等于列数为5,batch_size是行数为4
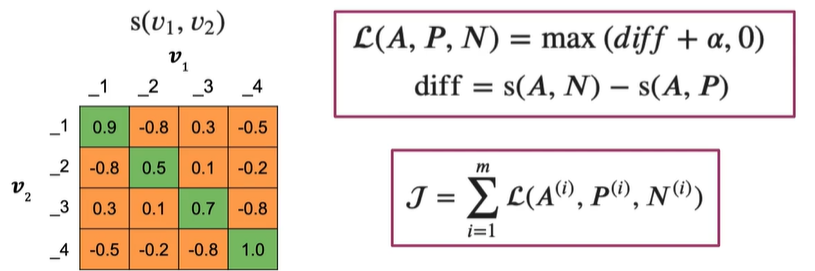
绿色对角线是重复问题的相似度,会大于非对角线的值
橙色是不重复问题的相似度
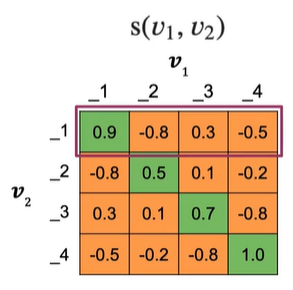
mean negative:
mean of off-diagonal values in each row 每行的非对角线元素,如第一行不包括 0.9
closest negative:
off-diagonal value closest to (but less
than)the value on diagonal in each row
非对角线元素中最接近对角线元素值的元素,如第一行为 0.3
即改相似度为0.3的negative示例对学习贡献最大
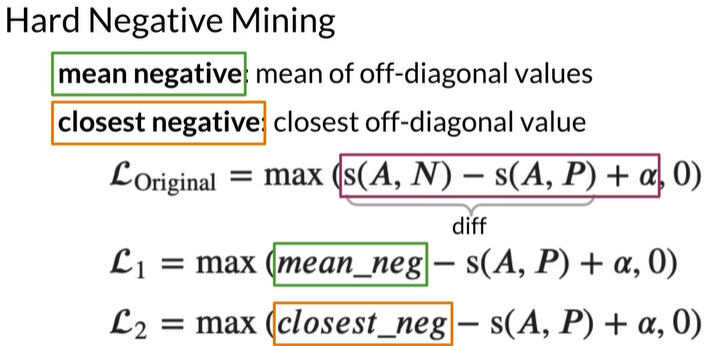
mean neg通过仅对平均值的训练,减少噪声
(噪声是接近0的,即几个噪声值的平均值通常为0)
Closest_neg:与negative example的余弦相似度之间的最小差异,
如果与alpha的差异很小,就可以获得更大的Loss,通过将训练重点放在产生更高损失值的示例上,让模型更快更新权重
接下来将两个Loss相加
Hard Negative Mining
One Shot learning
Classification vs One Shot Learning
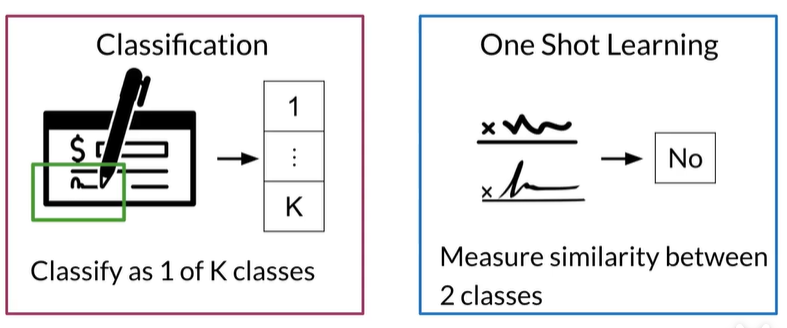
如辨别这首诗是不是Lucas写的,如果分类,将这类诗集加入到类别中,就会变成 K+1类,需要重新训练
而One shot learning不是分类,在Lucas的诗集上训练,然后计算两个类别的相似性
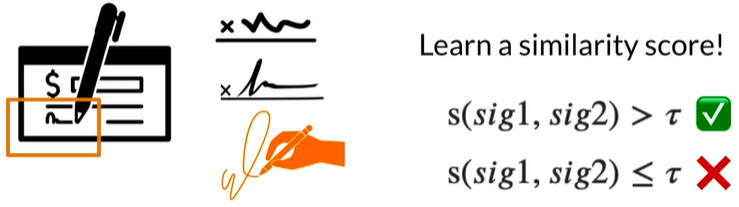
Need for retraining 如在银行出现新签名不需要重新训练
设置阈值来判断是否同一类
Training Testing
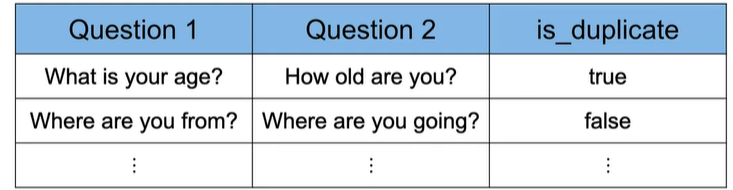
Dataset
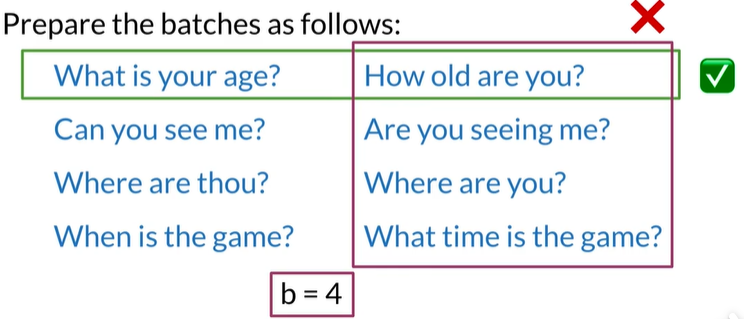
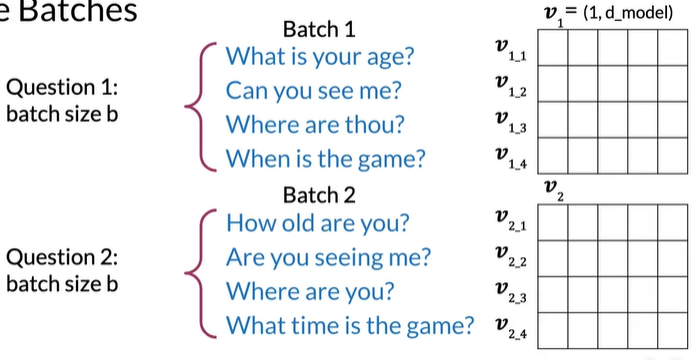
Prepare Batches
同一个batch的内容是不会重复的,但和另一个batch对应位置的元素重复
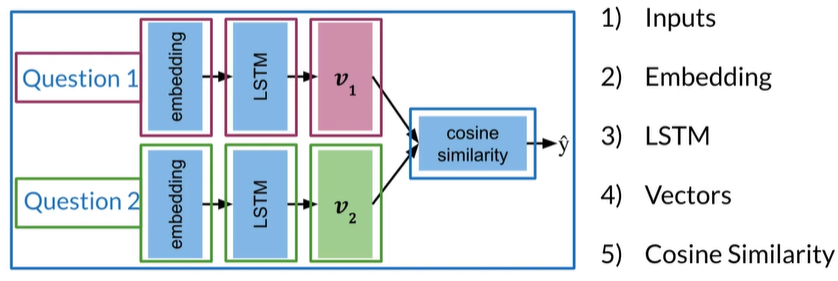
Siamese Model
两个子网的参数相同所以只训练一组权重
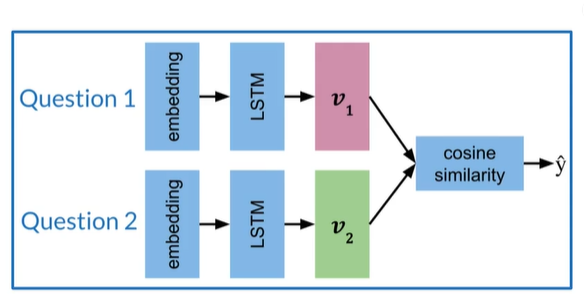
Create a subnetwork:
- Embedding
- LSTM
- Vectors
- Cosine Similarity
Testing


 浙公网安备 33010602011771号
浙公网安备 33010602011771号