[吴恩达团队自然语言处理第二课_3]词嵌入与神经网络
[吴恩达团队自然语言处理第二课_3]词嵌入与神经网络
Overview
主要应用
- Semantic analogies and similarity
- Sentiment analysis
- Classification of
customer feedback
高级应用
- Machine translation
- Information extraction
- Question answering
Learning objectives
- Identify the key concepts of word representations
- Generate word embeddings
- Prepare text for machine learning
- Implement the continuous bag-of-words model
Basic word representation
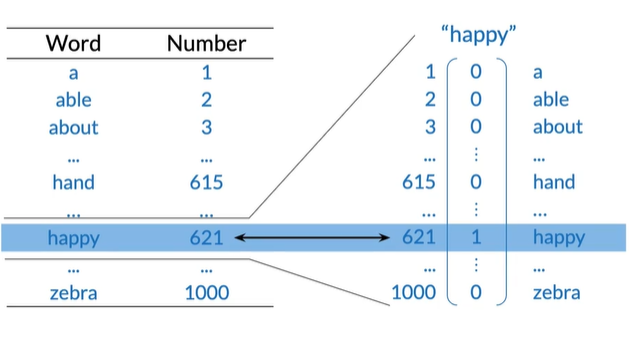
Integers
给词汇表每个单词分配一个唯一整数

-
简单
-
Nunber按字母顺序排列,没有什么语义,如
happy的值比hand大没有原因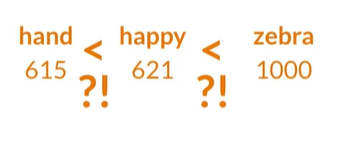
One-hot vectors
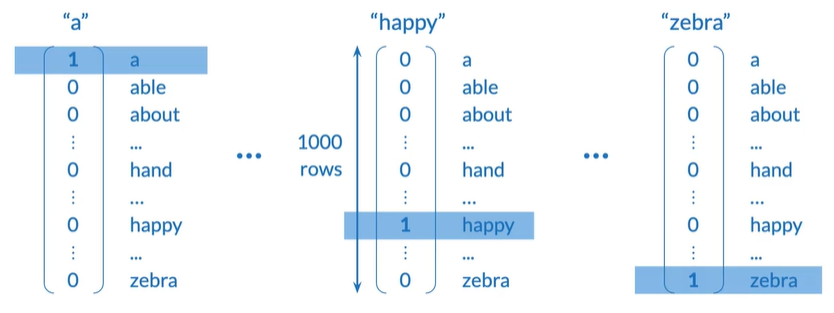
-
简单
-
No implied ordering不暗示两个词有任何关系
-
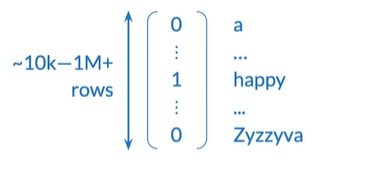
Huge vectors可能超过一百万行
-
No embedded meaning 不包含单词意思,如无法计算相似度,
happy应该更接近excited
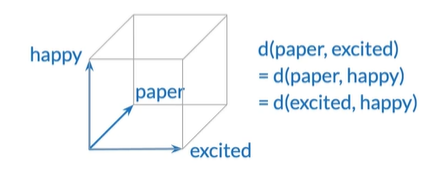
Word embeddings
Meaning as vectors
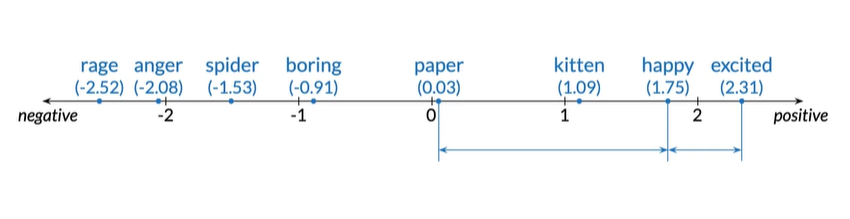
可以发现happpy与excited更接近而不是paper
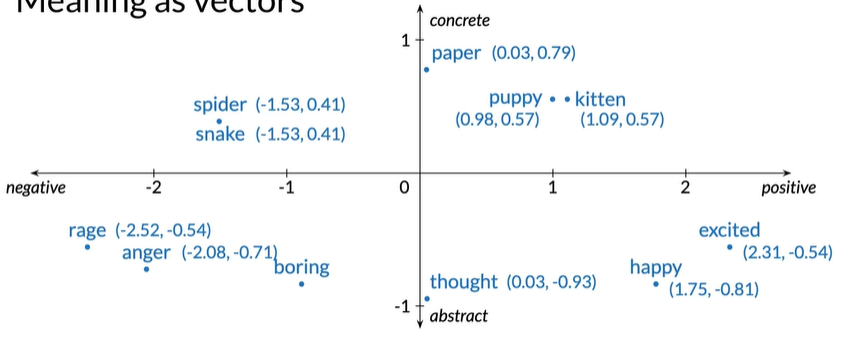
获得了一些语义但是也放弃了一些精确度,精确度不如one-hot,因为在此2D图中,两个单词可能位于同一点,如spider和snake
word embeddings
-
维数低
-
Embed meaning 有语义
-
e.g. semantic distance
forest≈treeforest≠ticket -
e.g. analogies类比
Paris:France::Rome:?
-
Terminology

Summary
- Words as integers
- Words as vectors.
- One-hot vectors
- Word embedding vectors
- Benefits of word embeddings for NLP
How to create word embedding
Methods
Basic word embedding methods
- word2vec(Google,2013)
- Continuous bag-of-words(CBOW) 根据给定的单词预测丢失的单词
- Continuous skip-gram/Skip-gram with negative sampling(SGNS) 根据给定的词预测词
- Global Vectors(GloVe)(Stanford,2014)
- fast Text(Facebook,2016)
- Supports out-of-vocabulary (OOV) words
Advanced word embedding methods
Deep learning, contextual embeddings 单词根据context有不同的embedding,增加了多义词或相似词
- BERT(Google,2018)
- ELMo (Allen Institute for Al,2018)
- GPT-2(OpenAl,2018)
以上都 Tunable pre-trained models available
Continuous bag-of-words(CBOW) model
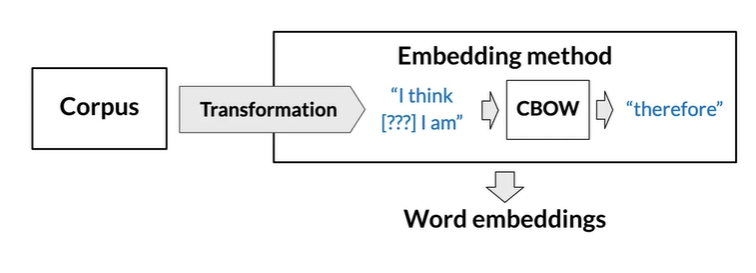
基于周围单词得缺失单词
如果两个词周围的单词很像,那么他们可能语义相关
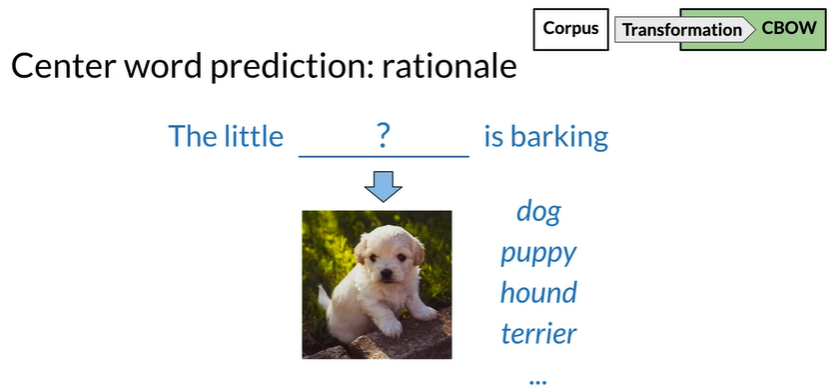
Create a training example
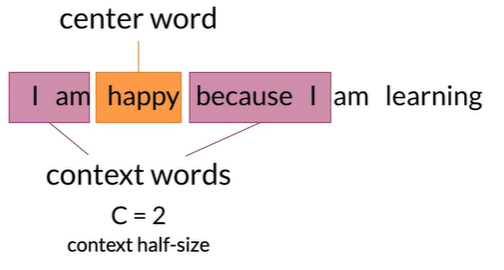
C是模型超参,可改,将中心词加上上下文词称为window,此处window=1+2+2=5
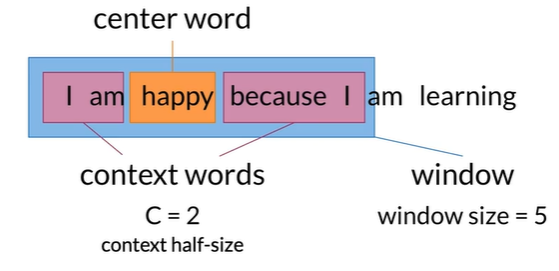
From corpus to training
e.g. 刚开始window内容为I am happy because I,然后window像右边滑动得am happy I am.
如此重复获得训练示例
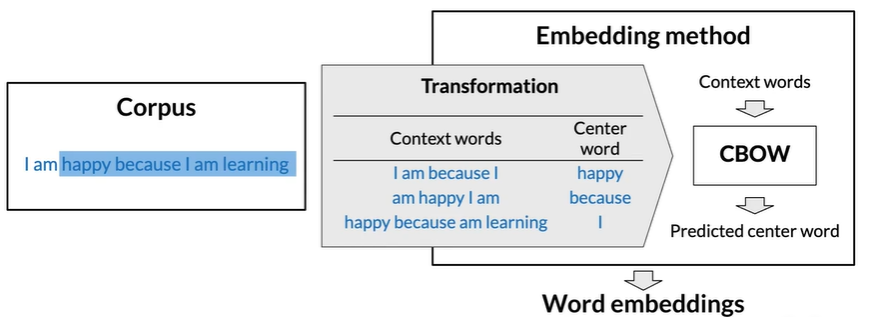
CBOW in a nutshell
Cleaning and tokenization

Example in Python: corpus

# pip install nltk
# pip instalL emoji
import nltk
from nltk.tokenize import word_tokenize
import emoji
import re
nltk.download('punkt') # download pre-trained Punkt tokenizer for English
corpus = 'Who ♥"word embeddings" in 2020? I do!!!'
data = re.sub(r'[,!2;-]+','.', corpus)
data = nltk.word_tokenize(data)# tokenize string to words
data = [ ch.lower() for ch in data
if ch. isalpha()
or ch == '.'
or emoji.get_emoji_regexp().search(ch)
]
print(data)
#['who', '♥', 'word', 'embeddings', 'in', 'i', 'do', '.']
#Sliding window of words
def get_windows(words,C):
i=C
while i<len(words)-C:
center_word=words[i]
context_words=words[(i-C):i]+words[(i+1):(i+C+1)]
yield context_words,center_word
i += 1


for x,y in get_windows(
['i','am','happy','because','i','am','learning'],
2
):
print(f'{x}\t{y}')
#['i', 'am', 'because', 'i'] happy
#['am', 'happy', 'i', 'am'] because
#['happy', 'because', 'am', 'learning'] i
Transforming words into vectors

Average of individual one-hot vectors
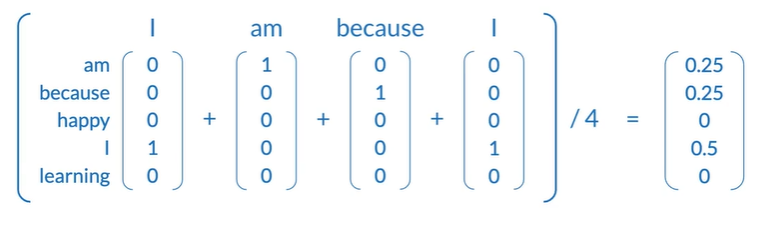
Final prpared training set
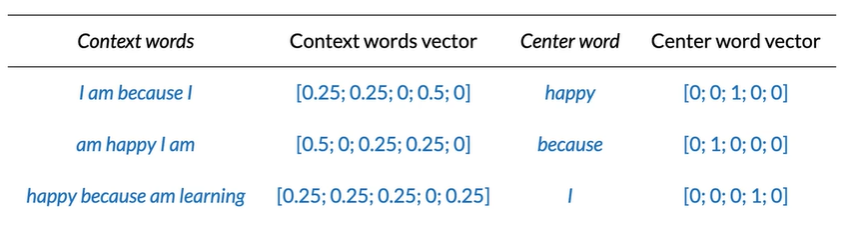
vector都是行向量,这样写是为了好看
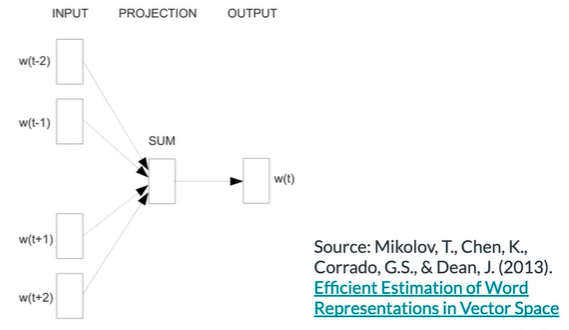
Architecture of the CBOW model
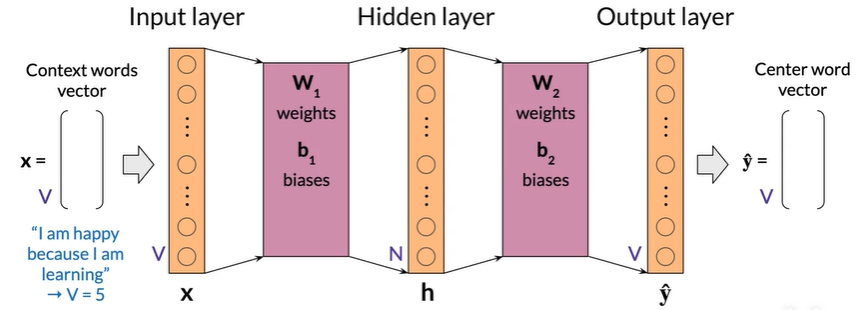
Demension(single input)
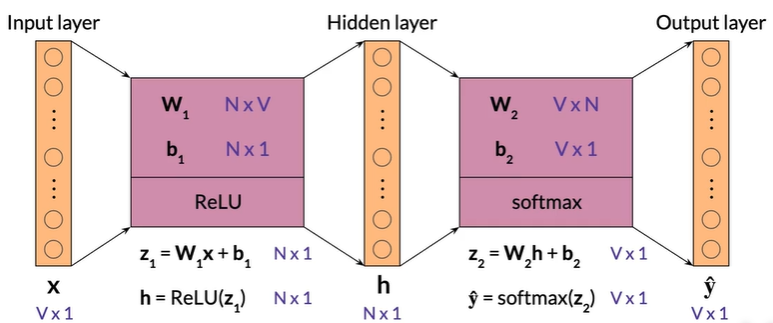
行列向量 转置
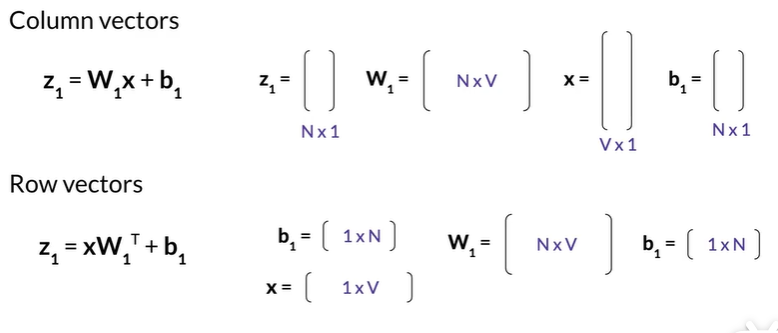
Dimensions (batch input)
m : batch size 超参
组合成一个 V 行m 列的矩阵 称为 X
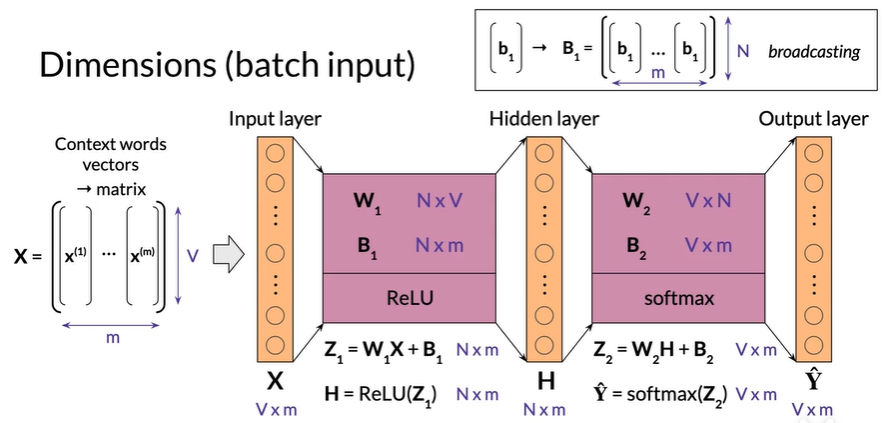
将y_hat分解为m个列向量
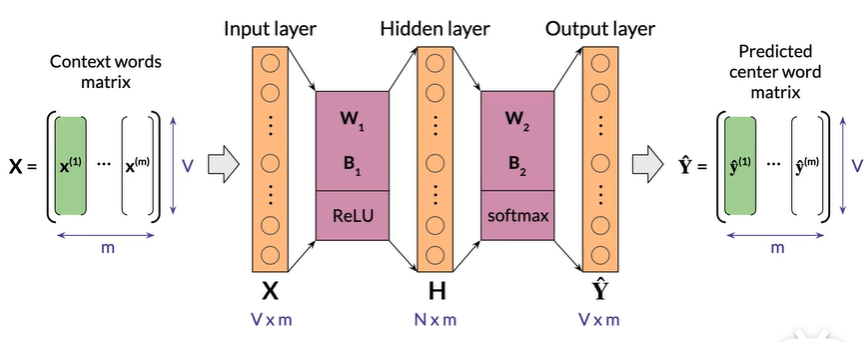
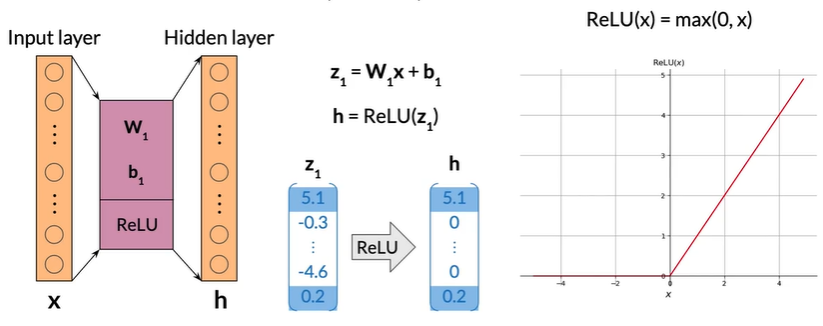
Rectified Linear Unit(ReLU)
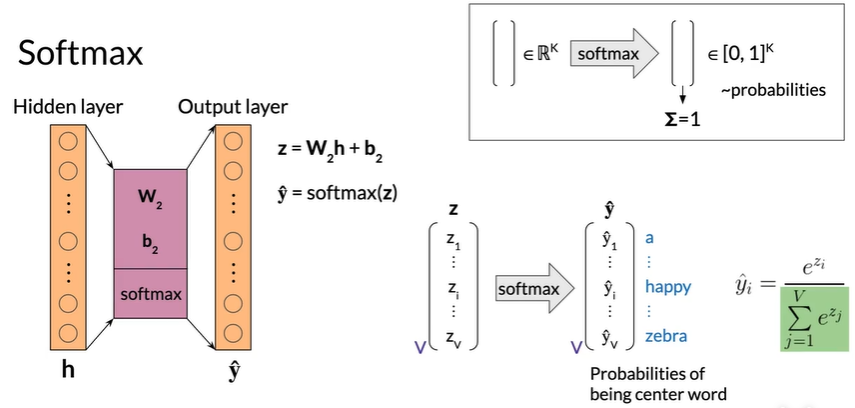
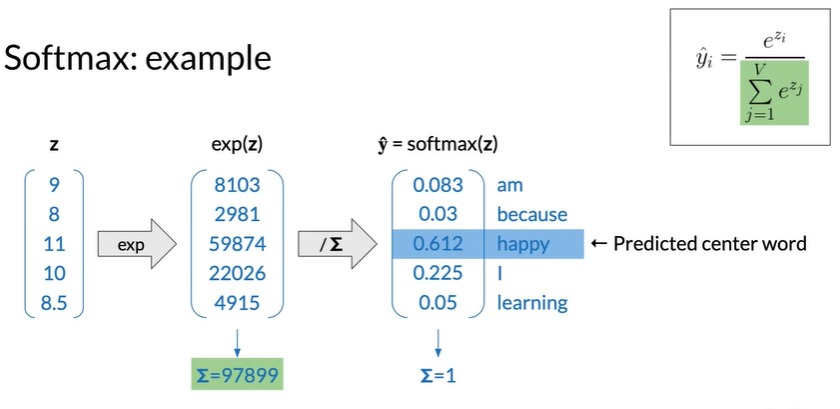
Softmax
e.g.
Training a CBOW model
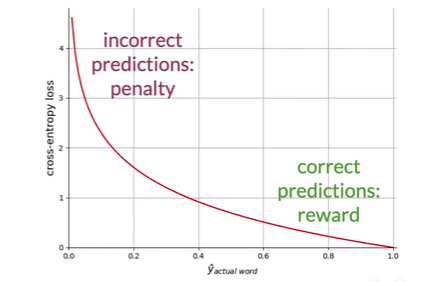
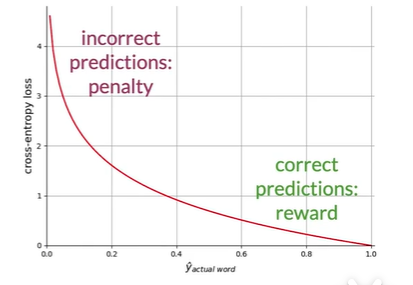
Loss
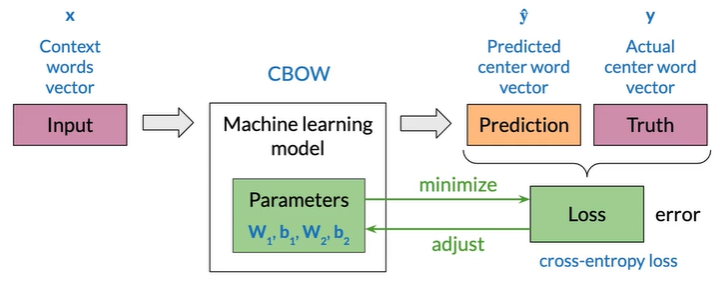
Corss-entropy loss
常在分类中使用
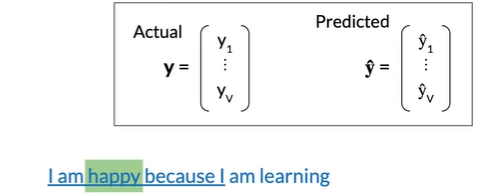
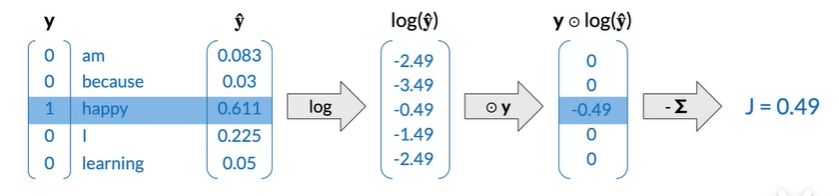
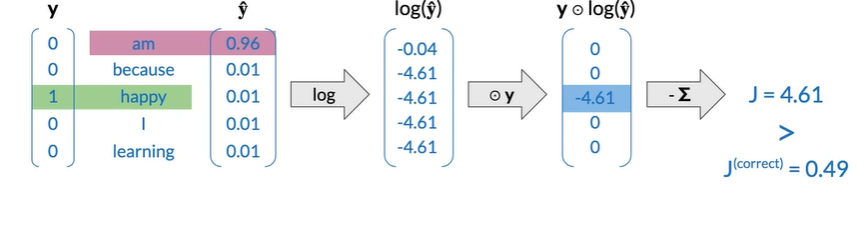
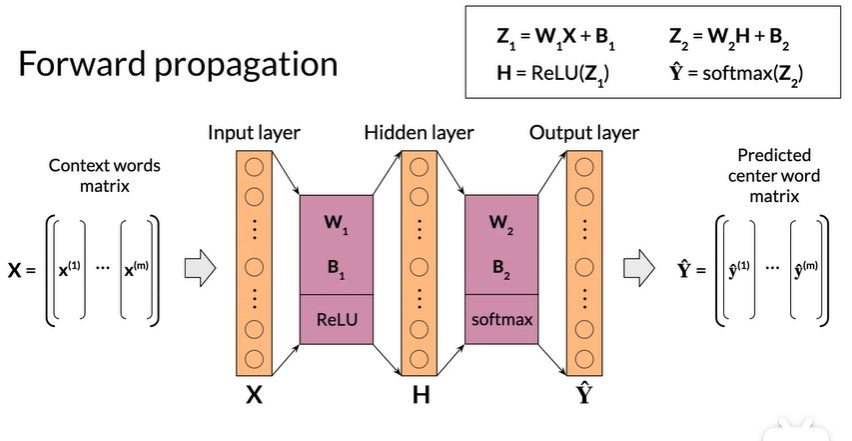
forward propagation
Training process
- forward propagation
- Cost
- Backpropagation and gradient descent
forward propagation
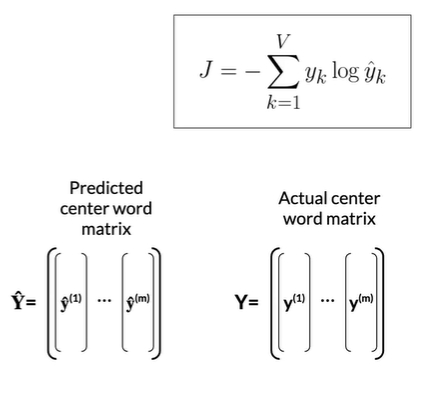
Cost
Cost: mean of losses
Minimizing the cost
-
Backpropagation:calculate partial derivatives of cost with respect to
weights and biases\[\frac{\partial J_{batch}}{\partial W_1}, \frac{\partial J_{batch}}{\partial W_2}, \frac{\partial J_{batch}}{\partial b_1}, \frac{\partial J_{batch}}{\partial b_2} \]\[J_{batch}=f(W_1,W_2,b_1,b_2) \] -
Gradient descent:update weights and biases
Backpropagation

Gradient descent

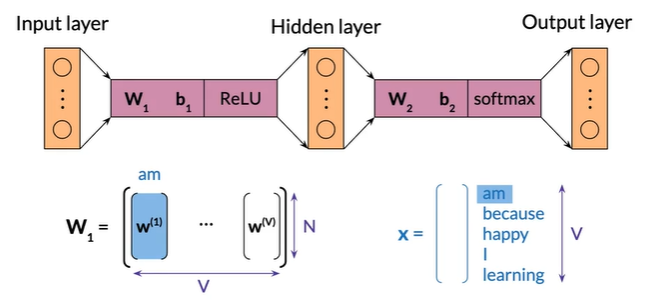
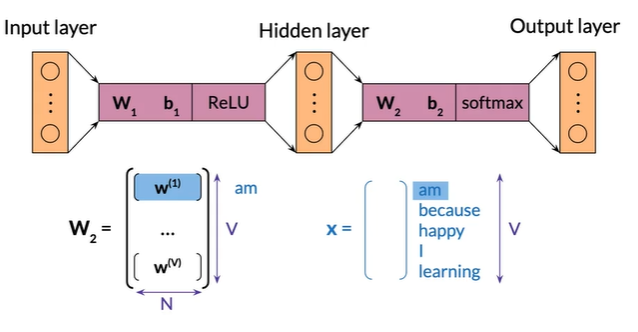
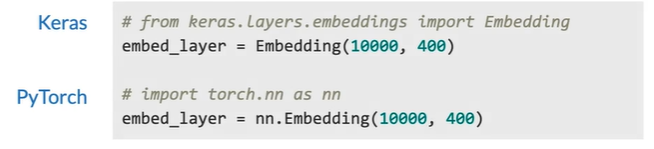
Extracting word embedding vectors
Option 1
Option 2
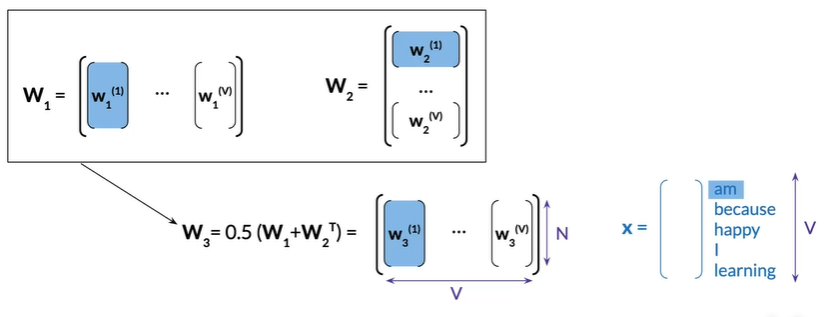
Option 3
取前两个平均值
Evaluation word embedding
Intrinsic evaluation
Test relationships between words
-
Analogies
-
Semantic analogies
“France"is to"Paris"as"Italy"is to<?> -
Syntactic analogies
“seen"is to"saw"as"been"is to<?> -
Ambiguity
“wolf”is to"pack"as"bee"is to <?>→swarm? colony? -
在化学元素对应做的不好,word2vec给出:
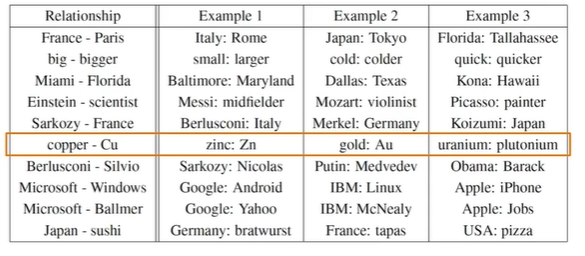
-
-
Clustering
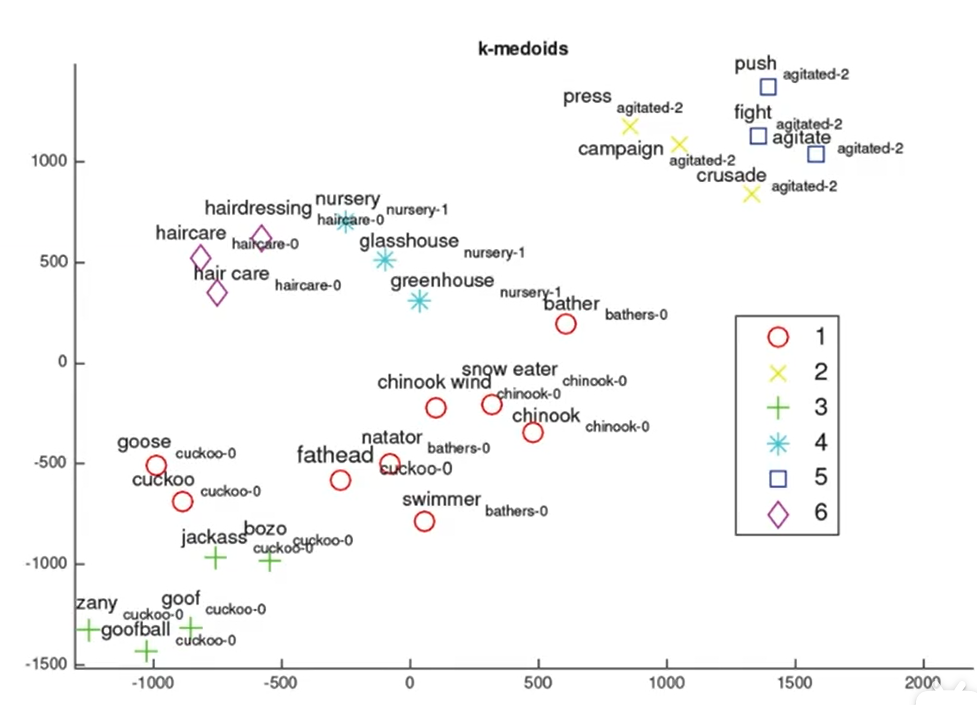
-
Visualization
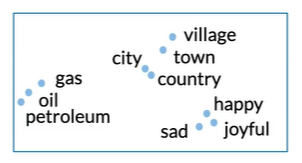
Extrinsic evaluation
Test word embeddings on external task
e.g. named entity recognition, parts-of-speech tagging
- Evaluates actual usefulness of embeddings
- 比内在评估更耗时
- More difficult to troubleshoot
Conclusion
Recap and assignment
- Data preparation
- Word representations
- Continuous bag-of-words model
- Evaluation
Going further
- Advanced language modelling and word embeddings
- NLP and machine learning libraries

 浙公网安备 33010602011771号
浙公网安备 33010602011771号