
[吴恩达团队自然语言处理第二课_1]概率模型:自动更正 最小编辑距离 词性标注 隐式马尔可夫 Viterbi维特比算法
Autocorrect自动更正
what is autocorrect#
将拼写错误的单词更改为正确的单词
Eg:
Happy birthday deah frend
更改为
Happy birthday dear frend
但是如果错误的是deer
Happy birthday deer frend
会单词拼写正确。但是上下文错误
How it works#
| 步骤 | |
|---|---|
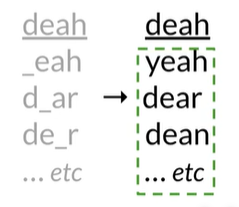
| 1. Identify a misspelled word | deah |
| 2. Find strings n edit distance away | _each d_ar de_r ..etc |
| 3. Filter candidates | 过滤,找出拼写正确的单词 |
| 4. Calculate word probabilities | 计算单词概率 |
Build#
1. Identify a misspelled word#
如果不在单词表中,就是拼写错误的单词(无论上下文如何)
2. Find strings n edit distance away#
找到编辑距离n内的单词,操作的次数
-
Edit: an operation performed on a string to change it
-
Insert (add a letter)
'to': 插入p变成'top';
插入w变成'two'...
-
Delete (remove a letter)
‘hat':'ha','at',’ht‘
-
Switch (swap 2 adjacent letters)
交换两个相邻的字母 'eta':'eat','tea'
3. Filter candidates#
过滤,找出拼写正确的单词
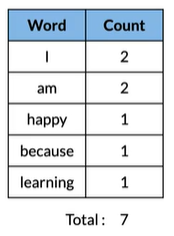
4. Calculate word probabilities#
计算单词概率,选取概率最大的单词
Eg:
I am happy because I am learning
Minimum edit distance#
Eg#
衡量两个单词相似性:计算将一个单词转化成另一个单词的最小操作次数(编辑距离)
Eg:
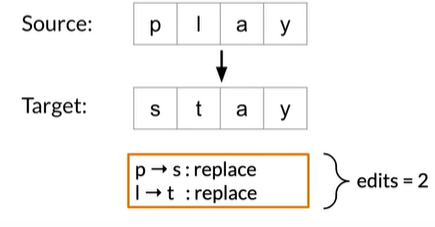
上图将每种操作看作cost都为1,下面我们考虑不一样,Replace视为先delete再insert
| Edit cost: | |
|---|---|
| Inset | 1 |
| Delete | 1 |
| Replace | 2 |
那么Eg就应该为 edit distance=2*2=4
算法#
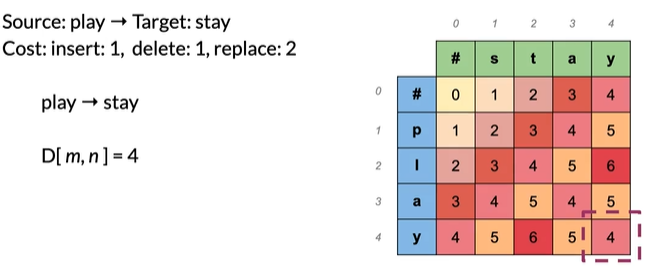
Source: play → Target: stay
使用表格:#开头,有编号
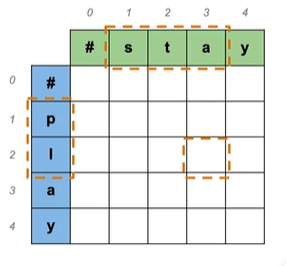
D[2,3]=pl→sta 指的是pl到sta的最小编辑距离
D[2,3]=source[:2]→target[:3]
即D[i,j]=source[:i]→target[:j]
D[m,n]=source→target即为表格右下角,是两个字符串之间的最小编辑距离
表格从左上角开始往右下角进行计算
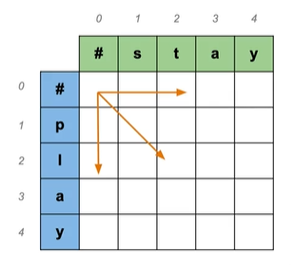
那么开始计算吧
Source: play → Target: stay
Cost: insert:1,delete:1,replace:2
#→# 空到空:0
p→# 一个字符删除后为空:1
#→s 插入一个:1
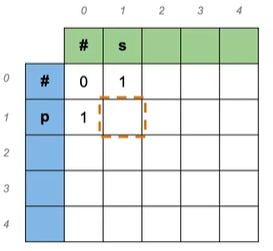
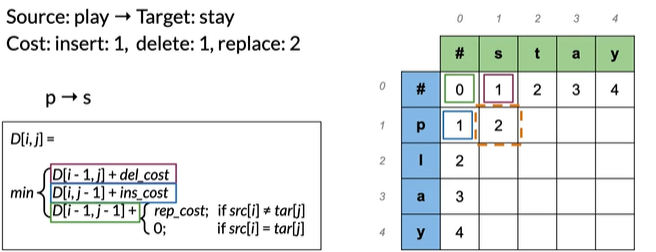
p→s 有多种方法进行转换,每个可能的编辑顺序称为路径,取所有路径最小值:
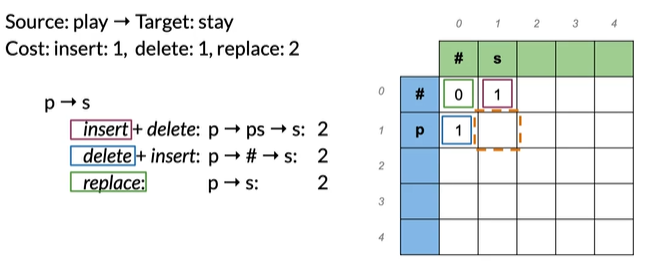
注意看颜色,当前步是上一步的值加上当前步操作的cost,如insert+delete,
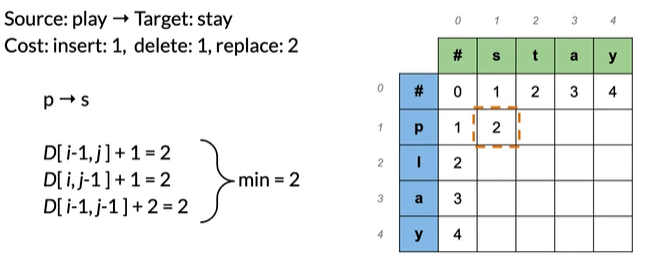
是1(插入s)+1(删除p)=2
replace是绿色框0(上一步)+2(当前步替换),选取所有路径最小值得2
play→#
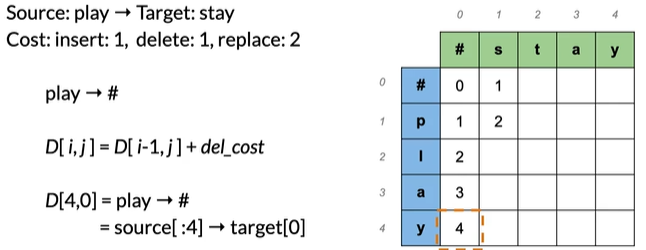
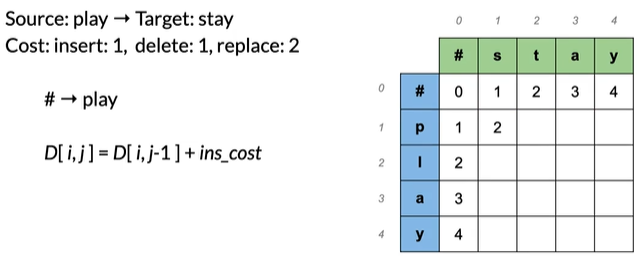
#→play 同理
p→s
play→stay
有表格并不能解决所有问题,有时候还需要知道过程,可以使用Backtrace
回溯,同时这个表格是动态规划的思想
词性标注speech tagging和隐式马尔可夫模型
What is part of speech tagging?#
Part of speech tags(POS)#

Applications of POS tagging#
- 命名实体识别
埃菲尔铁塔位于巴黎。→埃菲尔铁塔、巴黎
- 共指解析
”埃菲尔铁塔位于巴黎。它有324米。“
可以用词性下垂分析出它是埃菲尔铁塔
- 语音识别
用部分语音标签来检查单词序列是否具有高概率
Markov chains 马尔可夫链#
Eg:

在句子中下一个单词的词性往往取决于前一个单词的词性
可视化
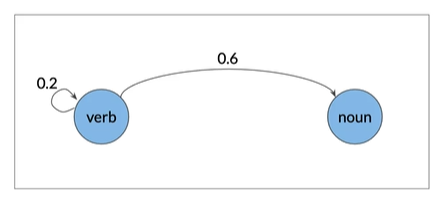
0.6>0.2 说明verb到noun的可能性比verb到verb可能性大
States#
马尔可夫链是一种随机模型,描述了一系列可能的事件
EG 如果用图模拟水的状态,冻结、液体、气态。
将每个状态标记为q1,q2,q3,以便赋名称
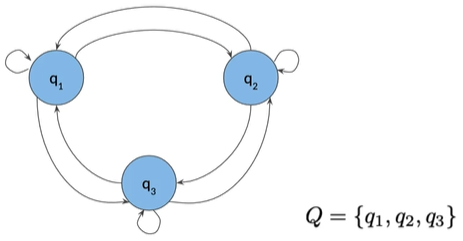
POS tags as States#
将句子视为与词性相关的单词序列,你可以用图表表示该序列,
Eg:
NN:名词,VB:动词,O:其他
图的边缘是与权重关联的转移概率,是一种状态进入其他状态的可能性
马尔可夫属性:下一个事件仅取决于当前事件
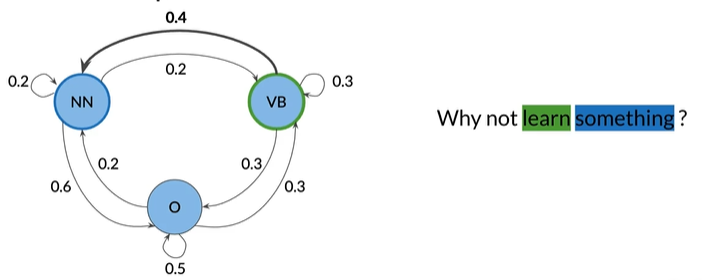
使用表来存储状态和转移概率,该表为转移矩阵,nxn矩阵,其中n是状态数
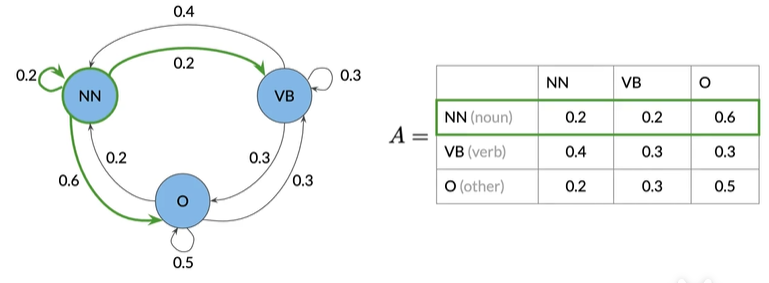
注意:给定所有的可能性,转移概率
缺陷:第一个单词如何分配POS,所以引入初始状态
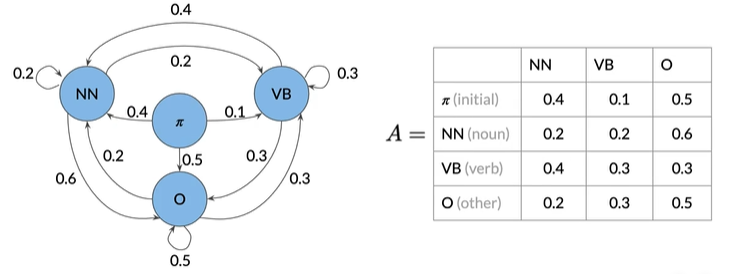
也可以写成实际矩阵
Summary#
- States
- 转移矩阵
第一行是初始概率
Hidden Markov models 隐式马尔可夫模型#
introduction#
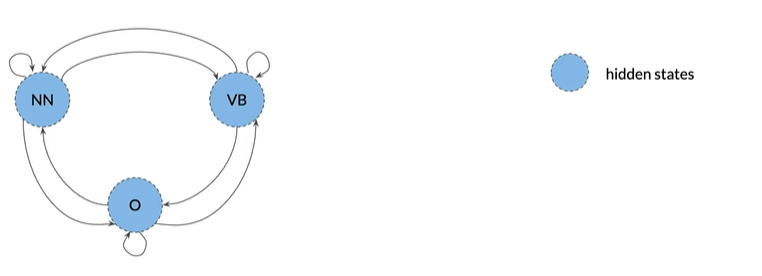
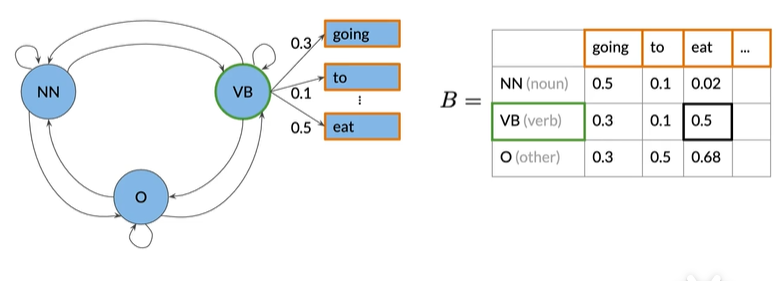
将状态视为隐藏的。从机器的角度看,并不像人一样,看见jump就知道是动词,机器能看见的只有实际的单词,这些单词被认为是可以观察到的,因为他们可以被机器看见

马尔可夫模型和隐式马尔可夫模型都有转移概率,可以用矩阵A表示,
尺寸(n+1)xn,其中n是隐藏状态的数量。
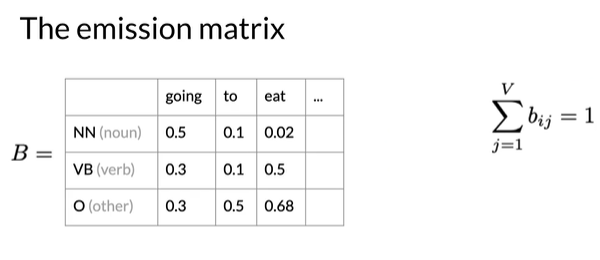
隐式马尔可夫模型还有 Emission probabilities发射概率
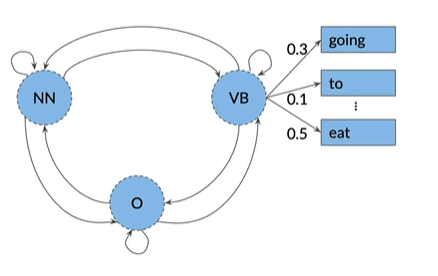
从隐藏状态VB可观察到eat的初始概率为0.5,表示当模型处于VB的隐藏状态的时候,有百分之50概率该模型给出的单词是eat
Emission matrix:每行都指定为一种隐藏状态,每列为一个可观察对象
例如,注意概率的行总和为1
Summary#
- States
- Transition matrix
- Emission matrix
计算 Transition matrix#
词性由背景色表示


可以看出有两种组合的标签,而标签对的数量:
蓝+紫有两个;蓝色标记开头的有3个

可以得出 蓝色标记后是紫色标记的概率是2/3
为了正式的计算,我们需要先找出corpus中所有出现的标记对,定义为函数C
接下来计算概率,可以结合Eg理解
Eg:

将每句话视为一个单独的句子,将开始令牌添加到开头
<s>In a Station of the Metro
<s>The apparition of these faces in the crowd:
<s>Petals on a wet, black bough.
全部转化为小写
<s>in a station of the metro
<s>the apparition of these faces in the crowd:
<s>petals on a wet, black bough.

根据对应颜色的观察,填充得下图
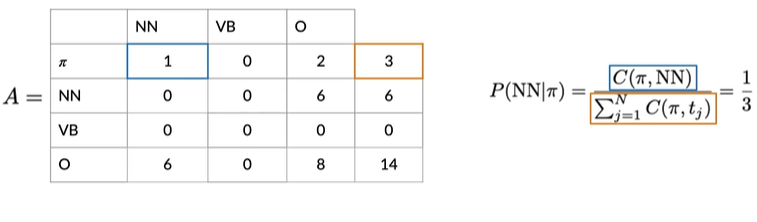
计算,如在起始标记(Π)后的NN,即NN标签的初始概率为1/3
可以发现出现了很多0,所以我们需要平滑一下函数
Smoothing#

将epsilon设为0.001,N为词汇量,得到如下矩阵
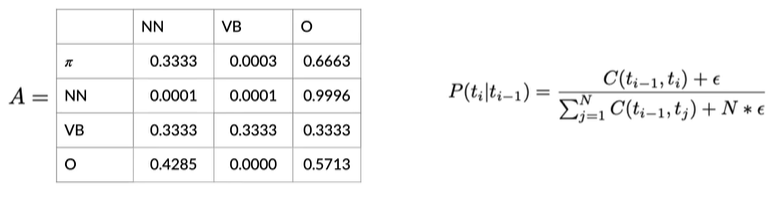
在实际使用中,可能并不想将平滑应用到初始概率,因为如果在初始概率使用平滑,向可能为0的结果添加一个很小的值,将可以使句子开头出现任何词性,包括标点符号
计算Emssion Matrix#


You的emission probabilities为2/3
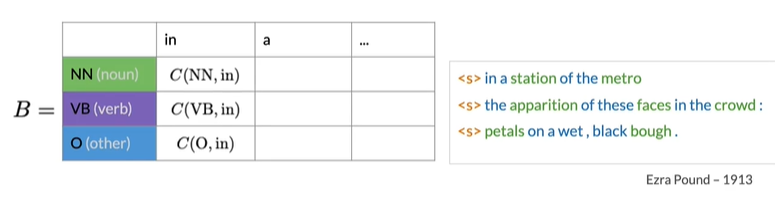
名词标签与in关联0次,动词标签与0关联0次,O标签两次,所以第一列得0,0,2,使用平滑函数
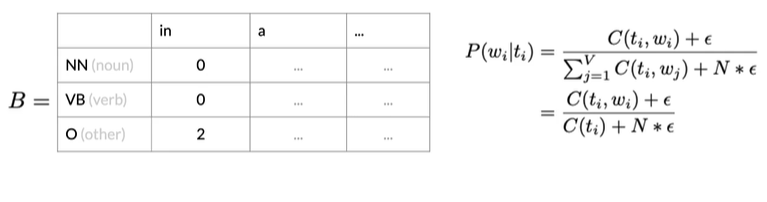
Summary
- Calculate transition and emssion matrix
- How to apply smoothing
Viterbi algorithm#
a graph algorithm
Eg#
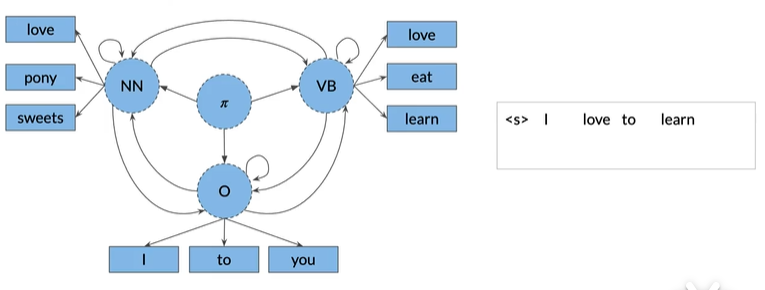
注意love只能由NN和VB发出
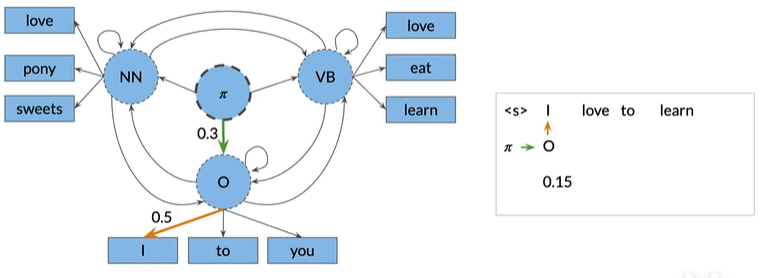
I:从初始状态(Π)开始,选择下一个最可能的隐藏状态,即O状态中的I,如下图,绿色的转移概率是0.3,橙色的发射概率是0.5,观察单词的联合概率,I通过O状态的转换为0.15,即转移概率0.3乘以发射概率0.5
LOVE:确定了I之和,接下来有两种可能性获得love这个词,通过隐藏状态NN或者
隐藏状态VB,而进入两个状态的转移矩阵相等(都是0.5),如下图
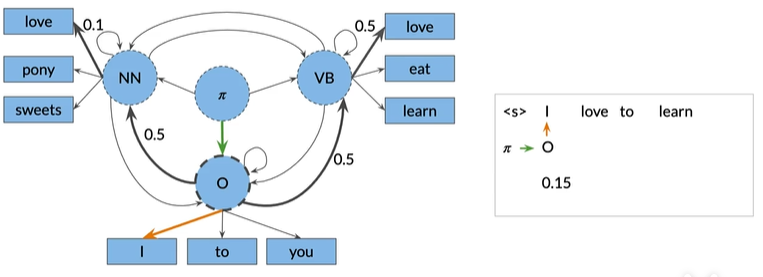
TO:但是在VB中的love发射概率更高(0.5>0.1),所以我们应该选择这个,组合概率为0.25,接下来回到O状态,因为其他的状态没有to的非零发射概率,如下图,得到0.2*0.4=0.08
LEARN:接下来再次回到VB状态,因为其他状态没有learn单词,如下图,得组合概率为0.5*0.2=0.1
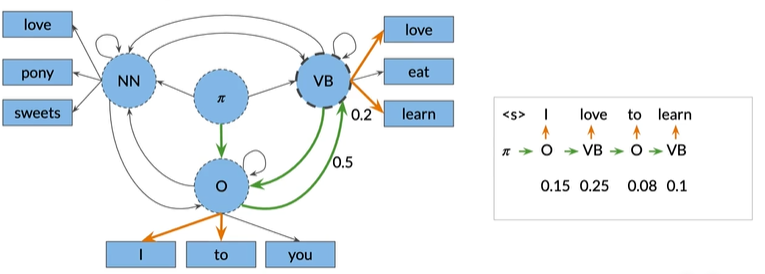
Probalities for this sequence of hidden states:
0.15*0.25*0.08*0.1=0.0003
Steps 矩阵描述#
- Initialization step
- Forward pass 前进
- Backward pass 后退
给定转移和发射矩阵,接下来使用辅助矩阵C和D,C矩阵存中间最优概率,D是访问状态的索引,N行,N为POS数量,K列,K是给定序列中的单词数
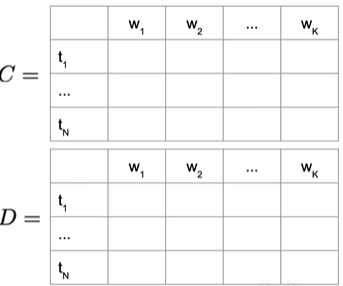
1. Initialization Step#
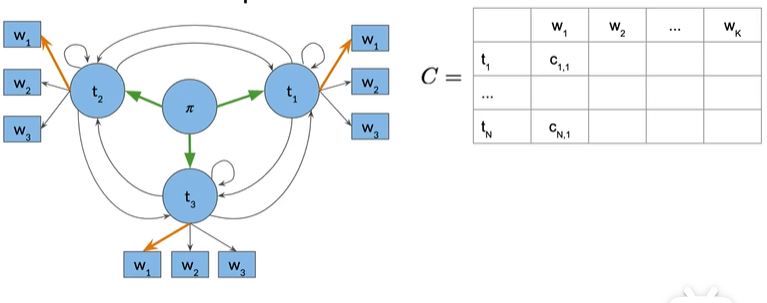
第一个列的ti和w1表示我们正尝试从词性标签1到单词w1,所以第一列
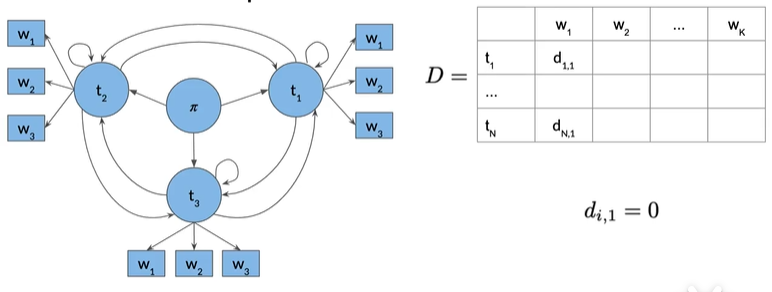
对于D矩阵,第一列就初始为0
2. forward pass#
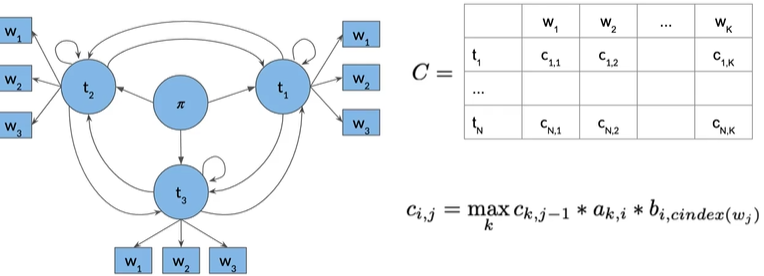
 在每个di,j中,只需要保存k(ci,j最大化),argmax函数返回使公式最大化的参数k而不是最大值
在每个di,j中,只需要保存k(ci,j最大化),argmax函数返回使公式最大化的参数k而不是最大值
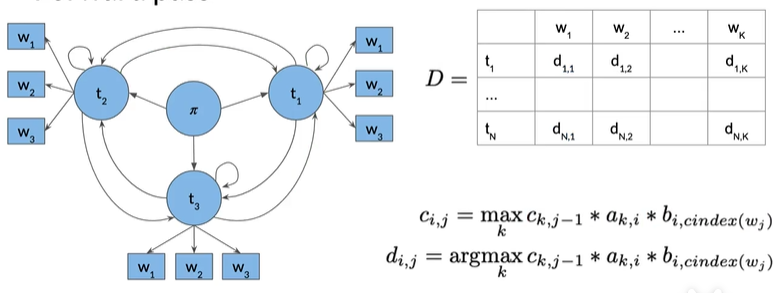
3. backward pass#
 t
t
填充矩阵C和D之和,我们需要从D提取路径,它表示最有可能生成我们序列的隐藏状态序列,单词 1 一直到单词 k。
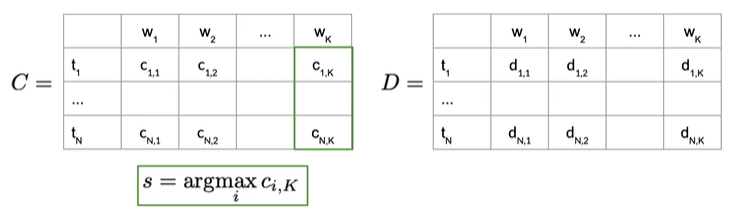
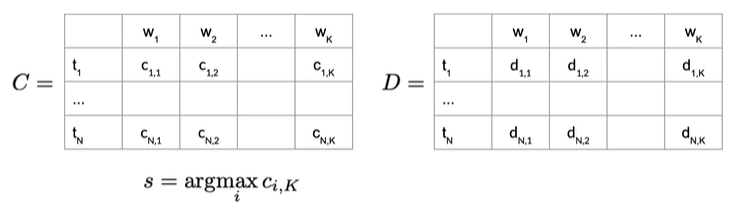
首先计算最后一列ci,k中概率最高的值,最有可能的隐藏状态序列生成给定的单词序列,利用索引s来向后遍历矩阵D,重建词性标签序列
Eg:
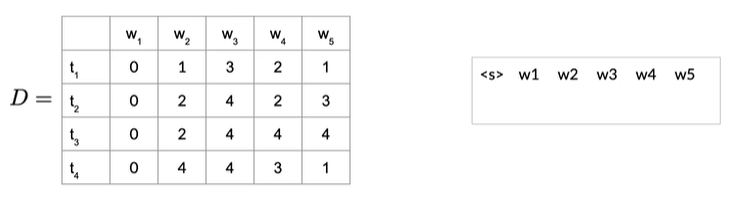
四种状态,5个单词,D存储在前进路径中遍历的隐藏状态的词性标签,如果我们要回到隐藏状态,就从具有可能性最高的路径开始
实际上得到了最可能的隐藏状态序列,或者词性标签,我们要从C中找到最后一列概率最高的,如下图
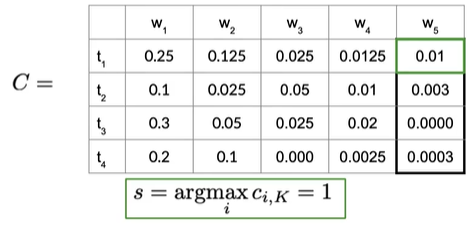
得到最高概率0.01,所以索引s为
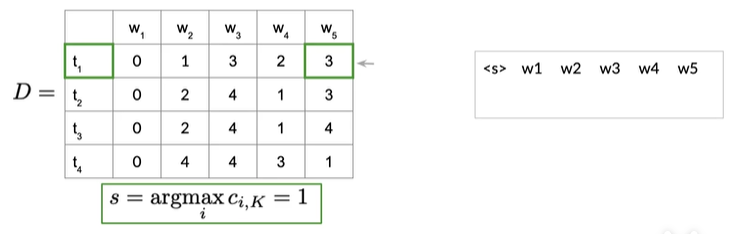
表示单词w5最可能的状态是词性标签的t1,所以我们将t1添加到序列的末尾,接下来在D中查找下一个索引,索引告诉你它是从何而来,可以看见第一行第五列存储的值是3,即下一个索引是3,来到第三行第四列,是t3,即w4最可能的状态是t3,如下图
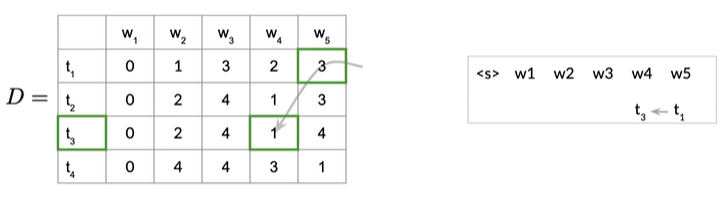
将w4和t3相关联,往左移动一列,因为存在第三行第四列的值为1,我们就可以将词性标签t1分配给前一个单词,即w3,如下图
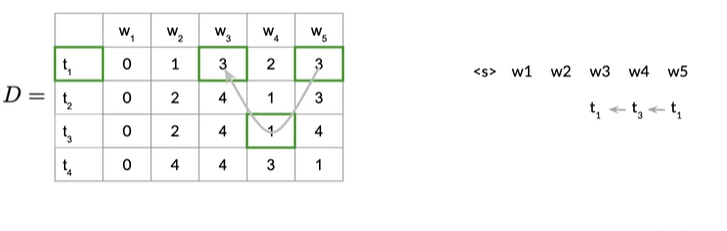
第一行第3列存储的值是3,所以在第三行第二列的w2对应的状态是t3,它的前一个索引是2,如下图
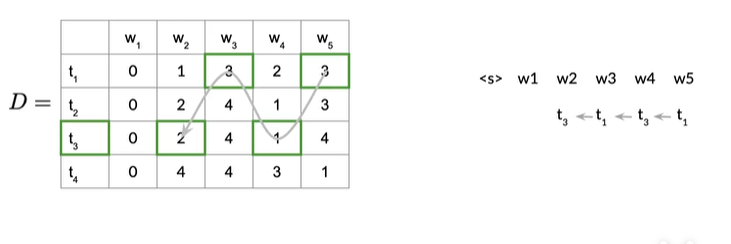
因为前一个索引是2,所以初始状态为t2,如下图
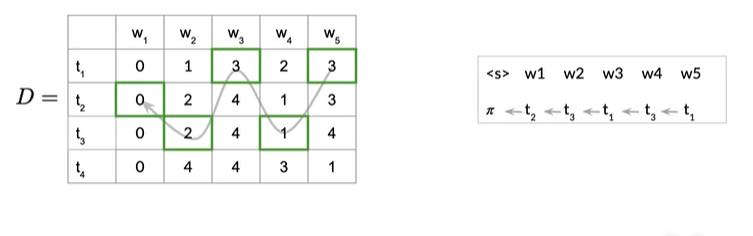
在实现代码时需要注意的问题
-
python下标开始为0
-
使用log probabilities,很小的概率相乘时,使用对数概率求和,而不是小数相乘



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
2019-02-13 UVA 814 The Letter Carrier's Rounds