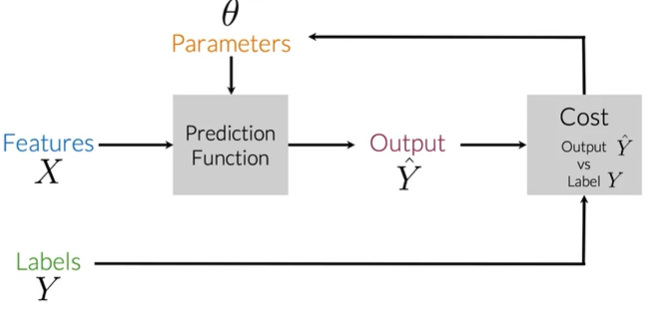
[吴恩达团队自然语言处理第一课_1]分类:逻辑回归与朴素贝叶斯
监督学习与情感分析
Supervised ML(training)
V维特征
出现为1,否则为0,得出V维向量

计数器
包含四个推文的Corpus(语料库)
I am happy because I am learning NLP I am happy I am sad,I am not learning NLP
I am sad
得到vocabulary
I
am happy because learning NLP sad not
已经有的分类
| Positive tweets | negative tweets |
|---|---|
| I am happy because I am learning NLP | I am sad,I am not learning NLP |
| I am happy | I am sad |
计数
freq: dictionary mapping from (word,class) to frequency
| vocabulary | PosFreq(1) | NegFreq(0) |
|---|---|---|
| I | 3 | 3 |
| am | 3 | 3 |
| happy | 2 | 0 |
| because | 1 | 0 |
| learning | 1 | 1 |
| NLP | 1 | 1 |
| sad | 0 | 2 |
| not | 0 | 1 |
特征提取得向量
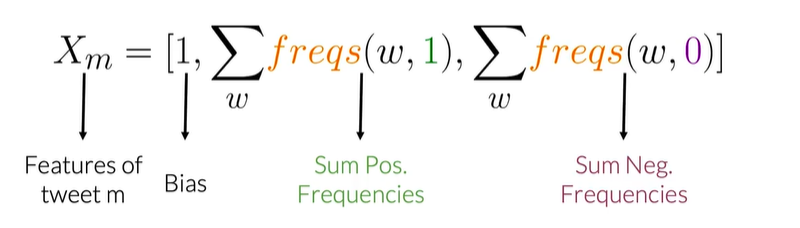
例如I am sad,I am not learning NLP
| vocabulary | PosFreq(1) | NegFreq(0) |
|---|---|---|
| I | 3 | 3 |
| am | 3 | 3 |
| learning | 1 | 1 |
| NLP | 1 | 1 |
| sad | 0 | 2 |
| not | 0 | 1 |
计算
预处理
停用词和标点符号
| Stop words | Punctuation |
|---|---|
| and is are at has for a | , . ; ! " ' |
将@YMourri and @AndrewYNg are tuninga GREAT AI modelat https://deeplearning. ai!!!
去掉停用词@YMourri @AndrewYNg tuning GREAT AI model https://deeplearning. ai!!!
去掉标点符号``@YMourri @AndrewYNg tuning GREAT AI model https://deeplearning. ai`
Handles and urls
去掉handles和urls 后tuning GREAT AI model
stemming and lowercasing
stemming词干提取:去除单词的前后缀得到词根的过程

Preprocessed tweet
[tun,great,ai,model]

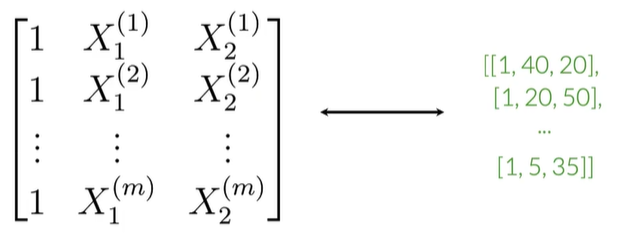
代码
#建立频率词典
freqs=build_freqs(tweets,labels)#build freqs dicitonary
#初始化X矩阵
X=np.zeros((m,3))
for i in range(m):#For every tweet
p_tweet=process_tweet(tweets[i])
X[i,:]=extract_features(p_tweet,freqs)#提取特征

逻辑回归
公式
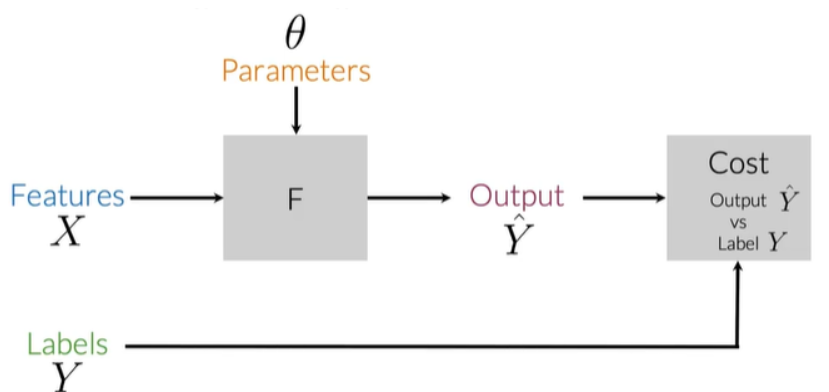
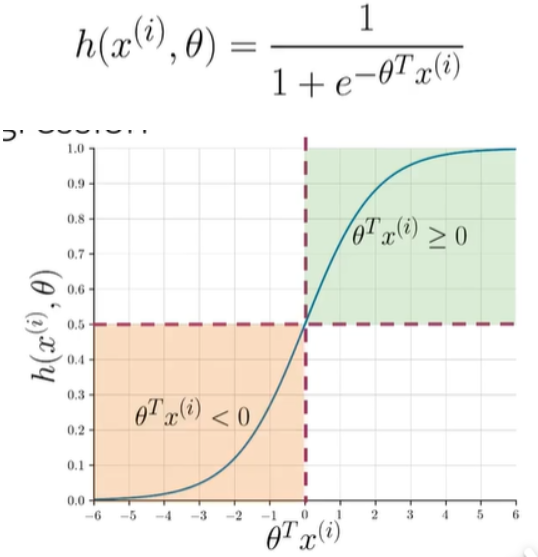
左下角预测为negative,右上角为positive
@YMourri and @AndrewYNg are tuning a GREAT AI model
去掉标点符号和停用词后,转化为词干
[tun,ai,great,model]
LR
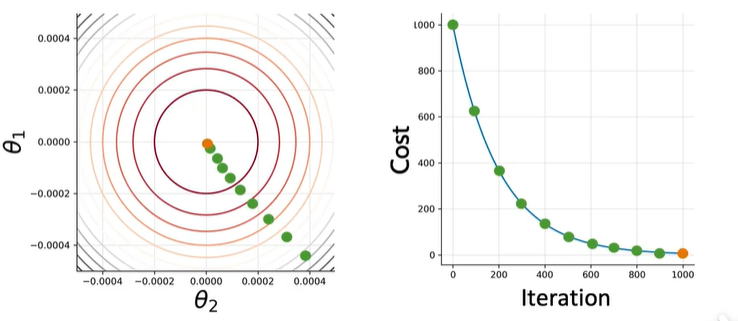
梯度下降
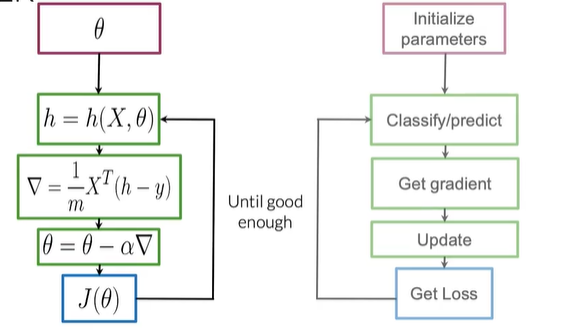
测试
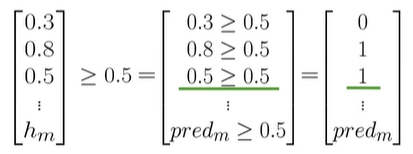
得到如上预测向量,用验证集来计算
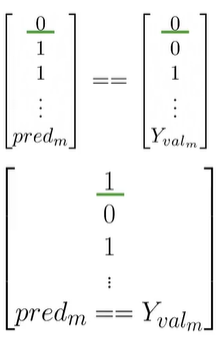
预测结果和验证集比较,如果相等就为1,如
计算
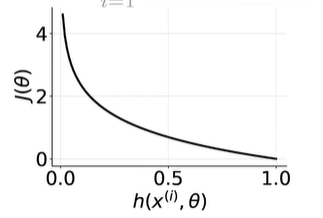
cost function损失函数
m:样本数,负号使结果为正数
当标签为1时,与下面相关
| y^i | h(x^i,theta) | |
|---|---|---|
| 0 | any | 0 |
| 1 | 0.99 | ~0 约等于0 |
| 1 | ~0 | -inf 负无穷 |
可以看出,当标签为1,预测1,损失很小,预测为0损失很大
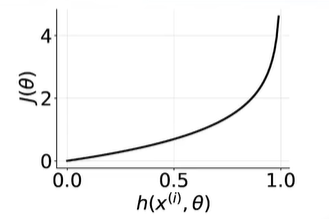
当标签为0,与下面相关
| y^i | h(x^i,theta) | |
|---|---|---|
| 1 | any | 0 |
| 0 | 0.01 | ~0 |
| 0 | ~1 | -inf |
情感分析与朴素贝叶斯
朴素贝叶斯
介绍
某类别推特总数除以语料库中的推文总数
如
 $$
P(A)=N_{pos}/N=13/20=0.65\\
P(Negative)=1-P(Positive)=0.35
$$
$$
P(A)=N_{pos}/N=13/20=0.65\\
P(Negative)=1-P(Positive)=0.35
$$
Probabilities
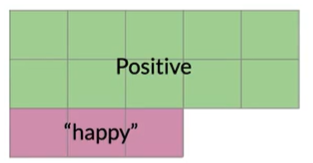
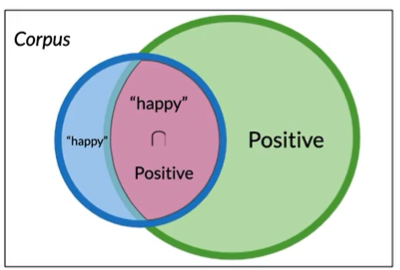
包含happy的推特
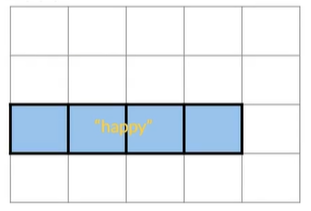 $$
B\rightarrow tweet contains "happy"\\
P(B)=P(happy)=N_{happy}/N\\
P(B)=4/20=0.2
$$
$$
B\rightarrow tweet contains "happy"\\
P(B)=P(happy)=N_{happy}/N\\
P(B)=4/20=0.2
$$
 $$
P(A\cap B)=P(A,B)=3/20=0.15
$$
$$
P(A\cap B)=P(A,B)=3/20=0.15
$$
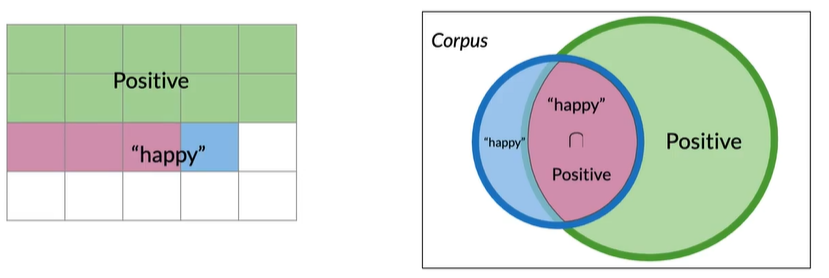
Conditional Probabilities条件概率

P(AB)=P(A|B)*P(B)
P(AB)是AB同时发生,P(A|B)是B发生条件下A发生的概率,乘以P(B)即AB同时发生.或在A集合中一个元素同时也属于B的概率
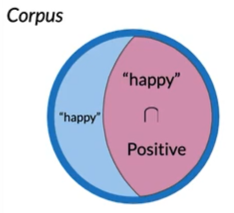
 $$
P(B|A)=P("happy"|Positive)\\
P(B|A)=3/313=0.231
$$
$$
P(B|A)=P("happy"|Positive)\\
P(B|A)=3/313=0.231
$$
 $$
P(Positive|"happy")=\frac{P(Positive\cap"happy")}{P("happy")}
$$
$$
P(Positive|"happy")=\frac{P(Positive\cap"happy")}{P("happy")}
$$
Bayes' Rule
而
得
即
naive Bayes for sentiment analysis
naive:因为假设X和Y是独立的,但是很多情况并不是
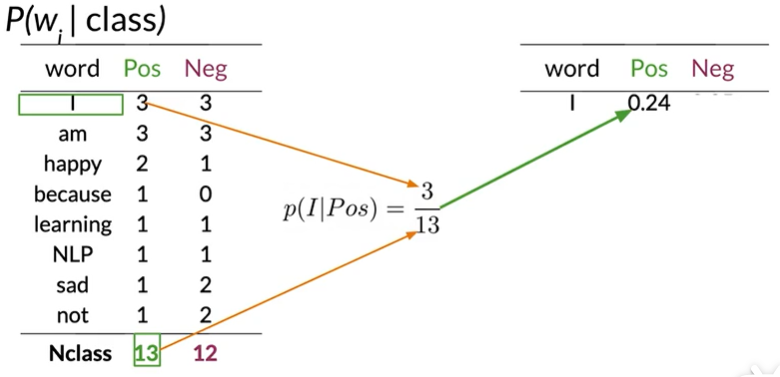
step 1 频率表
Positive tweets:
I am happy because I am learning NLP
I am happy, not sad
Negative:
I am sad, I am not learning NLP
I am sad, not happy
进行计数
| word | PosFreq(1) | NegFreq(0) |
|---|---|---|
| I | 3 | 3 |
| am | 3 | 3 |
| happy | 2 | 1 |
| because | 1 | 0 |
| learning | 1 | 1 |
| NLP | 1 | 1 |
| sad | 1 | 2 |
| not | 1 | 2 |
| N_class | 13 | 12 |
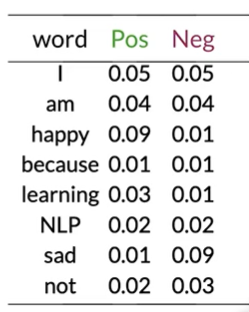
step 2 概率表
| word | Pos | Neg |
|---|---|---|
| I | 0.24 | 0.25 |
| am | 0.24 | 0.25 |
| happy | 0.15 | 0.08 |
| because | 0.08 | 0 |
| learning | 0.08 | 0.08 |
| NLP | 0.08 | 0.08 |
| sad | 0.08 | 0.17 |
| not | 0.08 | 0.17 |
| sum | 1 | 1 |
像I am lerning之类差值很小的值为中性词,而happy是power word,becuase的Neg为0,造成计算问题,为避免这种情况,我们使概率函数平滑
| word | Pos | Neg |
|---|---|---|
| I | 0.20 | 0.20 |
| am | 0.20 | 0.20 |
| happy | 0.14 | 0.10 |
| because | 0.10 | 0.05 |
| learning | 0.10 | 0.10 |
| NLP | 0.10 | 0.10 |
| sad | 0.10 | 0.15 |
| not | 0.10 | 0.15 |
naive Bayes inference condition rule for binary classification
Tweet:
I am happy today; I am learning.
Laplacian Smoothing 拉普拉斯平滑
避免概率为0
+1:防止概率为0,为了+1后的归一化,分母加V,词汇表中去重后单词的数量

四舍五入后得Pos和Neg,接下来利用
| word | Pos | Neg | ratio |
|---|---|---|---|
| I | 0.19 | 0.20 | 1 |
| am | 0.19 | 0.20 | 1 |
| happy | 0.14 | 0.10 | 1.4 |
| because | 0.10 | 0.05 | 1 |
| learning | 0.10 | 0.10 | 1 |
| NLP | 0.10 | 0.10 | 1 |
| sad | 0.10 | 0.15 | 0.6 |
| not | 0.10 | 0.15 | 0.6 |
| sum | 1 | 1 |
积极的词>1,越大说明越积极,消极的词小于1,越接近0说明越消极,
Navie Bayes' inference 推论
先验概率对不均衡的数据集很重要
Log likelihood
连续相乘面临下溢出风险,太小而无法存储。
使用数学技巧先log
log prior + log likelihood
Calculating Lambda
lambda为比率的对数
 $$
\lambda(I)=log\frac{0.05}{0.05}=log(1)=0
$$
得
$$
\lambda(I)=log\frac{0.05}{0.05}=log(1)=0
$$
得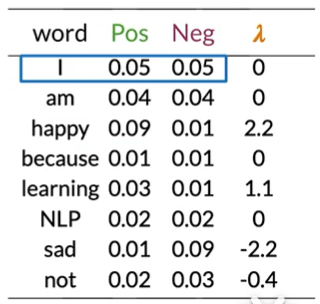
doc:I am happy because I am learning.
log likelihood=0+0+2.2+0+0+0+1.1=3.3
如右图
如右图
3.3>0得出推文为正
summary
naive Bayes model
step0: collect and annotate corpus

step1: preprocess
-
lowercase
-
remove punctuation, urls, names
-
remove stops words
-
stemming
-
tokenize sentences

step2: word count
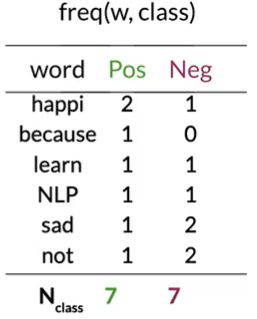
step3: P(w|class)
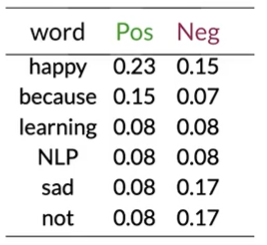
step4: get lambda
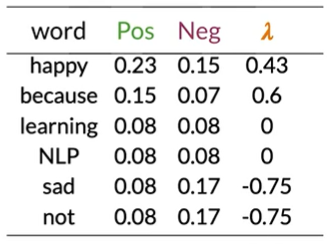
step5: get the log prior
summary
-
get or annotate a dataset with positive and negative tweets
-
preprocess the tweets: process_tweet(tweet)->[w1,w2,w3,...]
-
compute freq(w,class)
-
get P(w|pos),P(w|neg)
-
get lambda(w)
-
compute logprior=log(P(pos)/P(neg))
test navie baye's
-
predict using naive bayes model
-
using your validation set to compute model accuray
-
log-likehood dictionary
\[\lambda(w)=log\frac{P(w|pos)}{P(w|neg)} \]
-
\[logprior=log\frac{D_{pos}}{D_{neg}}=0 \]
-
tweet:
[I,pass,the,NLP,interview]依次累加分数,表格没有的单词为中性词不需要操作,添加logprior平衡数据集
score=-0..01+0.5-0.01+0+logprior=0.48
pred=score>0积极
-
\[X_{val}\ Y_{val}\ \lambda_{logprior}\\ score=predict(X_{val},\lambda,logprior)\\ pred=score>0\\ \left[\begin{matrix}0.5\\-1\\1.3\\...\\score_m\end{matrix}\right]>0 =\left[\begin{matrix}0.5>0\\-1>0\\1.3>0\\...\\socre_m>0\end{matrix}\right] =\left[\begin{matrix}1\\0\\1\\...\\pred_m\end{matrix}\right] \]
首先,计算Xval中每列的分数,计算每个分数是否大于0,得到pred矩阵,1为积极,0为消极
summary
-
\[X_{val}\ Y_{val}\longrightarrow Performance\ on\ unseen\ data \]
-
\[Predict\ using\ \lambda and logprior for each new tweet \]
-
\[Accuracy\ \longrightarrow \frac{1}{m}\sum_{i=1}^m(pred_i==Y_{val_i}) \]
-
\[what\ about\ words\ that\ do\ not\ appear\ in\ \lambda (w)? \]
Application of naive bayes
applicatons:
-
作者识别
\[\frac{P(莎士比亚|book)}{P(海明威|book)} \] -
垃圾邮件过滤
\[\frac{P(spam|email)}{P(nonspam|email)} \] -
Information retrieval
\[P(document_k|query)\varpropto \prod_{i=0}^{|query|}P(query_i|document_k)\\ Retrieve\ document\ if\ P(document_k|query)>threshold \]最早应用于查找数据库中相关和不相关的文档
-
word disambiguation消除单词歧义
Bank:河岸或银行
navie bayes assumptions假设
Independence
预测变量或特征之间的独立性
It is sunnuy and hot in the Sahara desert
假设文本中的单词是独立的,但通常情况并非如此,sunny 和 hot 经常同时出现,可能会导致低估或者高估单个单词的条件概率
It's always cold and snowy in _
spring?summer?fall?winter?
贝叶斯认为他们相等,但是上下文得是winter
Relative frequency in corpus
依赖与数据集的分布。实际上推文中发送正面的推文频率高于负面推文的频率
错误分析
-
Removing punctuation and stop words 预处理过程失去语义
-
word order 单词顺序影响句子的含义
-
adversarial attaks 人类有些自然语言的怪癖
错误案例
-
去掉标点符号
Tweet:
My beloved grandmother :(去掉
:(processed_tweet:
[belov,grandmoth] -
去停顿词
Tweet:
This is not good, because your attitude is not even close to being nice.prcessed_tweet:
[good,attitude,close,nice] -
单词顺序
tweet:
I am happy because I do not go.tweet:
I am not happy because I did go.not被贝叶斯分类器忽略
-
Adversarial attacks
对抗攻击,Sarcasm, Irony and Euphemisms 面对讽刺和委婉语
tweet:
This is a ridiculously powerful movie. The plot was gripping and I cried through until the ending!processed_tweet:
[ridicul,power,movi,ploy,grip,cry,end]积极的推文处理获得大量否定的词汇

 浙公网安备 33010602011771号
浙公网安备 33010602011771号