MySQL的使用和SQL语句的学习
一、认识数据库
1. 数据库分类
通常数据库被分为关系型数据库和非关系型数据库:
关系型数据库:MySQL、 Oracle、DB2、SQL Server、 Postgre SQL等;
- 关系型数据库通常我们会创建很多个二维数据表;
- 数据表之间相互关联起来,形成一对一、一对多、多对对等关系;
- 之后可以利用SQL语句在多张表中查询我们所需的数据;
- 支持事务,对数据的访问更加的安全;
非关系型数据库:MongoDB、Redis、Memcached、HBse等;
- 非关系型数据库的英文其实是Not only SQL,也简称为NoSQL ;
- 相当于非关系型数据库比较简单一些,存储数据也会更加自由(甚至我们可以直接将一个复杂的json对象直接塞入到数据库中);
- NoSQL是基于Key-Value的对应关系,并且查询的过程中不需要经过SQL解析,所以性能更高;
- NoSQL通常不支持事务,需要在自己的程序中来保证一些原子性的操作;
2. 下载和安装MySQL
详情看我博客文章MySQL的下载和安装
3.MySQL的连接
这里我使用工具
Navicat软件,相比在终端使用更加方便。
在软件左上角点击连接按钮,输入相关信息即可。然后测试连接,连接成功就可。
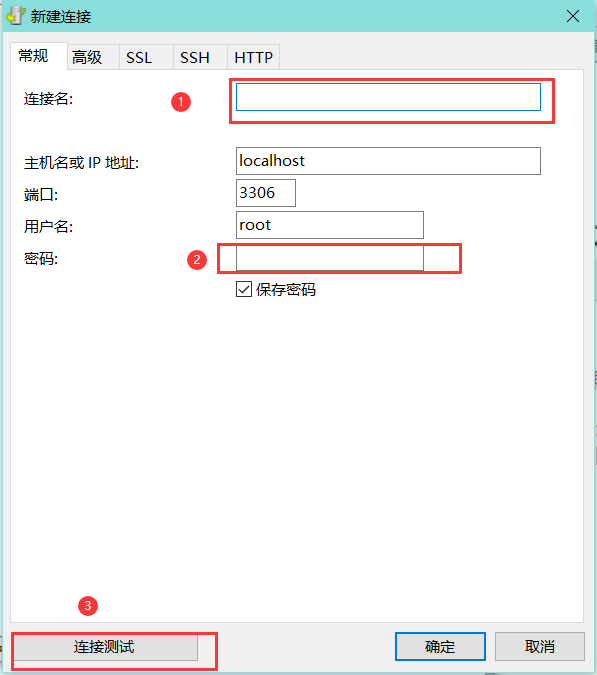
随后双击你设置的连接名就可以查看本机的数据库列表。
4. 字符集和排序规则的选择
当使用Navicat软件,新建数据库时:
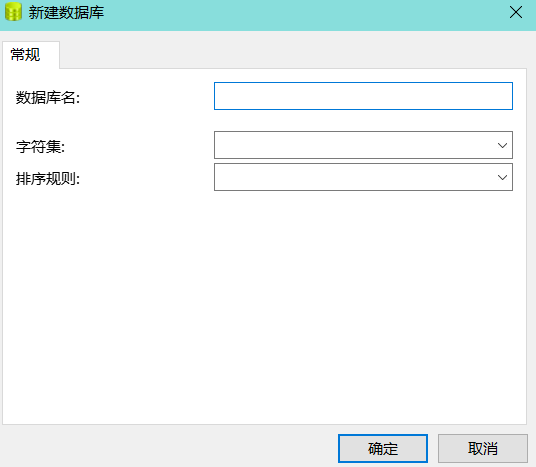
会出现选择字符集和排序规则(这两个看存储数据需求),当然数据库名看自己想起什么名字。
4.1 字符集
一般选择utf8。如果你存储的数据中有emoji表情这类的(如:😎🙂),使用utf8mb4进行存储。
原因:
utf8mb4兼容utf8,且比utf8能表示更多的字符。unicode编码区从1 ~ 126就属于传统utf8区,当然utf8mb4也兼容这个区,126行以下就是utf8mb4扩充区。
4.2 排序规则
一般有以下几种:
utf8_general_ci✔utf8_unicode_ciutf8_general_csutf8_bin
- 首先,
ci表示case insensitive,对大小写不敏感; cs区分大小写;bin是以二进制数据存储,且区分大小写。utf8_general_ci和utf8_unicode_ci对于存储语言为中、英文来说没有实质性的差别;utf8_general_ci校对速度快,但准确度稍差。(准确度够用,一般使用这个)utf8_unicode_ci准确度高,但校对速度稍慢。
二、SQL
1. SQL的数据类型
1.1 数字类型
| 整数数字类型: | 存储字节(Bytes) |
|---|---|
TINYINT |
1 |
SMALLINT |
2 |
MEDIUMINT |
3 |
INT(INTERER) |
4 |
BIGINT |
8 |
| 浮点数字类型: | 存储字节(Bytes) |
|---|---|
FLOAT |
4 |
DOUBLE |
8 |
1.2 日期类型
| 日期类型 | 格式 | 范围 |
|---|---|---|
YEAR |
YYYY | 1901 ~ 2155,或0000 |
DATE |
YYYY-MM-DD | '1000-01-01'到'9999-12-31' |
DATETIME |
YYYY-MM-DD hh:mm:ss | 1000-01-01 00:00:00 到 9999-12-31 23:59:59 |
TIMESTAMP |
YYYY-MM-DD hh:mm:ss | 1970-01-01 00:00:01 到 2038-01-19 03:14:07 |
1.3 字符串类型
| 字符串类型 | 特点 | 大小长度 |
|---|---|---|
CHAR |
固定长度,被查询时会删除后面的空格 | 0 ~ 255 |
VARCHAR |
可变长度,被查询时不会删除后面的空格 | 0 ~ 65535 |
TEXT |
存储大的字符串类型 |
2. 表约束
2.1 主键
主键:PRIMARY KEY
- 主键是表中唯一索引;
- 并且必须是不能为空NOT NULL;
- 主键可以是多列索引,PRIMARY KEY( key_part,... ),称为联合主键;
2.2 唯一
唯一:UNIQUE
表示该字段的值希望是唯一的,不会重复的。比如手机号码、身份证号码等;
2.3 不能为空
不能为空:NOT NULL
表示当前字段必须有值,不能为空。
2.4 默认值
默认值:DEFAULT
当前字段在没有值时,希望有一个默认值时。
2.5 自动递增
自动递增:AUTO_INCREMENT
3. DDL
对数据库或表进行创建、删除、修改等操作。
3.1 数据库操作
# 查询所有数据库 大小写均可。
show databases;
# 选择某一个数据库
use '数据库名';
# 查询当前使用的数据库
SELECT DATABASE();
# 新建一个数据库
create database '数据库名'; # 当数据库名重复时,会报错
# 解决:如果不存在再创建
CREATE DATABASE IF NOT EXISTS '数据库名';
# 新建数据库并且指定 字符集和排序规则
CREATE DATABASE IF NOT EXISTS huya CHARACTER SET utf8 COLLATE utf8_general_ci;
# 删除数据库
DROP DATABASE IF EXISTS '数据库名';
# 修改数据库的字符集和排序规则
ALTER DATABASE '数据库名' CHARACTER SET = utf8 COLLATE = utf8_unicode_ci;
3.2 数据表操作
# 查看所有的数据表
show tables;
# 查看某一个表的结构
DESC "数据表名"
# 创建一个数据表
create table if not exists "数据表名" (
id int primary key auto_increment,
name varchar(10) not null,
age int default 0,
pthone varchar(20) unique,
createTime timestamp,
updateTime timestamp
);
# 高版本 MySQL 使用
# 使createTime在创建时直接赋值
alter table "数据表名" modify createTime timestamp default current_timestamp;
# 使updateTime能够在当前数据改变时,自动改变时间
alter table "数据表名" modify updateTime timestamp on update current_timestamp;
# 删除表
drop table if exists "数据表名";
# 修改表
# 1. 修改表名
alter table "旧数据表名" rename to "新数据表名";
# 2. 增加新的字段
alter table "数据表名" add "字段名" '数据类型';
# 3. 更改原来的字段名
alter table "数据表名" change "旧字段名" "新字段名" '数据类型';
# 3. 更改字段的数据类型
alter table "数据表名" modify "字段名" '数据类型';
# 4. 删除某一个字段
alter table "数据表名" drop "字段名";
# 根据一个表的结构创建另一个表
create table "新创建的数据表名" like "模板的数据表名";
# 根据一个表的内容创建另一个表
create table "新数据表名" (select * from "内容数据表名");
3.3 MySQL低版本设置timestamp的问题:
低版本MySQL只能设置一条CURRENT_TIMESTAMP。高版本则可设置多条。
CREATE TABLE IF NOT EXISTS userInfo(
id int PRIMARY KEY auto_increment,
name VARCHAR(20) NOT NULL,
age int DEFAULT 0,
telPhone VARCHAR(20) UNIQUE NOT NULL,
createTime TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updateTime TIMESTAMP NOT NULL,
# 设置外键
# brand_id int,
# foreign key(brand_id) references brand(id)
);
# 设置触发器
DROP TRIGGER IF EXISTS `update_example_trigger`;
DELIMITER //
CREATE TRIGGER `update_example_trigger` BEFORE UPDATE ON `userInfo`
FOR EACH ROW SET NEW.`updateTime` = NOW()
//
DELIMITER ;
4.DML
DML数据操作语言:对数据进行增加、更新、删除
4.1 插入数据
insert into "数据表名" values (null,xxx,xxxx,xxxx);
insert into "数据表名" (id, name, age, tel) values (null,xxx,xxxx,xxxx);
insert into "数据表名" (name, age, tel) values (xxx,xxxx,xxxx);
4.2 删除数据
# 删除所有数据
delete from "数据表名";
# 删除某一条数据(满足条件)
delete from "数据表名" where id = 11;
4.3 更新数据
# 修改符合条件的数据中的 name 字段属性值
update "数据表名" set name="lily", tel = '011-297948' where id = 12;
5. DQL
数据查询语言:用于查询SELECT
一、单表查询
查询的格式如下:
SELECT select_expr [, select_expr]...
[FROM table_references]
[WHERE where_condition]
[ORDER BY expr [ASC | DESC]]
[LIMIT {[offset, ] row_count \ row_count OFFSET offset
[GROUP BY expr]
[HAVING where_condition]
1. 基本查询语句:
# 查询表中所有数据
select * from "数据表名";
# 查询表单中某一些数据
select title,price from "数据表名";
# 对字段结果起别名
select title as '标题',price as '价格' from "数据表名";
2. where 条件
2.1 基本查询
# 查询 价格小于1000的所有数据
select * from "数据表名" where price < 1000;
# 查询 价格等于 2999 的所有数据
select * from "数据表名" where price = 2999;
# 查询 价格不等于 999 的所有数据
select * from "数据表名" where price != 999;
# 查询 品牌等于 华为 的所有数据
select * from "数据表名" where brand = '华为';
# 查询 价格区间1000-2000的所有数据
select * from "数据表名" where price > 1000 and price < 2000;
# between and 包含等于情况
select * from "数据表名" where price between 1099 and 2000;
# 查询 价格大于5000或品牌为华为的手机。
select * from "数据表名" where price > 5000 or brand = '华为';
# 查询某一个值为NULL
select * from "数据表名" where url is NULL;
# 不为NULL
select * from "数据表名" where url is not NULL;
2.2 模糊查询
使用like关键字,结合两个特殊的符号:
%表示匹配任意个的任意字符_表示匹配一个的任意字符
# 查询 姓名的姓氏为李的数据
select * from "数据表名" where name like '李%';
# 查询 电话号码第2,3位是87的数据
select * from "数据表名" where tel like '_87%';
2.3 IN 条件
表示取多个值中的一个值即可。
# 查询 品牌为华为或小米或苹果的手机
select * from "数据表名" where brand = '华为' or brand = '小米' or brand = '苹果';
select * from "数据表名" where brand in ('华为','小米','苹果');
3. 结果排序
对查询到的结果进行排序。
# 查询 品牌为华为或小米或苹果的手机,并按照价格降序排序、分数升序排序
select * from "数据表名" where brand in ('华为','小米','苹果')
order by price desc, score asc; # asc 升序,desc降序
4. 分页查询
根据条件以多少个数据作为一页数据结果输出。
格式:[LIMIT {[offset,] row_count | row_count OFFSET offset}]
# 查询20条数据,偏移量为0。即0-20条数据
select * from "数据表名" limit 20 offset 0;
select * from "数据表名" limit 0, 20; # 与上面结果相同
# 查询20条数据,偏移量为20。即20-40条数据
select * from "数据表名" limit 20 offset 20;
select * from "数据表名" limit 20, 20; # 与上面结果相同
5. 聚合函数
聚合函数表示对值集合进行操作的组(集合)函数。
# 查询 所有数据的价格之和
select sum(price) as '总价格' from "数据表名";
# 查询 品牌为华为的数据的价格之和
select sum(price) from "数据表名" where brand = '华为';
# 查询 品牌为华为的数据的价格平均值
select avg(price) from "数据表名" where brand = '华为';
# 查询 品牌为华为的数据的最高价格(最低价格)
select max(price) from "数据表名" where brand = '华为';
select min(price) from "数据表名" where brand = '华为';
# 查询 品牌为华为的数据的个数
select count(*) from "数据表名" where brand = '华为';
# 查询 品牌为华为的数据且URL不为空的个数
select count(url) from "数据表名" where brand = '华为';
# 查询 品牌为华为的数据且当price价格相等时算作一个的个数
select count(distinct price) from "数据表名" where brand = '华为';
6. GROUP BY的使用
group by 可以对查询的结果进行分组。
# 查询 按照品牌分组,查询品牌名、平均价格、产品个数、平均评分
select brand, avg(price), count(*), avg(score) from "数据表名" group by brand;
7. HAVING 的使用
having对分组后的数据进行筛选操作。
# 查询 按照品牌分组,查询品牌名、平均价格、产品个数、平均评分,并且平均价格大于2000的数据
select brand,avg(price) as avgPrice,count(*),avg(score) from "数据表名" group by brand having avgPrice > 2000;
# 查询 评分大于7.5的手机的平均价格
select avg(price) from "数据表名" where score > 7.5;
# 查询 评分大于7.5的手机按照手机品牌分组,求各个品牌的平均价格
select brand,avg(price) from "数据表名" where score > 7.5 group by brand;
二、多表查询
1. 外键
外键:依赖另一个表的主键,取值必须是另一个表主键有的值。
1.1 设置外键
1.1.1 创建表时,添加外键约束:
CREATE TABLE IF NOT EXISTS userInfo(
id int PRIMARY KEY auto_increment,
name VARCHAR(20) NOT NULL,
brand_id int,
foreign key(brand_id) references brand(id)
);
1.1.2 表已经创建好了,额外添加外键:
# 设置某一个字段为 外键
alter table "数据表名1" add "字段名1" "数据类型";
alter table "数据表名1" add foreign key("字段名1") references "数据表名2"("数据表名2的主键");
# 例:将字段brand_id设为外键,关联表brand中的主键id
alter table product add brand_id int;
alter table product add foreign key(brand_id) references brand(id);
1.2 修改和删除外键引用
-
当外键有删除和更新操作时会触发action动作,默认为
restrict。即当更新或删除某个记录时,会检查该记录是否有关联的外键记录,有的话会报错的,不允许更新或删除; -
设置为
cascade时,当更新或删除某个记录时,会检查该记录是否有关联的外键记录,有的话,会更新对应的记录、或删除对应的关联记录。
# 1. 获取当前表中外键的名称
show create table "数据表名";
# 2. 删除外键
alter table "数据表名" drop foreign key '外键名称';
# 3. 重新设置外键约束action
alter table "数据表名" add foreign key("字段名") references "数据表名2"("数据表名2的主键")
on update cascade # 更新时,引用自动修改
on delete restrict;# 卸载时,采用默认严格
2. 多表查询
2.1 默认多表查询
会生成笛卡尔积数据,即X * Y
# 查询的结果条数为:表1所有数据条数 * 表2所有数据条数
select * from "表1", "表2";
# 筛选笛卡尔积后的数据
select * from "表1", "表2" where "表1".b_id = "表2".id;
2.2 多表连接查询
使用SQL JOIN操作。
前提:
现有表
products,和表brand。products表(手机商品表)中字段为:id、name(手机名)、price、score、brand_id。brand_id为外键关联brand表中的主键id。
brand表(手机品牌表)中字段为:id、name(品牌名)、website。
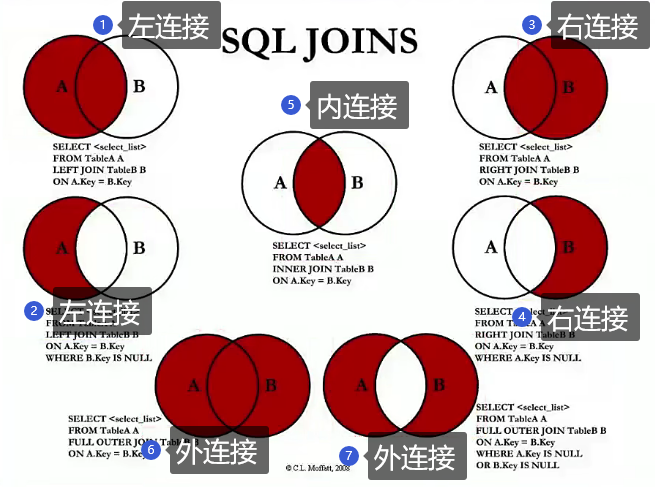
2.2.1 左连接
# ①查询所有的手机以及对应的品牌名称(包括brand_id为NULL的手机数据)
select * from products left join brand on products.brand_id = brand.id;
# ②查询没有对应品牌的手机数据
select * from products left join brand on products.brand_id = brand.id where brand.id is null;
2.2.2 右连接
# ③查询所有的手机品牌与之关联的手机商品数据(没有对应的手机数据,品牌信息也显示)
select * from products right join brand on products.brand_id = brand.id;
# ④查询没有对应手机的品牌信息
select * from products right join brand on products.brand_id = brand.id where products.brand_id is null;
2.2.3 内连接
# ⑤只查询 双方有关系的数据
select * from products join brand on products.brand_id = brand.id;
2.2.4 全连接
# ⑥查询手机商品数据和品牌数据的并集
(select * from products left join brand on products.brand_id = brand.id;)
union
(select * from products right join brand on products.brand_id = brand.id;)
# ⑦查询双方独有的数据
(select * from products left join brand on products.brand_id = brand.id where brand.id is null;)
union
(select * from products right join brand on products.brand_id = brand.id where products.brand_id is null;)
2.3 多对多查询
2.3.1 多对多关系
如:学生可以选择多门课程,一个课程可以被多个学生选择。
现有表:
学生表students(id、name(学生名)、age),课程表courses(id、name(课程名)、price)。
多对多关系,所以新增一个存储两表关系的关系表sc选课表(id、sid(学生id,外键)、cid(课程id,外键))。
2.3.2 多表查询
# 查询已选课的学生的选课情况(内连接)
select students.id,students.name,students.age,cources.id,cources.name,cources.price
from students
join sc on students.id = sc.sid
join cources on sc.cid = cources.id;
# 查询学生的选课情况(无论学生有没有选课)(左连接)
select students.id,students.name,students.age,cources.id,cources.name,cources.price
from students
left join sc on students.id = sc.sid
left join cources on sc.cid = cources.id;
# 查询哪些学生没选课
select students.id,students.name,students.age
from students
left join sc on students.id = sc.sid
left join cources on sc.cid = cources.id
where cources.id is null;
# 查询哪些课程是没被选择的
select students.id,students.name,students.age,cources.id,cources.name,cources.price
from students
right join sc on students.id = sc.sid
right join cources on sc.cid = cources.id
where students.id is null;
-- select cources.id,cources.name,cources.price
-- from cources
-- left join sc on cources.id = sc.sid
-- left join students on sc.id = students.id
-- where students.id is null;
# 查询 姓名为fct的学生选了哪些课程
select students.id,students.name,students.age,cources.id,cources.name,cources.price
from students
left join sc on students.id = sc.id
left join cources on sc.id = cources.id
where students.name = 'fct';
3. 查询结果转化
3.1 一对多情况
将联合查询到的数据转成对象:
SELECT userinfo.id, userinfo.`name`, userinfo.telPhone, JSON_OBJECT('id',class.id,"name",class.name) as brand
from userinfo
LEFT JOIN class ON userinfo.class_id = class.id;
3.2 多对多情况
将查询到的多条数据,组织成对象,放入到一个数组中。
select students.id, students.name, students.age, json_arrayagg(json_object("id",cources.id,"cname",cources.name,"price",cources.price)) as scInfo
from students
join sc on students.id = sc.sid
join cources on sc.cid = cources.id
group by students.id;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号