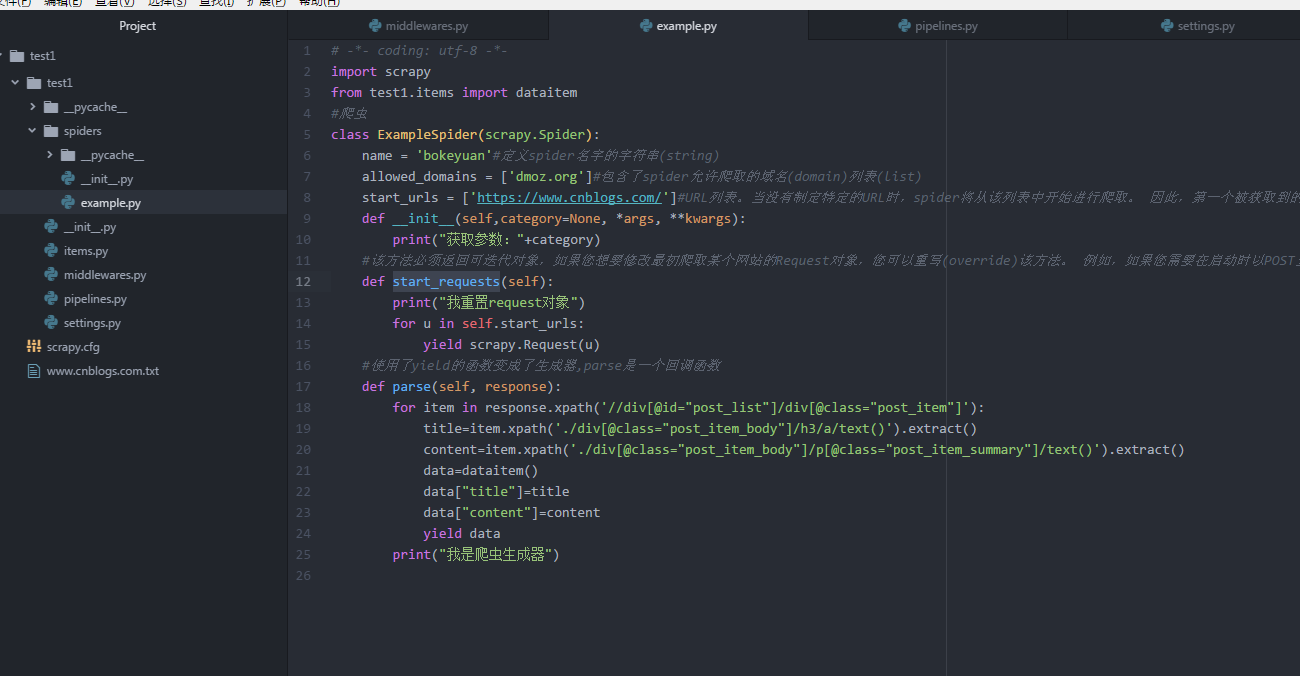
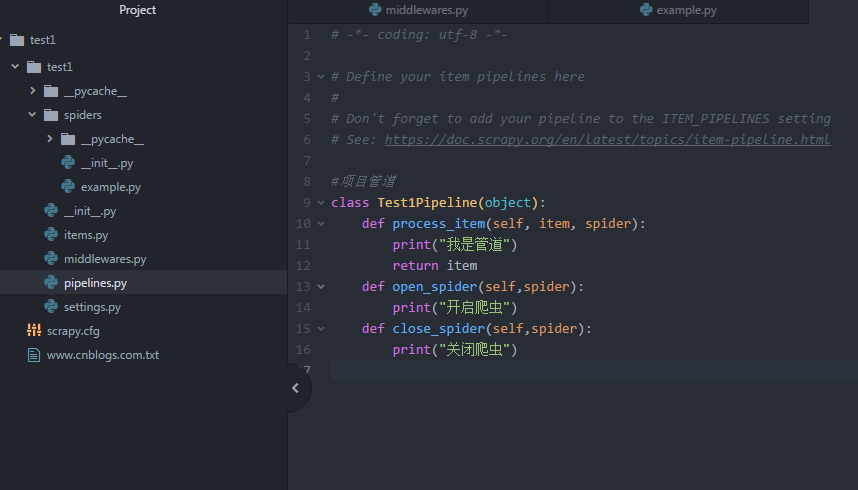
爬虫框架Scrapy使用
1:熟悉框架内容
http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
2:Windows下安装pypiwin32
使用pip install pypiwin32 下载环境插件,网页中下载插件并安装后运行程序是还是报错提示ImportError: DLL load failed: 找不到指定的模块。 还未找到原因。
3:创建项目
scrapy startproject test
4:运行程序
scrapy crawl test
5:Selector
xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表 ,例如xpath('.//div[@id="post_list"]/div[@class="post_item"][1]/div[@class="post_item_body"]/h3/a/text()').extract()。css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表.extract(): 序列化该节点为unicode字符串并返回list。re(): 根据传入的正则表达式对数据进行提取,返回unicode字符串list列表。
6:scrapy 框架
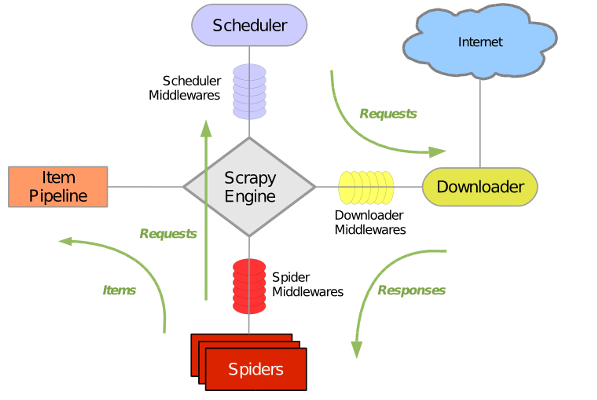
7:生成项目结构
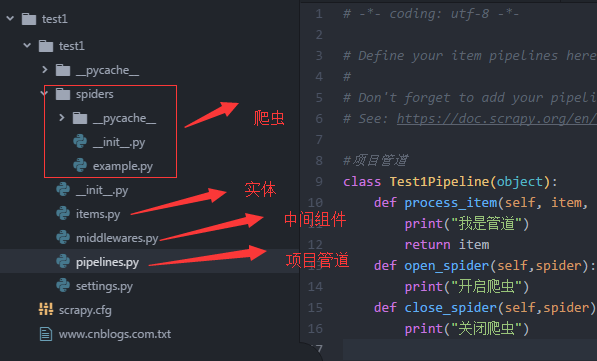
8:文件介绍