
Redis 主从复制架构中出现宕机怎么办?以及哨兵功能
如果主从复制架构中出现宕机的情况,需要分情况看:
1. 从Redis宕机
相对而言比较简单,Redis从库重新启动后会自动加入到主从架构中,自动完成同步数据;
存在的问题是,如果从库在断开期间,主库变化不大,从库再启动后,主库依然会将所有的数据做RDB操作吗?还是增量更新?(从库在有做持久化的前提下)
不会的,因为在Redis2.8版本后酒实现了,主从断线后恢复的情况下实现增量复制。
2. 主Redis宕机
相对而言复杂一些,需要以下两个步骤才能完成
第一步:在从数据库中执行SLAVE ON ONE 命令,断开主从关系并且提升为主库继续服务。
第二步:将主库重新启动后,执行SLAVEOF 命令,将其设置为其他库的从库,这是数据就能更新回来。
从上看出,主Redis宕机恢复较麻烦,并且容易出错,有没有更好的解决办法呢?当然有,Redis的哨兵(sentinel)功能
哨兵(Sentinel)
什么是哨兵
顾名思义,哨兵的作用就是对Redis的系统的运行情况进行监控,他是一个独立的进程。他的功能有两个:
1. 监控主库和从库是否运行正常
2. 主库出现故障后自动将从库转化为主库
原理:
单个哨兵的架构:

多个哨兵的架构
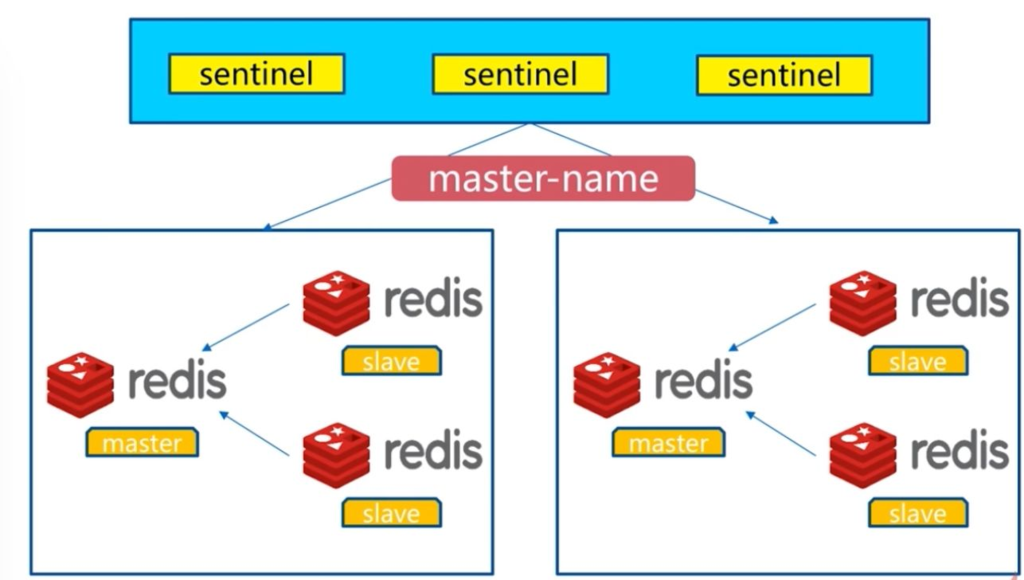
多个哨兵,不仅同时监控主从数据库,而且哨兵之间互为监控。
环境处于一主多从的环境中
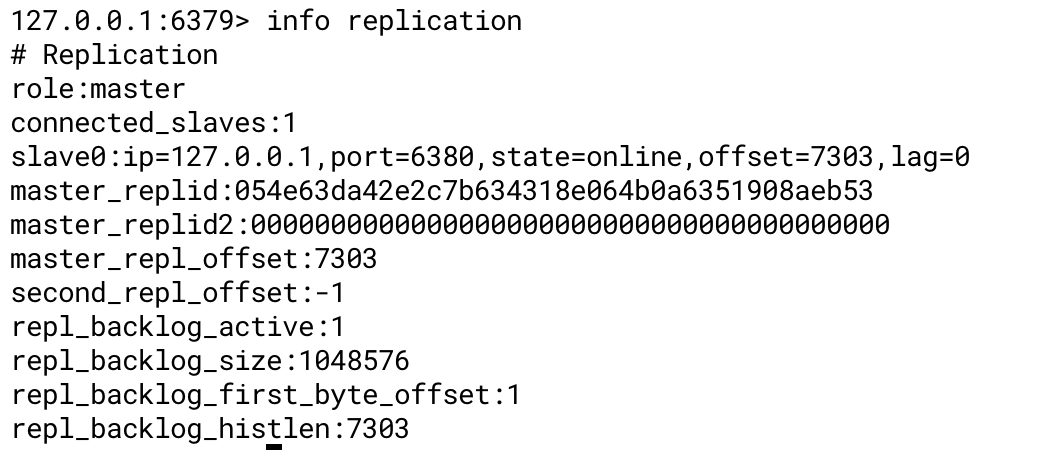
配置哨兵
启动哨兵进程首选需要创建哨兵配置文件;
vi sentinel.conf
写入配置:
sentinel monitor RedisMaster 127.0.0.1 6379 1
说明:
MyMonitorMaster:监控主数据库的名称 ,自定义即可,可以使用大小姐字母和“.-_”符号
127.0.0.1:监控的主数据库的IP
6379:监控主数据库的端口
1:最低通过票数
启动哨兵:
redis-sentinel ../sentinel.conf
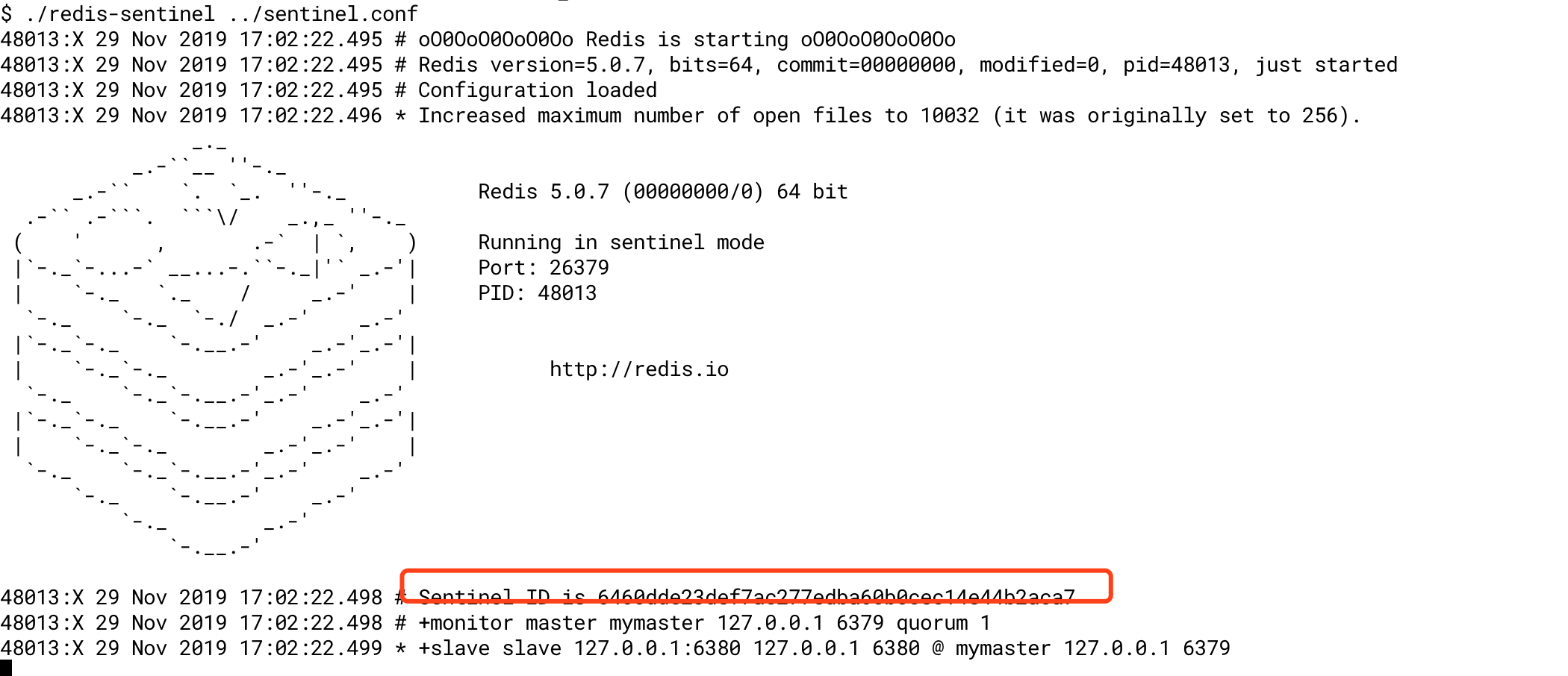
上图信息:
1. 哨兵已经启动,id为6460dde23def7ac277edba60b0cec14e44b2aca7
2.为master添加一个监控
3.发现了一个slave,哨兵无需配置slave,只需要指定master,哨兵会自动发现slave
从库宕机模拟:
kill -9 掉从库的redis进程30秒后,哨兵控制台输出:
48013:X 29 Nov 2019 17:41:23.390 # +sdown slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
说明已经监控到slave宕机了,那么,我们将6380实例重新启动后,会自动加入主从复制么?
./redis-server ../redis.conf 48013:X 29 Nov 2019 17:44:30.178 * +reboot slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 48013:X 29 Nov 2019 17:44:30.257 # -sdown slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
可以看出,slave从新加入主从复制中,-sdown:说明服务恢复。
主库宕机模拟:
停止主Redis的进程:哨兵输出如下:

48013:X 29 Nov 2019 17:46:55.897 # +sdown master mymaster 127.0.0.1 6379 说明6379 master服务已经宕机 48013:X 29 Nov 2019 17:46:55.897 # +odown master mymaster 127.0.0.1 6379 #quorum 1/1 48013:X 29 Nov 2019 17:46:55.897 # +new-epoch 1 48013:X 29 Nov 2019 17:46:55.897 # +try-failover master mymaster 127.0.0.1 6379 开始恢复故障 48013:X 29 Nov 2019 17:46:55.900 # +vote-for-leader 6460dde23def7ac277edba60b0cec14e44b2aca7 1 投票选举哨兵leader,现在就一个哨兵所以leader就是自己 48013:X 29 Nov 2019 17:46:55.900 # +elected-leader master mymaster 127.0.0.1 6379 选中leader 48013:X 29 Nov 2019 17:46:55.900 # +failover-state-select-slave master mymaster 127.0.0.1 6379 选中其中的一个slave当作master 48013:X 29 Nov 2019 17:46:55.973 # +selected-slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 选中6380 48013:X 29 Nov 2019 17:46:55.973 * +failover-state-send-slaveof-noone slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 发送slaveof no one命令 48013:X 29 Nov 2019 17:46:56.056 * +failover-state-wait-promotion slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 等待升级master 48013:X 29 Nov 2019 17:46:56.509 # +promoted-slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 升级6380为master 48013:X 29 Nov 2019 17:46:56.509 # +failover-state-reconf-slaves master mymaster 127.0.0.1 6379 48013:X 29 Nov 2019 17:46:56.611 # +failover-end master mymaster 127.0.0.1 6379 故障恢复完成 48013:X 29 Nov 2019 17:46:56.611 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6380 主数据库从6379转变为6380 48013:X 29 Nov 2019 17:46:56.611 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6380 添加6379为6380的从库 48013:X 29 Nov 2019 17:47:13.013 * +convert-to-slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6380
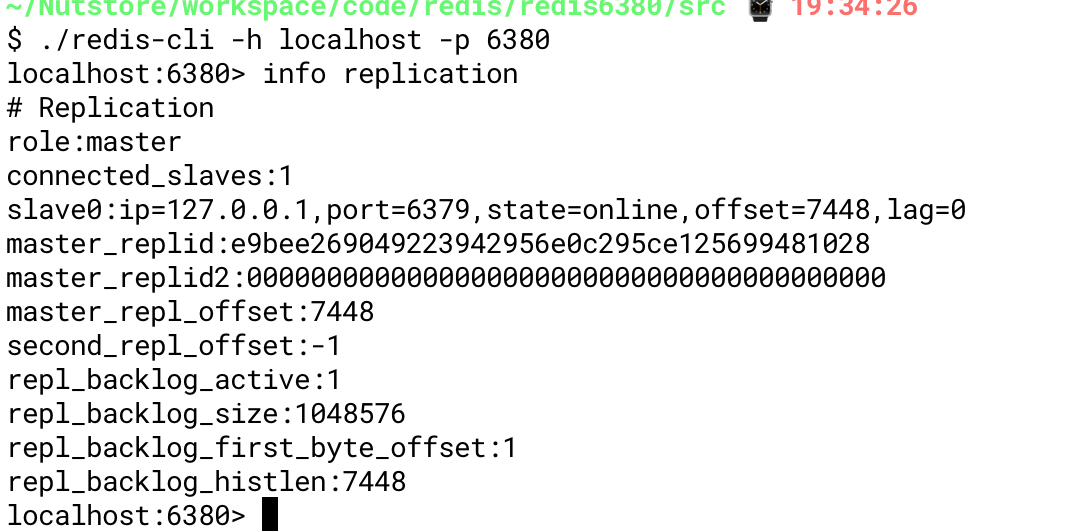
可以看出,目前,6380为master,拥有一个slave为6379
配置多个哨兵
vi sentinel.conf
输入内容:
sentinel monitor taotaoMaster 127.0.0.1 6381 2
sentinel monitor taotaoMaster2 127.0.0.1 6381 1

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步