软工实践寒假作业(2/2)
作业基本信息
| 这个作业属于哪个课程 | <2021春软件工程实践S班> |
|---|---|
| 这个作业要求在哪里 | <软工实践寒假作业(2/2)> |
| 这个作业的目标 | <提问、词频统计> |
| 其他参考文献 | ... |
目录:
Github:https://github.com/fujiangfer/PersonalProject-C
1. 阅读《构建之法》并提问
一、在3.1中提到了关于团队对个人的期望
大多数工程师都在团队的环境中工作,怎么样才是一个合格,甚至优秀的队员呢?前面提到了PSP ( Personal Software Process ),和它对应的有团队的软件流程TSP ( Team SoftwareProcess ),TSP对团队成员也有要求:
1.交流:能有效地和其他队员交流,从大的技术方向,到看似微小的问题。
2.说到做到:就像上面说的“按时交付”。
3.接受团队赋予的角色并按角色要求工作:团队要完成任务,有很多事情要做,是否能接受不同的任务并高质量完成?
4.全力投入团队的活动:就像一些评审会议,代码复审,都要全力以赴地参加,而不是游离于团队之外。
5.按照团队流程的要求工作:团队有自己的流程(见“团队和流程”一章),个人的能力即使很强,也要按照团队制定的流程工作,而不要认为自己不受流程约束。
6.准备:在开会讨论之前,开始一个新功能之前,一个新项目之前,都要做好准备工作。
7.理性地工作:软件开发有很多个人的、感情驱动的因素,但是一个成熟的团队
成员必须从事实和数据出发,按照流程,理性地工作。很多人认为自己需要灵感和激情,才能为宏大的目标奋斗,才能成为专业人士。著名的艺术家Chuck Close 说:我总觉得灵感是属于业余爱好者的。我们职业人士只是每天持续工作。今天你继续昨天的工作,明天你继续今天的工作,最终你会有所成就。
那个人应该对团队有期望吗?还是说应该如何选择适合自己的团队?
总的来说有以下几个:
选择一个好的上级,好的要求,团队才能带领你把项目做好,所以选择领头人很重要.
多看几家团队,纵向横向都比较下,自己选择一个好的,团队真的很重要.
1.团队的价值观是否认同
2.领导的能力
3.领导的处事作风是否认同
4.整个团队的风气是不是积极向上,要是死气沉沉的就不用考虑了
5.队员之间的相处
6.加入己有没有发展、提升起码要有所进步
7.公司对团队的态度
看了网上的些回答,我就感觉,好像领导者,领头人或者说团队的管理者非常重要,甚至是起决定性作用,我认为除了对领导者个人的要求外的几点,像是团队价值观、
团队风气、这些似乎也和领导者有很大关系。就好像我们不是在选团队,而是在选领导,或者说选团队本质就是选领导?
二、关于书中4.3.2提到goto
函数最好有单一的出口,为了达到这一目的,可以使用goto。只要有助于程序逻辑的清晰体现,什么方法都可以使用,包括goto
实际应用中,goto究竟适不适用?团队会不会对这方面有所要求?
goto似乎一直以来争议很大,像我们以前学C的时候老师就要我们尽量别用,有人认为只要清晰可读都能用,觉得非常的方便。
严格来说goto不是不能用,不过一般用于出错处理部分,如果你代码用goto能非常简洁且不会有任何问题的确可以用
我发现goto在很多场合都很有用,比如跳出多重循环等.
极端反对的人,像这个:
忘记goto吧。。。那是面向过程的东西。。现代编程,基本全是面向对象的。goto会使一个严谨的程序,变成一坨翔。除非你想做的是个BUG或病毒。
否则你的工作中,可能一辈子也不会用到goto
似乎更多的认为应该慎用
goto这个无条件的转移目标,以前是很多争议的,就算是现今也是争议很多.很多大神说不能用是因为(不是完全不能用是尽量不要用),
你没事跳来跳去你会搞的整个程序只有你自己看的懂,(你跳二十次之后你自己也看不懂).基本上不推广goto这无条件转移(但是是可以用的).
if & goto这两个可以一起用但尽量是少用(等你调试就知道有多无言)
goto可以用,为什么不可以用呢。只是能不用的时候就不要用,能用其他办法解决跳转的就不用goto,goto只是在迫不得已的是否才用,并且不能多用。
goto是慎用而不是不能用
我的想法也是尽量不用,但是以前图方便也会用,像书上给的例子,也可以用一个符号位解决,而避免用goto。就是不知道工作中对这个有没有强制要求之类东西。
三、书中6.3关于敏捷的团队
敏捷对团队的要求很简单:自主管理( Self-managing )、自我组织(Self-organizing )、多功能型(Cross-functional ),但是这很难做到。
软件项目的团队各式各样(请看“团队和流程”一章),假设一个团队做得还不错,现在要变成敏捷流程,那团队要做下面的改变:1.自主管理:以前领导布置了任务,我们实现就可以了,现在要自己挑选任务;每次
Sprint结束之后,还要总结不足,提出改进,并且自己要实施这些改进。“自主管理”不等于“没有管理”。
2.自我组织:以前做好自己的事情就好了,安心下班。现在每个人要联合起来对项目负责,有人工作落后了还要帮助他改进,项目缺少某类资源还要自己顶上去。
3.多功能型:以前规格说明书由PM来写,测试由测试人员来做,现在每个人都全面负责,自己搞定规格说明书,和别人沟通,同时自己搞定测试。
这里提到了每个人要联合起来对项目负责,落后还要帮忙改进。但是书中也提到过我们在团队中要各司其职,如7.2.4。这冲突吗?
我觉得这应该是不冲突的,因为就是是各司其职也同样对项目共同负责,在敏捷的团队中也有任务的分配。但如果项目出问题了,普通
情况下肯定是由负责这部分任务的人负责,但在敏捷的团队中,也一样吗?不是说每个人都全面负责,有人工作落后了还要帮助他改进吗。
我感觉我有点混乱。
四、在12.1.3中提到的了
长期使用之后,软件会更好用么?
在设计软件界面时,我们的设计师经常会画新功能的UI设计图,来征求大家的意见。我注意到大部分设计都假设用户是头一次使用产品,
所以没有任何积累的文件、照片、处理过的图像、曾经做过的选择等数据。我同意第一印象很重要,但是当用户已经是第N次使用你的产品时,你的UI能否为这些用户提供方便呢?你的产品是下面的哪一种:a.软件用得越多,一样难用
b.软件用得越多,越发难用
c.软件用得越多,越来越好用
软件是否好用和硬件也是相关的,但硬件发展很快(摩尔定律),所以软件开发的时候也要考虑硬件。
这abc三种情况是可能同时出现的,那么开发者如何把握软件功能的提升和对硬件的要求提升的平衡?
同一款软件不断更新,可能有人会觉得越来越好用,因为他的硬件性能强大,有人觉得越发难用,因为他可能用的是好几年前的机器。
拿手机来说,app的大小增长简直太可怕,几年前还是十几M或者几十M,现在动辄几G,有些应用因太大被用户暂时抛弃。
我觉得软件提升前要考虑当前设备的持有分布,把握好用户群体分布,利益最大化;
极端假设:社会上所有人都很有钱,设备一直保持最新款,那软件的提升就只需要考虑软件本身的功能性能了,完全不用考虑用户的硬件是否支持,因为用户的硬件一直是最好的。
五、书中16.3.0提到的改良式创新(Incremental Innovation)和颠覆式创新(Disruptive Innovation)
提到了个故事:
雅卡尔( Joseph Marie Jacquard ) 1752年出生于里昂,一成年便在丝绸工坊打工,并且很快成为一个有创意的、技艺娴熟的工匠。
他的改革计划在法国大革命期间多次中断,但1805年一大批改革后改进后的半自动织机最终在法国运转了起来。
新织机不但缩短了产品的成型时间,更重要的是减轻了劳动量,减少了工作人数。这必然引起大批工人的恐慌和随之而来的抵制及破坏,
因为使用雅卡尔织布机后,原来需要六名工人完成的工作现在只需一名,这就意味着大批工人的失业。雅卡尔多次受到人身攻击,甚至有人对他以死相逼,
更严重的是,工坊里的新型织机不断被损坏和焚烧。尽管如此,革新的成果还是迅速遍及全国。1812年,整个法国已装置了一万一干多台雅卡尔自动织布机。
颠覆式创新的影响这么大,会不会对这种创新起到致命影响?比如因人身攻击之类被迫停止。有没有办法减小影响的同时改变社会?
查阅资料:
一旦颠覆性创新出现(它是市场上现有产品更为便宜、更为方便的替代品,它直接锁定低端消费者或者产生全然一新的消费群体),现有企业便立马瘫痪。
为此,他们采取的应对措施往往是转向高端市场,而不是积极防御这些新技术、固守低端市场,然而,颠覆性创新不断发展进步,
一步步蚕食传统企业的市场份额,最终取代传统产品的统治地位。
我也认为蚕食是个好办法,可以有效的减少冲突,但是需要付出时间代价;但是要是能更快的带来变革,也一定有积极的影响吧。至于会不会对创新起到致命影响,
如果那么容易被击败,也就不能称得上颠覆式创新了吧,我认为影响最多就是蛰伏一些时间,当然时间也可能很长。
小知识
打开搜索引擎,搜索“软件开发教父”,你会搜到一个叫Martin Fowler的人。
2001年2月,Martin Fowler,Jim Highsmith等17位著名的软件开发专家齐聚在美国犹他州雪鸟滑雪圣地,
举行了一次敏捷方法发起者和实践者的聚会。在这次会议上面,他们正式提出了Agile(敏捷开发)这个概念,并共同签署了《敏捷宣言》。
没错就是他。他被公认为全球知名的面向对象分析设计、UML、模式等方面的专家,现在还担任ThoughtWorks公司的首席科学家。
但是仔细一看,你会发现,他的职业写的居然是演说家。百度百科介绍:马丁·福勒是一个软件开发方面的著作者和国际知名演说家,专注于面向对象分析与设计,
统一建模语言,领域建模,以及敏捷软件开发方法,包括极限编程。
这有一篇他采访“我是一个幸运的家伙”。真的不愧是演说家。
里面提到对程序员的建议
对全世界的程序员我都是那么几条建议。
第一,每年学习并熟悉一个新的编程语言。坚持几年,你对于程序设计会有非常深刻的见解。
第二,学习测试驱动开发,这种新的方法会改变你对于软件开发的看法。
第三,劳逸结合,不要总是绷得紧紧的,爬爬山,跳跳舞,经常放松神经,你会发现你更有活力和创造力。我的一些最好的想法就是在山顶上萌发的。
2. 完成词频统计个人作业
题目要求:
假设有一个软件每隔一小段时间会记录一次用户的搜索记录,记录为英文。
输入文件和输出文件以命令行参数传入。例如我们在命令行窗口(cmd)中输入:
//C语言类
WordCount.exe input.txt output.txt
//Java语言
java WordCount input.txt output.txt
则会统计input.txt中的以下几个指标
统计文件的字符数(对应输出第一行):
只需要统计Ascii码,汉字不需考虑
空格,水平制表符,换行符,均算字符
统计文件的单词总数(对应输出第二行),单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
英文字母: A-Z,a-z
字母数字符号:A-Z, a-z,0-9
分割符:空格,非字母数字符号
例:file123是一个单词, 123file不是一个单词。file,File和FILE是同一个单词
统计文件的有效行数(对应输出第三行):任何包含非空白字符的行,都需要统计。
统计文件中各单词的出现次数(对应输出接下来10行),最终只输出频率最高的10个。
频率相同的单词,优先输出字典序靠前的单词。
例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
输出的单词统一为小写格式
然后将统计结果输出到output.txt,输出的格式如下;其中word1和word2 对应具体的单词,number为统计出的个数;换行使用'\n',编码统一使用UTF-8。
characters: number
words: number
lines: number
word1: number
word2: number
...
目录:
1. PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 10 | 20 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 180 | 360 |
| • Design Spec | • 生成设计文档 | 30 | 20 |
| • Design Review | • 设计复审 | 20 | 10 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 10 |
| • Design | • 具体设计 | 60 | 100 |
| • Coding | • 具体编码 | 360 | 800 |
| • Code Review | • 代码复审 | 120 | 180 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120 | 360 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 180 | 200 |
| • Size Measurement | • 计算工作量 | 30 | 20 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1160 | 2110 |
2. 解题思路描述
具体的函数
- 将文件路径作为字符串参数传递
- 字符计算函数将读入每一个字符并统计数量,返回值为字符数。
- 行数计算函数将读入每一个字符以'\r''\n'为界分隔行,并且检测空行忽略,返回值为行数。
- 单词计算也是读入每一个字符,检测是否符合单词规则,并且存下,返回值为单词总数。
- 保存单词函数会将单词存下,无返回值。
- 单词排序函数会将存下的单词按规则排序并返回结构数组。
3. 代码风格
https://github.com/fujiangfer/PersonalProject-C/blob/main/221801131/example/codestyle.md
4. 计算模块接口的设计与实现过程
(1)字符计算
char code;
int num = 0;
infile >> noskipws;//强制读入空格和换行符
while (!infile.eof())
{
infile >> code;
if (infile.eof())
break; //防止最后一个字符输出两次
num++;
}
这里其实也进行了多次更改,一开始觉得没什么问题,结果老出这样那样的问题。'\r'读不出来也折腾了好久,原来用二进制读就能读到了。算法其实没什么好说的,
就是一个个读罢了。
(2)行数计算
char code;
bool flag = false;
int num = 0;
infile >> noskipws;
while (!infile.eof()) {
while(infile >> code) {
if (code >= 0 && code <= 127) {
if (!isspace(code))
flag = true; //标志是否空行
}
if (code == '\n') //读完一行,跳出循环
break;
}
if (flag){
num++;
flag = false;
}
}
- 一个个字符读入,强制读入空白
- 同时记下是否有非空的合法字符
- 但遇到'\n'时进行判断,不为空行则行数加一,标志位重置。
- 返回行数
采用一个个字符读取的方法,读到'\n'时算一行,同时设置一个标志位来算空行,只有那一行有非空ASCII字符才会计数一行。
--------原来'\r'不做换行(其实原来就没考虑)。没有注意要求文档,谢谢助教提醒。
(3)单词计算&保存&排序
char word;
char* str = new char[100]; //记录单词
bool flag = false;
bool isWords = false;
int charCount = 0;//记录字母数
int num = 0;
word = infile.get();
while (true) {
if (word >= 'A' && word <= 'Z')word += 32;
if (flag)
{
if (!((word >= 'a' && word <= 'z') || (word >= '0' && word <= '9'))) { //确认一个单词后寻找下一个间隔符
if (isWords) {
str[charCount] = NULL;
safeWord(str);
}
memset(str, NULL, sizeof(str));
flag = false;
isWords = false;
charCount = 0;
}
else if (isWords) {
str[charCount++] = word;
}
}
else {
if (word >= 'a' && word <= 'z') { //判断是否是字母
str[charCount++] = word;
if (charCount == 4) { //4个英文字母开头时计一个单词数并寻找下一个间隔符
num++;
flag = true;
isWords = true;
}
}
else { //没有4个英文字母开头则寻找下一个间隔符
flag = true;
continue;
}
}
if ((word = infile.get()) == EOF)break;
}
if (isWords) { //若最后一个为单词则保存
str[charCount] = NULL;
safeWord(str);
}
- 逐个读取字符,若为大写则换为小写。
- 连续4个字母,记下为单词,单词数加1。
- 若为单词则继续保存字符,直到下一个分隔符。
- 遇到分隔符,检测当前存储是否为单词,若是则存下。
- 因为最后一个单词可能碰不到分隔符,就额外判断一次。
简单粗暴,还是一个个读取字符,碰到连续四个字母开头,分隔符间隔的单词存入map中,保存函数如下:
void WordCount::safeWord(char* str) {
string word;
word = str;
map<string, int>::iterator iter = words.find(word);//找单词
if (iter == words.end()) {
words.insert(pair<string, int>(word, 1));//没找到单词,插入单词并设定次数为1
wordnum2++; //单词个数+1
}
else {
iter->second++;//找到单词,单词出现次数增加
}
}
然后就是排序了,借用vector把map中的单词排序,然后存入结构数组中。
typedef pair<string, int> PAIR;
struct CmpByValue {
bool operator()(const PAIR& lhs, const PAIR& rhs) {
if (lhs.second == rhs.second) {//词频相同时
if (lhs.first.compare(rhs.first) > 0)return false;
else return true;
}
else return lhs.second > rhs.second;
}
};
void WordCount::wordsort() {
Words temp;
map<string, int>::iterator iter;
iter = words.begin();
vector
sort(vwords.begin(), vwords.end(), CmpByValue());
for (int i = 0; i != vwords.size(); ++i) {
wwords[i].word = vwords[i].first;
wwords[i].count = vwords[i].second;
}
}
类和结构体的声明
struct Words { //用于存放单词及次数
string word;
int count;
};
class WordCount {
private:
int characternum;
int wordnum1; //单词总数
int wordnum2; //单词个数
int linenum;
map<string, int> words;//用于存放单词及次数
Words* wwords;
public:
WordCount();
WordCount(char* Path);
int getcharacternum();
int getlinenum();
int getwordnum1();
int getwordnum2();
Words* getwords();
int charactersCount(char* Path);
int wordCount(char* Path);
int lineCount(char* Path);
void safeWord(char* str);
void wordsort();
};
5. 计算模块接口部分的性能改进
一开始单词频数的排序我用了简单的冒泡
for (int i = 0; i < count; i++) { //冒泡排序
for (int j = 0; j < count - i - 1; j++) {
if (wwords[j].count < wwords[j + 1].count) {
temp = wwords[j];
wwords[j] = wwords[j + 1];
wwords[j + 1] = temp;
}
else if (wwords[j].count == wwords[j + 1].count) {
if (!wwords[j].word.compare(wwords[j + 1].word)) { //频率相同的单词,优先输出字典序靠前的单词。
temp = wwords[j];
wwords[j] = wwords[j + 1];
wwords[j + 1] = temp;
}
}
}
}
然后跑了个大的文件,跑了1分多钟,完全不行啊,然后就去查找资料,学习map怎么排序,结果在前面,就不再放一遍了。
总之就是速度提高了很多。
性能分析
同一个文本的检测,文本不大,因为性能分析跑的太慢,还占空间,本来跑了大文本,报告几十g,c盘都给它搞完
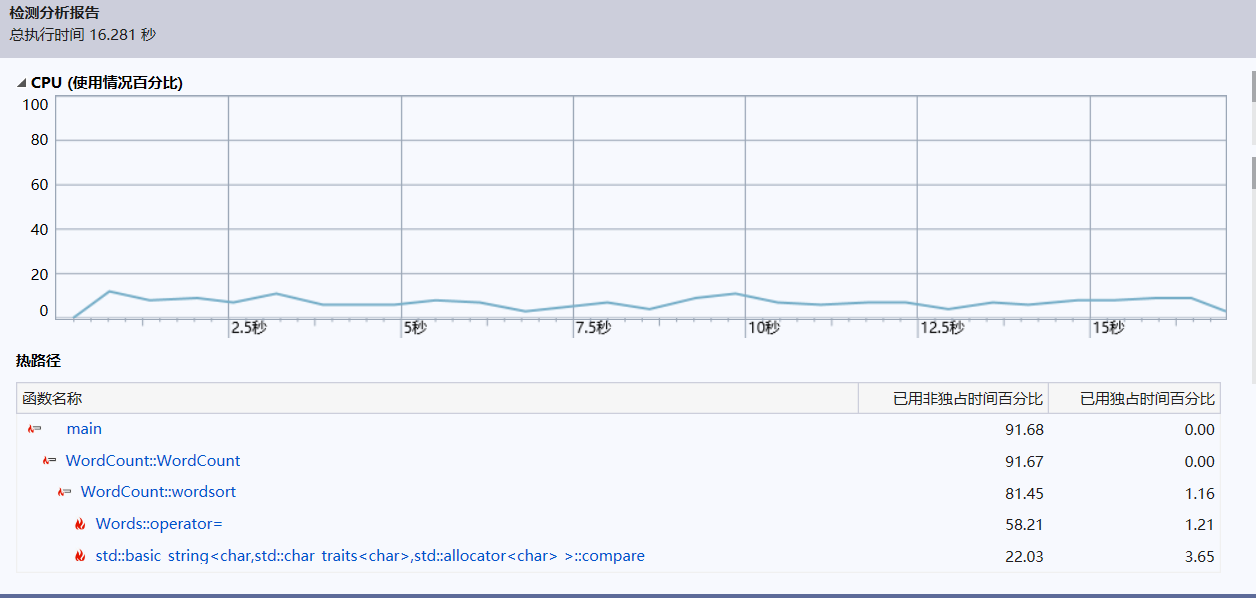
所以跑了这个不打的文本测试
改进前
改进后
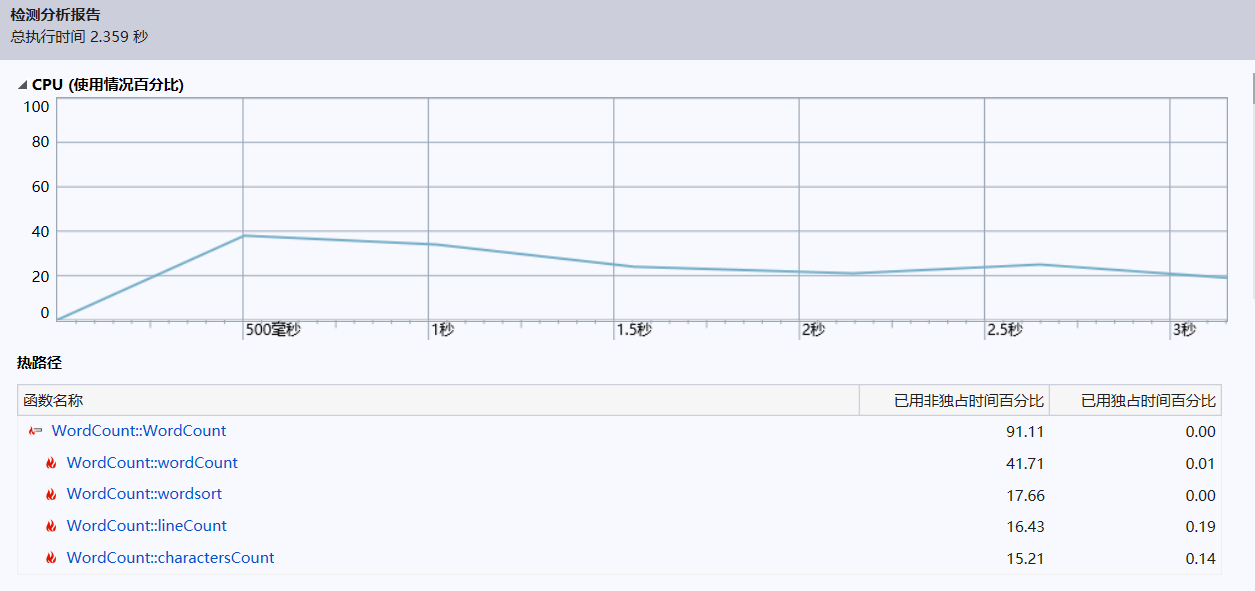
明显看出来时间的减少,和排序函数时间占比的下降
此外就是找单词的函数,可以用正则表达式完成,可以节省许多代码,但我也有点乱,记不住,这就不写了。
6. 计算模块部分单元测试展示
选了一些数据进行单元测试包括大文本、含有'\r'文本、空文本等等。因为题目要求说不考虑中文等,就没做中文相关单元测试,但是写代码的时候考虑了中文之类的,大都正常通过了。
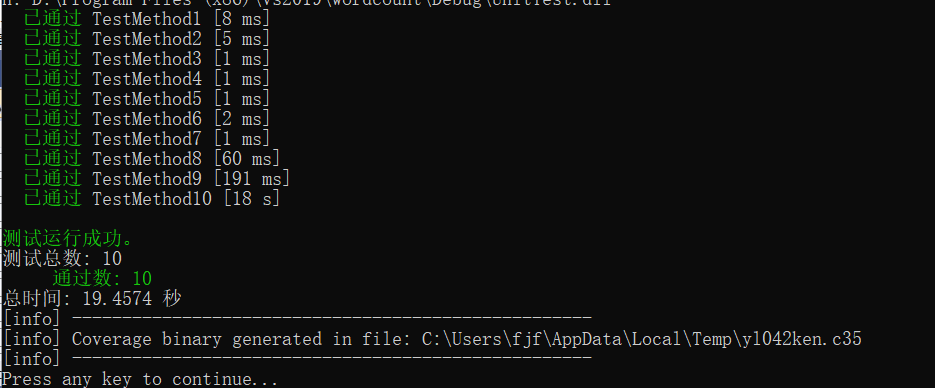
覆盖率如下:

7. 计算模块部分异常处理说明
做了文件打开失败的提醒
if (!infile) {
cout << "文件打开失败!" << endl;
}
或者
if (!input) {
cout << "未输入文件名或文件不存在" << endl;
return 0;
}
8. 心路历程与收获
其实就是比预想的难熬了些。本以为不是太难,然后同学发来一个大文本,炸了。修修补补,与同学一比,擦,结果不一样,还不知道谁错。
只得把词频全印出来,没毛病,他出问题了(>-<)。深夜12点,另一位同学发来贺电,给我带来了\r的福报,好家伙,行数统计和字符统计
都炸了...淦,好吧找资料,修修补补,搞完睡觉。
然后就是单元测试性能分析这些,真的是没啥头绪,就只能一遍查资料一边慢慢搞定了。还有代码风格这事,
感觉编译器会对我有挺大的影响...像vs会自动往运算符两边加空格,但是修改的时候不会补上空格,有时候我也会忘记。还有就是{我其实不习惯重开一行,但是编译器生成,
或者规范是会单独一行。
-------------------------------------------
个性签名:没有
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
万水千山总是情,打赏一分行不行(っ•̀ω•́)っ✎⁾⁾!



 浙公网安备 33010602011771号
浙公网安备 33010602011771号