Hadoop 综合大作业
1.将爬虫大作业产生的csv文件上传到HDFS
此处选取的是rank.csv文件
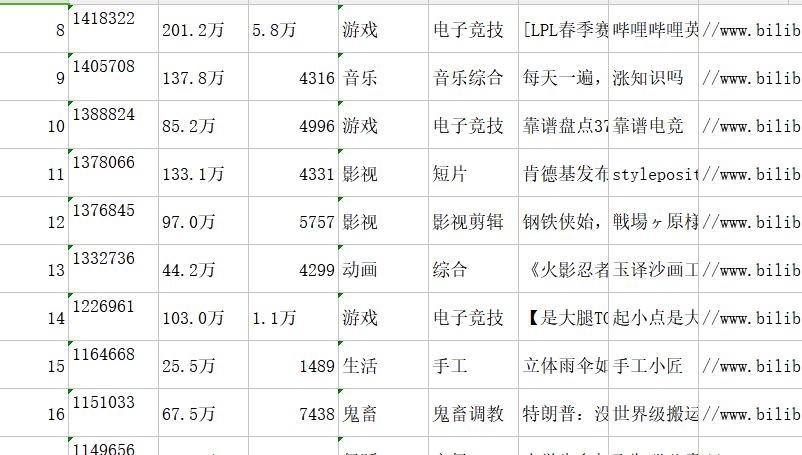
启动hadoop
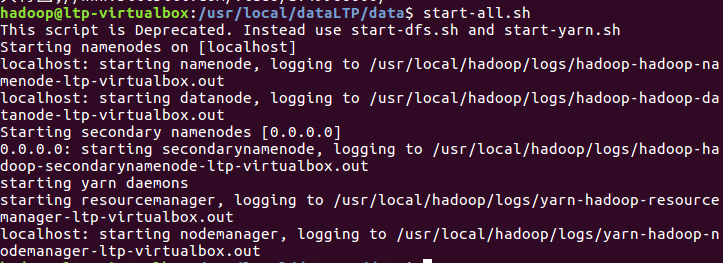
在hdfs上创建文件并上传rank.csv至hdfs

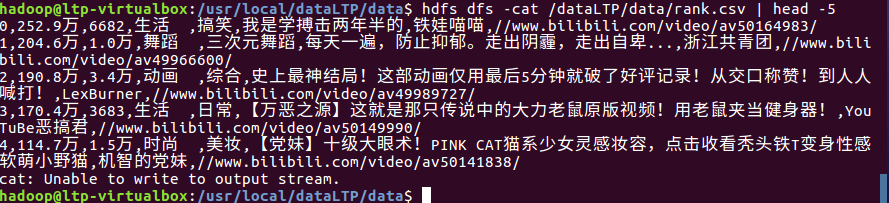
查看上传至hdfs上文件的前5条信息
2.对CSV文件进行预处理生成无标题文本文件
编辑pre_deal.sh文件进行数据的取舍处理

3.把hdfs中的文本文件最终导入到数据仓库Hive中
创建数据库dbltp并使用dbltp,创建表database_ltp

4.在Hive中查看并分析数据
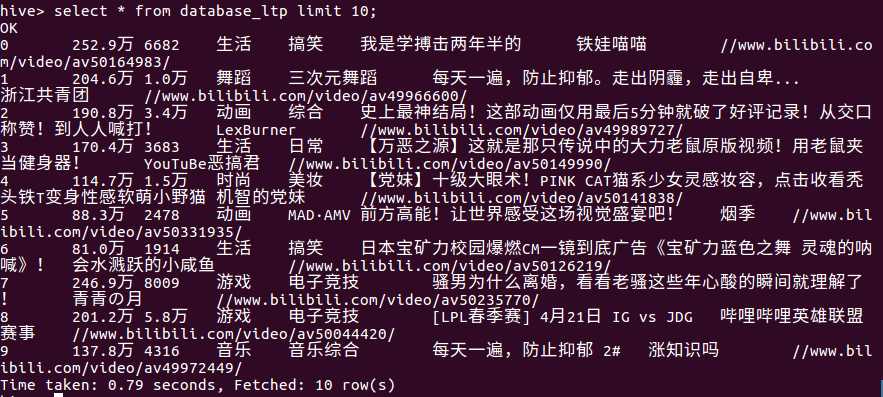
查看在hive中的前10条信息
5.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
(1)前10条信息
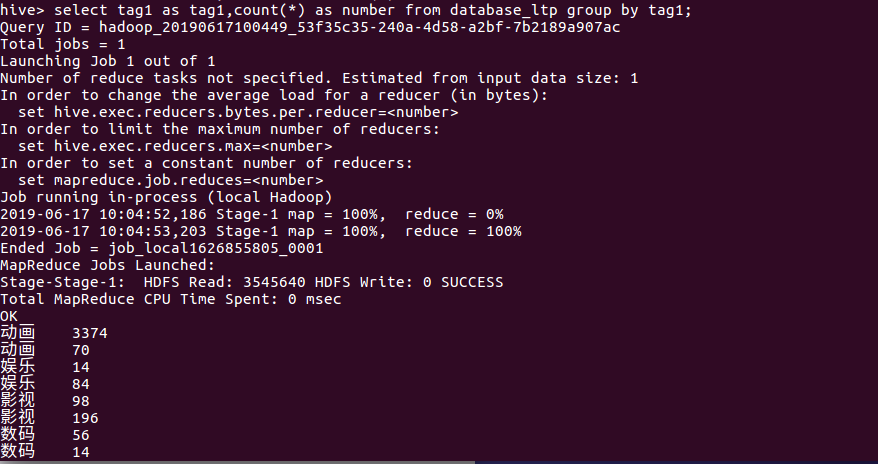
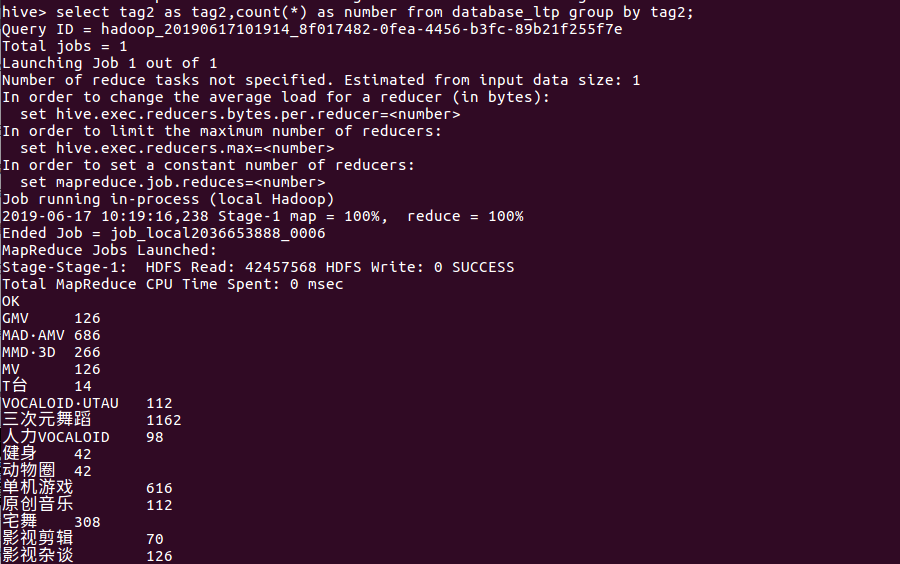
(2)统计各标签的视频量
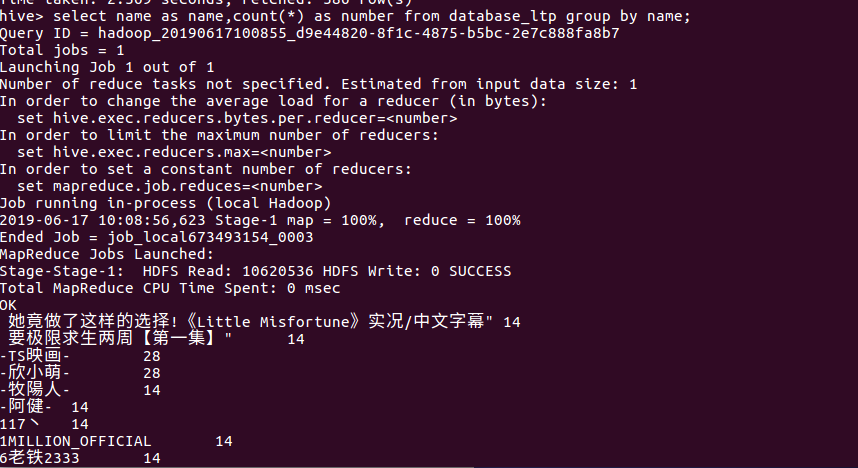
(3)统计各个up主的上榜视频量
(4)查看华农兄弟的上榜视频及播放量

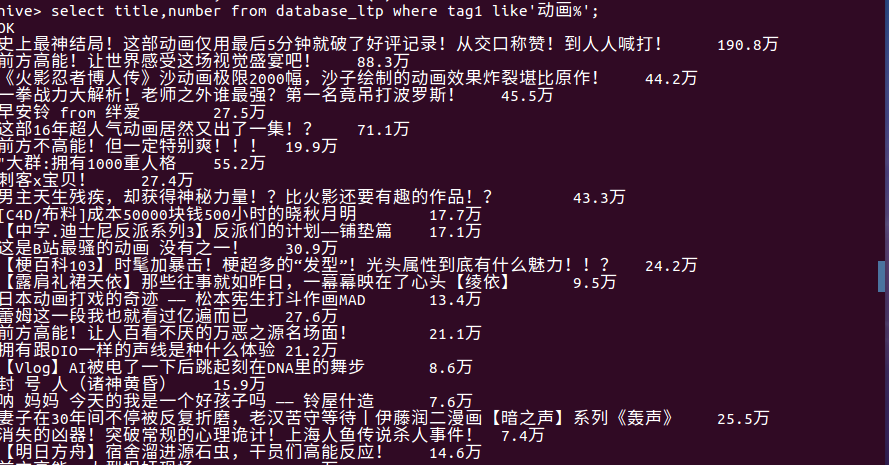
(5)查看动画标签的视屏播放量
(6)查看舞蹈标签的视屏播放量
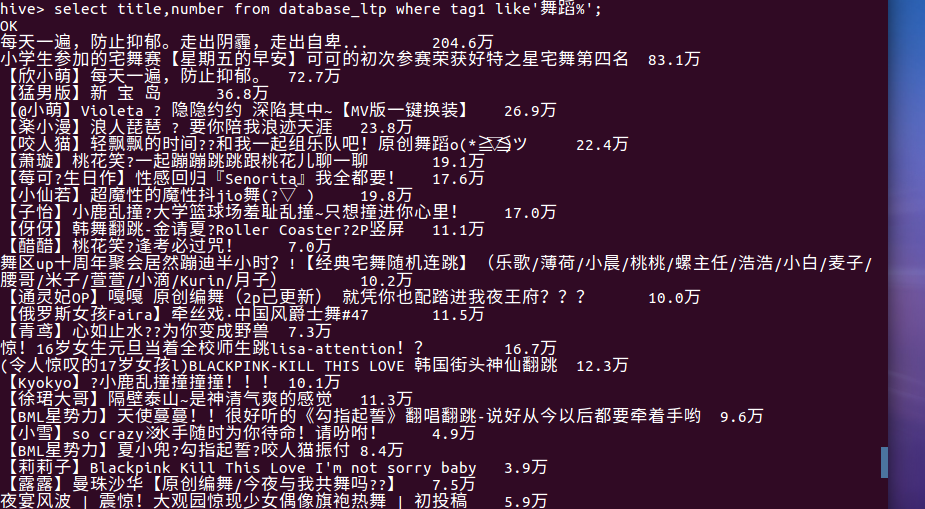
(7)统计各标签的上榜视屏量
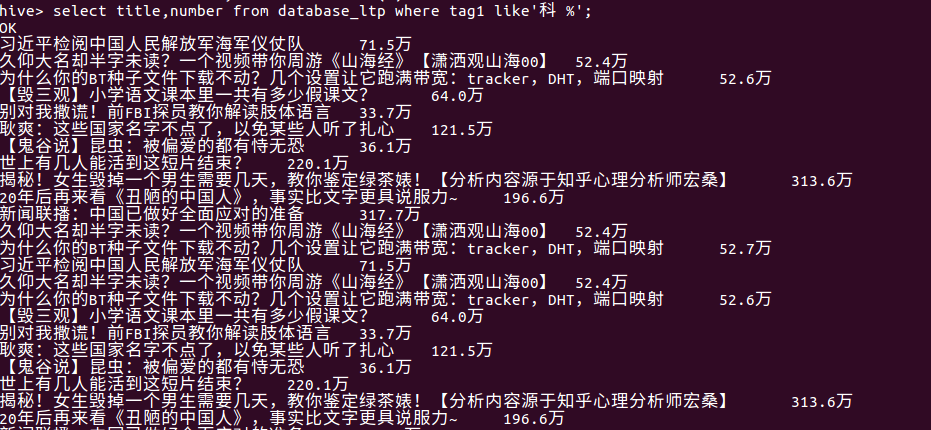
(8)查看科技标签的视屏播放量
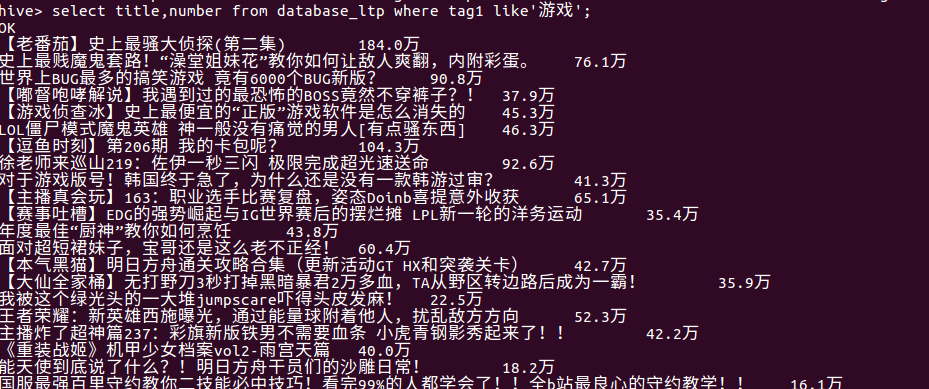
(9)查看游戏标签的视屏播放量
(10)查看视频名带番的视屏播放量


 浙公网安备 33010602011771号
浙公网安备 33010602011771号