爬虫综合
一.把爬取的内容保存取MySQL数据库
- import pandas as pd
- import pymysql
- from sqlalchemy import create_engine
- conInfo = "mysql+pymysql://user:passwd@host:port/gzccnews?charset=utf8"
- engine = create_engine(conInfo,encoding='utf-8')
- df = pd.DataFrame(allnews)
- df.to_sql(name = ‘news', con = engine, if_exists = 'append', index = False)
二.爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
参考:
爬了一下天猫上的Bra购买记录,有了一些羞羞哒的发现...
Python做了六百万字的歌词分析,告诉你中国Rapper都在唱些啥
分析了42万字歌词后,终于搞清楚民谣歌手唱什么了
十二星座的真实面目
唐朝诗人之间的关系到底是什么样的?
中国姓氏排行榜
三.爬虫注意事项
1.设置合理的爬取间隔,不会给对方运维人员造成压力,也可以防止程序被迫中止。
- import time
- import random
- time.sleep(random.random()*3)
2.设置合理的user-agent,模拟成真实的浏览器去提取内容。
- 首先打开你的浏览器输入:about:version。
- 用户代理:
- 收集一些比较常用的浏览器的user-agent放到列表里面。
- 然后import random,使用随机获取一个user-agent
- 定义请求头字典headers={’User-Agen‘:}
- 发送request.get时,带上自定义了User-Agen的headers
3.需要登录
发送request.get时,带上自定义了Cookie的headers
headers={’User-Agen‘:
'Cookie': }
4.使用代理IP
通过更换IP来达到不断高 效爬取数据的目的。
headers = {
"User-Agent": "",
}
proxies = {
"http": " ",
"https": " ",
}
response = requests.get(url, headers=headers, proxies=proxies)
BILIBILI每日排行榜视频信息获取
获取bilibili每日全站排行榜,提取标签,评论。
获取评论
API: http://api.bilibili.cn/feedback
参数
| aid | true | int | AV号 |
| page | true | int | 页码 |
| pagesize | false | int | 单页返回的记录条数,最大不超过300,默认为10。 |
| ver | false | int | API版本,最新是3 |
| order | false | string | 排序方式 默认按发布时间倒序 可选:good 按点赞人数排序 hot 按热门回复排序 |
ver1
| 返回值字段 | 字段类型 | 字段说明 |
|---|---|---|
| mid | int | 会员ID |
| lv | int | 楼层 |
| fbid | int | 评论ID |
| msg | string | 评论信息 |
| ad_check | int | 状态 (0: 正常 1: UP主隐藏 2: 管理员删除 3: 因举报删除) |
| face | string | 发布人头像 |
| rank | int | 发布人显示标识 |
| nick | string | 发布人暱称 |
| totalResult | int | 总评论数 |
| pages | int | 总页数 |
replay
| 返回值字段 | 字段类型 | 字段说明 |
|---|---|---|
| mid | int | 会员ID |
| lv | int | 楼层 |
| fbid | int | 评论ID |
| msg | string | 评论信息 |
| ad_check | int | 状态 (0: 正常 1: UP主隐藏 2: 管理员删除 3: 因举报删除) |
| face | string | 发布人头像 |
| rank | int | 发布人显示标识 |
| nick | string | 发布人暱称 |
| totalResult | int | 总评论数 |
| pages | int | 总页数 |
| good | int | 点赞数? |
| isgood | int | 是否已点赞? |
| device | 未知 | 未知 |
| create | int | 创建评论的UNIX时间 |
| create_at | String | 创建评论的可读时间(2016-01-20 15:52) |
| reply_count | int | 回复数量 |
| level_info | list | 用户的等级信息? |
| sex | String | 用户的性别 |
例: AV number=50164983:
http://api.bilibili.com/x/reply?type=1&oid=50164983&pn=1&nohot=1&sort=0

返回信息:

再看Preview
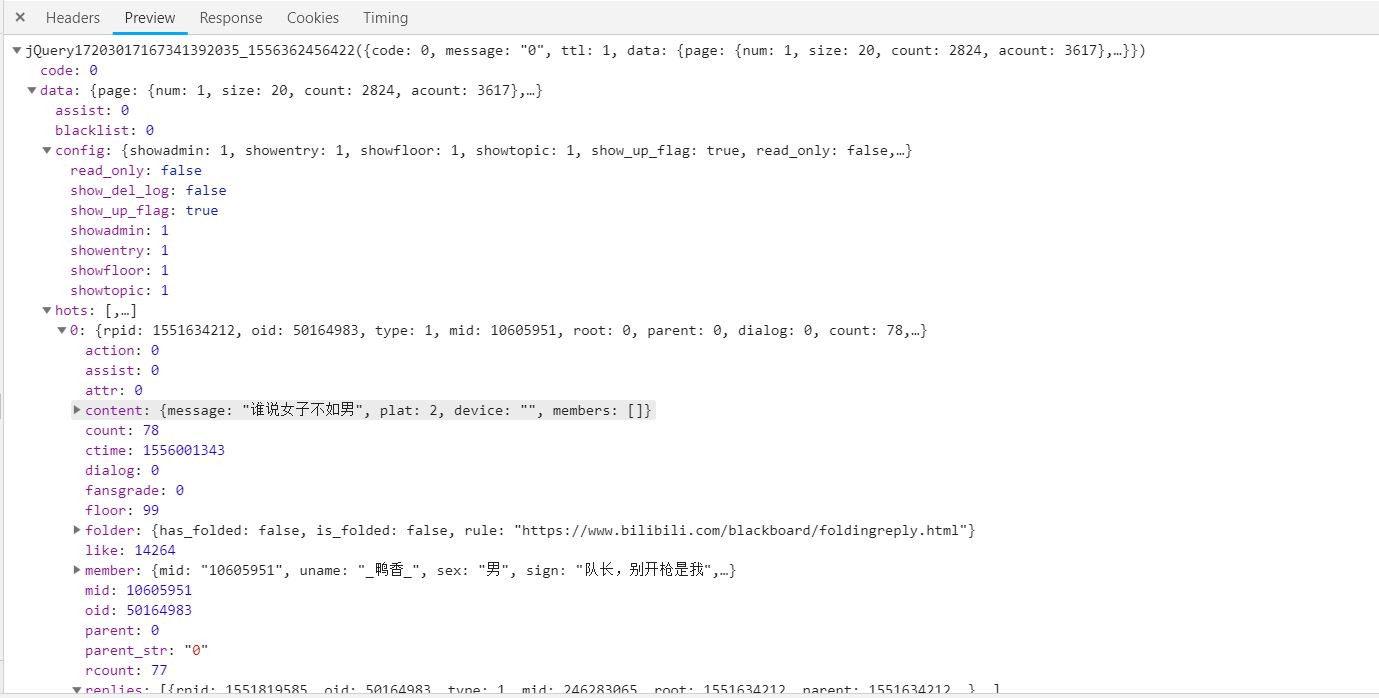
可知Size=20,count=2824,用户名在[MEMBER][UNAME]下,回复信息在[content][message]下
如此balabala.......
标签分析

可以发现b站用户多喜欢看 生活向,鬼畜向的视频
排行榜第一的视频的评论数据(ps我对蔡某人没任何意见)
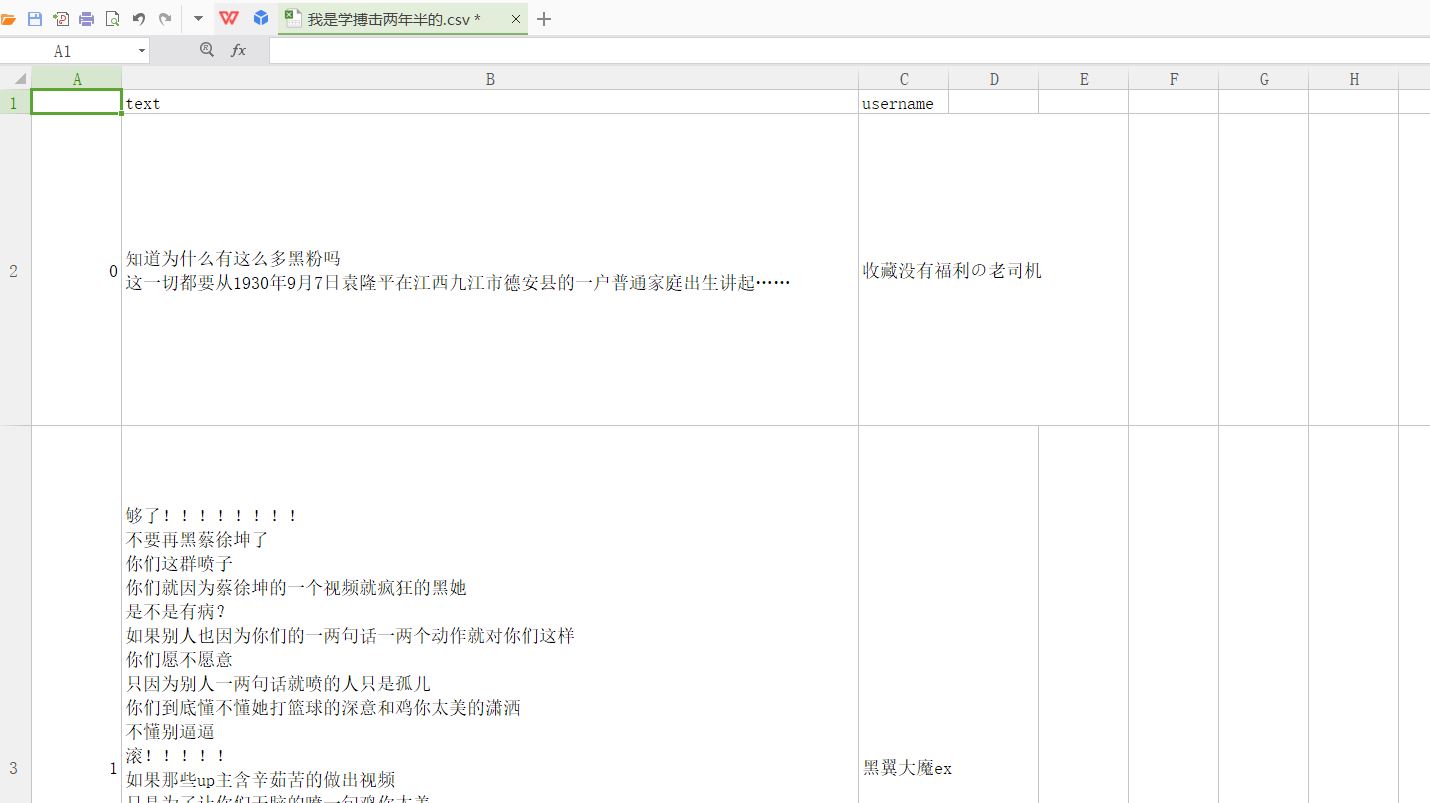
这是在数据库里面

排行榜:
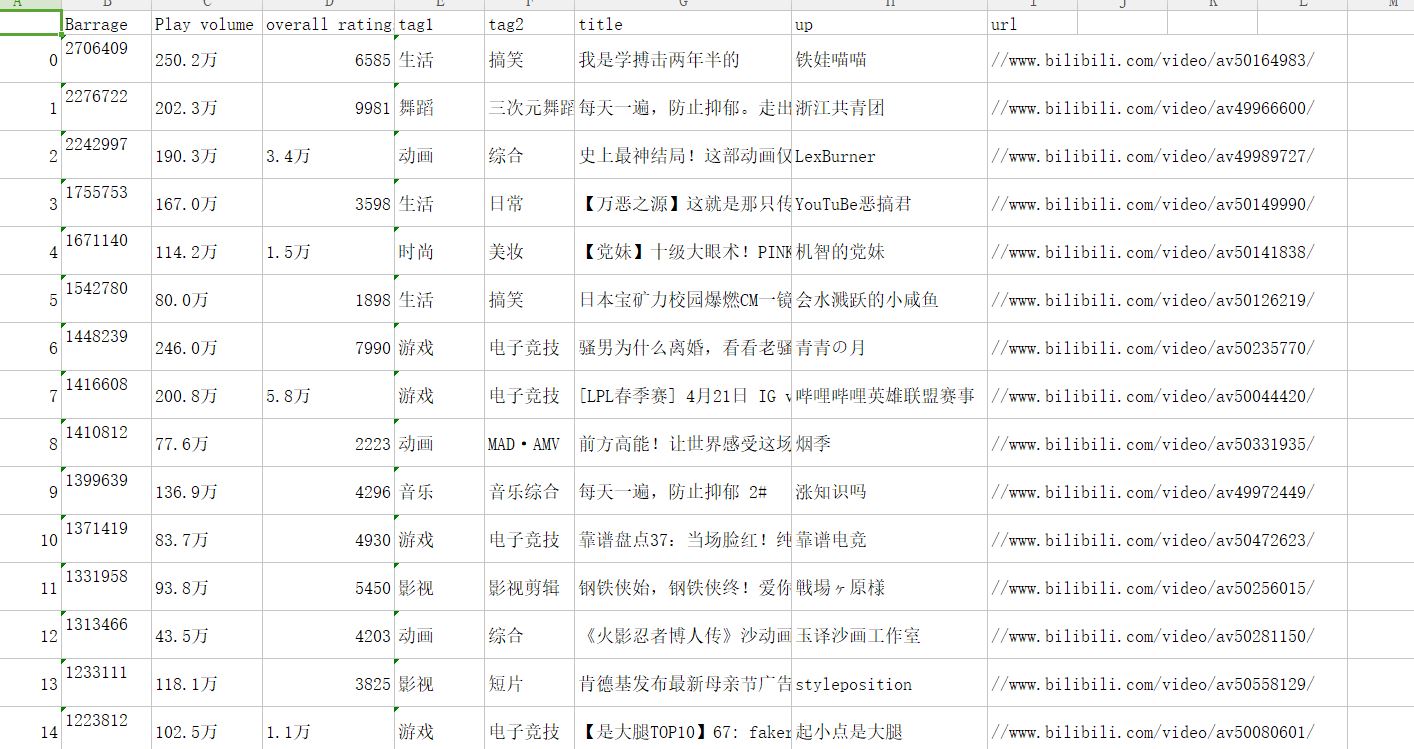

以下是代码:
头部
UA = [ 'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50', 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1', 'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1', 'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11', 'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)', 'Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5', 'Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5', 'Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5', 'Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1', 'MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile ', 'Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10', 'Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13', 'Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+', 'Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0', 'Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) ', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)', 'Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999', ] headers = { 'Referer': 'https://www.bilibili.com/v/douga/mad/?spm_id_from=333.334.b_7072696d6172795f6d656e75.3', 'User-Agent': choice(UA) } herder={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36', 'Host': 'www.bilibili.com', 'Connection': 'keep-alive', 'Cache-Control': 'max-age=0', 'Upgrade-Insecure-Requests': '1', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9,zh-TW;q=0.8,en;q=0.7', "Cookie": "fts=1519723607; pgv_pvi=9921057792; im_notify_type_5172000=0; LIVE_BUVID=d9102c76da863db3e7c92490dc7c1458; LIVE_BUVID__ckMd5=300ca52bca0020e2; im_local_unread_5172000=0; buvid3=633B41F7-7489-4AFF-A338-C6B691D748BF163029infoc; CURRENT_FNVAL=16; _uuid=154F2A25-2995-7B95-9278-CEB7B98119CB36766infoc; UM_distinctid=16797b478ab161-09c84bb5055ad7-b79183d-144000-16797b478ac59c; stardustvideo=-1; sid=iv38z60z; CURRENT_QUALITY=32; DedeUserID=5172000; DedeUserID__ckMd5=177188bf6c38a514; SESSDATA=7901bc88%2C1557721353%2Ccca68741; bili_jct=7b58735b2fbf739a2a7ca05ffb0aa722; rpdid=|(J~R)uJlkYl0J'ullYJluJYY; bp_t_offset_5172000=247013898595062047; _dfcaptcha=cf9b64400c2062d1a78de2019210c7fb", }
评论
def getAllCommentList(id): url = "http://api.bilibili.com/x/reply?type=1&oid=" + str(id) + "&pn=1&nohot=1&sort=0" r = requests.get(url) numtext = r.text json_text = json.loads(numtext) commentsNum = json_text["data"]["page"]["count"] page = commentsNum // 20 + 1 for n in range(1,page): url = "https://api.bilibili.com/x/v2/reply?jsonp=jsonp&pn="+str(n)+"&type=1&oid="+str(id)+"&sort=1&nohot=1" req = requests.get(url) text = req.text json_text_list = json.loads(text) for i in json_text_list["data"]["replies"]: info={} info['username']=i['member']['uname'] info['text']=i['content']['message'] infolist.append(info) def saveTxt(filename,filecontent): df = pd.DataFrame(filecontent) df.to_csv(filename+'.csv') print('视频:'+filename+'的评论已保存')
标签
def gettag(id): ranksss={} url="https://www.bilibili.com/video/av"+str(id)+'' tag = requests.get(url,headers=herder) tag.encoding = 'utf-8' tagsoup = BeautifulSoup(tag.text, 'html.parser') tagwww=tagsoup.select('.tm-info') for ii in tagsoup.select('.tm-info'): tag1 = ii.select('.crumb')[1].text.replace('>','') tag2 = ii.select('.crumb')[2].text ranksss['tag1']=tag1 ranksss['tag2']=tag2 return ranksss
主体信息
for ii in soup.select('.rank-list'): for ifo in ii.select('.rank-item'): ranks={} rankUrl = ifo.select('.title')[0]['href'] ranktitle = ifo.select('.title')[0].text ranknum = ifo.select('.data-box')[0].text rankdanmus = ifo.select('.data-box')[1].text rankmaker = ifo.select('.data-box')[2].text rankfie = ifo.select('.pts')[0].text.replace('综合得分','') id = re.findall('(\d{7,8})', rankUrl)[-1] # 获取车牌号 ranks=gettag(str(id)) ranks['up'] = rankmaker ranks['title'] = ranktitle print(ranks['tag1']) ranks['url'] = rankUrl ranks['Play volume'] = ranknum ranks['Barrage'] = rankfie ranks['overall ratings'] = rankdanmus ranklist.append(ranks) with open('tag.txt', "a", encoding='utf-8') as txt: txt.write(ranks['tag1']+ranks['tag2']) infolist.clear() getAllCommentList(id) # 给定车牌号获取评论信息 saveTxt(ranktitle, infolist)
词云
from wordcloud import WordCloud, ImageColorGenerator import matplotlib.pyplot as plt import jieba mask_png = plt.imread("fate.jpeg") cloud = WordCloud( font_path=r"C:\Windows\Fonts\simhei.ttf",# 词云自带的字体不支持中文,在windows环境下使用黑体中文 background_color="white", # 背景颜色 max_words=500, # 词云显示的最大词数 max_font_size=150, # 字体最大值 random_state=50, mask=mask_png, width=1000, height=860, margin=2,) def stopWordsList(): stopwords = [line.strip() for line in open('csw.txt', encoding='UTF-8').readlines()] return stopwords txt = open(r'C:\Users\Ltp\Downloads\bd\tag.txt', 'r', encoding='utf-8').read() stopWords = stopWordsList() for exc in stopWords: txt = txt.replace(exc, '') wordList = jieba.lcut(txt); wordDict = {} woreSet=set(wordList) woreSet=woreSet-set(stopWords) for word in wordList: if word not in stopWords: if len(word) == 1: continue else: wordDict[word] = wordDict.get(word, 0) + 1 wordCloudLS = list(wordDict.items()) wordCloudLS.sort(key=lambda x: x[1], reverse=True) for i in range(35): print(wordCloudLS[i]) wcP = " ".join(wordList) mywc = cloud.generate(wcP) plt.imshow(mywc) plt.axis("off") plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号