理解爬虫
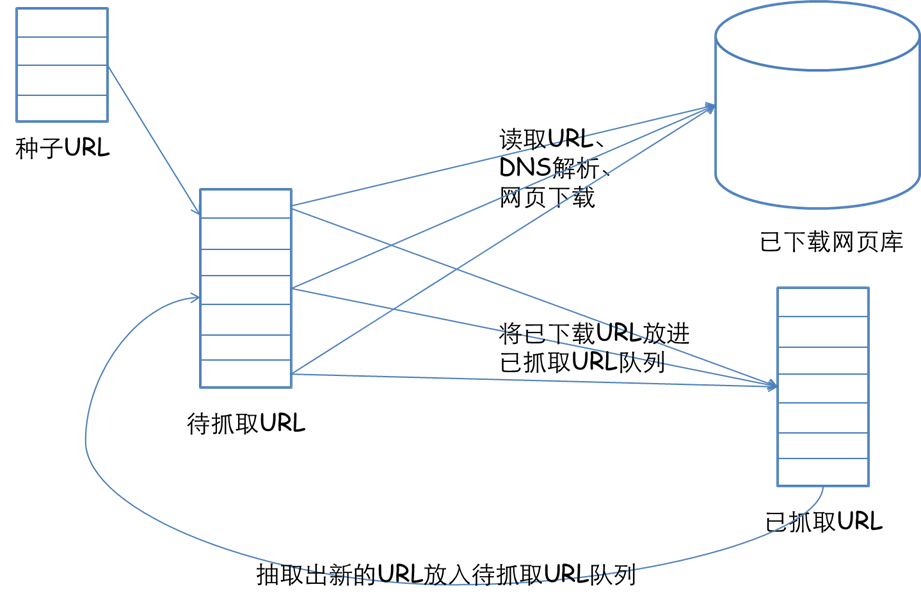
1. 简单说明爬虫原理
通过技术手段来快速获取互联网的内容,并从中提取有价值的信息的过程。
2. 理解爬虫开发过程
request->response->process->extract
伪造或者模仿用户行为访问网页->获取网页内容->提取有价值信息
1).简要说明浏览器工作原理;
浏览器提交访问请求->网页返回response->浏览器呈现网页返回信息
2).使用 requests 库抓取网站数据;
requests.get(url) 获取校园新闻首页html代码
import requests url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html' res=requests.get(url) res.encoding='UTF-8' print(res.text)
3).了解网页
写一个简单的html文件,包含多个标签,类,id
<!doctype html>
<html class="no-js" lang="">
<head>
</head>
<body bgcolor="#eeeeee">
<div id="header" class=‘main_title’>
<h1>Power By Urara</h1>
</div>
<div id="nav" class='nav_content'>
<h1>live up!<h1>
<li>prous!<li>
<li>钉子<li>
</div>
<div id="mid-down" align="center" class='mid'>
<a href="http://www.bing.com"><font id="font5">qop</font></a><p>
<hr>
</div>
<div id="footer" class='footer'>
live up! o1.v
</div>
</body>
</html>
4).使用 Beautiful Soup 解析网页;
通过BeautifulSoup(html_sample,'html.parser')把上述html文件解析成DOM Tree
select(选择器)定位数据
找出含有特定标签的html元素
找出含有特定类名的html元素
找出含有特定id名的html元素
import requests
from bs4 import BeautifulSoup
url='http://www.bing.com'
parser = 'html.parser'
soup = BeautifulSoup(requests.get(url), parser)
tsel1=soup.select('.show-title')
tsel2=soup.select('a')
tfind1=soup.find(id='main')
tfind2=soup.find(id='mian').find_all('a')
3.提取一篇校园新闻的标题、发布时间、发布单位
url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html'
import requests
from bs4 import BeautifulSoup
parser = 'html.parser'
url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html'
res=requests.get(url)
res.encoding='UTF-8'
soup = BeautifulSoup(res.text, parser)
for selsoup in soup.select('.show-nav'):
title=soup.select('.show-title')[0].text
msg=soup.select('.show-info')[0].text
print('标题: '+title +' 信息:'+ msg)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号