1. 简介
Flask-APScheduler
适配于Flask框架 是APScheduler扩展
支持flask配置类加载定时任务调度器配置和任务配置明细
提供内部restful风格API监控管理定时任务、认证机制、host白名单访问机制
高度与flask蓝图集成
2. 安装
pip install Flask-APScheduler -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
3. 基础使用
# -*- coding:utf-8 -*-
import datetime
from apscheduler.events import EVENT_JOB_EXECUTED, EVENT_JOB_ERROR
from flask import Flask
from flask_apscheduler import APScheduler
class Config:
SCHEDULER_API_ENABLED = True # 开启内置API访问权限
WERKZEUG_RUN_MAIN = True
app = Flask(__name__) # webApp实例
app.config.from_object(Config()) # 通过配置类配置
scheduler = APScheduler()
# scheduler.api_enabled = True # 等价于 类属性 SCHEDULER_API_ENABLED = True
scheduler.init_app(app)
scheduler.start()
# interval触发器实例
@scheduler.task('interval', id='do_job_1', seconds=30, misfire_grace_time=900)
def job1():
print('Job 1 executed ' + str(datetime.datetime.now()))
# cron触发器实例
@scheduler.task('cron', id='do_job_2', minute='*')
def job2():
print('Job 2 executed ' + str(datetime.datetime.now()))
# date触发器实例
def job3():
print('Job 3 executed ' + str(datetime.datetime.now()))
if __name__ == '__main__':
scheduler.add_job(id='do_job_3', func=job3, trigger='date', run_date='2023-03-09 15:39:00', timezone="Asia/Shanghai", replace_existing=True)
# scheduler.add_listener(job3, EVENT_JOB_EXECUTED | EVENT_JOB_ERROR)
app.run(use_reloader=False)
4. 组件介绍

triggers>触发器
job stores>任务存储器
executors>执行器
scheduler>调度器
4.1 triggers(触发器)
1. 描述
任务的运行周期;每个任务都有自己的触发器,只有满足触发条件才会执行任务;可结合多种触发器同时使用
2. 方式
2.1 date 特定时间节点
参数:
run_date: 特定日期 str | date | datetime
time_zone: 时区 str
2.2 interval 固定时间间隔
参数:
weeks:间隔几周 int
days:间隔几天 int
hours:间隔几小时 int
minutes:间隔几分钟 int
seconds:间隔几秒 int
start_date:开始日期 datetime | str
end_date:结束日期 datetime | str
timezone:指定时区 str
2.3 cron 特定时间周期
参数:
year: 年 四位数 int | str
month: 月 (范围1-12) int | str
day: 日 (范围1-31) int | str
week:周 (范围1-53) int | str
day_of_week: 一周中第几天 (范围0-6 0是周一 6是周日 | mon,tue,wed,thu,fri,sat,sun) int |str
hour: 时 (范围0-23) (int | str)
minute: 分 (范围0-59) (int | str)
second: 秒 (范围0-59) (int | str)
start_date: 开始日期 (datetime | str)
end_date: 结束日期 (datetime | str)
timezone: 指定时区 (datetime | str)
参数表达式
* : 任意值
*/x: 每隔x执行
x-y: 在x-y区间执行
x,y,z: 在x y z 特定点执行
2.4 date+interval+cron 组合
AndTrigger(triggers:list, jitter:int|None)
OrTrigger(triggers:list, jitter:int|None)
-jitter: 最多延迟执行时间(s)
import datetime
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.triggers.combining import AndTrigger, OrTrigger
from apscheduler.triggers.date import DateTrigger
from apscheduler.triggers.interval import IntervalTrigger
from apscheduler.triggers.cron import CronTrigger
from flask import Flask
from flask_apscheduler import APScheduler
# 1 date触发器
date_trigger = DateTrigger(run_date="2023-03-09 20:56:00", timezone='Asia/Shanghai')
# 2 interval触发器
interval_trigger = IntervalTrigger(seconds=5, timezone='Asia/Shanghai')
# 3 cron触发器
cron_trigger = CronTrigger(minute="*", timezone='Asia/Shanghai')
# 4 复合触发器 combining_trigger
combining_trigger = AndTrigger([IntervalTrigger(minutes=1, timezone='Asia/Shanghai'),
CronTrigger(day_of_week="sat,sun", timezone='Asia/Shanghai')])
# combining_trigger = OrTrigger([CronTrigger(day_of_week='mon', hour=2),
# CronTrigger(day_of_week='tue', hour=15)])
def job(trigger_type):
print(f"type-{trigger_type}-job executed " + str(datetime.datetime.now()))
if __name__ == '__main__':
app = Flask(__name__)
scheduler = APScheduler(BackgroundScheduler(timezone='Asia/Shanghai'))
scheduler.init_app(app)
scheduler.add_job(id='date_trigger', func=job, trigger=date_trigger, args=('date_trigger', ), replace_existing=True)
scheduler.add_job(id='interval_trigger', func=job, trigger=interval_trigger, args=('interval_trigger', ), replace_existing=True)
scheduler.add_job(id='cron_trigger', func=job, trigger=cron_trigger, args=('cron_trigger', ), replace_existing=True)
# ps: AndTrigger存在一定问题
scheduler.add_job(id='combining_trigger', func=job, trigger=combining_trigger, args=('combining_trigger', ), replace_existing=True)
scheduler.start()
app.run(port=5001, use_reloader=False)
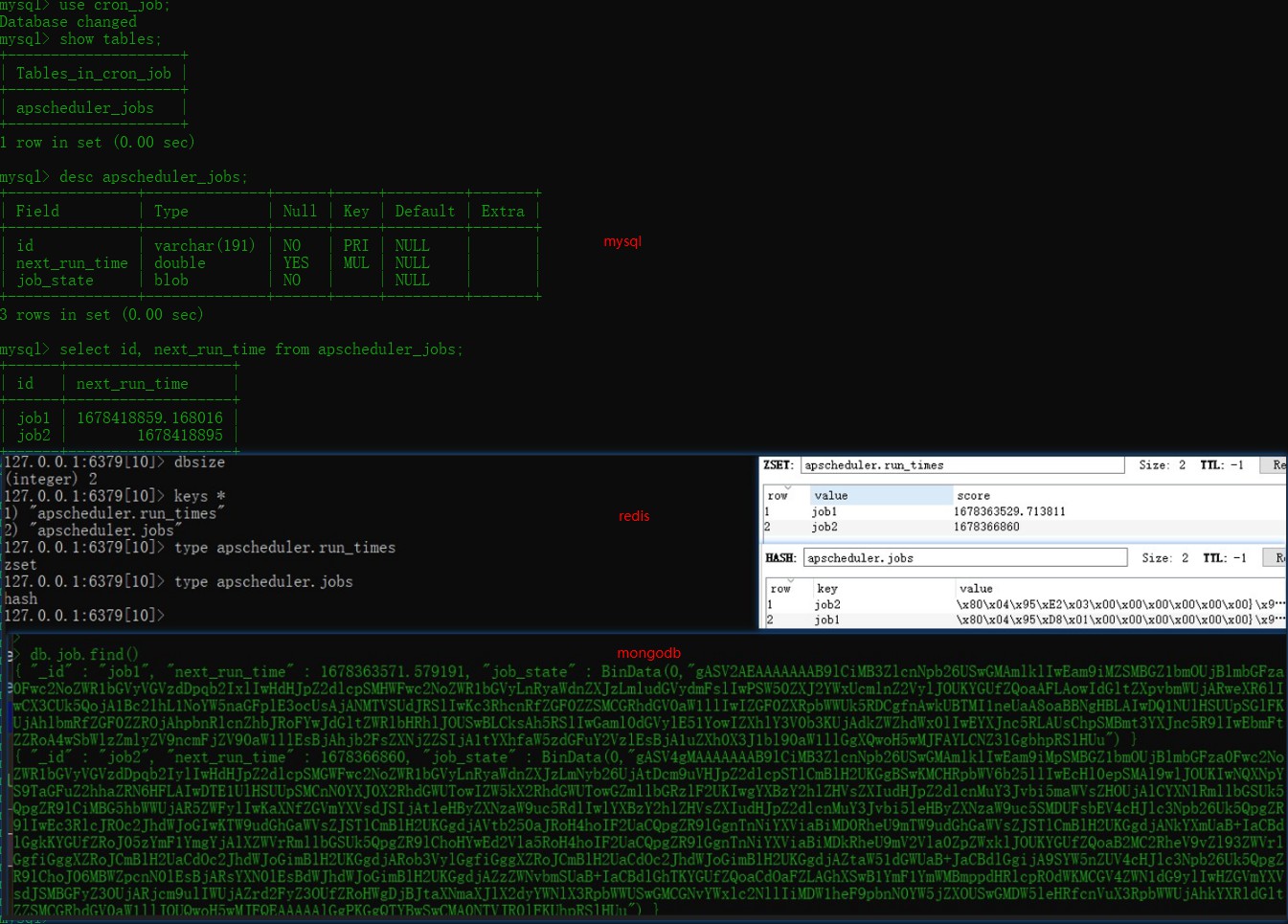
4.2 job stores(任务存储器)
1. 描述
任务信息存储;默认保存到内存,提供多种数据中间件存储方式;
2. 方式
2.1 memory(默认内存)
2.2 mongodb(文档型数据库)
2.3 redis(键值对型数据库)
2.4 sqlalchemy(关系型数据库)
3. ps:
MongoDBStore name 'mongo'
SqlalchemyJobStore name 'default' using sqlite
# -*- coding:utf-8 -*-
from apscheduler.jobstores.redis import RedisJobStore
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.mongodb import MongoDBJobStore
jobstores = {
'default': SQLAlchemyJobStore(url="sqlite:///jobs.sqlite")
}
jobstores = {
'default': SQLAlchemyJobStore(url="mysql://root:xxx@127.0.0.1:3306/job'"),
# 若出现源码层面问题 更新依赖包版本比如pymysql
# 'default': SQLAlchemyJobStore(url="mysql+pymysql://root:xxx@127.0.0.1:3306/cron_job'") # 可自定义tablename
}
jobstores = {
'default': MongoDBJobStore(host="127.0.0.1", port=27017, database="cronJob", collection="job")
}
jobstores = {
'default': RedisJobStore(host="127.0.0.1",port=6379, db=0, password='')
}
# 引入配置的方法,在创建类时加入配置项
scheduler = BackgroundScheduler(jobstores=jobstores)
4.3 executors(执行器)
1.描述
负责任务处理;方式可采用线程池或者进程池,与调度器交互;
2. 方式
2.1 threadpoolExecutor
2.2 processpoolExecutor
3. ps
threadpoolExecutor name 'default' 默认20
processpoolExecutor name 'processpool' 默认5
from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor
executors = {
'default': ThreadPoolExecutor(20),
'processpool': ProcessPoolExecutor(5)
}
sche = BackgroundScheduler(executors=executors)
# 任务配置
job_defaults = {
# 不合并执行>异常任务再下次服务启动后是否重启
'coalesce': False,
# 同一时间同个任务最大执行次数为3
'max_instances': 3,
# 任务错过当前时间60s内,仍然可以触发任务
'misfire_grace_time':60
}
# 创建类,导入配置
scheduler = BackgroundScheduler(job_defaults=job_defaults)
4.4 scheduler(调度器)
1. 描述
任务发布决策;调度器与其他组件交互完成任务的添加 修改 删除 查询;
2. 类型
2.1 BlockingScheduler: use when the scheduler is the only thing running in your process(阻塞)
2.2 BackgroundScheduler: use when you’re not using any of the frameworks below, and want the scheduler to run in the background inside your application(非阻塞)
2.3 AsyncIOScheduler: use if your application uses the asyncio module(异步asyncio框架)
2.4 GeventScheduler: use if your application uses gevent(高并发gevent模块)
2.5 TornadoScheduler: use if you’re building a Tornado application(tornado Web框架)
2.6 TwistedScheduler: use if you’re building a Twisted application(twisted 基于reactor异步非阻塞io网络框架)
2.7 QtScheduler: use if you’re building a Qt application(Qt Ui)
# -*- coding:utf-8 -*-
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.mongodb import MongoDBJobStore
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor
# 方式1 scheduler
jobstores = { # 任务存储器配置
'mongo': MongoDBJobStore(),
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
executors = { # 任务执行器配置
'default': ThreadPoolExecutor(20),
'processpool': ProcessPoolExecutor(5)
}
job_defaults = { # 任务常规配置
'coalesce': False,
'max_instances': 3,
}
scheduler1 = BackgroundScheduler(jobstores=jobstores, executors=executors, job_defaults=job_defaults, timezone="Asia/Shanghai")
# 方式2
scheduler2 = BackgroundScheduler({
'apscheduler.jobstores.mongo': {
'type': 'mongodb'
},
'apscheduler.jobstores.default': {
'type': 'sqlalchemy',
'url': 'sqlite:///jobs.sqlite'
},
'apscheduler.executors.default': {
'class': 'apscheduler.executors.pool:ThreadPoolExecutor',
'max_workers': '20'
},
'apscheduler.executors.processpool': {
'type': 'processpool',
'max_workers': '5'
},
'apscheduler.job_defaults.coalesce': 'false', # 是否合并执行任务默认true;false则服务重启后异常未执行的任务会累计重新执行
'apscheduler.job_defaults.max_instances': '3', # 同一时间特定任务执行的实例个数;大于1时若之前任务未完成会再满足触发器的情况再次执行该任务
'apscheduler.timezone': 'UTC', # 时区
})
# 方式3
jobstores = {
'mongo': {'type': 'mongodb'},
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
executors = {
'default': {'type': 'threadpool', 'max_workers': 20},
'processpool': ProcessPoolExecutor(max_workers=5)
}
job_defaults = {
'coalesce': False,
'max_instances': 3
}
scheduler = BackgroundScheduler()
scheduler.configure(jobstores=jobstores, executors=executors, job_defaults=job_defaults, timezone='Asia/Shanghai')
5. 常规设置
5.1 Schedule配置参数
SCHEDULER_API_ENABLED: bool (default: False)
SCHEDULER_API_PREFIX: str (default: "/scheduler")
SCHEDULER_ENDPOINT_PREFIX: str (default: "scheduler.")
SCHEDULER_ALLOWED_HOSTS: list (default: ["*"])
SCHEDULER_JOBSTORES: dict
SCHEDULER_EXECUTORS: dict
SCHEDULER_JOB_DEFAULTS: dict
SCHEDULER_TIMEZONE: dict
jobstores = { # 任务存储器配置
'default': RedisJobStore(host='127.0.0.1', port=6379, db=10, password=''),
# 'default': SQLAlchemyJobStore(url="mysql://root:xxx@127.0.0.1:3306/job'"),
# 'default': MongoDBJobStore(host="127.0.0.1", port=27017, database="cronJob", collection="job"),
}
executors = { # 任务执行器配置
'default': ThreadPoolExecutor(20), # 线程池
'processpool': ProcessPoolExecutor(5) # 进程池
}
job_defaults = { # 任务常规配置
'coalesce': False, # True执行一次 False累计异常的任务会在下次重新执行
'max_instances': 3, # 同时间同个任务执行的最大实例数
'misfire_grace_time': 60, # 任务在触发器满足条件后的60s 还可触发任务
}
5.2 内置API
# 前置配置
SCHEDULER_API_ENABLED: True
# API集合
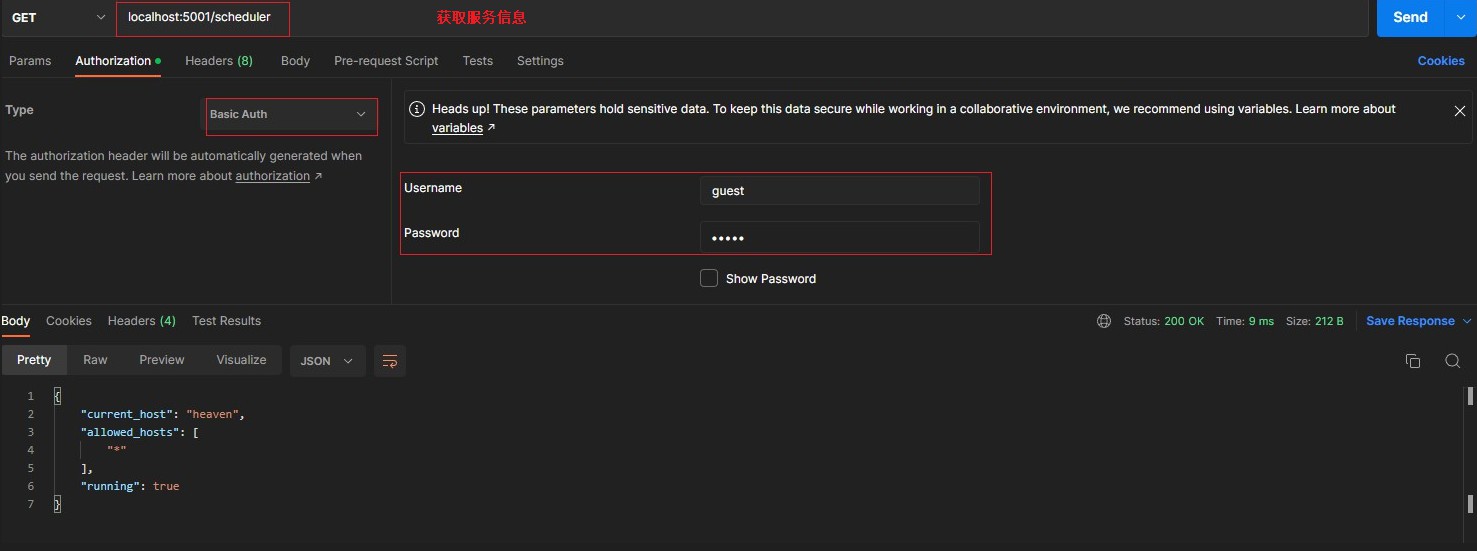
/scheduler [GET] > returns basic information about the webapp > 获取服务基本信息
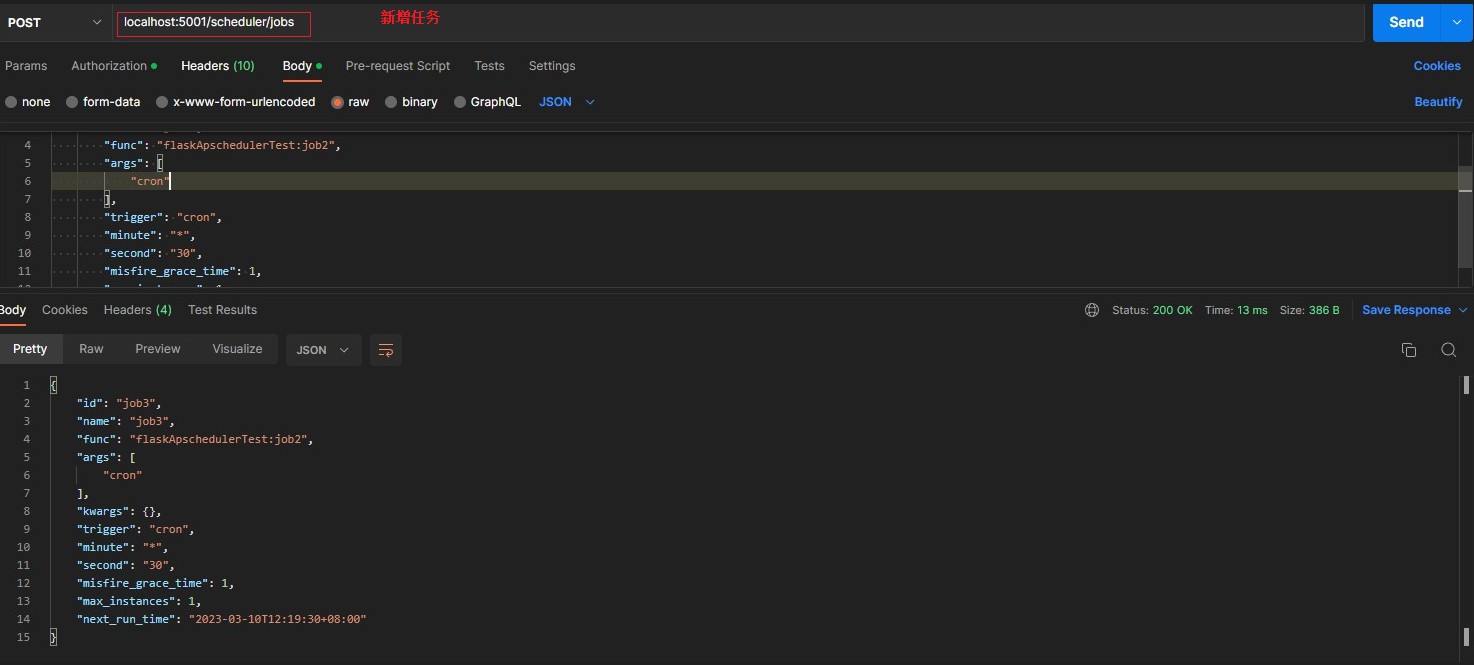
/scheduler/jobs [POST json job data] > adds a job to the scheduler > 新增任务(需要入参 类型json)
{
"id": "job3",
"name": "job3",
"func": "flaskApschedulerTest:job2",
"args": [
"cron_test"
],
"trigger": "cron",
"minute": "*",
"second": "45",
"misfire_grace_time": 1,
"max_instances": 1
}
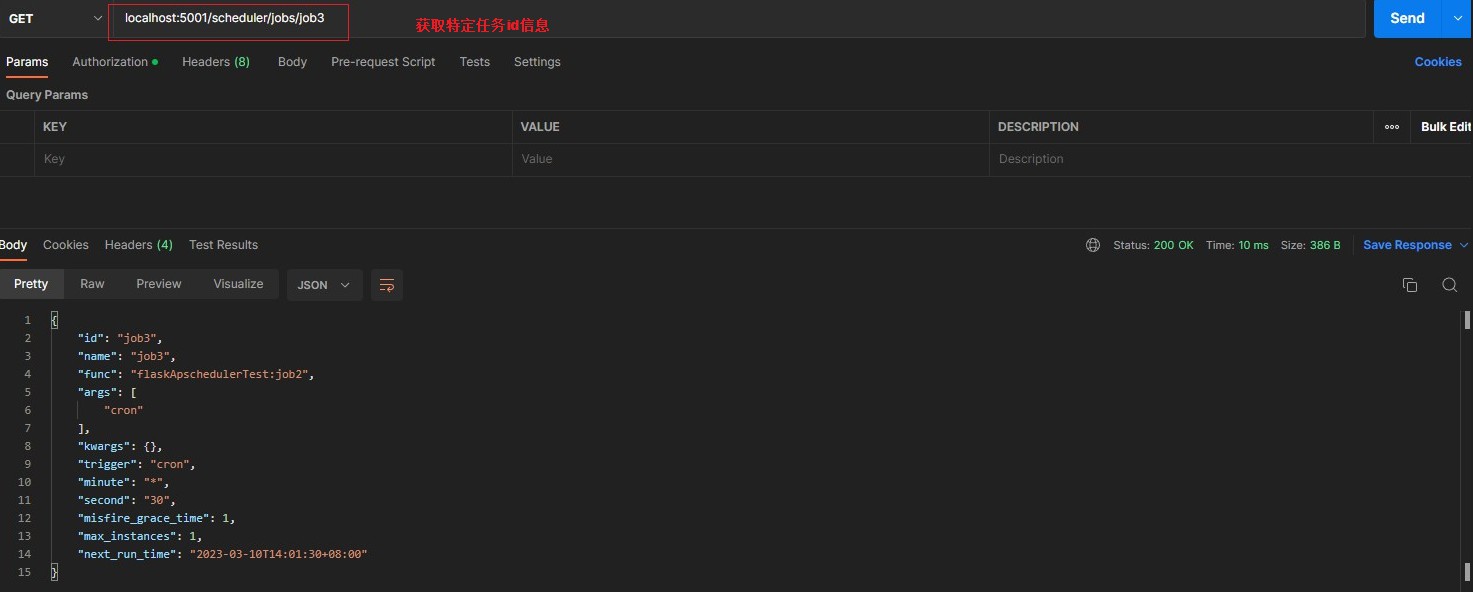
/scheduler/jobs/<job_id> [GET] > returns json of job details > 查询特定任务信息
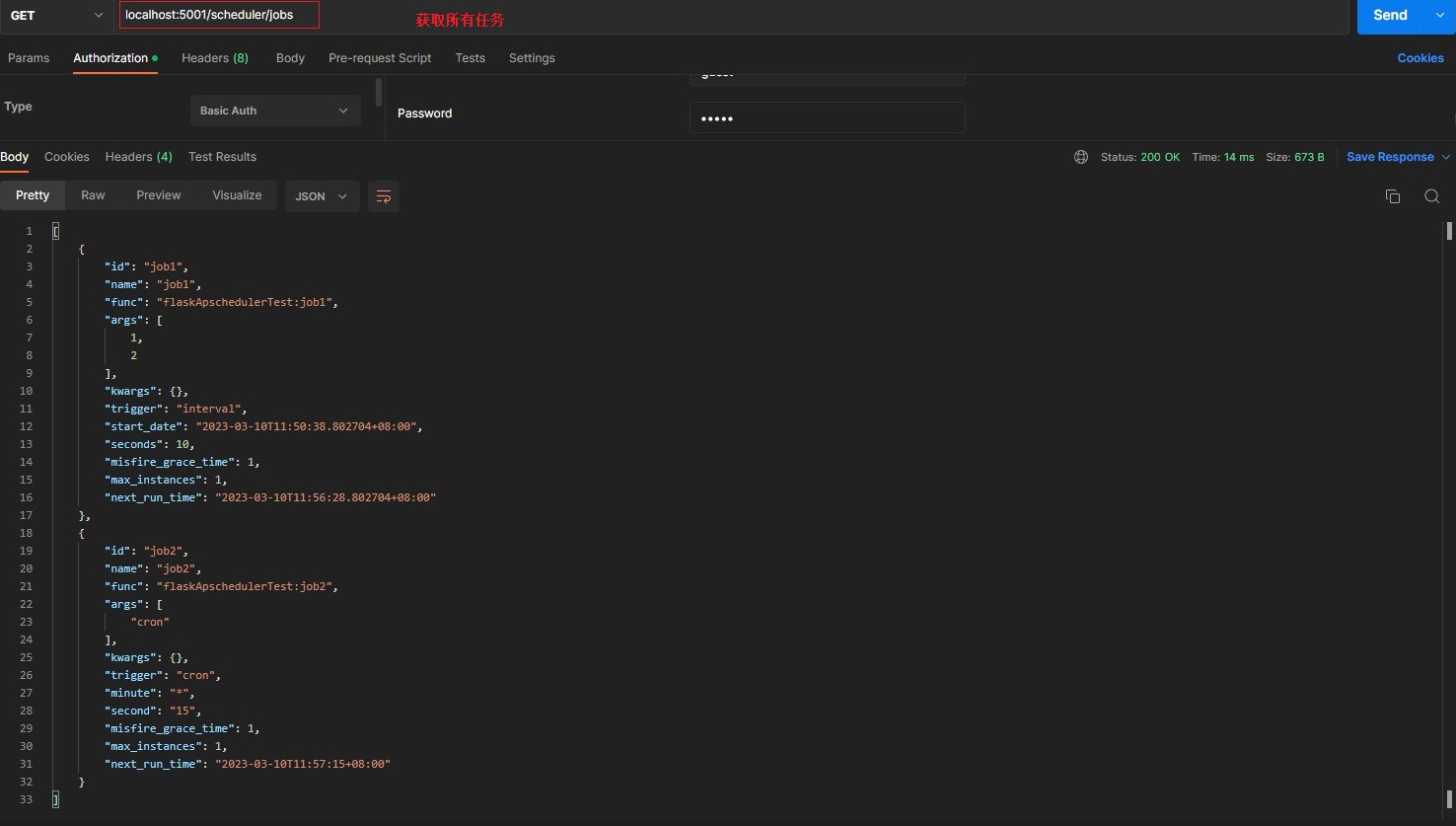
/scheduler/jobs [GET] > returns json with details of all jobs > 查询所有任务信息
/scheduler/jobs/<job_id> [DELETE] > deletes job from scheduler > 删除特定任务
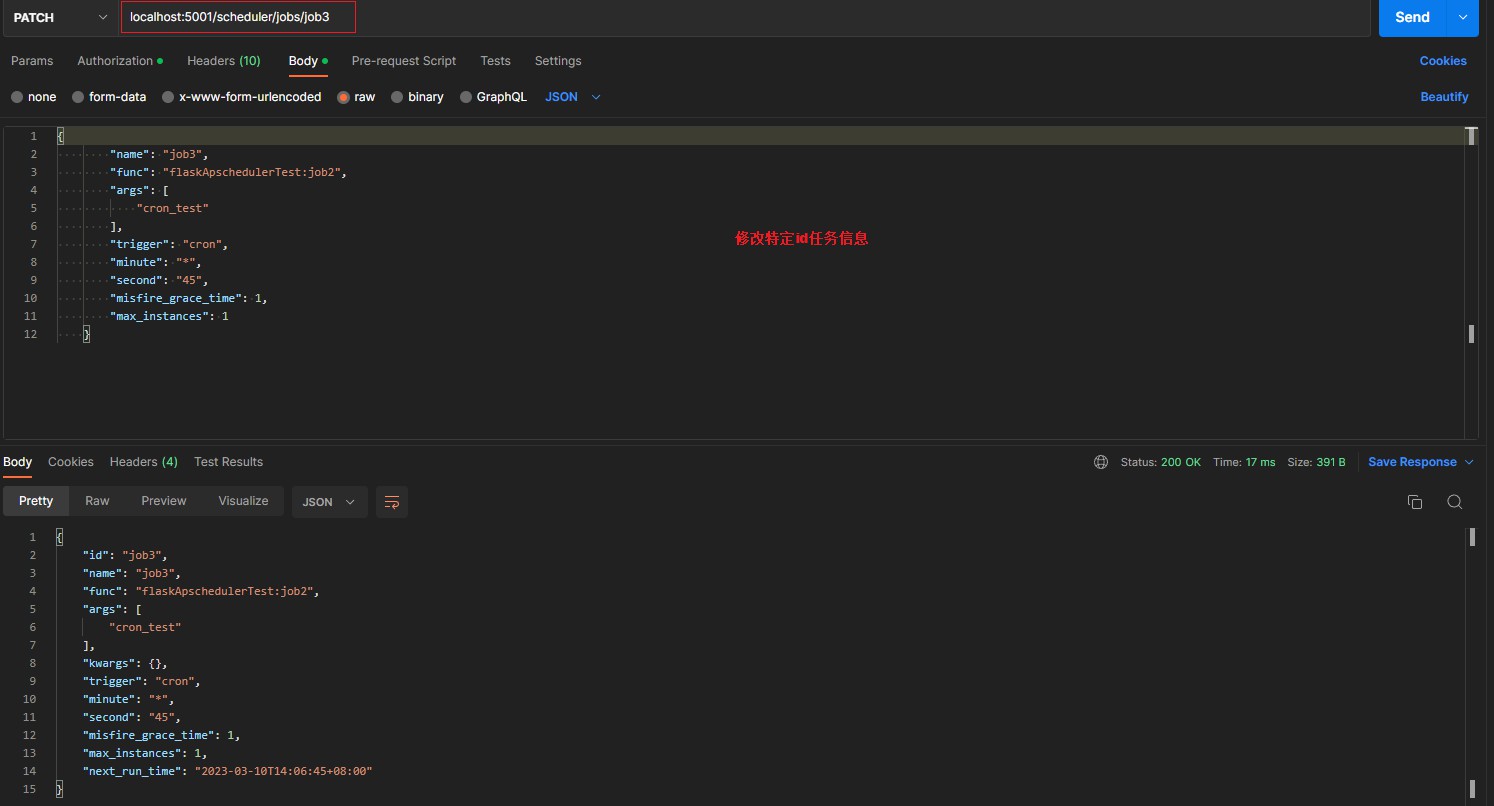
/scheduler/jobs/<job_id> [PATCH json job data] > updates an already existing job > 修改特定任务配置信息(需要入参 id参数不传 类型json)
{
"name": "job3",
"func": "flaskApschedulerTest:job2",
"args": [
"cron_test"
],
"trigger": "cron",
"minute": "*",
"second": "45",
"misfire_grace_time": 1,
"max_instances": 1
}
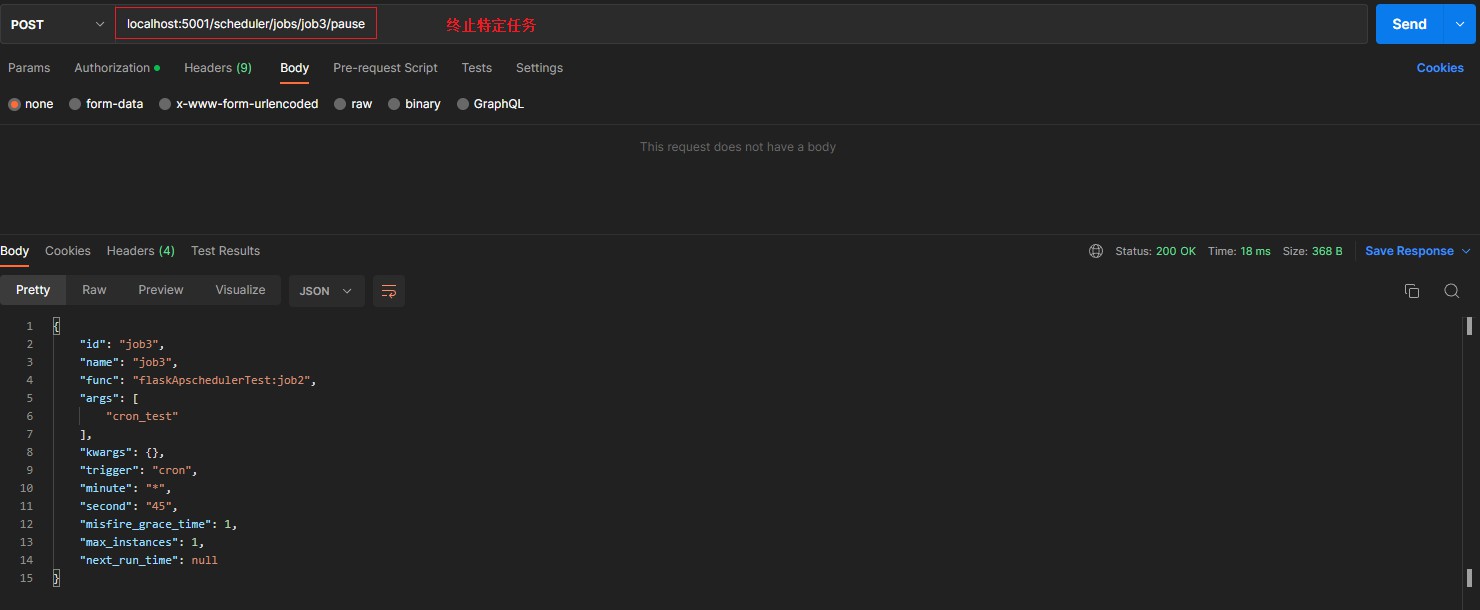
/scheduler/jobs/<job_id>/pause [POST] > pauses a job, returns json of job details > 终止特定任务
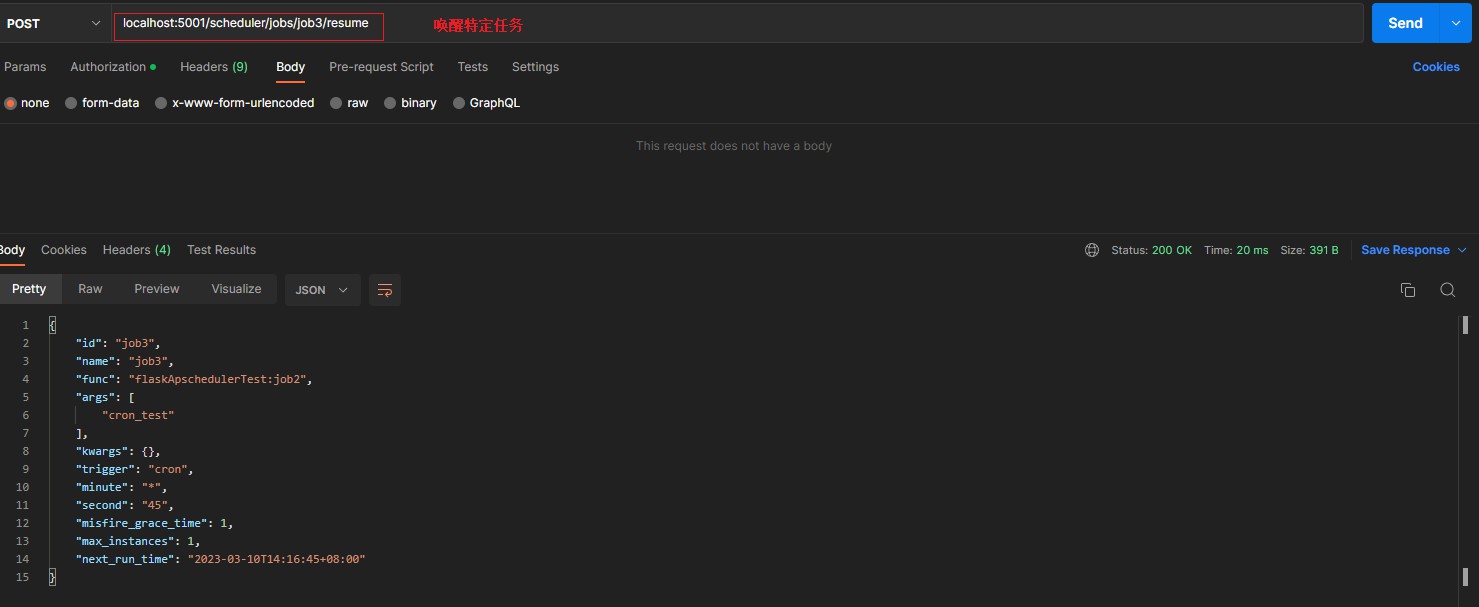
/scheduler/jobs/<job_id>/resume [POST] > resumes a job, returns json of job details > 唤醒特定任务
/scheduler/jobs/<job_id>/run [POST] > runs a job now, returns json of job details > 立即运行特定任务
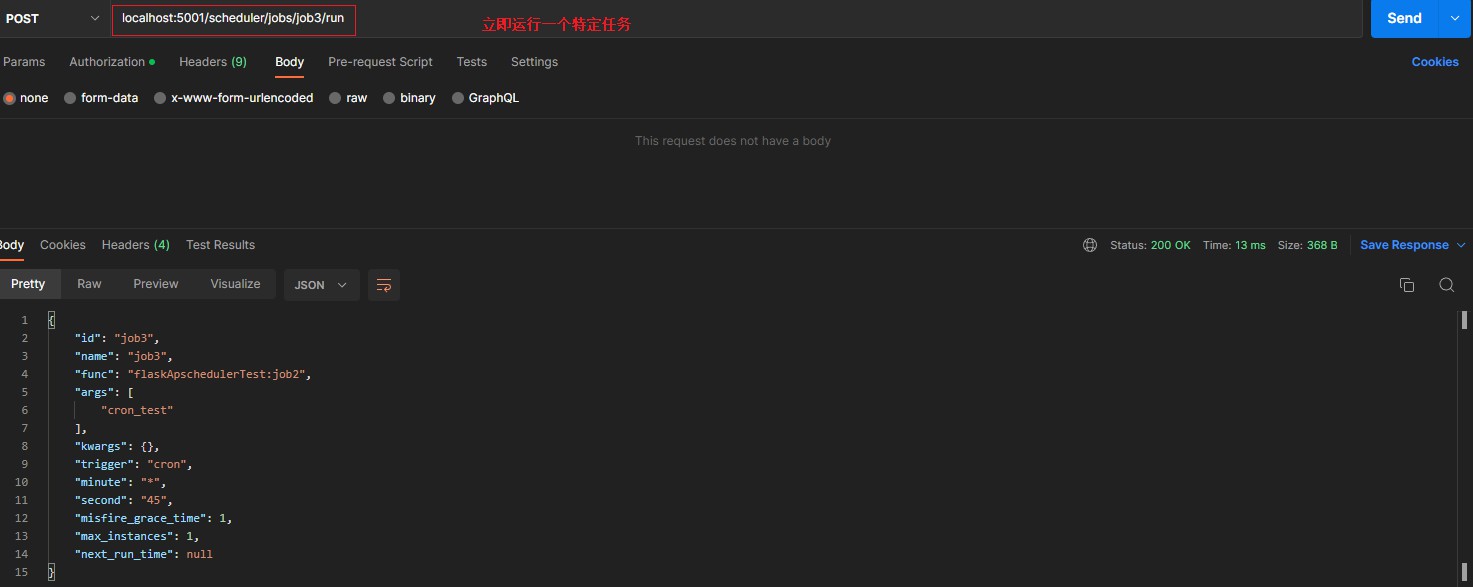
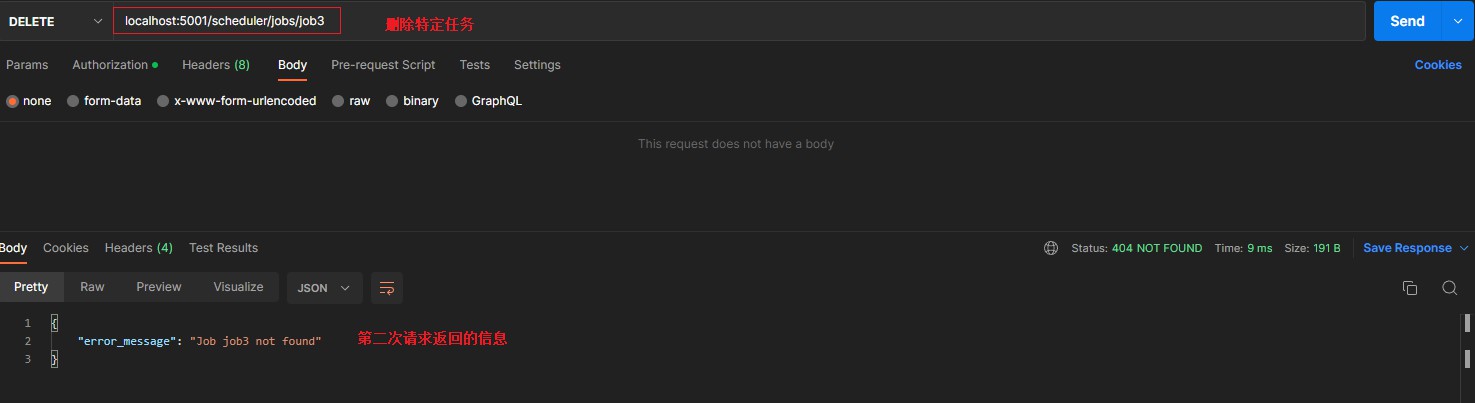
5.3 常用方法
scheduler.start() > 调度器运行=运行jobstores的任务
scheduler.shutdown(wait=False) > 默认为true 等待其他任务完成
scheduler.pause() > 停止所有任务 正在运行的不受影响
scheduler.resume() > 唤醒任务
scheduler.add_listener(<callback function>,<event>) > 添加任务监听事件
scheduler.remove_listener(<callback function>) > 移除监听事件
scheduler.add_job(<id>,<function>, **kwargs) > 添加任务
scheduler.remove_job(<id>, **<jobstore>) > 移除任务
scheduler.remove_all_jobs(**<jobstore>) > 移除所有
scheduler.get_job(<id>,**<jobstore>) > 获取任务信息
scheduler.get_jobs() > 获取所有任务信息
scheduler.modify_job(<id>,**<jobstore>, **kwargs) > 修改任务信息
scheduler.pause_job(<id>, **<jobstore>) > 中止任务
scheduler.resume_job(<id>, **<jobstore>) > 唤醒任务
scheduler.run_job(<id>, **<jobstore>) > 运行任务
scheduler.authenticate(<function>) > 认证
6. 实例
6.1 实例1
# -*- coding:utf-8 -*-
"""
pip install Flask-APScheduler
"""
import datetime
import time
from apscheduler.jobstores.mongodb import MongoDBJobStore
from apscheduler.jobstores.redis import RedisJobStore
from apscheduler.schedulers.background import BackgroundScheduler
from flask import Flask
from flask_apscheduler import APScheduler
from flask_apscheduler.auth import HTTPBasicAuth
class Config:
# 任务集
JOBS = [
{
"id": "job1", # 任务id
"func": "flaskApschedulerTest:job1", # 前面是job所处python文件的地址:后面不能有空字符
"args": (1, 2), # 执行函数参数
"trigger": "interval", # 触发器
"seconds": 10,
'replace_existing': True
},
{
"id": "job2",
'func': 'flaskApschedulerTest:job2',
'args': ("cron",),
"trigger": "cron",
'minute': "*",
"second": 15,
'replace_existing': True
}
]
# 任务信息储存器
SCHEDULER_JOBSTORES = {
'default': MongoDBJobStore(host="127.0.0.1", port=27017, database="cronJob", collection="job"),
# 'default': RedisJobStore(host='127.0.0.1', port=6379, db=10, password='')
}
# 执行器配置
SCHEDULER_EXECUTORS = {"default": {"type": "threadpool", "max_workers": 20}}
# 执行任务配置
SCHEDULER_JOB_DEFAULTS = {"coalesce": True, "max_instances": 1}
# API访问认证
SCHEDULER_AUTH = HTTPBasicAuth()
# API访问路径
SCHEDULER_API_PREFIX = '/scheduler'
# API访问开启
SCHEDULER_API_ENABLED = True
# 时区
SCHEDULER_TIMEZONE = 'Asia/Shanghai'
# HOST白名单
SCHEDULER_ALLOWED_HOSTS = ["*"]
def job1(var_one, var_two):
"""Demo job function.
:param var_two:
:param var_two:
"""
time.sleep(3)
print(datetime.datetime.now(), str(var_one) + " " + str(var_two))
def job2(name):
print(datetime.datetime.now(), f" {name}")
if __name__ == "__main__":
app = Flask(__name__)
app.config.from_object(Config())
scheduler = APScheduler(BackgroundScheduler(timezone='Asia/Shanghai'))
scheduler.init_app(app)
scheduler.start()
@scheduler.authenticate
def authenticate(auth):
"""Check auth"""
return auth["username"] == "guest" and auth["password"] == "guest"
# print(scheduler.get_jobs())
app.run(host='0.0.0.0', port=5001, use_reloader=False)
6.1 实例2
#--cron
#--cron/task/task1.py
#--app.py
#--config.py
#--__init__.py
# task1.py
import datetime
import time
from multiprocessing import Process
def task_1(name):
time.sleep(10)
print(f"{name} running " + str(datetime.datetime.now()))
def run():
pl = [Process(target=task_1, args=(str(s) + "_task1", )) for s in range(3)]
for p in pl:
p.start()
for p in pl:
p.join()
print(">>>>执行下面的进程了1")
p = Process(target=task_1, args=("my1", ))
p.start()
p.join()
print(">>>>执行下面的进程了2")
p = Process(target=task_1, args=("my2",))
p.start()
p.join()
#__init__.py
import atexit
import platform
from apscheduler.schedulers.background import BackgroundScheduler
from flask_apscheduler import APScheduler
from config import Config
scheduler = APScheduler(BackgroundScheduler(timezone='Asia/Shanghai'))
def create_app(config=Config):
from flask import Flask
app = Flask(__name__)
app.config.from_object(config)
scheduler_init(app)
return app
def scheduler_init(app):
"""
保证系统只启动一次定时任务
:param app: 当前flask实例
:return: None
"""
if platform.system() != 'Windows':
fcntl = __import__("fcntl")
f = open('scheduler.lock', 'wb')
try:
fcntl.flock(f, fcntl.LOCK_EX | fcntl.LOCK_NB)
scheduler.init_app(app)
scheduler.start()
except:
pass
def unlock():
fcntl.flock(f, fcntl.LOCK_UN)
f.close()
atexit.register(unlock)
else:
msvcrt = __import__('msvcrt')
f = open('scheduler.lock', 'wb')
try:
msvcrt.locking(f.fileno(), msvcrt.LK_NBLCK, 1)
scheduler.init_app(app)
scheduler.start()
except:
pass
def _unlock_file():
try:
f.seek(0)
msvcrt.locking(f.fileno(), msvcrt.LK_UNLCK, 1)
except:
pass
atexit.register(_unlock_file)
# config.py
from apscheduler.jobstores.redis import RedisJobStore
class Config:
# 任务集
JOBS = [
{
"id": "my_job1", # 任务id
"func": "web.cron.task.task1:run",
"trigger": "interval",
"seconds": 1,
'replace_existing': True,
},
{
"id": "my_job2", # 任务id
"func": "web.cron.task.task1:task_1",
"trigger": "interval",
"args": ("my_job2", ),
"seconds": 3,
'replace_existing': True,
}
]
# 任务信息储存器
SCHEDULER_JOBSTORES = {
# 'default': MongoDBJobStore(host="127.0.0.1", port=27017, database="cronJob", collection="job"),
'default': RedisJobStore(host='127.0.0.1', port=6379, db=10, password=''),
# 'default': SQLAlchemyJobStore(url="mysql://root:python@localhost:3306/cron_job?charset=utf8"),
}
# 执行器配置
SCHEDULER_EXECUTORS = {"default": {"type": "threadpool", "max_workers": 20}}
# 执行任务配置
SCHEDULER_JOB_DEFAULTS = {"coalesce": True, "max_instances": 1}
# API访问路径
SCHEDULER_API_PREFIX = '/scheduler'
# API访问开启
SCHEDULER_API_ENABLED = True
# 时区
SCHEDULER_TIMEZONE = 'Asia/Shanghai'
# HOST白名单
SCHEDULER_ALLOWED_HOSTS = ["*"]
# app.py
from web.cron import create_app
app = create_app()
if __name__ == '__main__':
app.run(use_reloader=False)
7. 参考文档


