项目交付时遇到的一些问题及反思
在某地出差做实施的时候,把以前没遇到过的坑都遇到了,每天都在怀疑自己能力有问题。
1.k8s pod网络不通。
这个问题特别诡异,部署了两个pod,会有一个网络出现问题,ping 不通docker网关,ping不通svc地址,ping不通其他pod 的ip。
pod-A通,pod-B不通。过几分钟变成了pod-A网络不通,pod-B网络通。
尝试过的方法:
最开始安装的是k8s1.18.16,使用默认的calico网络插件的ipip模式,后修改为bgp模式,失败
将calico改为flannel,失败。
怀疑版本问题,将k8s升级到1.19.8,使用calico cni的ipip模式,修改为bgp模式,改为用flannel,失败。
怀疑机房网络有限制,联系机房网络人员对接,回复无任何限制。
找了几个k8s大佬指导,也无效果。
仔细排查发现,pod出现网络问题都是在k8sn3这台机器上,再一检查,这台机器内核升级失败了,还是默认的3.10.x,其余机器均为5.8.x,升级内核后
问题解决。
总结就是,要细心啊。
2.基础不牢固
由于默认不能访问互联网如微信登录等网页的权限,所以需要走申请。机房开通后宿主机可以访问外网,而k8s里不行。
正常情况下,k8s cni不管使用什么插件,都要通过宿主机的网卡进行转发的。怀疑机房做的策略特别严格,还需要对
k8s的网段100.64.0.0/10做策略,机房说这个网段和其他业务有冲突,要求修改为 101.200.0.0/24。于是在网上查如何修改calico
,官方说需要删除所有旧的pod才能生效,那我还不如重装呢。于是重装k8s,重新部署。又浪费一天时间。
哪里基础不牢固呢?
kubectl edit ds calico-node -n kube-system
查到了calico的网段是value: 100.64.0.0/10,但是查看k8s的pod有 100.68.x.x、100.79.x.x,就觉得这不准啊。
后来被大佬教育了一番,通过ip计算机去计算这个网段,发现这些ip地址确实都是包含在内的。
总结就是,基础太差了,好好学习吧。
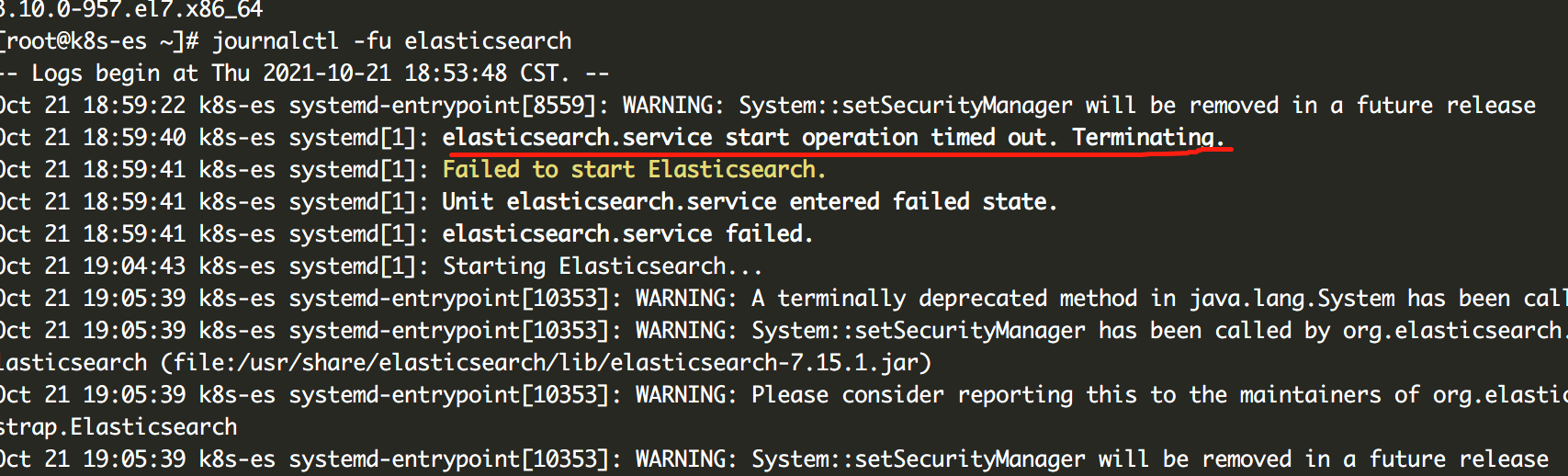
3.elasticsearch启动失败
在其他城市使用过无数次的安装方法,到这里就是启动不了。换rpm包,换自带的jdk、换启动用户,换配置文件都不好使。
后来自己查看了报错,在网上找到了,居然是启动时间太长,超过了预设的超时时间,于是启动失败。修改超时时间即可。。。
https://terryl.in/zh/elasticsearch-service-start-operation-timed-out/
elasticsearch.service: Start operation timed out. Terminating.
4.rocketmq集群异常。
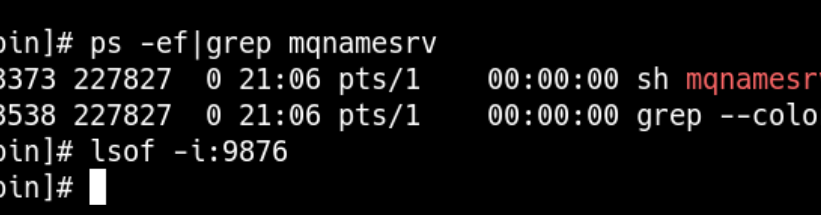
反馈短信发不出去了,在mq控制台查看发现消息挤压严重。将defaultTopicQueueNums设置到20,发现rocketmq启动不了了,没有任何日志,9876端口也未监听。
震惊了,完全没遇到过这的问题,于是打算在k8s里部署了一套应急,结果服务器上不了网,迟迟拉不到镜像。于是生产环境使用测试环境的mq先将就着用。
后来无意中发现,9876端口又处于监听状态了。于是再测试一次nohup sh mqnamesrv & 启动namesrv,过了5分钟居然启起来了!!!再启broker,又等了差不多5分钟,又起起来了。但是,问题并没有解决。,于是尝试在控制台修改了defaultTopicQueueNums,修改以后积压的问题解决了。
网上查资料才知道,有数据以后再修改这个参数是不生效的,只能在控制台修改。
https://www.jianshu.com/p/ccdf6fc710b0

activemq控制台修改密码不生效
参考的是官方文档,https://activemq.apache.org/web-console
照着修改以后无效
开始去github,stackoverflow、google各种查资料,把甚至把代码注释掉也不好使。
即activemq.xml里的删掉都无效。
<import resource="${activemq.base}/conf/jetty.xml" />
深深的怀疑自己的能力,最后无意间ps -ef查看进程,发现有七八个进程,才发现每次重启都没生效,深深的震惊了我。
使用 ./activemq stop && ./activqmq start 居然重启无效果!!!
所有进程kill掉再启动,问题解决。
未完待续

 浙公网安备 33010602011771号
浙公网安备 33010602011771号