Mongodb 之 oplog
一开始我就以为 oplog 应该就类似于 mysql bin-log 而事实上,确实差不多。oplog 也是用于复制集间由 Primary 记录,Secondary 用来同步。从而保持数据一致。
最近遇到了误删db(删库不能跑路)的事情,所以,实验了N多次的 oplog 恢复数据。
特地记录一下,以备后查。
# ------------------------------ oplog ---------------------------------
## 1. 在复制集中使用 oplog ,可以使用以下命令查看oplog情况:
rpset1:PRIMARY> rs.printReplicationInfo()
configured oplog size: 10240MB
log length start to end: 149092secs (41.41hrs)
oplog first event time: Sun Apr 26 2020 20:25:46 GMT+0800 (CST)
oplog last event time: Tue Apr 28 2020 13:50:38 GMT+0800 (CST)
now: Tue Apr 28 2020 13:50:38 GMT+0800 (CST)
rpset1:SECONDARY> rs.printReplicationInfo()
configured oplog size: 10240MB
log length start to end: 149937secs (41.65hrs)
oplog first event time: Sun Apr 26 2020 20:10:59 GMT+0800 (CST)
oplog last event time: Tue Apr 28 2020 13:49:56 GMT+0800 (CST)
now: Tue Apr 28 2020 13:49:56 GMT+0800 (CST)
rpset1:SECONDARY> rs.printReplicationInfo()
configured oplog size: 10240MB
log length start to end: 148635secs (41.29hrs)
oplog first event time: Sun Apr 26 2020 20:32:00 GMT+0800 (CST)
oplog last event time: Tue Apr 28 2020 13:49:15 GMT+0800 (CST)
now: Tue Apr 28 2020 13:49:16 GMT+0800 (CST)
# 配置文件 conf/slave.conf 中的oplogSize
replication:
oplogSizeMB: 10240
replSetName: rpset1
从以上的命令中可以看出,这个复制集的 oplog 有41小时的容量,而这个 mongodb 每天都有定时备份。所以,这个容量肯定是够用了。
使用 oplogReplay 恢复数据,官文说必须要有一个特殊的权限。
## 2. 创建专门的角色使用 oplogReplay 此角色必须有 anyResource 和 anyAction # 备份时不需要此权限,但恢复时必须要有此权限,否则恢复失败且没有报错信息。 use admin db.createRole( { "role" : "sysadmin", "privileges" : [{ "resource" : {"anyResource" : true}, "actions" : ["anyAction"] }], "roles" : [] } ) # 创建专门的用户使用此角色 db.createUser({user:"admin", pwd:"admin", roles:[{role:"sysadmin", db:"admin"}]}) # 或者授权某个用户 db.grantRolesToUser( "root" , [ { role: "sysadmin", db: "admin" } ])
检查一下定时备份db的命令,找到如下:
## 3. 日常全量备份 ./mongodump -h 10.170.6.116:27017 -u admin -p admin --authenticationDatabase admin --gzip -o /data/tmp/rs0 # 备份时如果有 --oplog 选项,输出目录下就会有 oplog.bson 文件 # ./mongodump -h 10.170.6.116:27000 -u rsroot -p abcd1234 --authenticationDatabase admin --oplog -o /data/tmp/rs0
因为备份时没有带 --oplog 参数,所以进行恢复时,使用先恢复备份,再 oplogReplay的方式完成,也就是参考下面的第9点。
而4到8点,用来在恢复备份的同时带上 oplogReplay 的方式。
## 4. 假设上次日常备份之后的某个时间点出现了误删除操作,就需要利用 oplogReplay 来恢复这段时间的新数据 # 先检查上次日常备份的时间点(如果 dump 时使用了 --oplog 参数,就会有oplog.bson文件。如果没有,可参考第9条): ./bsondump /data/tmp/rs0/oplog.bson > /data/tmp/0 cat /data/tmp/0 # 找到第一行 {"ts":{"$timestamp":{"t":1588138496,"i":1}}, ...
# 字段的意思:
ts: 操作发生的时间,t: unix时间戳, i: 可以认为是同一时间内的第几个. h: 记录的唯一ID v: 版本信息 op: 写操作的类型 n: no-op c: db cmd i: insert u: update d: delete ns: 操作的namespace, 即: 数据库.集合 o: 操作所对应的文档 o2: 更新时所对应的where条件,更新时才有
# 起始时间戳可自由指定,不必oplog中找记录。稍微早于需要的时间点即可。
./mongodump -h 192.168.6.116:27017 -u admin -p admin --authenticationDatabase admin -d local -c oplog.rs -q '{"ts":{"$gt": {"$timestamp":{"t":1588138300,"i":1}}}}' -o /data/tmp/rs1
## 5. 导出当前的 local/oplog.rs 注意 -q 选项的 JSON格式 # 因为备份整个 local/oplog.rs 容量太大,恢复也会耗时过长,所以采用起始时间的方式: ./mongodump -h 192.168.6.116:27017 -u admin -p admin --authenticationDatabase admin -d local -c oplog.rs -q '{"ts":{"$gt": {"$timestamp":{"t":1588138393,"i":1}}}}' -o /data/tmp/rs1 # 也可以同时指定结束时间,如下: ./mongodump -h 192.168.6.116:27017 -u rsroot -p abcd1234 --authenticationDatabase admin -d local -c oplog.rs -q '{"ts":{"$lte": {"$timestamp":{"t":1588142111,"i":1}}, "$gte": {"$timestamp":{"t":1588138393,"i":1}}}}' -o /data/tmp/rs2 # 也可以使用 --queryFile=./n.json 的方式,指定查询文件(可能4.0.7以下版本会有错误提示)
{"ts":{"$gte": {"$timestamp":{"t":1589042338,"i":1}}}, "ns":{"$not": {"$regex": "test.names"}}}
# -q 参数示例:
-q '{"ts":{"$gte": {"$timestamp":{"t":1589342458,"i":1}}}, "ns":{"$nin":["test.tlog","config.system.sessions"]}}' -q '{"ts":{"$gte": {"$timestamp":{"t":1589342458,"i":1}}}, "lsid":{"$exists": false }}'
## 6. 检查 oplog.rs.bson 手工找出误删除的时间戳: ./bsondump /data/tmp/rs1/local/oplog.rs.bson > /data/tmp/1 # 打开 /data/tmp/1 手工查找,如果有删除表或库,则有 drop 信息, 如果有删除数据,则有 "op":"d" 信息 ## 7. 替换日常全备份中的 oplog.bson rm -rf /data/tmp/rs0/oplog.bson mv /data/tmp/rs1/local/oplog.rs.bson /data/tmp/rs0/oplog.bson ## 8. 执行恢复命令(注意用户权限) ./mongorestore -h 192.168.6.116:27017 -u admin -p admin --authenticationDatabase admin --oplogReplay --oplogLimit "1588232764:1" --dir /data/tmp/rs0/ # 其中 1588232764 即是 $timestamp 中的"t",1 即是 $timestamp 中的 "i" 这样配置后oplog将会 # 重放到这个时间点以前,即正好避开了第一条删除语句及其后面的操作,数据库停留在灾难前状态 ## 9. 如果日常备份没有 --oplog 并且使用了 --gzip,可以先恢复此备份。 # 然后再使用oplogReplay 指定单独的 oplog.rs.bson 文件进行恢复. ./mongorestore -h 192.168.6.116:27017 -u admin -p admin --authenticationDatabase admin /data/tmp/rs0/ --gzip ./mongorestore -h 192.168.6.116:27017 -u admin -p admin --authenticationDatabase admin --oplogReplay --oplogLimit "1588232764:1" /data/tmp/rs1/local/oplog.rs.bson
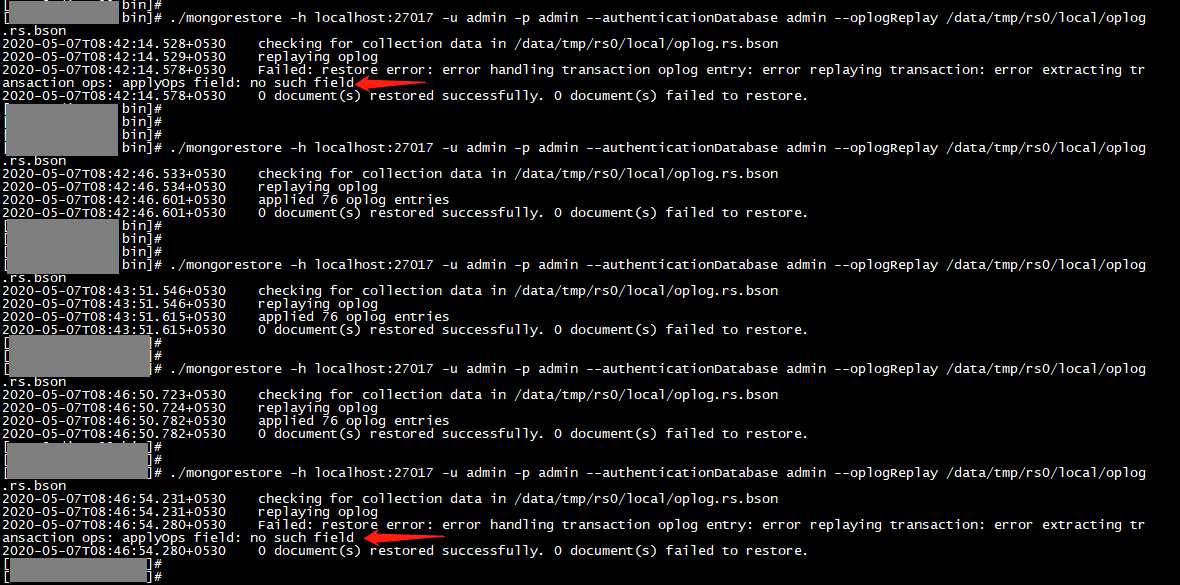
# 有可能恢复时不成功,提示 “ applyOps field: no such field ” ,此时,只能使用上面的第8步的方式试试了。
不必担心数据混乱。因为 oplog 的幂等性,即使多次Replay 也不会产生重复数据。 已存在相同的 _id,即使其它字段不同,也不会恢复,不存在的 _id 则会恢复。
当然,也可以将备份和oplog恢复到某台单机上,再使用导出导入的方法将数据移到生产环境。
试验往单机恢复的时候,同一个命令执行多次,有时出错有时成功,就不知道为什么了。操作时只能是多试几次了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号