Logistic回归
Logistic回归和线性回归虽然都带有回归,梯度下降,损失函数,求取预测值的方法虽然很相似,但是它却是一个实打实的分类算法。
因为是分类算法,所以逻辑斯特回归预测的是样本为某一分类的概率,所以预测值的范围为0<=hθ(x)<=1;
分布函数如下图
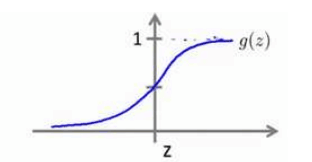
由此得出逻辑斯特的预测函数
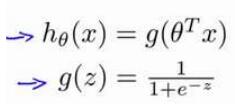
在逻辑斯特回归中,我们预测:
当hθ(x)>=0.5时,预测y=1,这时z>=0;
当hθ(x)<0.5是,预测y=0,这时z<0;
线性回归的代价函数并不适用与逻辑斯特回归,因为我们将hθ(x)带入进去的时候,得到的是一个非凸函数,这意味着我们的代价函数有着愈多的局部最优解,会影响梯度下降算法找到全局的最优解。
所以我们从新定义逻辑斯特回归的代价函数为: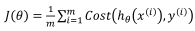 ,其中
,其中
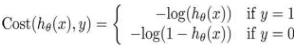
ℎ 𝜃 (x)与Cost(ℎ 𝜃 (x),y)之间的关系如下图所示
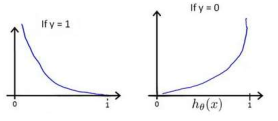
这个代价函数的意思是这样的当你的原值为0而预测值为1时,这时候这个概率是很小的,换言之,你想让0变成一所需要的代价是无穷大的。当原值为1时同样。
在这里我们可以将Cost函数整合成一个更简单的函数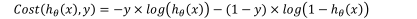
带入到代价函数中得到: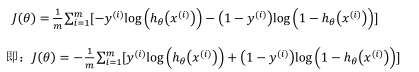
在这里,我们最小化代价函数的方法还是使用梯度下降法,至于具体的流程,他和线性回归里的梯度下降是一样的,读这篇博客的博友可以去我之前写的线性回归中看,我在此就不重复写了。同时,特征缩放在逻辑斯特回归中也是可以使用的。
逻辑斯特回归不止适用于两类分类问题,还适用于多类分类问题。
在面对多分类问题时,我们可以将此转化为一对多的问题,并且拟合多个分类器。
hθ(i)(x),其中的i对应每一个可能的分类y=i,最后,为了做出预测,我们给出输入一个新的x值,用这个做预测。我们要做的就是在我们多个分类器里面输入x,然后我们选择一个让hθ(i)(x)最大的i。
在最后,贴出一个代价函数J(θ)的python实现代码
import numpy as np def cost(theta,X,y): theta=np.matrix(theta)#根据theta创建出一个矩阵 X=np.matrix(X) y=np.matrix(y) first=np.multiply(-y,np.log(sigmoid(X*theta.T)))#multiply数组和矩阵对应位置相乘,输出与相乘数组/矩阵的大小一致 second=np.multiplyy((1-y),np.log(1-sigmoid(X*theta.T))) return np.sum(first-second)/(len(X))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号