【服务器数据恢复】nas存储服务器raid6数据恢复案例
摘要: 服务器数据恢复环境:
nas存储服务器,14块硬盘组建raid6磁盘阵列。
服务器故障&分析:
服务器在正常运行过程中突然有硬盘出现故障离线,导致磁盘阵列失效,服务器无法正常访问了。
北亚数据恢复工程师首先对故障服务器内的所有硬盘的底层数据进行了检测,发现服务器的磁盘阵列虽然已经失效,但thin-lvm结构及thin-lv尚未被破坏,数据可以恢复。thin-lvm算法结构的复杂性决定了恢复数据的难度比较大。
阅读全文
服务器数据恢复环境:
nas存储服务器,14块硬盘组建raid6磁盘阵列。
服务器故障&分析:
服务器在正常运行过程中突然有硬盘出现故障离线,导致磁盘阵列失效,服务器无法正常访问了。
北亚数据恢复工程师首先对故障服务器内的所有硬盘的底层数据进行了检测,发现服务器的磁盘阵列虽然已经失效,但thin-lvm结构及thin-lv尚未被破坏,数据可以恢复。thin-lvm算法结构的复杂性决定了恢复数据的难度比较大。
阅读全文
服务器数据恢复环境:
nas存储服务器,14块硬盘组建raid6磁盘阵列。
服务器故障&分析:
服务器在正常运行过程中突然有硬盘出现故障离线,导致磁盘阵列失效,服务器无法正常访问了。
北亚数据恢复工程师首先对故障服务器内的所有硬盘的底层数据进行了检测,发现服务器的磁盘阵列虽然已经失效,但thin-lvm结构及thin-lv尚未被破坏,数据可以恢复。thin-lvm算法结构的复杂性决定了恢复数据的难度比较大。
阅读全文
posted @ 2022-11-30 10:37
 服务器数据恢复环境:
惠普ML系列某型号塔式服务器,5块SAS硬盘组建raid5磁盘阵列。
服务器故障&分析:
服务器中的一块硬盘掉线,由于磁盘阵列的冗余特性,服务器正常运行,用户没有察觉。直到另外一块硬盘掉线,服务器崩溃。用户联系我们要求恢复存储在服务器中的设计素材及客户数据。
北亚服务器数据恢复工程师检测故障服务器的底层数据,没有发现明显的同步痕迹。
服务器数据恢复环境:
惠普ML系列某型号塔式服务器,5块SAS硬盘组建raid5磁盘阵列。
服务器故障&分析:
服务器中的一块硬盘掉线,由于磁盘阵列的冗余特性,服务器正常运行,用户没有察觉。直到另外一块硬盘掉线,服务器崩溃。用户联系我们要求恢复存储在服务器中的设计素材及客户数据。
北亚服务器数据恢复工程师检测故障服务器的底层数据,没有发现明显的同步痕迹。
 服务器数据恢复环境:
北京某公司IBM X系列某型号服务器;
服务器上共8块硬盘组建raid5磁盘阵列;
服务器上部署有oracle数据库。
服务器故障&分析:
服务器在运行过程中,raid5磁盘阵列中有2块硬盘报警,服务器操作系统启动不了,服务器上部署的ORACLE数据库无法启动,用户联系我们数据恢复中心要求恢复服务器的数据。
RAID5最多只能允许有一块硬盘离线,若有第二块磁盘离线,RAID5磁盘阵列便会崩溃,不能正常工作。在用户确认之前还没有第二块硬盘离线,所以初步认定RAID卡上的RAID信息可能已经丢失或破坏。
服务器数据恢复环境:
北京某公司IBM X系列某型号服务器;
服务器上共8块硬盘组建raid5磁盘阵列;
服务器上部署有oracle数据库。
服务器故障&分析:
服务器在运行过程中,raid5磁盘阵列中有2块硬盘报警,服务器操作系统启动不了,服务器上部署的ORACLE数据库无法启动,用户联系我们数据恢复中心要求恢复服务器的数据。
RAID5最多只能允许有一块硬盘离线,若有第二块磁盘离线,RAID5磁盘阵列便会崩溃,不能正常工作。在用户确认之前还没有第二块硬盘离线,所以初步认定RAID卡上的RAID信息可能已经丢失或破坏。
 云服务器数据恢复环境:
某云ECS网站服务器,linux操作系统,mysql数据库。
云服务器故障情况:
在执行mysql数据库版本更新测试时,将本应在测试库执行的sql脚本错误地在生产库中执行,部分表被truncate,部分表内的少量数据被delete。该实例内数据表均采用innodb作为默认存储引擎。
云服务器数据恢复环境:
某云ECS网站服务器,linux操作系统,mysql数据库。
云服务器故障情况:
在执行mysql数据库版本更新测试时,将本应在测试库执行的sql脚本错误地在生产库中执行,部分表被truncate,部分表内的少量数据被delete。该实例内数据表均采用innodb作为默认存储引擎。
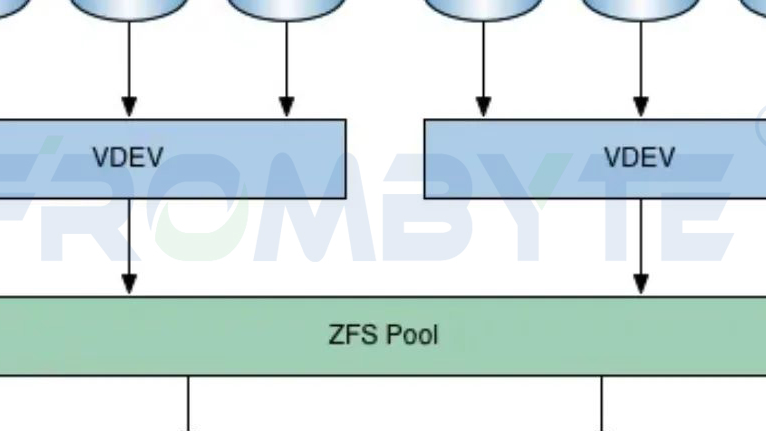 服务器数据恢复环境:
一台采用zfs文件系统的服务器,配备32块硬盘。
服务器故障:
服务器在运行过程中崩溃,经过初步检测没有发现服务器有物理故障,重启服务器后故障依旧,用户联系我们中心要求恢复服务器数据。
服务器数据恢复环境:
一台采用zfs文件系统的服务器,配备32块硬盘。
服务器故障:
服务器在运行过程中崩溃,经过初步检测没有发现服务器有物理故障,重启服务器后故障依旧,用户联系我们中心要求恢复服务器数据。
 Linux误删除及误格式化的数据恢复方案针对的文件系统:
1 、基于EXT2/EXT3/EXT4文件系统 ;
2 、基于Reiserfs文件系统;
3 、基于Xfs文件系统。
Linux误删除及误格式化的数据恢复方案针对的文件系统:
1 、基于EXT2/EXT3/EXT4文件系统 ;
2 、基于Reiserfs文件系统;
3 、基于Xfs文件系统。
 服务器数据恢复环境:
一台HP EVA某型号存储设备;
共23块硬盘,上层映射给一台windows系统服务器。
服务器故障情况:
存储设备有三块硬盘的指示灯变黄色,存储设备还在正常运行。管理员在更换亮黄灯的故障硬盘过程中,存储设备中又有一块硬盘的指示变黄离线,这时存储设备已经不可用了。
服务器数据恢复环境:
一台HP EVA某型号存储设备;
共23块硬盘,上层映射给一台windows系统服务器。
服务器故障情况:
存储设备有三块硬盘的指示灯变黄色,存储设备还在正常运行。管理员在更换亮黄灯的故障硬盘过程中,存储设备中又有一块硬盘的指示变黄离线,这时存储设备已经不可用了。
 移动硬盘常见故障情况和解决方法:
1、硬盘本身没有问题,数据线、硬盘盒或接口卡问题。
2、硬盘质量问题,固件损坏或出现坏道。
3、人为导致移动硬盘无法工作或损坏。
移动硬盘常见故障情况和解决方法:
1、硬盘本身没有问题,数据线、硬盘盒或接口卡问题。
2、硬盘质量问题,固件损坏或出现坏道。
3、人为导致移动硬盘无法工作或损坏。
 经常使用电脑和移动硬盘的用户,如果察觉到电脑运行速度变得很慢,即使做了磁盘整理和系统重装操作后速度还是没有恢复到正常状态,这个时候就要小心是硬盘盘片出现坏道了。
如果这个时候用硬盘检测软件扫描硬盘就会发现扫描界面上出现很多绿块,也有可能出现褐色或红色的色块,这就表明硬盘已经或即将出现坏道,那么什么是硬盘坏道?
经常使用电脑和移动硬盘的用户,如果察觉到电脑运行速度变得很慢,即使做了磁盘整理和系统重装操作后速度还是没有恢复到正常状态,这个时候就要小心是硬盘盘片出现坏道了。
如果这个时候用硬盘检测软件扫描硬盘就会发现扫描界面上出现很多绿块,也有可能出现褐色或红色的色块,这就表明硬盘已经或即将出现坏道,那么什么是硬盘坏道?
 服务器数据恢复环境:
5台服务器节点,每台服务器节点配置一组RAID5,每组6块硬盘,其中1块设置为热备盘。
系统环境为Lustre分布式文件系统,5台服务器共同存储全部的数据文件。
服务器故障&检测:
机房漏水导致服务器进水,服务器中的部分硬盘损坏。每组服务器有2块及以上的盘掉线。由于短时间同时掉线2块及以上硬盘导致RAID5崩溃,服务器,数据无法正常读取。
服务器数据恢复环境:
5台服务器节点,每台服务器节点配置一组RAID5,每组6块硬盘,其中1块设置为热备盘。
系统环境为Lustre分布式文件系统,5台服务器共同存储全部的数据文件。
服务器故障&检测:
机房漏水导致服务器进水,服务器中的部分硬盘损坏。每组服务器有2块及以上的盘掉线。由于短时间同时掉线2块及以上硬盘导致RAID5崩溃,服务器,数据无法正常读取。
 SQL SERVER数据库故障类型:
MDF(NDF)或LDF损坏。
SQL SERVER故障原因:
1、数据库正在操作过程中,机器突然断电;
2、人为误操作。
SQL SERVER数据库故障类型:
MDF(NDF)或LDF损坏。
SQL SERVER故障原因:
1、数据库正在操作过程中,机器突然断电;
2、人为误操作。
 数据库数据恢复环境:
合肥某大学一台安装redhat linux操作系统的服务器,采用ext3文件系统,服务器部署有mysql数据库用来存储&管理教职员工和学生的信息。
编写好的脚本每天会定时将数据库文件打包成tar.gz备份到本地磁盘的其他分区并删除前一天的备份文件。
数据库故障&分析:
服务器遭受攻击,所有数据库文件(包括备份)被恶意删除。
本案例是ext3文件系统数据被删除,若删除的文件数量比较少且删除后没有或者只有很少的写入,恢复出数据的概率比较高。
数据库数据恢复环境:
合肥某大学一台安装redhat linux操作系统的服务器,采用ext3文件系统,服务器部署有mysql数据库用来存储&管理教职员工和学生的信息。
编写好的脚本每天会定时将数据库文件打包成tar.gz备份到本地磁盘的其他分区并删除前一天的备份文件。
数据库故障&分析:
服务器遭受攻击,所有数据库文件(包括备份)被恶意删除。
本案例是ext3文件系统数据被删除,若删除的文件数量比较少且删除后没有或者只有很少的写入,恢复出数据的概率比较高。
 服务器数据恢复环境:
infortrend某型号存储;
12块硬盘组成RAID6,一个GPT分区文件系统为NTFS。
服务器故障:
3块硬盘离线后强制激活并做了REBUILD,数据出错。
服务器数据恢复环境:
infortrend某型号存储;
12块硬盘组成RAID6,一个GPT分区文件系统为NTFS。
服务器故障:
3块硬盘离线后强制激活并做了REBUILD,数据出错。
 xen server常见故障:
1、sr无法识别,所有虚拟磁盘(vdi)丢失。
2、sr中的虚拟磁盘(vdi)访问时报错。
3、虚拟磁盘(vdi)删除或丢失。
4、快照(snapshot)删除或丢失。
5、sr初始化。
6、sr所在的LVM结构损坏。
7、sr所属的PV分区表损坏。
8、其他故障。
xen server故障分析:
上述故障是用户界面层的常见故障表现,解决这些故障问题首先要明白xen server sr层的结构组成。
xen server常见故障:
1、sr无法识别,所有虚拟磁盘(vdi)丢失。
2、sr中的虚拟磁盘(vdi)访问时报错。
3、虚拟磁盘(vdi)删除或丢失。
4、快照(snapshot)删除或丢失。
5、sr初始化。
6、sr所在的LVM结构损坏。
7、sr所属的PV分区表损坏。
8、其他故障。
xen server故障分析:
上述故障是用户界面层的常见故障表现,解决这些故障问题首先要明白xen server sr层的结构组成。
 服务器数据恢复环境:
IBM AIX系统;
存储由4个PV组成1个VG,VG中划分了5个文件系统:2个JFS2,2个JFS2LOG,1个JFS,两个JFS2中重要的一个JFS2由2组LV条带化后组成;
存储中存放的是由ORACLE数据库组织的某单位交管系统的重要数据。
服务器故障&分析:
因业务需要新增应用服务器,管理员不小心将4个PV MAP到新环境,然后删除全部LV后重新做了4个LV并生成文件系统。生产环境报错后又试图重建回原始的LV结构,导致对数据的进一步破坏。
需要恢复数据的文件系统中有200多个ORACLE数据文件。
服务器数据恢复环境:
IBM AIX系统;
存储由4个PV组成1个VG,VG中划分了5个文件系统:2个JFS2,2个JFS2LOG,1个JFS,两个JFS2中重要的一个JFS2由2组LV条带化后组成;
存储中存放的是由ORACLE数据库组织的某单位交管系统的重要数据。
服务器故障&分析:
因业务需要新增应用服务器,管理员不小心将4个PV MAP到新环境,然后删除全部LV后重新做了4个LV并生成文件系统。生产环境报错后又试图重建回原始的LV结构,导致对数据的进一步破坏。
需要恢复数据的文件系统中有200多个ORACLE数据文件。
 服务器数据恢复环境:
MYSQL数据库服务器,2块硬盘组建RAID1;
DATA卷存储了200多个数据库;
每天将每个数据库dump出后直接压缩成.gz包,然后将所有重要数据库的.gz 包放在一起压缩成一个总的.tar.gz包,覆盖原来的备份;
数据文件及备份文件全部存储于DATA卷上。
服务器故障&分析:
在一次常规的维护中,管理员不小心将DATA卷下的所有文件全部rm,删除后管理员马上关闭系统,再未做其它操作,但在删除那一刻有大量终端在访问此服务器。
服务器数据恢复环境:
MYSQL数据库服务器,2块硬盘组建RAID1;
DATA卷存储了200多个数据库;
每天将每个数据库dump出后直接压缩成.gz包,然后将所有重要数据库的.gz 包放在一起压缩成一个总的.tar.gz包,覆盖原来的备份;
数据文件及备份文件全部存储于DATA卷上。
服务器故障&分析:
在一次常规的维护中,管理员不小心将DATA卷下的所有文件全部rm,删除后管理员马上关闭系统,再未做其它操作,但在删除那一刻有大量终端在访问此服务器。
 服务器电源损坏,用户找到一家电源销售商更换电源。可能是害怕损坏硬盘中的数据,电源销售商竟然把硬盘全部拔掉(只留下RAID卡)启动服务器进行测试,完成测试后再次连接硬盘启动服务器,发现RAID信息已经破坏。之后又做了一些操作(未知)。
我们中心拿到故障服务器时的故障表现:启动操作系统时提示无效的引导记录。用户要求恢复服务器中的数据,同时重新激活修复服务器的操作系统。
服务器电源损坏,用户找到一家电源销售商更换电源。可能是害怕损坏硬盘中的数据,电源销售商竟然把硬盘全部拔掉(只留下RAID卡)启动服务器进行测试,完成测试后再次连接硬盘启动服务器,发现RAID信息已经破坏。之后又做了一些操作(未知)。
我们中心拿到故障服务器时的故障表现:启动操作系统时提示无效的引导记录。用户要求恢复服务器中的数据,同时重新激活修复服务器的操作系统。
 LINUX系统执行FSCK出错的故障表现:
1、无法挂载分区;
2、文件/目录丢失,根目录下生成/LOST+FOUND文件夹,里面有大量#XXXXXX类的文件和目录;
3、FSCK很快报错完成;
4、执行FSCK时有大量提示如修改节点、清0节点等操作。
LINUX系统执行FSCK出错的故障表现:
1、无法挂载分区;
2、文件/目录丢失,根目录下生成/LOST+FOUND文件夹,里面有大量#XXXXXX类的文件和目录;
3、FSCK很快报错完成;
4、执行FSCK时有大量提示如修改节点、清0节点等操作。
 数据库数据恢复环境:
LINUX EXT3文件系统,部署ORACLE数据库。
数据库故障&分析:
管理员在建立测试库时选错了服务器,在ORACLE数据库平台上CREATE了一套新库,创建至10%左右时发现异常,中止操作。
查看数据库目录发现只剩下SYSTEM2.DBF这一个库,其他的库(主要为SYSTEM1.DBF)丢失。
数据库数据恢复环境:
LINUX EXT3文件系统,部署ORACLE数据库。
数据库故障&分析:
管理员在建立测试库时选错了服务器,在ORACLE数据库平台上CREATE了一套新库,创建至10%左右时发现异常,中止操作。
查看数据库目录发现只剩下SYSTEM2.DBF这一个库,其他的库(主要为SYSTEM1.DBF)丢失。
 服务器数据恢复环境:
北京某科技大学,某品牌PowerEdge系列某型号服务器,6块SAS硬盘组成RAID5;
操作系统REDHAT,文件系统EXT3,分区采用LVM方式,存储着该大学某研究室运算1年多的重要数据。
服务器故障&分析:
未知原因导致服务器崩溃。管理员进入RAID控制界面检查发现1号盘与6号盘状态显示损坏。咨询服务器原厂工程师后,管理员强制上线6号盘,结果raid无法启动(操作系统也安装于此RAID)。管理员意识到问题严重性,马上停止所有操作。
服务器数据恢复环境:
北京某科技大学,某品牌PowerEdge系列某型号服务器,6块SAS硬盘组成RAID5;
操作系统REDHAT,文件系统EXT3,分区采用LVM方式,存储着该大学某研究室运算1年多的重要数据。
服务器故障&分析:
未知原因导致服务器崩溃。管理员进入RAID控制界面检查发现1号盘与6号盘状态显示损坏。咨询服务器原厂工程师后,管理员强制上线6号盘,结果raid无法启动(操作系统也安装于此RAID)。管理员意识到问题严重性,马上停止所有操作。
 数据库恢复环境:
联通海南分部信息平台,HP-UX小型机;
ORACLE数据库,卷文件系统为VxFS。
数据库故障&分析:
工程师误RM掉了重要ORACLE数据库,丢失了所有的数据表、UNDO、LOG等。
数据库恢复环境:
联通海南分部信息平台,HP-UX小型机;
ORACLE数据库,卷文件系统为VxFS。
数据库故障&分析:
工程师误RM掉了重要ORACLE数据库,丢失了所有的数据表、UNDO、LOG等。
 服务器数据恢复环境:
某网站服务器,LINUX操作系统;
6块硬盘组建RAID5;
逻辑磁盘中只包含一个卷,文件系统为EXT3,存放所有客户的数码照片。
服务器故障&分析:
网站正常工作中卷突然离线,管理员检查服务器发现1号与4号两块硬盘指示灯显示黄色。致电服务器厂商售后,厂商技术人员提供的解决方案为随机选择一块报警的硬盘强制上线。
管理员选择4号盘强制上线,上线后可MOUNT,但很多目录打不开,某些目录下近几天的文件丢失。用户意识到问题的严重性后马上关机,没有做其他任何操作,联系我们数据恢复中心寻求帮助。
服务器数据恢复环境:
某网站服务器,LINUX操作系统;
6块硬盘组建RAID5;
逻辑磁盘中只包含一个卷,文件系统为EXT3,存放所有客户的数码照片。
服务器故障&分析:
网站正常工作中卷突然离线,管理员检查服务器发现1号与4号两块硬盘指示灯显示黄色。致电服务器厂商售后,厂商技术人员提供的解决方案为随机选择一块报警的硬盘强制上线。
管理员选择4号盘强制上线,上线后可MOUNT,但很多目录打不开,某些目录下近几天的文件丢失。用户意识到问题的严重性后马上关机,没有做其他任何操作,联系我们数据恢复中心寻求帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号